
はじめに
本記事では、昨今話題の AI エージェントサービスをこれから作る方へ、AI エージェントシステムを作る上での抑えるべきポイントと実践的なハンズオンにて DeepDive していきたいと思います。
本記事は 2 部構成になっており、以下の構成です。
- 第 1 部: AI エージェント の基本概念とエージェントシステム構築のガイド
- 第 2 部: Azure AI Agent Service を使ったワークフロールーティングの実装
第1部では、OpenAI 社のa-practical-guide-to-building-agents を参考に、AI エージェントの基本概念とエージェントシステム構築のガイドを解説します。
第2部では、Anthropic のブログ記事 Building Effective Agents – Workflow Routing で紹介されている ワークフロールーティング のアイデアを、Azure AI Agent Service を使って実装しながら理解していきます。
上記概念の動作を確認する為に、2025/5 にリリースされた AI Agent Service の _Connected Agents _ を使ってみます。
この Connected Agents は、Azure AI Agent Service の新機能で、複数のエージェントを連携させてワークフローを簡単に構築することができます。
ハンズオンは以下の Agent の構成を実装します。ぜひ手を動かしながらアプリケーションを動作させて catch up してみてください。
ハンズオンの流れを図にするとこんな感じのアプリケーションを作っていきます。

本記事は AI エージェントの設計から深く学びたい方は第1部から、
とにかく動かして理解したい方は第2部から始めていただければ OK です。
それでは、AI エージェントの世界へ Deep Dive していきましょう 🚀
第 1 部: AI エージェント の基本概念とエージェントシステム構築のガイド
AI Agent とは?
前提として、AI Agent についてざっとおさらいです。
従来のソフトウェアでもワークフローを効率化・自動化することは可能ですが、エージェントはユーザーの代わりに高い独立性を持って同じワークフローを実行することができます。
エージェントとは、ユーザーに代わってタスクを自律的に遂行するシステムのこと
ワークフローとは、ユーザーの目的を達成するために実行すべき一連のステップを指し、たとえばカスタマーサービスの問題解決、レストラン予約、コード変更のコミット、レポート生成などがあります。
LLM を統合していても、それをワークフローの実行側に利用しないアプリケーション(例:単純なチャットボット、単一ターンの LLM、感情分類器など)はエージェントとはみなされません。
より具体的には、エージェントはユーザーの代理として安定的かつ一貫してタスクを実行するために、次のような特性を持ちます。
具体的には、以下のような例です。
-
ワークフローの実行を管理し、意思決定を行うために LLM を活用する
- ワークフローが完了したかどうかを認識し、必要に応じて自らの行動を積極的に修正する。
- 失敗した場合には、実行を停止し、制御をユーザーに戻す。
-
外部システムとやり取りするためのさまざまなツールにアクセスできる
- コンテキストを収集したりアクションを実行したりする。
- ワークフローの現状に応じて適切なツールを動的に選択し、常に明確に定義されたガードレール内で動作する。
Agent 利用のユースケース
エージェントを構築するには、システムの意思決定方法や複雑さへの対応方法を見直す必要があります。従来の自動化とは異なり、エージェントは決定論的でルールベースの手法では対応できないワークフローにおいて特に効果を発揮します。
具体的には、支払い不正の分析を考えてみましょう。
従来のルールエンジンはチェックリストのように機能し、あらかじめ設定された基準に基づいて取引を識別します。これに対して AI エージェント は、経験豊富な調査員のようにコンテキストを評価し微妙なパターンを考慮するため、明確なルール違反がない場合でも疑わしい活動を特定できます。
この高度な思考能力があるからこそ、エージェントは複雑で不明瞭な状況にも対応できるのです。
エージェントが価値を提供できるユースケース
エージェントを検討する際は、従来の自動化が困難だったワークフロー、特に下記のような領域に注目してください。
-
複雑な意思決定
- 綿密な判断や例外処理、文脈に応じた対応が必要なワークフロー
- ex.) カスタマーサービスワークフローにおける返金承認
- 綿密な判断や例外処理、文脈に応じた対応が必要なワークフロー
-
運用が煩雑なルール
- 膨大かつ複雑なルールにより更新が困難になり、変更のたびにコストやエラーが発生しやすくなっているシステム
- ex.) ベンダーのセキュリティレビューの実施
- 膨大かつ複雑なルールにより更新が困難になり、変更のたびにコストやエラーが発生しやすくなっているシステム
-
非構造化データへの強い依存
- 自然言語の解釈や文書から情報を抽出する処理、あるいはユーザーとの会話を通じたやり取りが必要な場面
- ex.) 住宅保険の請求処理
- 自然言語の解釈や文書から情報を抽出する処理、あるいはユーザーとの会話を通じたやり取りが必要な場面
エージェントの開発を決定する前に、そのユースケースがこれらの条件を明確に満たしているか確認してください。満たしていない場合、従来の決定論的アプローチでも十分な可能性があります。
改めてになりますが、エージェントが効力を発揮するのは、決定論的でルールベースの手法では対応できないワークフローです。
それ以外だと、従来の自動化手法で十分対応可能な場合が多いです。
エージェント設計の基本
エージェントは、以下の 3 つの主要な構成要素 から成り立っています。
| # | 要素 | 役割割 |
|---|---|---|
| 01 | モデル (Model) | エージェントの推論および意思決定を支える LLM |
| 02 | ツール (Tools) | エージェントがアクションを実行するために使用する外部関数や API |
| 03 | 指示 (Instructions) | エージェントの振る舞いを定める明確なガイドラインとガードレール |
python で OpenAI 社の Agent SDK を使う場合は以下のようなコードになります。
weather_agent = Agent(
name="Weather Agent",
instructions="""You are a weather agent that provides accurate and up-to-date weather information.
Use the provided tools to fetch current weather data and respond to user queries.
""",
tools=[get_weather]
)
モデル(Model)の選択
モデルには、それぞれ タスクの複雑さ・レイテンシ・コスト に関する強みとトレードオフがあります。
本記事の「オーケストレーション」セクションでは、ワークフロー内のさまざまなタスクに応じて複数のモデルを使い分ける方法を紹介します。
すべてのタスクに最高性能のモデルが必要なわけではありません。
- 単純な情報取得や分類 には、小型で高速なモデルで十分対応できます。
- 返金の可否判断のような複雑なタスク には、より能力の高いモデルが適しています。
効果的なアプローチは以下の通りです。
- まず最高性能モデルでプロトタイプを構築し、性能の基準線を確立する。
- その後 小型モデルに置き換え ても許容できる結果が得られるかを確認する。
- こうしてエージェントの能力を制限しすぎることなく、小型モデルで成功するタスクと失敗するタスクを把握できる。
モデル選択の原則は以下になります。
- 評価基準を設定し、パフォーマンスの基準を確立する
- 最高性能のモデルを用いて、精度目標を達成することに注力する
- コストとレイテンシを最適化 するために、可能な限り小型のモデルに置き換える
OpenAI 社 が提供するモデル選択に関する包括的なガイドは 以下 で確認できます。
ツール(Tools)の定義
ツールは、対象のアプリケーションやシステムが提供する API を利用することで、エージェントの能力を拡張します。
API が存在しないレガシーシステムでは、コンピュータ操作モデルを用いて人間と同様に Web やアプリケーションの UI を介して直接やり取りを行います。
各ツールは標準化された定義に従い、ツールとエージェントの間に柔軟な多対多の関係を実現できます。適切にドキュメント化され、十分にテストされ、再利用可能なツールは発見性を高め、バージョン管理を簡易化し、冗長な定義を防止します。
エージェントが必要とするツールは、主に以下の 3 種類 です。
| 種類 | 説明 | 例 |
|---|---|---|
| データ | エージェントがワークフローを実行するために必要なコンテキストや情報を取得するツール | 取引データベースや CRM の検索、PDF ドキュメントの読み込み、Web 検索の実行 |
| アクション | エージェントがシステムと対話し、データベースに新情報を追加・更新したり、メッセージを送信したりするツール | メール/テキストの送信、CRM レコードの更新、人間へのカスタマーサービスチケット引き継ぎ |
| オーケストレーション | エージェント自体が他のエージェントのツールとして機能するもの(オーケストレーションセクションのマネージャーパターン参照) | 返金エージェント、調査エージェント、ライティングエージェント |
指示 (Instructions) の設定
高品質な 指示 (Instructions) は LLM を活用したアプリケーションにおいて不可欠ですが、特にエージェントではきわめて重要です。明確な指示は 曖昧さを減らし、エージェントの意思決定を改善し、ワークフローの円滑な実行とエラーの減少 につながります。
エージェント指示のベストプラクティスは以下になります。
既存のドキュメントを活用する
ルーチンを作成する際は、既存の業務手順書・サポート用スクリプト・ポリシードキュメントを活用し、LLM に適した形式へ落とし込みます。
