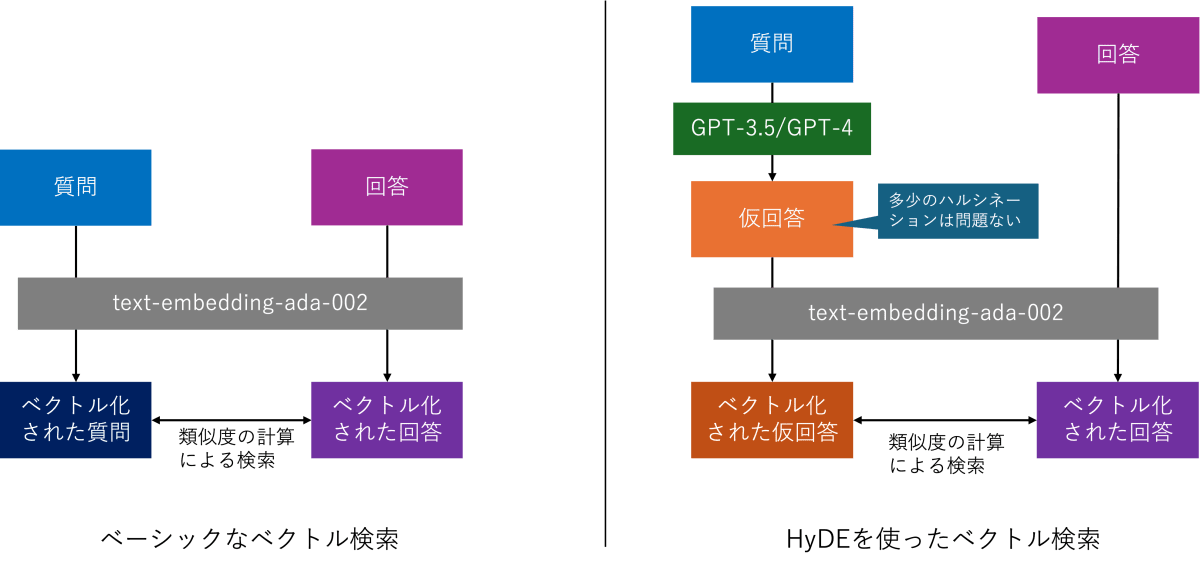
HyDE
通常、ベクトル検索を行う際には、事前にベクトル化した検索対象の文書と、都度ベクトル化した検索クエリのベクトルとの類似度を計算します。
歴史的に見れば以前は「text-search-davinci-doc-001」「text-search-davinci-query-001」のように、文書とクエリをそれぞれ別々にモデルに入力して埋め込みベクトルを得ていました。このようにモデルを分けることによって「質問」と「回答」といった文脈や文体が異なるような2つのベクトル空間上での類似度を高めるというアプローチです。
一方、現在Azure OpenAIでサポートされている埋め込みモデルである「text-embedding-ada-002」は上記のように用途によってモデルを分ける必要はなく、文書とクエリを同じモデルに入力して埋め込みベクトルを得ることができるとされています。しかし1つのモデルで良くなったとは言え、前述のような「質問」と「回答」のように異文脈・文体に対応する類似度検索には若干の懸念は残ります。
それを解決できそうなHyDE(Hypothetical Document Embeddings:仮説文書の埋め込み)という手法が提唱されています。
文字通り質問に対して仮の回答を生成し、その仮の回答と検索対象の類似度を比較するというものです。仮の回答の生成にはGPT-3.5やGPT-4などの言語モデルを利用することが想定されています。GPTモデル単体でのQAタスクはハルシネーションが発生するため、そのまま回答として使用することは基本的に推奨されていません。しかし、HyDEでは回答形式の文体と比較することで「回答」対「回答」の類似度検索になり、多少のハルシネーションが含まれている場合でも類似度の向上、つまるところ検索精度の向上に繋がるとされています。
原著論文はこちらです。Submittedが2022/12/22と比較的古くから提唱されている手法です。
実装
実際にPythonライブラリでHyDEを実装してみます。とは言ってもそこまで特殊なことをしているわけでは無いので本記事では要点のみピックアップします。すべてのコードはこちらに掲載しています。
はじめに質問と回答のサンプルを用意します。今回は比較対象として間違った回答も用意しました。
# ユーザーから入力される質問
question = "Surfaceの電源が入りません。どうすればよいですか?"
