



はじめに
Markdown ファイルを対象にした RAG のチャンクサイズ検討を行う中で、検索対象ファイル群をレベル別 (e.g. #: レベル1、##: レベル2、等) にチャンキングした場合のトークン数を手っ取り早く知りたい状況があったため、確認する Python スクリプトを書きました。
なお、本記事は OpenAI の言語モデルのうちエンコーディングに cl100k_base が使われているモデルの使用を想定して書かれています。
使うパッケージ
サンプル入力データ
記事に記載する例として、ChatGPT に雑に指示をして Markdown 形式のデータを作ってもらいました。

# イルカの不思議な世界
イルカは知性と社会性を兼ね備えた海の哺乳類で、その行動やコミュニケーション能力は科学者や海洋愛好家の間で長年にわたって魅力的な研究対象となっています。この文書では、イルカの生態からコミュニケーション、人間との関わりに至るまで、様々な側面を探求します。
## イルカの基本情報
イルカは約40種類が確認されている鯨偶蹄目に属する海の哺乳類です。体長は種によって大きく異なり、1.2メートルから9メートルまでの範囲があります。多くの種類が群れを形成して生活しており、複雑な社会構造を持つことが知られています。
### 生態と行動
イルカは肉食で、魚やイカなどを主食としています。非常に知能が高く、複雑な狩猟戦略を用いることが観察されています。例えば、泡を使って魚を追い込む「泡ネット狩猟」や、泥をかき乱して魚をおびき寄せる技術などがあります。
#### コミュニケーション
イルカは高度なコミュニケーション技術を持っています。鳴き声、身体のポーズ、皮膚の色の変化などを用いて、群れ内で情報を伝達します。特に、イルカの鳴き声は個体識別の手段としても使われ、研究者はこれを「名前」と見なすことがあります。
##### 人間との関わり
イルカは人間との相互作用でよく知られており、多くの文化では友好的な存在として描かれています。イルカと人間との間には長い歴史があり、古代ギリシャでは救助の象徴と見なされていたと言われています。現代では、イルカと泳ぐ体験やイルカを通したセラピーが人気を博しています。
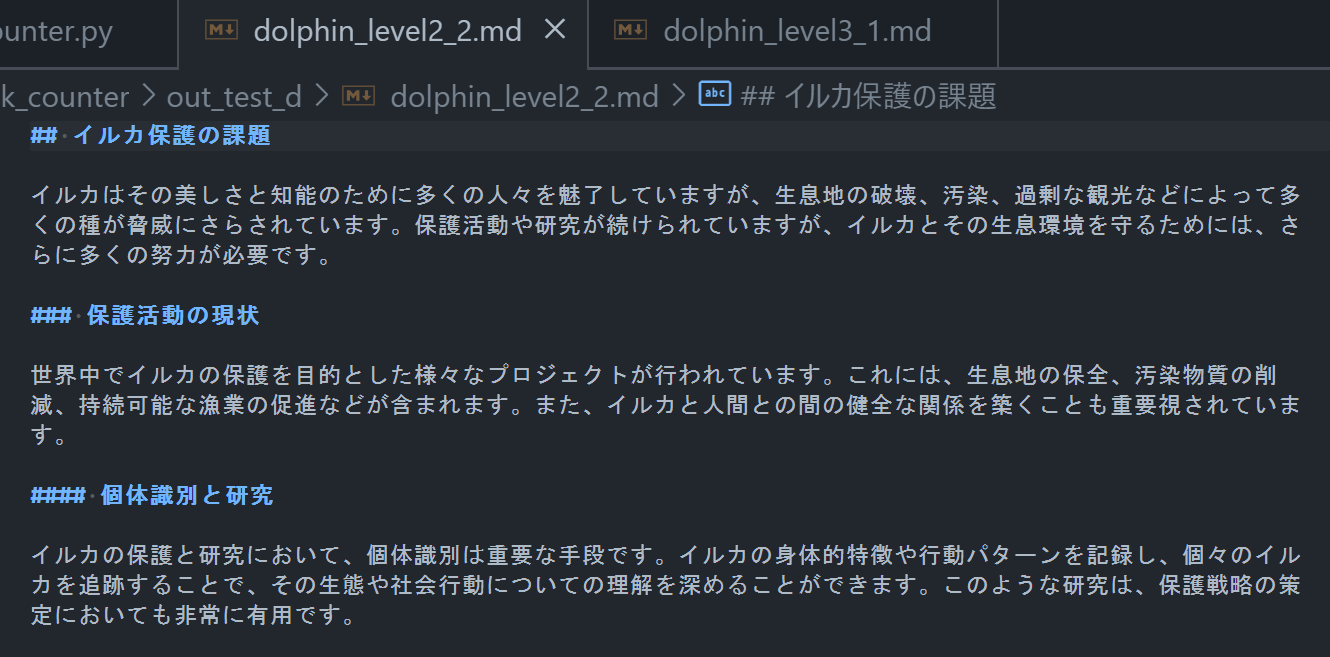
## イルカ保護の課題
イルカはその美しさと知能のために多くの人々を魅了していますが、生息地の破壊、汚染、過剰な観光などによって多くの種が脅威にさらされています。保護活動や研究が続けられていますが、イルカとその生息環境を守るためには、さらに多くの努力が必要です。
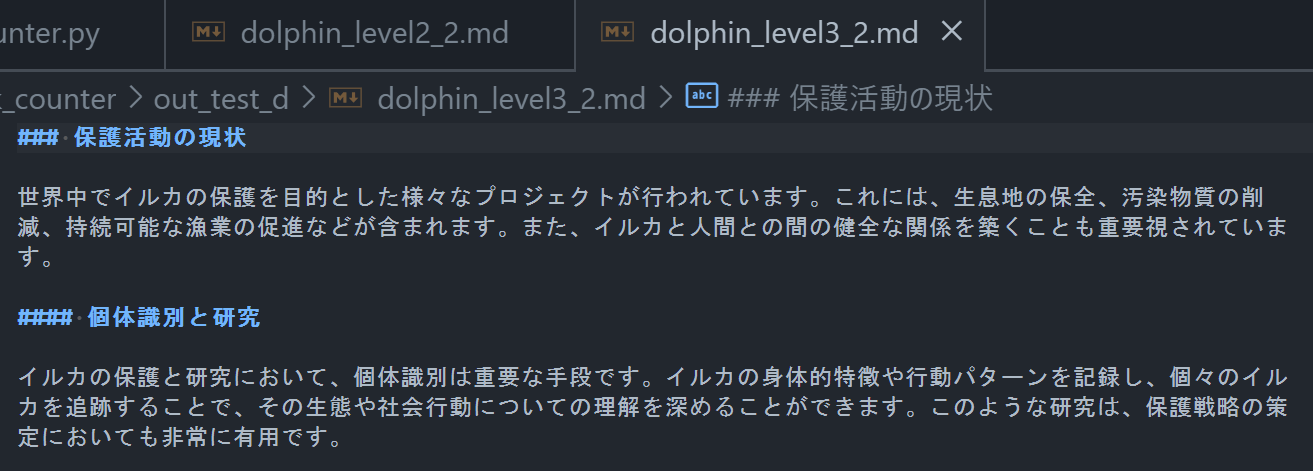
### 保護活動の現状
世界中でイルカの保護を目的とした様々なプロジェクトが行われています。これには、生息地の保全、汚染物質の削減、持続可能な漁業の促進などが含まれます。また、イルカと人間との間の健全な関係を築くことも重要視されています。
#### 個体識別と研究
イルカの保護と研究において、個体識別は重要な手段です。イルカの身体的特徴や行動パターンを記録し、個々のイルカを追跡することで、その生態や社会行動についての理解を深めることができます。このような研究は、保護戦略の策定においても非常に有用です。
## 結論
イルカはその知性と美しさで人々を魅了し続けていますが、私たちは彼らを保護するために積極的な行動を取る必要があります。科学研究、保護活動、そして日々の意識改革を通じて、イルカと人類が共存する未来を実現させることが大切です。
スクリプト
in_folder_path と out_folder_path で指定しているフォルダを事前に作成したうえでスクリプトを実行すると、入力フォルダ中の各 Markdown ファイルが解析されてレベル別にチャンキングされた Markdown ファイルが出力フォルダに書き出されます。また、解析結果をまとめたサマリの CSV ファイルがスクリプトと同じディレクトリに出力されます。
import csv
import os
import re
import tiktoken