例:カスタマーサービスでは、ルーチンがナレッジベース内の個々の記事に対応することが多い。
エージェントにタスクを細分化するよう指示する
密度の高いリソースから 小さく明確なステップ を提供することで、曖昧さを最小限に抑え、モデルが指示を的確に理解できるようにします。
明確なアクションを定義する
ルーチン内の各ステップが 具体的なアクションや出力 に対応していることを確認します。
例:「ユーザーに注文番号を尋ねる」「API を呼び出してアカウント情報を取得する」など。
アクションを明確に示すことで(ユーザー向けメッセージ文言でも同様)、解釈の誤りを減らします。
エッジケースを考慮する
現実のユーザー対応では、ユーザーが不完全な情報を提供したり、想定外の質問をするなど、判断が必要な場面が発生します。堅牢なルーチンでは、こうしたケースをあらかじめ想定し、条件分岐や代替ステップ を用意して対応します。
オーケストレーション
基本となるコンポーネントが揃ったら、エージェントが効果的にワークフローを実行できるように、オーケストレーションのパターン を検討しましょう。
最初から複雑なアーキテクチャで完全自律型エージェントを作りたいという気持ちを抑えて、少しずつ段階的なアプローチ をとる方が成功する確率が高くなります。
一般的に、オーケストレーションのパターンは大きく 2 つのカテゴリー に分類されます。
| # | パターン | 説明 |
|---|---|---|
| 01 | シングルエージェントシステム | 単一のモデルが、必要なツールや指示を利用して、ループの中でワークフローを処理します。 |
| 02 | マルチエージェントシステム | ワークフローの実行タスクを複数のエージェントに分散させ、それらを調整することで動作します。 |
それぞれのパターンについて詳しく見ていきましょう。
シングルエージェントシステム
シングルエージェントは ツールを段階的に増やす ことで多様なタスクに適応できます。
この方式はシステムの複雑さを抑え、評価・保守を容易にします。
また、新しいツールを追加するたびにエージェントの能力が拡張されるため、無理に複数エージェントを運用する必要がありません。
オーケストレーションのアプローチで **実行 (run)**という概念があります。これはループとして実装され、エージェントが何らかの修了条件を満たすまで継続的に動作します。終了条件はツールの呼び出しや structured output での出力、エラーの発生、または最大ターン数への到達などです。
- 実行ループ: エージェントが連続的に動作し、タスク完了まで処理を続ける仕組み。
-
主な終了条件
- ツール呼び出しの完了
- structured output での出力完了
- エラーの発生
- 最大ターン数への到達
いつマルチエージェントを構築すべきか?
私たちの一般的なアドバイスは、まずシングルエージェントの能力を最大限に活用することです。
エージェントの数を増やすと、概念の重複や分離が難しくなる一方で、より複雑性が増してオーバーヘッドが発生します。多くの場合、ツールを活用したシングルエージェントだけで十分でしょう。
しかし 複雑なワークフロー では、プロンプトやツールをマルチエージェントに分割することで パフォーマンスやスケーラビリティ を向上できる可能性があります。
- エージェントが複雑な指示に従うことができない
- 一貫して誤ったツールを選択してしまう
といった場合には、システム全体を分割して より明確に定義されたエージェント を導入する必要があるかもしれません。
実務で検討されるケースとしては以下となります。
| 判断基準 | 説明 | 推奨アクション |
|---|---|---|
| 複雑なロジック | プロンプトに多くの条件分岐 (if-then-else) が含まれ、テンプレートの拡張が困難 | 各ロジックを別エージェントに割り当て、管理とデバッグを簡素化 |
| ツールのオーバーヘッド | 15 個以上の明確に定義された異なるツールを効率的に管理できる実装は稀。10 個未満でも複雑化するケースあり | ツール名をわかりやすくし、パラメータを明確に記述。それでもパフォーマンスが向上しない場合はマルチエージェントを検討 |
シングル・マルチエージェント 判断フローは以下のように考えられます。
上記に沿って正しくシングル・マルチエージェントを選択することで、システムの複雑さを抑えつつ、エージェントのパフォーマンスとスケーラビリティを最大化できます。
マルチエージェントシステム
マルチエージェントシステムは、特定のワークフローや要件に合わせて様々な方法で設計できますが、実務上広く適用可能な 2 つの主要パターン が見えています。
| パターン | 役割・特徴 | 典型的なユースケース |
|---|---|---|
| マネージャー型 (ツールとしてのエージェント) |
中央の マネージャー役 のエージェントがツール呼び出しとして複数の専門エージェントを調整し、それぞれが特定ドメイン/タスクを担当 | コールセンターの自動応答基盤、RAG パイプラインのサブタスク分割 |
| 分散型 (エージェントからエージェントへのハンドオフ) |
複数のエージェントが対等な立場で協働し、専門性に基づいてタスクを次のエージェントへ引き継ぐ | 開発 → レビュー → テストの CI/CD ワークフロー、複合ドキュメント生成パイプライン |
モデル化イメージは以下になります。
どのパターンを採用する場合でも、基本原則は共通です。
- コンポーネントは柔軟かつ再利用可能なモジュールとして構成
- 明確かつ簡潔 なプロンプトで制御
- グラフ構造で依存関係とデータフローを可視化
これにより、複雑なタスクでもスケーラブルかつ保守しやすいアーキテクチャを実現できます。
マネージャー型パターン
マネージャー型パターンでは、中央の LLM(マネージャー) がツール呼び出しを通じて、
専門エージェントのネットワークを シームレスにオーケストレーション します。
マネージャーはコンテキストや制約を考慮し、適切なタイミングで適切なエージェントへタスクを振り分け、
結果を統合して 一貫した対話 を実現します。
それぞれ、特徴と利点は以下のようになります。
| 項目 | 説明 |
|---|---|
| 中央管理 | 1 つのエージェント(マネージャー)がワークフロー全体を制御 |
| 専門エージェントの活用 | ドメイン特化のエージェントをツールとして呼び出し、専門機能をオンデマンドで利用 |
| スムーズな UX | ユーザーは単一エージェントと対話するだけで、多様な機能を享受できる |
| 拡張性 | 専門エージェントを追加するだけで能力を拡張でき、マネージャー側の変更は最小限 |
フローの例は以下になります。
分散型パターン
分散型パターンでは、エージェントがワークフローの実行権限を他のエージェントへ直接“引き継ぎ(ハンドオフ)” できます。
- ハンドオフは 一方向 の移譲で、Agents SDK では ツール(関数) の一種として実装。
- ハンドオフ関数が呼び出された瞬間、新しいエージェントが処理を開始し、最新の会話状態 も継続されます。
この方式では 複数エージェントが対等 な立場で協働し、中央制御を持たずにタスクをリレー形式で完了させます。
単一エージェントに集約しにくい複雑なワークフローや、専門ドメインが明確に分かれているシナリオに最適です。
特徴と利点は以下になります。
| 項目 | 説明 |
|---|---|
| ハンドオフ | 一方向の移譲。呼び出し時に処理が即座に切り替わる |
| 状態継承 | 会話履歴やコンテキストを新エージェントへ引き継ぐ |
| 平等な協働 | 各エージェントが対等なノードとして連携し、中央管理を不要にする |
| 柔軟性 | 必要に応じてエージェントを追加・差し替えできるため、スケールや保守が容易 |
| ユースケース | マルチドメインのカスタマーサポート、複合ドキュメント生成、CI/CD での役割分担 など |
フローの例は以下になります。
ガードレールについて
AI エージェントにおける “ガードレール” とは、モデルの推論・ツール呼び出し・出力生成の各段階で 安全・適切・意図どおり に振る舞わせるために設ける “安全柵” や “制御ルール” の総称です。
イメージとしては、車線の外へ車が飛び出さないようにする道路脇のガードレールと同じで AI エージェントが 危険領域に逸脱しないよう囲い込む仕組み と考えると分かりやすいです。
具体的には以下の項目を保護するために設計されます。
| 保護対象 | 代表的なリスク | ガードレールの役割 |
|---|---|---|
| ユーザー | 有害・差別的・不正確な出力 | 不適切表現のブロック、ファクトチェック |
| 機密/個人情報 | PII 漏えい、内部情報の暴露 | マスキング・出力除去 |
| システム | プロンプトインジェクション、権限昇格 | 入力検査、動的ポリシー適用 |
| ビジネス/ブランド | ガイドライン違反、法令違反 | スタイル・トーン検証、コンプライアンスチェック |
上記のように、適切に設計された ガードレール は以下の2点を管理するうえで欠かせません。
- データプライバシー上のリスク(例:システムプロンプトの漏洩防止)
- 評判リスク(例:ブランド方針に沿わない出力の抑制)
単一のガードレールだけでは十分な保護を提供できないため、多層防御 (layered defense) として複数のガードレールを組み合わせることが推奨されます。
ガードレールの主なレイヤーは以下になります。
| レイヤー | 目的 | 具体例 |
|---|---|---|
| LLM ベース | 入力の妥当性・安全性・関連性を推論 | gpt-4o-mini でハルシネーション/関連度チェック、FT 版で safe/unsafe 判定 |
| モデレーション API | 有害・不適切コンテンツの検出 | OpenAI Moderation API を併用し “hate”, “self-harm” などをブロック |
| ルールベース | 明示的な禁止事項を高速フィルタ | 文字数上限・ブラックリスト・正規表現マッチングなど |
ガードレールの考えを入れた AI エージェント サービスのフロー全体のイメージは以下になります。

