はじめに
2023 年 6 月の Data + AI Summit で発表された English SDK for Apache Spark (pyspark-ai) の概要と、Azure Databricks で pyspark-ai のエンジンに Azure OpenAI Service を指定してデータ分析を行う方法をまとめました。
English SDK for Apache Spark (pyspark-ai) とは
概要
English SDK for Apache Spark (pyspark-ai) は Spark 開発をアシストしてくれる、Copilot 的なオープンソースのツールです。PySpark 経由で自然言語のプロンプトを与えることにより以下のような操作を手伝ってくれます。
- Spark DataFrame に対するデータ操作 (プロンプトを Spark SQL に変換して実行)
- Spark DataFrame のプロット (プロンプトを Plotly を使った Python コードに変換して実行)
- ユーザー定義関数 (UDF) の生成
pyspark-ai は LangChain を使って実装されていて、内部的に実行されるコード生成において LangChain が対応している任意の大規模言語モデル (LLM) をエンジンとして指定することができます。
イメージ図

※ LLM に Azure OpenAI Service を指定する場合
なお、English SDK for Apache Spark という名前がついているものの、Azure OpenAI Service の gpt-35-turbo や gpt-4 のように多言語対応対応しているモデルをエンジンとして使えば英語以外のプロンプトでも指示を行うことができます。
参考
- databrickslabs/pyspark-ai (GitHub)
- Introducing English as the New Programming Language for Apache Spark
- Data + AI Summit Keynote, Thursday Part 2 - What's New with Apache Spark (YouTube)
- The English SDK for Apache Spark™ (YouTube)
想定される利用者
pyspark-ai のメインターゲットは基本的な Python のコードは書けるものの Spark DataFrame 操作に慣れていないデータ分析従事者です。個々人のスキルセットに依存するため一概には言えませんが、データサイエンティストが Spark 上で探索的データ分析 (EDA) を行うような状況が最もハマる使い方な印象です。
GitHub Copilot との使い分け
いちおう GitHub Copilot との比較ポイントをまとめてみましたが、単純に Spark DataFrame を Databricks ノートブック環境で扱う場合は pyspark-ai、それ以外の一般的なコーディングであれば GitHub Copilot という使い分けで良いと思います。
| pyspark-ai | GitHub Copilot | |
|---|---|---|
| コード実行 | Yes (コード生成 & 実行して結果を返す) | No (コード生成のみ) |
| 開発環境 | Databricks ノートブックからの利用を想定 | IDE や コードエディタからの利用を想定 |
| DataFrame スキーマとの整合性 | Yes (与えた DataFrame のスキーマに基づいてコードが生成される) | No (直前のコードやコメントに基づいてコードが生成される) |
参考
ChatGPT Code Interpreter との使い分け
pyspark-ai と同じくコード生成と実行の両方を行ってくれる ChatGPT Code Interpreter とも比較ポイントをまとめてみましたが、こちらは単純に 対象データサイズによる使い分け で良いと思います。 また、pyspark-ai はノートブックによる Spark 開発が前提になりますので、必然的に利用者はコードを書ける必要があります。
| pyspark-ai | ChatGPT Code Interpreter | |
|---|---|---|
| 扱えるデータサイズ | 仕様上の上限なし (コードを実行する Spark クラスターサイズ次第) | 仕様は明確に公開されていないが、数 100 MB ~ 1 GB 程度のデータサイズが上限だと言われている |
| 前提となるスキル | Python のコーディングスキル | なし (自然言語のプロンプトのみで利用可能) |
使い方
0. 前提
以下が準備されていること。
- Azure OpenAI Service のリソース
- Azure Databricks (任意の価格レベル) のリソース
参考
- Azure OpenAI Service リソースを作成してデプロイする
- Azure OpenAI Service の価格
- portal を使用して Azure Databricks ワークスペースを作成する
- Azure Databricks の価格
- Databricks ご利用料金 - 各機能ページの "クラウドを選択" で "Azure" を選択する
1. Azure OpenAI Service モデルデプロイ
pyspark-ai が使うエンジンとして Azure OpenAI Service にて Chat Completions モデルをデプロイしておく必要があります。本記事では GPT-4 (gpt-4) をデプロイして検証しました。GPT-4 を利用する場合は Azure OpenAI Service の利用申請に加えて GPT-4 の利用申請が必要です。
参考
2. Azure Databricks クラスター作成
Azure Databricks にて任意のサイズのクラスターを作成します。本記事ではランタイムとして 12.2 LTS (includes Apache Spark 3.3.2, Scala 2.12) を選択しました。
参考
3. pyspark-ai インストール
新規ノートブックを事前に作成したクラスターにアタッチしたら pyspark-ai をインストールします。
%pip install pyspark-ai
4. 環境変数設定