in_folder_path = './data' # mdファイルが含まれるフォルダのパス
out_folder_path = './out' # 分割後のmdファイルを書き出すフォルダのパス (事前作成しておく)
model_encoding = 'cl100k_base' # gpt-35-turbo以降のモデルではこれが使われている
summary_file_path = './summary.csv' # 書き出すサマリファイルのパス
field_names = ['original_file', 'split_file', 'level', 'char_count', 'token_count'] # サマリファイルのヘッダ
def count_tokens(text):
"""テキストのトークン数を数える"""
encoding = tiktoken.get_encoding(model_encoding)
token_integers = encoding.encode(text)
num_tokens = len(token_integers)
return num_tokens
def write_each_level_to_file(original_file_name, out_folder_path, content, summary_file_path=None):
"""レベルごとに分割したmdファイルを書き出す"""
base_name, _ = os.path.splitext(original_file_name)
for k,vlist in content.items():
# レベルごとにループ
for i,v in enumerate(vlist, start=1):
out_file_name = f"{base_name}_level{k}_{i}.md"
out_file_path = os.path.join(out_folder_path, out_file_name)
with open(out_file_path, 'w', encoding='utf-8') as file:
file.write(v)
if summary_file_path:
# サマリファイルに書き込む
row = {
'original_file': original_file_name, # 元ファイル名
'split_file': out_file_name, # 分割後ファイル名 ({元のファイル名}_level{レベル}_{連番}.md)
'level': k, # mdのレベル
'char_count': len(v), # 文字数
'token_count': count_tokens(v) # トークン数
}
with open(summary_file_path, 'a', newline='') as file:
writer = csv.DictWriter(file, fieldnames=field_names)
writer.writerow(row)
def main():
with open(summary_file_path, 'w', newline='') as file:
# サマリファイルのヘッダを書き込む
writer = csv.DictWriter(file, fieldnames=field_names)
writer.writeheader()
for filename in os.listdir(in_folder_path):
# フォルダ内の各mdファイルを読み込んでレベルごとに分割して書き出す
file_path = os.path.join(in_folder_path, filename)
if not os.path.isfile(file_path):
# もしナンセンスなファイルパスの場合はスキップ
continue
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines() # ToDo: ファイルが大きい場合はメモリを食いすぎるので行ごとに処理するように変更する