参考: https://cdn.openai.com/business-guides-and-resources/a-practical-guide-to-building-agents.pdf
特に機密情報性の高いデータを取り扱うサービスでは、ガードレールの考えを入れることが非常に重要になってきます。
ガードレールの種類
ガードレールの種類を以下にまとめます。
| ガードレール | 英語名 | 主な目的・機能 |
|---|---|---|
| 関連性分類器 | Relevance classifier | エージェントの応答が話題に留まっているかを判定し、トピック外のクエリを検出する。 例:「エンパイアステートビルの高さは?」というユーザー入力は金融の話題では無関連と判断。 |
| 安全性分類器 | Safety classifier | システムの脆弱性を悪用しようとする不正入力(ジェイルブレイクやプロンプトインジェクション)を検出しブロックする。 |
| 個人識別情報フィルター | PII filter | モデル出力に個人識別情報 (PII) が含まれていないかを判定し、必要に応じてマスクまたは除去する。 |
| モデレーション | Moderation | 有害または不適切な入力(ヘイトスピーチ、ハラスメント、暴力など)を検出し、安全かつ敬意ある対話を維持。 |
| ツール利用時の安全対策 | Tool safeguards | エージェントが呼び出す 各ツールのリスクを評価 し、低リスク/中リスク/高リスクといったレーティングで制御。 高リスクのアクションでは追加ガードレールを強制発動して誤操作や不正エスカレーションを防止。 |
| ルールベースによる保護 | Rules-based protections | シンプルな決定論的対策として、入力文字数上限・正規表現フィルター・ブラックリストなどを適用し、禁止用語や SQL インジェクションを遮断。 |
| 出力の検証 | Output validation | ブランドガイドラインやコンプライアンスポリシーに合致しているかを出力後に二次チェックし、逸脱を修正またはブロック。 |
ガードレール構築の進め方
ガードレールを構築する上で重要なこちは、対象のユースケースにおいて特定されているリスクに対応するガードレールを設定し、その後新たに発見された脆弱性に応じて追加していく方法が効果的です。
最初から完璧を目指すのではなく、段階的に強化していくことが重要です。
- データプライバシーとコンテンツの安全性を重視
- 実際に遭遇したケースや失敗事例に基づいて新たなガードレールを整備
- エージェントの進化に合わせてガードレールを調整
3 つめのエージェントの進化に合わせてガードレールを調整することが意外と見落としやすく、重要になってくると考えています。
第 1 部 まとめ
-
エージェントシステムは、複雑な意思決定や非構造化データ、膨らむルールベースシステムを含むユースケースに適しています。
-
オーケストレーションパターンについては、まずはシングルエージェントの構成から始め、必要に応じてマルチエージェントへ進化させましょう。
-
ガードレールは入力フィルタリングやツール利用から人間の介入に至るまで、あらゆる段階で重要。これにより、エージェントが本番環境でも安全かつ予測可能に動作することを保証します。
サービス構築成功までの道筋は、決して一度にすべてを実現ものではなく、まず小規模なシングルエージェント構成から始めて実際のユーザーと検証を行い、必要に応じてマルチエージェントの仕組みを取り込みながら徐々にエージェントの能力を拡張していきましょう。
正しい実装と反復的なアプローチがあれば、エージェントはタスクだけでなくワークフロー全体を知性と適応力を持って自動化し、実際のビジネス価値を提供できます。
これで、AI エージェントのサービス構築における基本的な考え方と実装方法についてキャッチアップ完了です。
まずは第 1 部、お疲れ様でした 🖐️
第 2 部: Azure AI Agent Service を使ったワークフロールーティングの実装
ハンズオンの流れの全体像
改めて、今回実装する multi-agent application の全体像を確認します。
第1部で説明したマネージャー型のマルチエージェントシステムを Azure AI Agent Service を使って実装します。
各エージェントの役割は次の通りです。
- Router Agent: gpt-4o を使う。ユーザーのリクエストを受け取り、適切なエージェントへ振り分ける。
- FAQ Agent: gpt-4o を使う。よくある質問に対して、AI Search を用いてデータソースを検索し回答する。
- Expert Agent: gpt-4o を使う。より専門的な質問に対して、データソースを検索し得られた知見をもとに回答する。
- General Agent: gpt-4o-mini を使う。一般的な質問に回答する。(ex. 今日は暑いですね。とか。)
Azure AI Foundry Agent Service 概要
Azure AI Foundry 内のサービスの一つで、マルチエージェントアプリケーションを簡単に構築・運用できるサービスです。
Azure AI Foundry の モデル/ツール/フレームワーク を 1 つのマネージド・ランタイムに統合し安全かつスケーラブルに AI エージェントを開発・運用 できるようにするサービス。
主要機能は以下になります。
- スレッド管理 – すべての対話を構造化データとして保持し、ポータルでデバッグ可能。
- ツール呼び出しの自動オーケストレーション – JSON Schema で宣言した検索・DB・業務 API を安全に実行。
- コンテンツセーフティ & ガードレール – 不適切入力の検出と修正をランタイム側で強制。
- 統合運用 – Azure AD (RBAC)、VNet、監視 (App Insights) とそのまま連携。
Let's ハンズオン
ハンズオンは以下の流れで進めます。
- 環境セットアップ – Azure AI Agent Service の準備
- Azure AI Agent Service のセットアップ – エージェントの作成と設定
- 動作検証 – エージェントの動作確認
- まとめ
環境セットアップ
これから、ハンズオンを進めていくにあたり、筆者の環境は以下になります。
# Node 20.x 系
➜ node -v
v22.17.0
➜ npm -v
10.9.2
それでは早速各種セットアップしていきましょう!
Azure AI Agent Service のセットアップ
以下の記事を参照し、AI Agent を構築していく
AI Foundry へアクセスし、新しいプロジェクトの作成を選択