前述のとおり pyspark-ai は LangChain を使って実装されています。そのため、LangChain が Azure OpenAI Service を呼ぶ際に必要な環境変数を事前に設定しておきます。<your-aoai-key> と <your-aoai-resource-name> はそれぞれ Azure OpenAI Service のキーとリソース名と置き換えます。
import os
os.environ["OPENAI_API_TYPE"] = "azure"
os.environ["OPENAI_API_KEY"] = "<your-aoai-key>"
os.environ["OPENAI_API_BASE"] = "https://<your-aoai-resource-name>.openai.azure.com"
os.environ["OPENAI_API_VERSION"] = "2023-05-15"
参考
5. セットアップ
以下のコードを実行すると pyspark-ai のエンジンとして事前にデプロイした gpt-4 が設定されます。<your-deployment-name> は gpt-4 のデプロイ名と置き換えます。
from langchain.chat_models import AzureChatOpenAI
from pyspark_ai import SparkAI
llm = AzureChatOpenAI(
deployment_name="<your-deployment-name>",
temperature=0 # 生成結果を安定させるために 0 に設定
)
spark_ai = SparkAI(llm=llm)
spark_ai.activate()
6. サンプルデータロード
Azure Databricks ワークスペースに最初から含まれていて最もお手軽に使える New York Taxi データセットを使います。
df = spark.read.table("samples.nyctaxi.trips")
df.show()
+--------------------+---------------------+-------------+-----------+----------+-----------+
|tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip|
+--------------------+---------------------+-------------+-----------+----------+-----------+
| 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171|
| 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110|
| 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023|
| 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017|
| 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282|
| 2016-02-05 06:45:02| 2016-02-05 06:50:26| 1.8| 7.0| 10009| 10065|
| 2016-02-15 15:03:28| 2016-02-15 15:18:45| 2.58| 12.0| 10153| 10199|
| 2016-02-25 19:09:26| 2016-02-25 19:24:50| 1.4| 11.0| 10112| 10069|
| 2016-02-13 16:28:18| 2016-02-13 16:36:36| 1.21| 7.5| 10023| 10153|
| 2016-02-14 00:03:48| 2016-02-14 00:10:24| 0.6| 6.0| 10012| 10003|
| 2016-02-27 15:02:58| 2016-02-27 15:08:31| 2.02| 8.0| 10002| 11211|
| 2016-02-17 07:52:40| 2016-02-17 08:01:21| 1.5| 8.0| 10019| 10199|
| 2016-02-14 21:55:55| 2016-02-14 22:01:31| 0.93| 6.0| 10019| 10018|
| 2016-02-05 22:27:07| 2016-02-05 22:39:44| 2.34| 10.5| 10110| 10014|
| 2016-02-05 09:51:47| 2016-02-05 09:57:27| 0.91| 5.5| 10119| 10199|
| 2016-02-21 11:15:39| 2016-02-21 11:40:24| 11.6| 33.5| 10019| 11371|
| 2016-02-23 13:20:29| 2016-02-23 13:36:25| 1.4| 11.0| 10018| 10022|
| 2016-02-24 13:07:46| 2016-02-24 13:26:13| 2.43| 13.0| 10065| 10119|
| 2016-02-22 15:12:53| 2016-02-22 15:22:59| 1.2| 8.0| 10001| 10009|
| 2016-02-05 09:40:07| 2016-02-05 09:49:09| 1.3| 7.5| 10003| 10013|
+--------------------+---------------------+-------------+-----------+----------+-----------+
only showing top 20 rows
7. データ操作
7.1. データの説明
ここからは実際に pyspark-ai を使っていきます。explain() メソッドを使うことで、Spark DataFrame の概要を自然言語で説明してくれます。
df.ai.explain()
Out[4]: 'In summary, this dataframe is retrieving all columns from the `trips` table in the `nyctaxi` database under `samples`. The columns include pickup and dropoff datetime, trip distance, fare amount, and the zip codes of pickup and dropoff locations.'