# 正解データ
correct_answer = """まず、Surfaceに接続されているすべてのアクセサリを取り外し、電源ボタンを押してみてください。
それでも電源が入らない場合は、Surfaceを充電し、電源ボタンを長押しして強制的にシャットダウンし、再起動してみてください。
さらに、Surfaceの電源が入っていても特定の画面で停止している場合は、その画面に応じた手順を実行してください。
対面サポートや自己修復のオプションも提供されています。上記の手順を試しても問題が解決しない場合は、サポート窓口でお問い合わせください。"""
# 不正解データ(実際に同じナレッジベースにはいってそうな似ている回答)
incorrect_answer = """まず、Xboxに使用しているコンセントが他のデバイスでは機能することを確認します。
電源ケーブルがコンセントとXbox本体にしっかり接続されていることを確認します。
Xbox本体に同梱の電源ケーブルを使用していることを確認します。お住まいの国や地域に適した電源ケーブルが同梱されています。
それでも本体の電源が入らない場合は、本体の交換が必要です。交換を依頼するには、Microsoft アカウントで [デバイス サービス と修理] にサインインして、サービス注文を送信します。
"""
まずはベーシックなベクトル検索手法を試してみます。
question_vector = client.embeddings.create(
input = question,
model= embedding_deployment
).data[0].embedding
correct_answer_vector = client.embeddings.create(
input = correct_answer,
model= embedding_deployment
).data[0].embedding
incorrect_answer_vector = client.embeddings.create(
input = incorrect_answer,
model= embedding_deployment
).data[0].embedding
vs_correct_answer = cosine_similarity(question_vector,correct_answer_vector)
vs_incorrect_answer = cosine_similarity(question_vector,incorrect_answer_vector)
続いてHyDEでのベクトル検索手法を試してみます。ここでの仮の回答を生成するプロンプトは原著論文に倣っています。
hypothetical_gen_instruction = f"""Please write a passage to answer the question
Question: {question}
Passage:
"""
hypothetical_answer = client.chat.completions.create(
model=deployment,
messages=[
{"role": "system", "content": "You are an AI assistant."},
{"role": "user", "content": hypothetical_gen_instruction},
],
temperature=0
).choices[0].message.content
hypothetical_answer_vector = client.embeddings.create(
input = hypothetical_answer,
model= embedding_deployment
).data[0].embedding
vs_correct_answer_hyde = cosine_similarity(hypothetical_answer_vector,correct_answer_vector)
vs_incorrect_answer_hyde = cosine_similarity(hypothetical_answer_vector,incorrect_answer_vector)
実際のコードはこちら
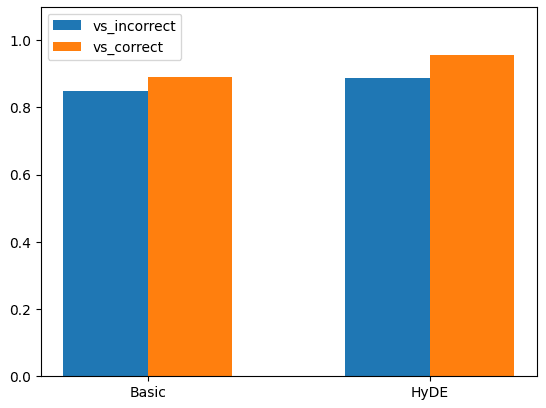
結果
結果は以下のようになりました。
| 正しい回答との類似度 | 間違った回答との類似度 | 差 | |
|---|---|---|---|
| ベーシック(クエリ) | 0.8898275927854662 | 0.8492056751258446 | 0.04062191765 |
| HyDE(仮の回答) | 0.9568607484152887 | 0.8885138499339678 | 0.06834689848 |
考察
「パッと見、効果がありそう」ということがなんとなくわかりますが、細かく考察すると次のような点がポイントと考えられます。
- HyDEを使った正しい回答の類似度は全てのサンプルの中で最も高くなっている。
- 文体が回答形式に寄っているためか、HyDEを使った場合は間違った回答の類似度も併せて高くなっている。しかし、HyDEの類似度はベーシックの場合と比較して正しい回答と間違った回答の類似度の差が大きくなっている。2023年11月に開催されたOpenAI DevDayの中でもRAGのプラクティスとして「シグナル/ノイズ比」という考え方で紹介されているが、シグナル(正解)とノイズ(間違った答え)の差が大きくなることでシグナルを検知しやすくなり、検索精度が向上すると考えられる。
- 仮の回答の生成にはインターネットの情報を学習したGPTモデルを使用しているため、少しでもインターネット上に情報があればハルシネーションを含んだとしてもそれらしい回答を生成してくれる。しかし、全くインターネット上に情報が無いような組織内情報の検索は別途対象データで検証してみる必要がありそう。とはいえ、概念レベルで情報がクローズドなケースはほとんど無いと考えられるため、この手法が使える望みは十分にあると考える。
今回試した実際のコードを含むAzure OpenAIに関する様々なコードをまとめたリポジトリを公開しています。
余談
HyDEの発音って「ハイド」でいいんですかね

Discussion