そのまま、プロジェクトの作成をクリック
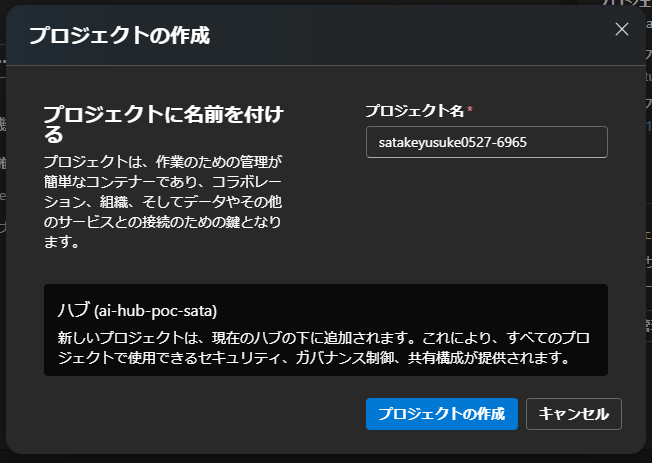
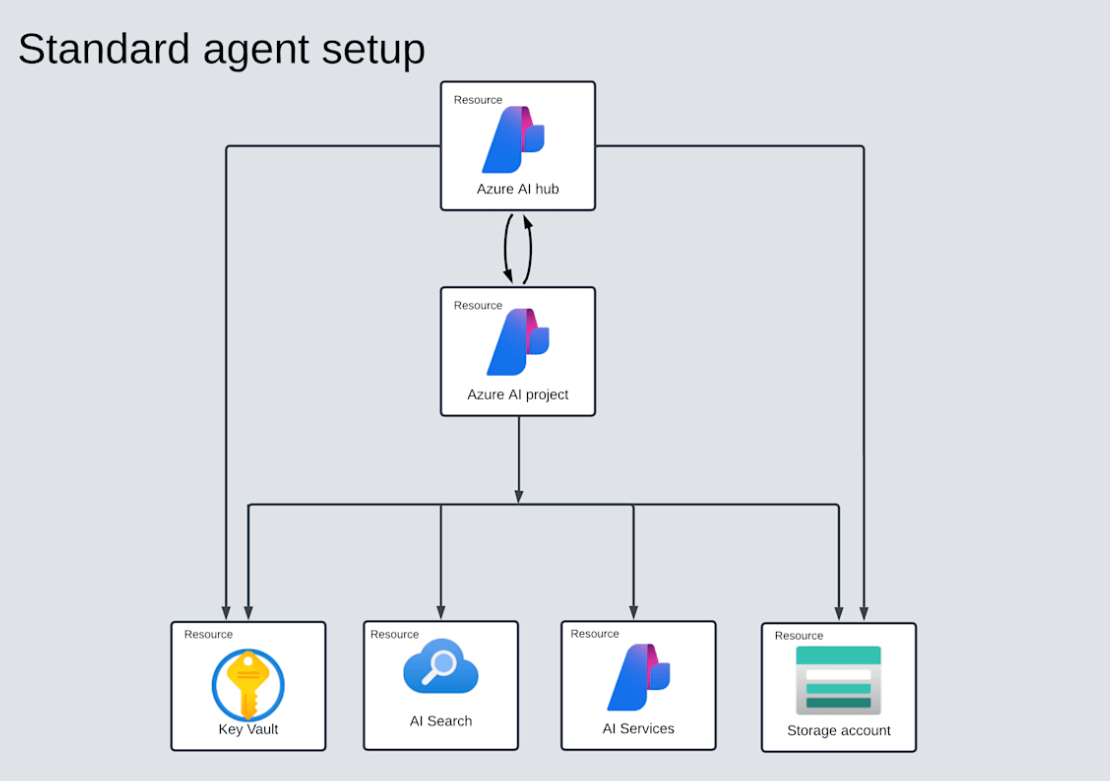
プロジェクトを作成すると、以下のリソースが作成される

図解すると以下。Azure AI hub の下に AI project が作成され、その下に KeyVault や AI Search, AI Services, Storage Account が作成される。
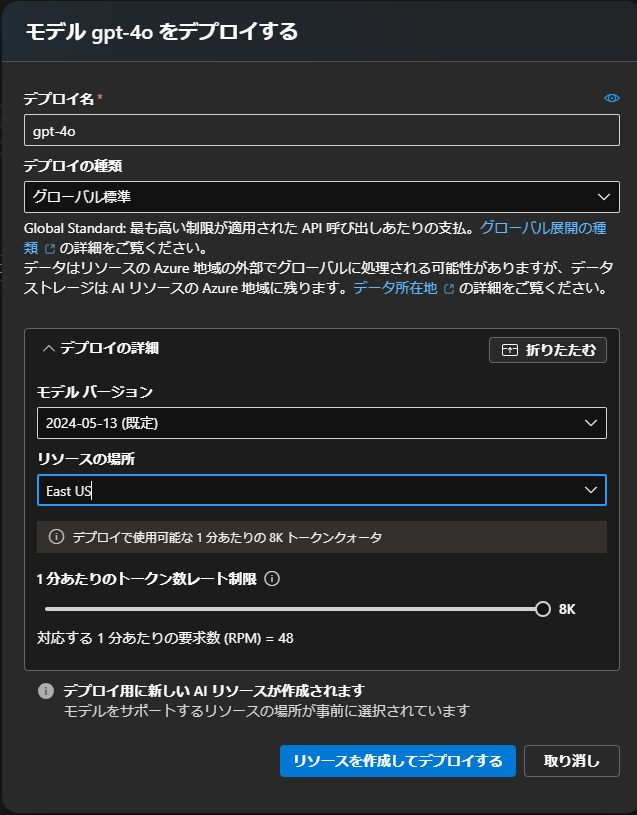
Azure AI Agent Service にてリソースを選択し、作成を進めていく。

モデル を Deploy するを選択

まずは、Router Agent と FAQ Agent で使用する GPT-4o を Deploy します。
次に、Expert Agent で使用する o3-mini と、General Agent で使用する gpt-4o-mini を Deploy します。
-
o3-mini