7.2. レコード件数確認
transform() メソッドを使うことで Spark DataFrame に対する操作を行うことができます。pyspark-ai は内部的には以下のような処理を行います。
- 与えられた DataFrame に対する TempView を作成する
- プロンプトから Spark SQL を生成する
- 生成した Spark SQL を実行して結果の DataFrame を返す
以下の例では簡単なプロンプトを与えてレコード件数を確認しています。
df.ai.transform("Count records.").show()
出力には生成、実行された Spark SQL が含まれます。
INFO: Creating temp view for the transform:
df.createOrReplaceTempView("spark_ai_temp_view_c036bd")
> Entering new AgentExecutor chain...
Final Answer: SELECT COUNT(*) FROM spark_ai_temp_view_c036bd
> Finished chain.
INFO: SQL query:
SELECT COUNT(*) FROM spark_ai_temp_view_c036bd
+--------+
|count(1)|
+--------+
| 21932|
+--------+
[補足] プロンプトの言語について
今回エンジンとして使っている gpt-4 はマルチリンガルモデルであるため日本語などの英語以外の言語で指示を行うこともできますが、一般的に英語のプロンプトを与えた場合が最もコード生成のクオリティが高いと言われているため、本記事では英語のプロンプトで指示を行っています。(日本語では稀に生成されたコードが実行できずエラーが発生することがありました。)
df.ai.transform("レコードを数えてください。").show()
7.3. 列の追加
pickup_datetime (乗車時間) と dropoff_datetime (降車時間) をもとに、乗車時間の列を追加します。
# 訳: trip minutes列を追加してください。有効数字は2桁にしてください。
df_triptime = df.ai.transform("Add trip minutes column. Round to two significant digits.")
df_triptime.show()
trip_minutes (乗車時間) が追加された DataFrame が返されます。
INFO: Creating temp view for the transform:
df.createOrReplaceTempView("spark_ai_temp_view_6056c5")
> Entering new AgentExecutor chain...
Thought: I can calculate the trip minutes by subtracting the pickup time from the dropoff time and converting the result to minutes. I will use the ROUND function to round the result to two significant digits.
Action: query_validation
Action Input: SELECT *, ROUND((UNIX_TIMESTAMP(tpep_dropoff_datetime) - UNIX_TIMESTAMP(tpep_pickup_datetime))/60, 2) AS trip_minutes FROM spark_ai_temp_view_6056c5
Observation: OK
Thought:I now know the final answer.
Final Answer: SELECT *, ROUND((UNIX_TIMESTAMP(tpep_dropoff_datetime) - UNIX_TIMESTAMP(tpep_pickup_datetime))/60, 2) AS trip_minutes FROM spark_ai_temp_view_6056c5
> Finished chain.
INFO: SQL query:
SELECT *, ROUND((UNIX_TIMESTAMP(tpep_dropoff_datetime) - UNIX_TIMESTAMP(tpep_pickup_datetime))/60, 2) AS trip_minutes FROM spark_ai_temp_view_6056c5
+--------------------+---------------------+-------------+-----------+----------+-----------+------------+
|tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip|trip_minutes|
+--------------------+---------------------+-------------+-----------+----------+-----------+------------+
| 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| 23.85|
| 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| 1.68|
| 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| 3.97|
| 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| 5.63|
| 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| 17.18|
| 2016-02-05 06:45:02| 2016-02-05 06:50:26| 1.8| 7.0| 10009| 10065| 5.4|
| 2016-02-15 15:03:28| 2016-02-15 15:18:45| 2.58| 12.0| 10153| 10199| 15.28|
| 2016-02-25 19:09:26| 2016-02-25 19:24:50| 1.4| 11.0| 10112| 10069| 15.4|
| 2016-02-13 16:28:18| 2016-02-13 16:36:36| 1.21| 7.5| 10023| 10153| 8.3|
| 2016-02-14 00:03:48| 2016-02-14 00:10:24| 0.6| 6.0| 10012| 10003| 6.6|
| 2016-02-27 15:02:58| 2016-02-27 15:08:31| 2.02| 8.0| 10002| 11211| 5.55|
| 2016-02-17 07:52:40| 2016-02-17 08:01:21| 1.5| 8.0| 10019| 10199| 8.68|
| 2016-02-14 21:55:55| 2016-02-14 22:01:31| 0.93| 6.0| 10019| 10018| 5.6|