content = {0: [], 1: [], 2: [], 3: [], 4: [], 5: []} # レベル別データ格納用リスト
level_count = {0: 0, 1: 0, 2: 0, 3: 0, 4: 0, 5: 0} # デバッグ用
current_level = 0
content[0].append('')
for line in lines:
# レベル切り替わりの判定
if re.match(r'^#\s', line): # level 1
level_count[1] += 1
current_level = 1
content[1].append('')
elif re.match(r'^##\s', line): # level 2
level_count[2] += 1
current_level = 2
content[2].append('')
elif re.match(r'^###\s', line): # level 3
level_count[3] += 1
current_level = 3
content[3].append('')
elif re.match(r'^####\s', line): # level 4
level_count[4] += 1
current_level = 4
content[4].append('')
elif re.match(r'^#####\s', line): # level 5
level_count[5] += 1
current_level = 5
content[5].append('')
# 現在のレベルに応じて行データをリストに格納 (現在のレベル以上の全てのレベルに格納)
if current_level == 1:
for i in range(1, -1, -1):
content[i][len(content[i]) -1] = content[i][len(content[i]) -1] + line
if current_level == 2:
for i in range(2, -1, -1):
content[i][len(content[i]) -1] = content[i][len(content[i]) -1] + line
if current_level == 3:
for i in range(3, -1, -1):
content[i][len(content[i]) -1] = content[i][len(content[i]) -1] + line
if current_level == 4:
for i in range(4, -1, -1):
content[i][len(content[i]) -1] = content[i][len(content[i]) -1] + line
if current_level == 5:
for i in range(5, -1, -1):
content[i][len(content[i]) -1] = content[i][len(content[i]) -1] + line
# レベルごとに分割したmdファイルとサマリファイルを書き出す
write_each_level_to_file(filename, out_folder_path, content, summary_file_path=summary_file_path)
if __name__ == '__main__':
main()
参考
出力データ
レベル別にチャンキングされた Markdown ファイル
level0 は入力ファイルと as-is のファイルです。以降、level1、level2 と各レベル別にチャンキングした場合のファイルがそれぞれ出力されます。

レベル 2 でチャンキングした場合の例
レベル 3 でチャンキングした場合の例
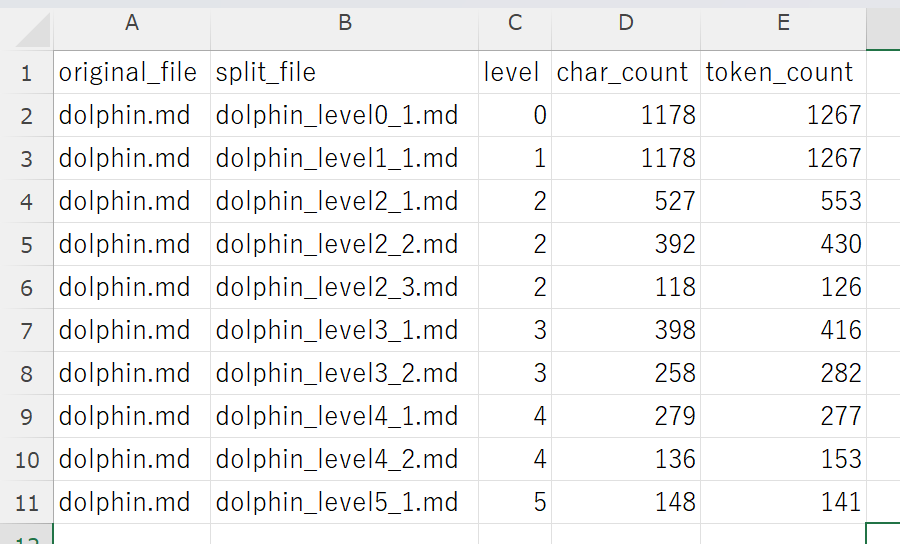
サマリファイル
各レベルでチャンキングをした場合の文字数とトークン数の一覧です。
おわりに
以上です。🍵

Discussion