-
4o-mini
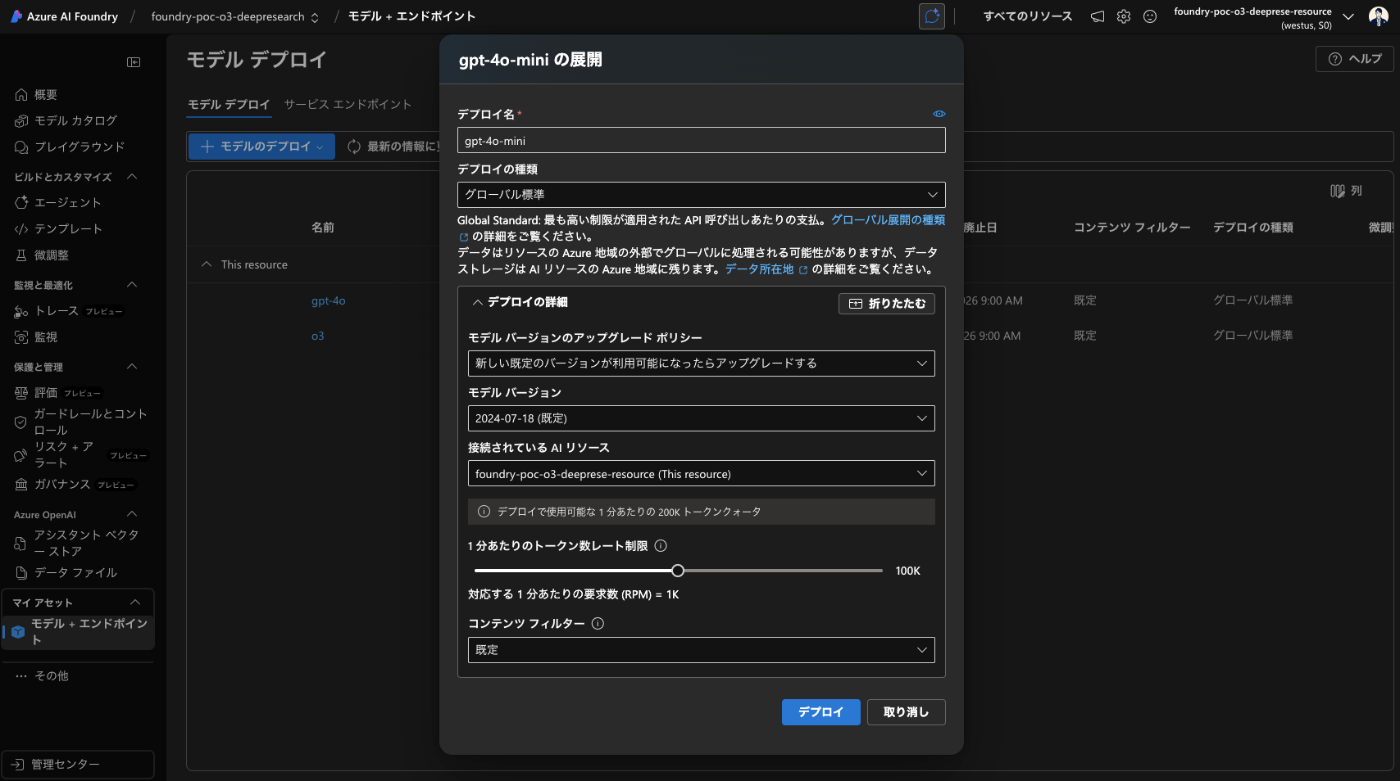
こんな感じに各モデルが表示されれば OK

次に AI Agent を作成していく。
画面左側メニューのエージェントを選択して、+ 新しいエージェントを選択

今回は 4 体の AI Agent を作成していきます。
- Router Agent: gpt-4o を使う。ユーザーのリクエストを受け取り、適切なエージェントへ振り分ける。
- FAQ Agent: gpt-4o を使う。よくある質問に対して、AI Search を用いてデータソースを検索し回答する。
- Expert Agent: gpt-4o を使う。より専門的な質問に対して、データソースを検索し得られた知見をもとに回答する。
- General Agent: gpt-4o-mini を使う。一般的な質問に回答する。(ex. 今日は暑いですね。とか。)
各エージェントの設定
これから、各エージェントの設定していきます。
general-agent
デプロイ
モデルは以下を使用
gpt-4o
手順へ以下を記載
一般的な質問の回答をしてください。
エージェントの説明へ以下を記載
user からの一般的な質問に回答してください。 ex.) 挨拶や今日の天気など
router-agent
デプロイモデルは以下を使用
gpt-4o
手順へ以下を記載
general-agent, faq-agent, expert-agent をオーケストレーションします。
- user からの一般的な質問は general-agent へ、
- user からの AI エージェント構築の単純な質問は faq-agent へ、
- user からの AI エージェント構築の複雑な質問は expert-agent を起動してください。
エージェントの説明へ以下を記載
general-agent, faq-agent, expert-agent をオーケストレーションするエージェントです。
user からの一般的な質問は general-agent へ、
user からの AI エージェント構築の単純な質問は faq-agent へ、
user からの AI エージェント構築の複雑な質問は expert-agent を起動してください。
接続されたエージェントの箇所で以下のように記載
general-agent

faq-agent
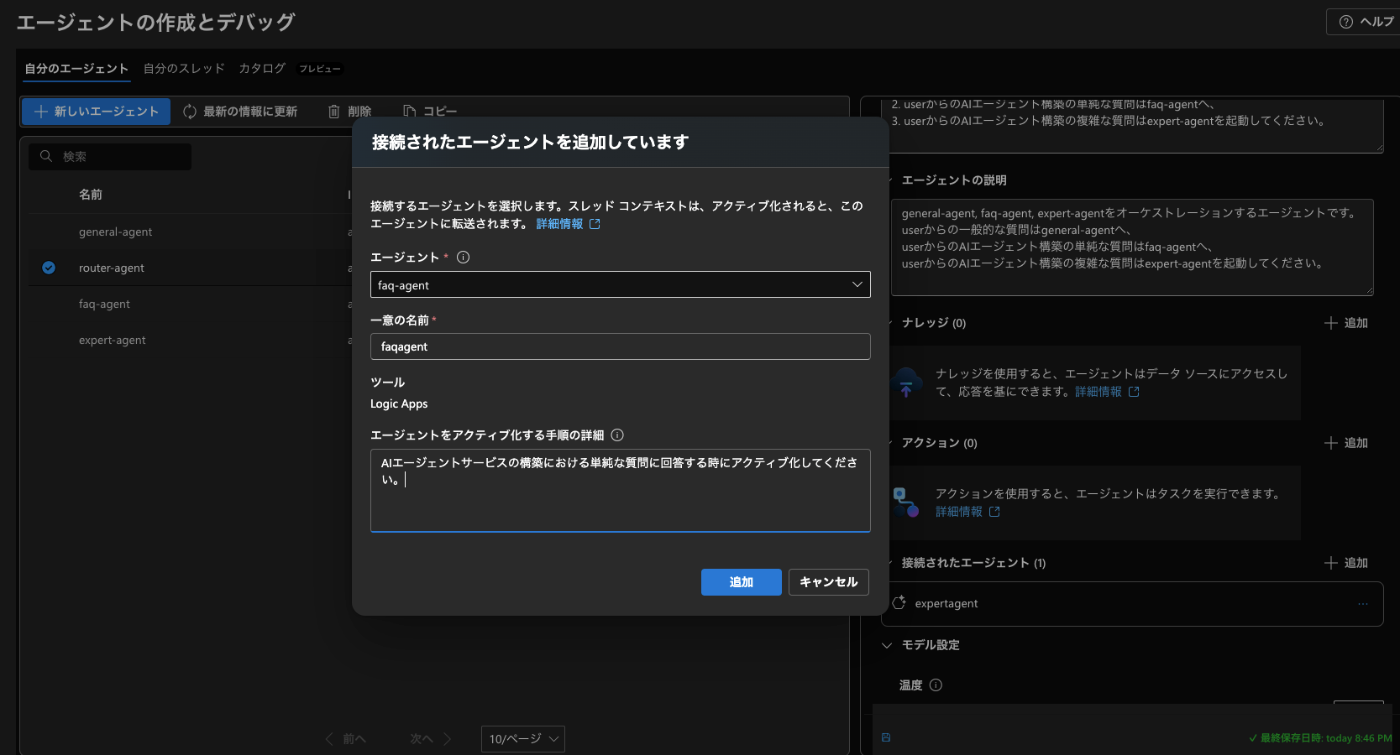
expert-agent
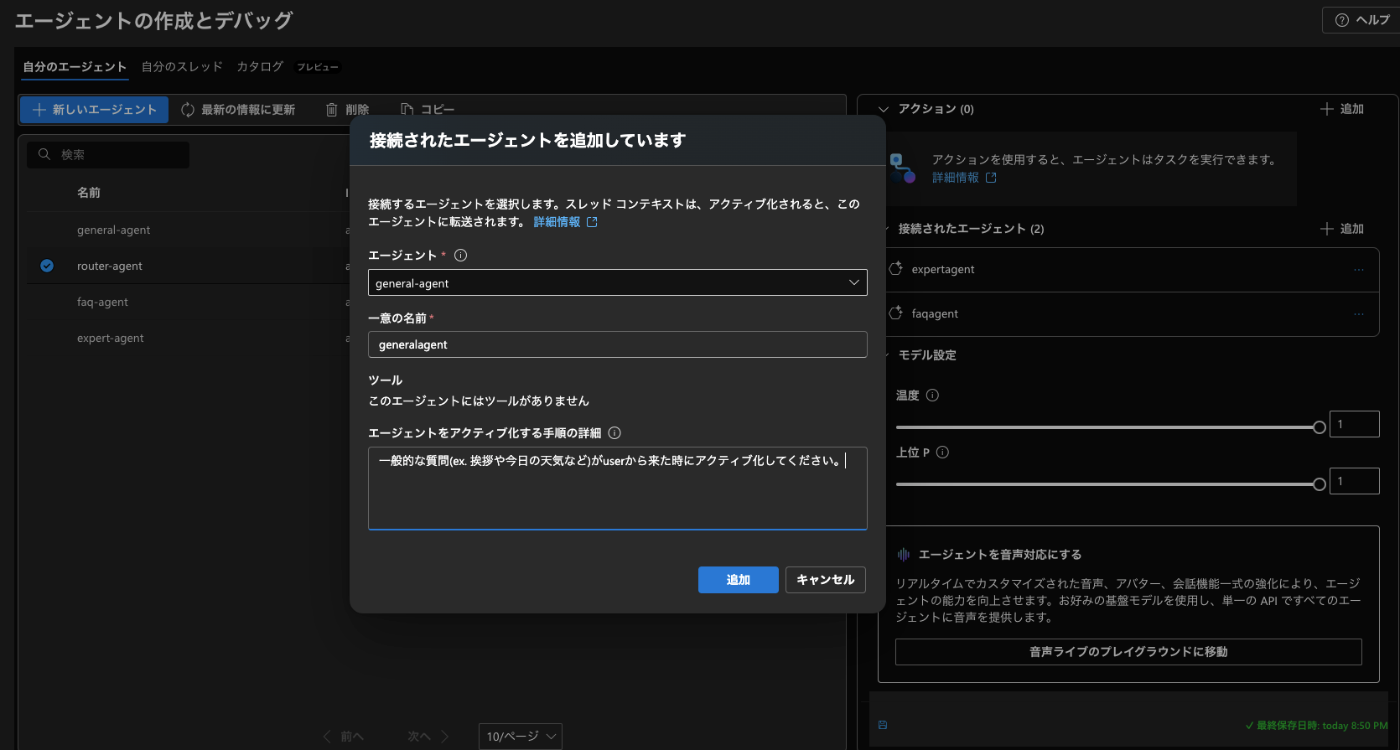
接続されたエージェントの箇所が以下の画像のようになっていれば OK

