基本的なおさらいになりますが、クエリのパラメーターとテーブルのデータ型を一致させておくことの重要性について改めてまとめておきたいと思います。
どんな話?
SQL Server に対してアプリケーションからクエリを発行する際、パラメーターのデータ型が、テーブルのカラムのデータ型と一致していないのを見かけることがあります。基本的なことですが 「クエリのパラメーターのデータ型とテーブルのカラムのデータ型は一致させておいた方がいいですよ(必須)」 というお話です。
異なるデータ型の比較
SQL Server では、異なるデータ型を比較する時に、明示的な変換が行われていない場合、下記のリンクにあるデータ型の優先順位に従って、どちらかのデータを暗黙的に変換して、比較することになります。
「暗黙的にやってくれるなら問題ないんじゃ?」と思うかもしれませんが、実は大きな影響があります。比較の際は、上記のルールに従って一方のデータを変換することになります。その為、以下の様なパラメーター側のデータ型の方が優先順位が高いパターンでは、 テーブル側のデータを変換する という動作が発生します。この組み合わせは一例ですが、一番見かける組み合わせになります。
クエリのパラメーターのデータ型: Unicode 型(nchar/nvarchar)
テーブルのカラムのデータ型:非 Unicode 型(char/varchar)
テーブルのデータを変換して比較するため、そこにインデックスが作成されていても、効率的に使用することは出来ません(非 Unicode 型で並び替えられてるわけですしね)。この辺りの実際の動作は後ほど説明しますが、効率的にインデックスが使用できない状態なので、当然パフォーマンスに影響が発生することになります。
「では、逆のパターンならいいの?」という疑問も出るかと思います。以下の様な感じですね。
クエリのパラメーターのデータ型:非 Unicode 型(char/varchar)
テーブルのカラムのデータ型: Unicode 型(nchar/nvarchar)
この場合は、クエリのパラメーターの方を暗黙的に変換して、デーブルのデータと比較することになります。パラメーターだけ変換すれば、インデックスは使用できますし、最初のパターンに比べて影響度は低いと言えますが、余計なオーバーヘッドであることは間違いありません[1]。
ということで、 「クエリのパラメーターのデータ型とテーブルのカラムのデータ型は一致させておいた方がいいですよ(必須)」 ということになるわけです。
これ以降は、動作の説明なので、 「オッケー、もうわかった」 という方は、読む必要はありませんので、お時間のある方だけお読みいただければと.....。
ちょっとだけ動作確認
テーブル側のデータを変換するパターンの動作を、ちょっとだけ確認しておこうと思います。テスト用に非 Unicode 型の文字列カラムを持つテーブルを作成して、適当なデータを作成しておきます。
create table paramtest(
c1 char(5) not null,
c2 char(5) not null,
c3 char(5),
c4 char(200),
c5 int
constraint pk_paramtest primary key(c1 ,c2)
)
まずは、データ型が一致してるパラメーターを指定してクエリを実行して、実際の実行プランと STATISTICS TIME と IO の情報を確認して見ましょう。
set statistics time on
set statistics io on
go
sp_executesql N'select * from paramtest where c1=@p1 and c2 = @p2',N'@p1 char(5),@p2 char(5)',@p1='9',@p2='4'
go
set statistics time off
set statistics io off
実際の実行プランでは、PK として作成したクラスタ化インデックスを Seek 操作していることが確認できます。

論理読み取り数も 2 で、クエリの実行時間は 3 ミリ秒程度と、最小限のリソース消費でクエリの実行が短時間で終わってることが確認できます。
テーブル 'paramtest'。スキャン数 0、論理読み取り数 2、物理読み取り数 0、ページ サーバー読み取り数 0、先読みの読み取り数 0、ページ サーバー先読みの読み取り数 0、LOB 論理読み取り数 0、LOB 物理読み取り数 0、LOB ページ サーバー読み取り数 0、LOB 先読みの読み取り数 0、LOB ページ サーバー先読みの読み取り数 0。