faq-agent
faq-agent の設定を行います。
faq-agent が参照するのは以下の OpenAI 社が出している AI エージェントに関するドキュメントです。
デプロイモデルは以下を使用
gpt-4o
手順へ以下を記載
ドキュメントを参照し、AI エージェントの構築に関するよくある質問に回答してください。
エージェントの説明へ以下を記載
AI エージェントのドキュメントを参照して、AI エージェントシステム構築における単純な回答を生成するエージェントです。
ナレッジの箇所の追加をクリックして、上述したドキュメントを追加します。

ファイルを追加してください。

以下のような形でナレッジが追加されていれば OK

expert-agent
専門的な質問に回答するエージェントを作成します。
外部ナレッジのデータは Blob Storage に格納し、検索には AI Search を使用します。
事前に Blob Storage に格納したデータを Index 化する為に、Azure OpenAI Service を Deploy して Embedding モデルも準備しておきます。
まずは Blob Storage にナレッジを格納します。
Azure Portal にアクセスし、Blob Storage を選択します。
デプロイの設定は以下で、あとはデフォルトのままで大丈夫です。

Storage Account が作成されたら、リソースへ移動しデータ ストレージ → コンテナー → コンテナーの追加を選択します。

コンテナ名はいい感じの名前をつけてください。
コンテナが作成されたら、先ほどと同様のファイルを Upload します。

これで、Blob Storage にナレッジが格納されました。
次に Azure OpenAI Service を Deploy して Embedding モデルを準備します。
Azure Portal から OpenAI Service を選択し、デプロイの設定を行います。

上記の画像のように設定して、後はデフォルトで OK です。
デプロイが完了したら、Azure OpenAI Service のリソースへ移動し、AI Foundry へ移動。Embedding モデルを Deploy します。

text-embedding-3-large を Deploy します。

次に AI Search を設定します。
Azure Portal から AI Search を選択し、デプロイの設定を行います。
設定は以下で、あとはデフォルトのままで大丈夫です。

※ 本記事では、Standard を選択していますが、Basic では、Index が 1 ファイル 16 MB (= 16,777,216 bytes) まで全文抽出できます。16MB 以上のデータを使用したい場合は Standard を、それ以下のデータサイズを参照させる場合は、Basic で問題ありません。
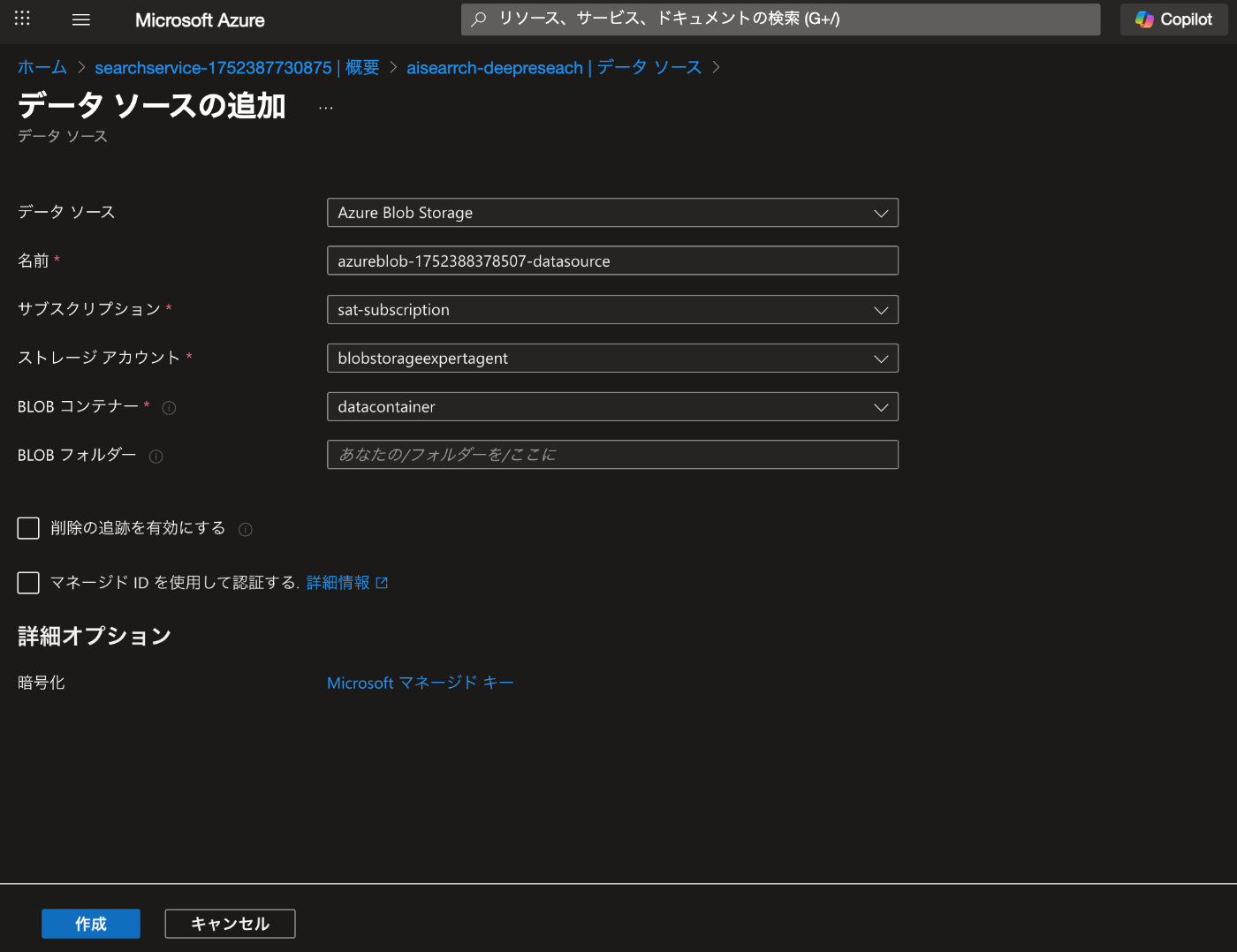
デプロイされたら、データソースを追加します。