SQL Server 実行時間:
、CPU 時間 = 0 ミリ秒、経過時間 = 3 ミリ秒。
では、パラメーターを Unicode 型にした場合はどうなるか見てみましょう。
set statistics time on
set statistics io on
go
sp_executesql N'select * from paramtest where c1=@p1 and c2 = @p2',N'@p1 nchar(5),@p2 nchar(5)',@p1=N'9',@p2=N'4'
go
set statistics time off
set statistics io off
上記のクエリを実行した際の実際の実行プランは、下記となります。先ほどとは形が異なり、何やら値を生成してから、クラスタ化インデックスを Seek しています。
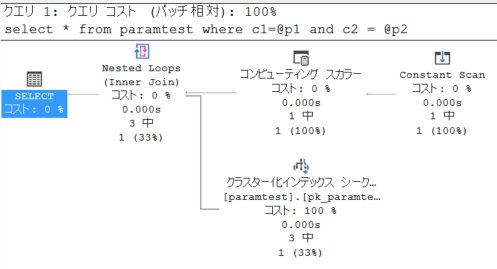
論理読み取り数や、実行時間も伸びていることが確認できます。
テーブル 'paramtest'。スキャン数 1、論理読み取り数 3、物理読み取り数 0、ページ サーバー読み取り数 0、先読みの読み取り数 0、ページ サーバー先読みの読み取り数 0、LOB 論理読み取り数 0、LOB 物理読み取り数 0、LOB ページ サーバー読み取り数 0、LOB 先読みの読み取り数 0、LOB ページ サーバー先読みの読み取り数 0。
SQL Server 実行時間:
、CPU 時間 = 0 ミリ秒、経過時間 = 99 ミリ秒。
「何をしているのか?」というと、テーブル側のデータを変換しなければならない状況ですが、全てのデータを変換するのではなく、対象データのありそうな範囲を特定して、その部分のデータを変換して比較するという動作を行っています。このために、GetRangeThroughConvert 関数という関数を利用して、範囲を絞るという工夫をしています[2]。この関数が使用されているかは、実行プランを XML 表示にすることで確認できます。
<ScalarOperator ScalarString="GetRangeThroughConvert([@p1],[@p1],(62))">
<Intrinsic FunctionName="GetRangeThroughConvert">
<ScalarOperator>
<Identifier>
<ColumnReference Column="@p1" />
</Identifier>
</ScalarOperator>
<ScalarOperator>
<Identifier>
<ColumnReference Column="@p1" />
</Identifier>
</ScalarOperator>
<ScalarOperator>
<Const ConstValue="(62)" />
</ScalarOperator>
ということで、テーブル側のデータを変換するパターンでは、SQL Server は工夫してなるべくリソースの消費を抑えてクエリの実行をしようとしていますが、やはりオーバーヘッドは多いんだなぁということをご理解いただけたのではないかと思います。
結論
「クエリのパラメーターのデータ型とテーブルのカラムのデータ型は一致させておいた方がいいですよ(必須)」 という結論(3回ちゃんと書いた)。
-
例に挙げている 非 Unicode 型/Unicode 型のパターンでは、そこまで影響はありませんが、クエリパラメーターが Int 型とかだと統計情報が使用できないので、影響が大きくなります。実行プランを確認すると、「式 (CONVERT_IMPLICIT(int,[hoge].[dbo].[hogehoge].[c2],0)) の型変換は、クエリ プランの選択の "CardinalityEstimate" に影響する可能性があります。, 式 (CONVERT_IMPLICIT(int,[hoge].[dbo].[hogehoge].[c2],0)=[@p1]) の型変換は、クエリ プランの選択の "SeekPlan" に影響する可能性があります。」といった警告が確認出来るパターンです。 ↩︎
-
大昔のバージョンでは問答無用に全件変換してたので、パフォーマンスへの影響がもろに出てました。 ↩︎

Discussion