データソースの追加から先ほど作成した Blob Storage を選択します。
次に AI Search 内に index を作成します。
概要からデータのインポートとベクター化を選択
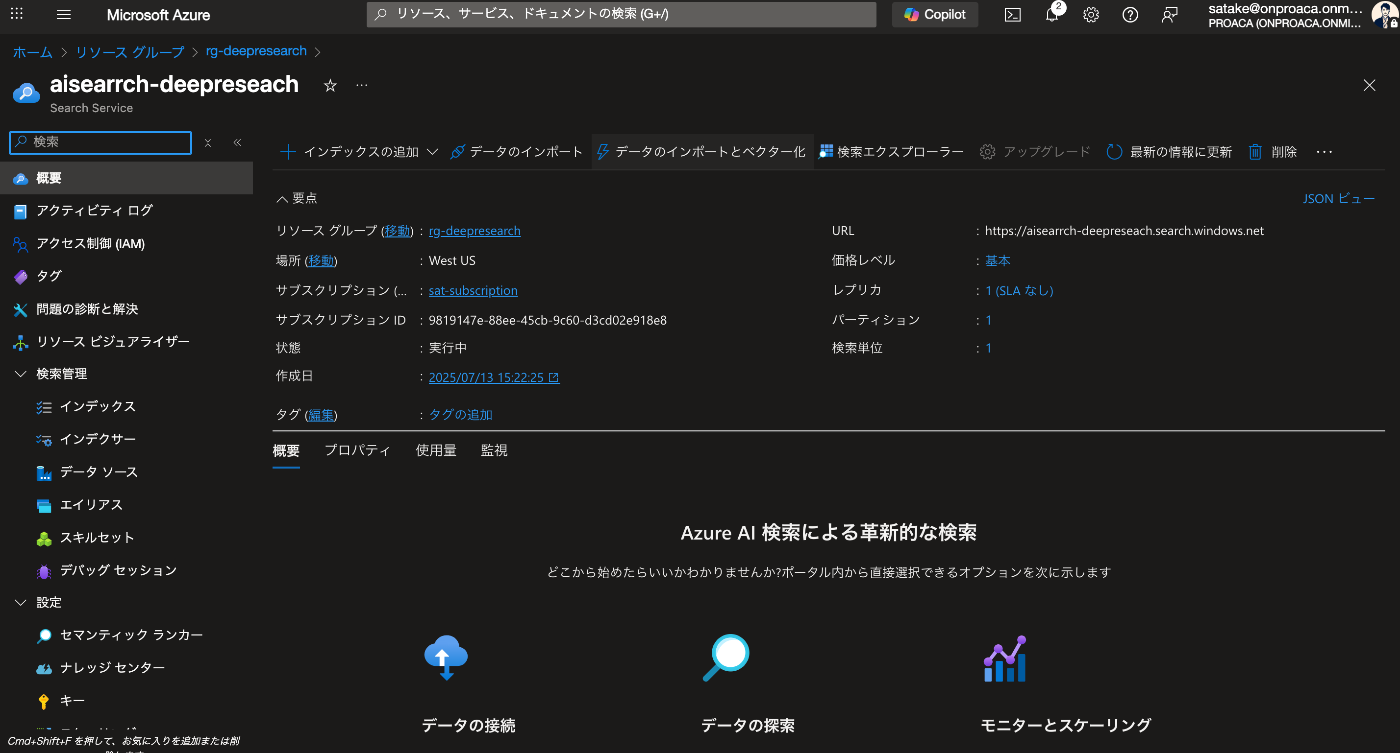
Azure Blob Storage を選択

RAG を選択してください。

データへの接続の箇所は以下の画像のように設定

デプロイが完了したら、Azure AI Foundry に戻り、expert-agent の設定を行います。
デプロイモデルは以下を使用
gpt-4o
手順へ以下を記載
AI エージェントの構築に関する専門的な質問に回答してください。また、ガードレールなどを考慮し、適切な回答を生成してください。
エージェントの説明へ以下を記載
AI Search を活用して、データソースから AI エージェントのドキュメントを参照して、AI エージェントシステム構築における複雑な回答を生成するエージェントです。データソースを検索して内容を回答することに加え、ガードレールなどを考慮し、適切な回答を生成してください。
ナレッジには、AI Search を選択し、先ほど作成した AI Search のインデックスを選択します。

以下のように Embedding モデルを選択します。

画像ファイルもベクター化したい場合は適宜チェックボックを選択してください。

検索精度を上げる為にセマンティックランカーを ON で設定します。

これで OK です。

Index 化が成功していれば、このように*を検索窓に入力して検索すると、検索結果が表示されます。

ここまできたら AI Agent Service のセットアップ完了です。
次は AI Foundry に戻り、AI Agent Service の expert-agent の設定を行います。
AI Search を選択

AI Agent Service に接続します。
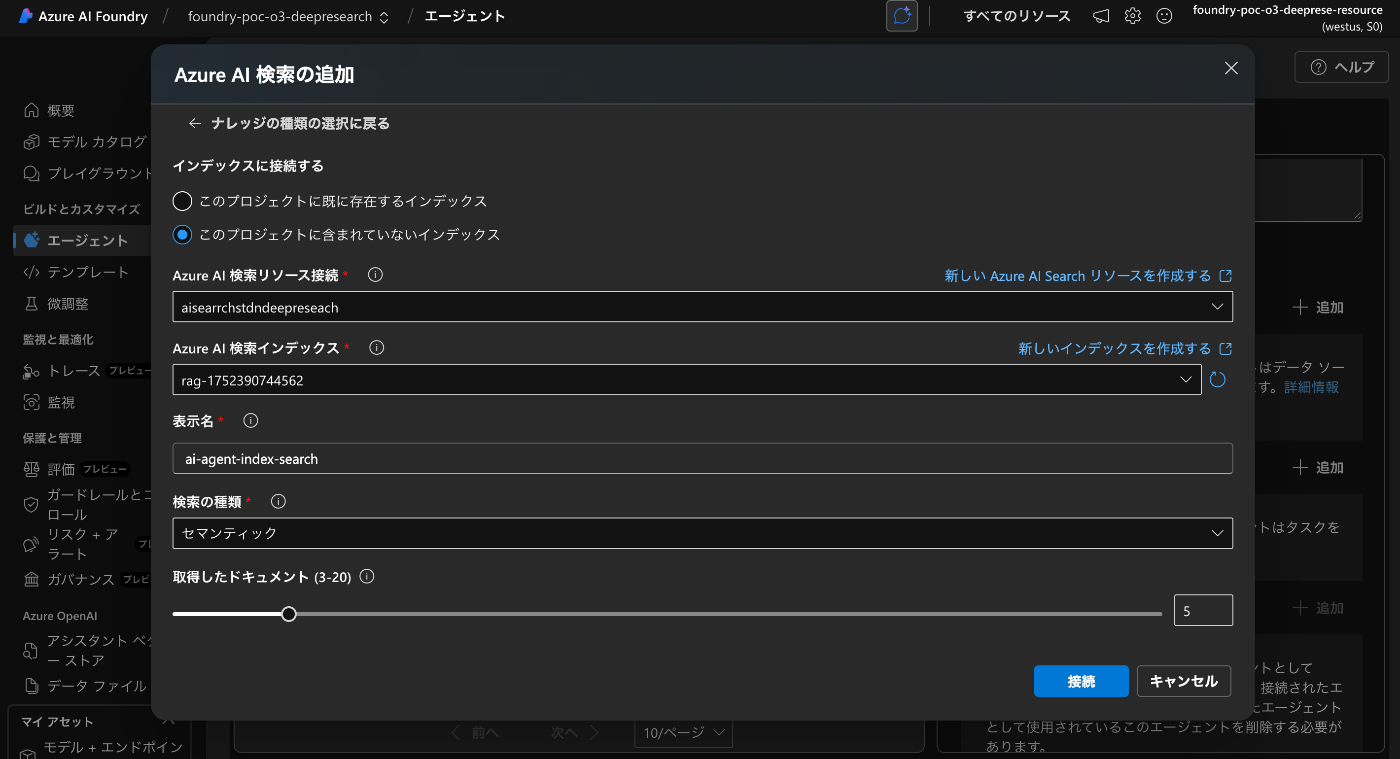
以下のように expert-agent に接続されていれば OK

これで、AI Agent Service のセットアップ完了です。
動作検証 – エージェントの動作確認
動作検証は簡単で、AI Roundry の AI Agent Service の router-agent を選択し、プレイグラウンドを開いてください。
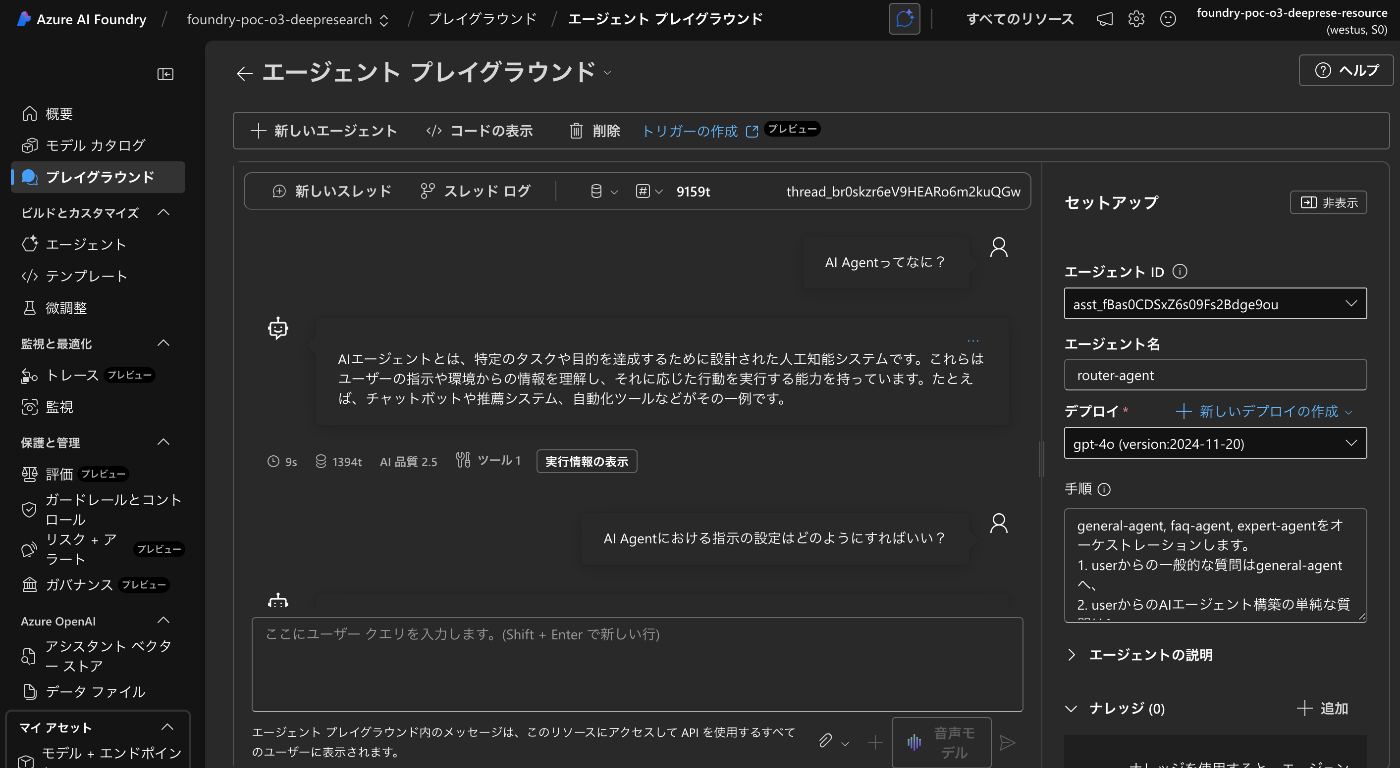
以下のように入力して会話を始めてみます。
スレッドログを見てみると、Tool にて connected_agent が呼び出され、適切なエージェントが呼び出されていることがわかります。

これで、router-agent が user からのリクエストを受け取り、適切なエージェントへ振り分けていることが確認できました。
ハンズオンもお疲れ様でした。
ちなみに Next.js のアプリケーションでも同様に動作することを確認しました。

Next.js の呼び出しの api は以下になります。
// app/api/agent/route.ts
/* eslint-disable @typescript-eslint/no-explicit-any */
import { DefaultAzureCredential } from '@azure/identity';
import { NextRequest } from 'next/server';
import { AIProjectClient } from '@azure/ai-projects';
export const runtime = 'nodejs';
/**
* POST /api/agent
* body: { userInput: string, threadId?: string }
*/
export async function POST(req: NextRequest) {
const { message } = await req.json();
console.log('🚀 ~ POST ~ message:', message);
// ── エージェントに投げて応答(1 行)を取得 ──
const assistantReply = await runAgentConversation(message);
console.log('🚀 ~ POST ~ assistantReply:', assistantReply);
// ── 文字列だけを返す ──
return new Response(assistantReply!, {
status: 200,
headers: { 'Content-Type': 'text/plain; charset=utf-8' },
});
}
async function runAgentConversation(userMessage: string) {
const project = new AIProjectClient(
'https://xxxxxxxxxxxxxxxxxx.services.ai.azure.com/api/projects/xxxxxxxxxxxxxxxxxxx',
new DefaultAzureCredential()
);
const agent = await project.agents.getAgent('asst_xxxxxxxxxxxxxxxxxx');
const thread = await project.agents.threads.create();
// ユーザー発話を追加
await project.agents.messages.create(thread.id, 'user', userMessage);
// エージェントを実行
let run = await project.agents.runs.create(thread.id, agent.id);
while (run.status === 'queued' || run.status === 'in_progress') {
await new Promise((r) => setTimeout(r, 1000));
run = await project.agents.runs.get(thread.id, run.id);
}
if (run.status === 'failed') throw new Error(run.lastError?.message);
// メッセージ一覧(昇順)を取得して最後の assistant 発話を抜き出す
const messages = await project.agents.messages.list(thread.id, {
order: 'asc',
});
let assistantReply = '';
for await (const m of messages) {
if (m.role === 'assistant') {
const content = m.content.find((c) => c.type === 'text' && 'text' in c);
if (content) assistantReply = content.text.value;
}
}
return assistantReply; // ← 1 行文字列を返す
}
こちらも上記の TypeScript のコードで呼び出すことができますので、ぜひ Next.js のアプリケーションを実装してチャレンジしてみてください。
第 2 部 まとめ
本章では、Azure AI Agent Service を使ってマルチエージェントアプリケーションを実装しました。
Connected Agents という新機能でより第1部で学んだマネージャー型のマルチエージェントシステムを Azure AI Agent Service を使って実装することで、エージェント間のオーケストレーションや専門エージェントの活用が容易になりました。
最後に
第1部・第2部とかなりのボリュームになってしましましたが、AI エージェントの基本的な考え方と実装方法についてキャッチアップできたかと思います。
AI エージェントは、複雑な意思決定や非構造化データ、膨らむルールベースシステムを含むユースケースに適しています。
まずはシングルエージェントの構成から始め、必要に応じてマルチエージェントへ進化させましょう。
また、ガードレールは入力フィルタリングやツール利用から人間の介入に至るまで、あらゆる段階で重要です。これにより、エージェントが本番環境でも安全かつ予測可能に動作することを保証することが出来ます。
これから AI エージェントを使ったサービスが増えていく中で、本記事が少しでも参考になれば幸いです。
それでは 🖐️
参考文献

Discussion