| 2016-02-05 22:27:07| 2016-02-05 22:39:44| 2.34| 10.5| 10110| 10014| 12.62|
| 2016-02-05 09:51:47| 2016-02-05 09:57:27| 0.91| 5.5| 10119| 10199| 5.67|
| 2016-02-21 11:15:39| 2016-02-21 11:40:24| 11.6| 33.5| 10019| 11371| 24.75|
| 2016-02-23 13:20:29| 2016-02-23 13:36:25| 1.4| 11.0| 10018| 10022| 15.93|
| 2016-02-24 13:07:46| 2016-02-24 13:26:13| 2.43| 13.0| 10065| 10119| 18.45|
| 2016-02-22 15:12:53| 2016-02-22 15:22:59| 1.2| 8.0| 10001| 10009| 10.1|
| 2016-02-05 09:40:07| 2016-02-05 09:49:09| 1.3| 7.5| 10003| 10013| 9.03|
+--------------------+---------------------+-------------+-----------+----------+-----------+------------+
only showing top 20 rows
7.4. 基礎統計量の計算
最低値、最大値、平均値、標準偏差、尖度、歪度などの基礎統計量を計算します。
# 訳: trip_distance、fare_amount、trip_minutes列に対してEDAを行ってください。各列に対して最低値、最大値、平均値、標準偏差、尖度、歪度を計算してください。
df_basic_stats = df_triptime.ai.transform("Perform EDA on trip_distance, fare_amount and trip_minutes. Show minumum, maximum, average, standard deviation, skewness and kurtosis for each column.")
df_basic_stats.show()
INFO: Creating temp view for the transform:
df.createOrReplaceTempView("spark_ai_temp_view_b381fe")
> Entering new AgentExecutor chain...
Thought: I will use the MIN, MAX, AVG, STDDEV, SKEWNESS and KURTOSIS functions to perform the EDA on the specified columns.
Action: query_validation
Action Input: SELECT MIN(trip_distance) AS min_trip_distance, MAX(trip_distance) AS max_trip_distance, AVG(trip_distance) AS avg_trip_distance, STDDEV(trip_distance) AS stddev_trip_distance, SKEWNESS(trip_distance) AS skewness_trip_distance, KURTOSIS(trip_distance) AS kurtosis_trip_distance, MIN(fare_amount) AS min_fare_amount, MAX(fare_amount) AS max_fare_amount, AVG(fare_amount) AS avg_fare_amount, STDDEV(fare_amount) AS stddev_fare_amount, SKEWNESS(fare_amount) AS skewness_fare_amount, KURTOSIS(fare_amount) AS kurtosis_fare_amount, MIN(trip_minutes) AS min_trip_minutes, MAX(trip_minutes) AS max_trip_minutes, AVG(trip_minutes) AS avg_trip_minutes, STDDEV(trip_minutes) AS stddev_trip_minutes, SKEWNESS(trip_minutes) AS skewness_trip_minutes, KURTOSIS(trip_minutes) AS kurtosis_trip_minutes FROM spark_ai_temp_view_b381fe
Observation: OK
Thought:I now know the final answer.
Final Answer: SELECT MIN(trip_distance) AS min_trip_distance, MAX(trip_distance) AS max_trip_distance, AVG(trip_distance) AS avg_trip_distance, STDDEV(trip_distance) AS stddev_trip_distance, SKEWNESS(trip_distance) AS skewness_trip_distance, KURTOSIS(trip_distance) AS kurtosis_trip_distance, MIN(fare_amount) AS min_fare_amount, MAX(fare_amount) AS max_fare_amount, AVG(fare_amount) AS avg_fare_amount, STDDEV(fare_amount) AS stddev_fare_amount, SKEWNESS(fare_amount) AS skewness_fare_amount, KURTOSIS(fare_amount) AS kurtosis_fare_amount, MIN(trip_minutes) AS min_trip_minutes, MAX(trip_minutes) AS max_trip_minutes, AVG(trip_minutes) AS avg_trip_minutes, STDDEV(trip_minutes) AS stddev_trip_minutes, SKEWNESS(trip_minutes) AS skewness_trip_minutes, KURTOSIS(trip_minutes) AS kurtosis_trip_minutes FROM spark_ai_temp_view_b381fe
> Finished chain.
INFO: SQL query:
SELECT MIN(trip_distance) AS min_trip_distance, MAX(trip_distance) AS max_trip_distance, AVG(trip_distance) AS avg_trip_distance, STDDEV(trip_distance) AS stddev_trip_distance, SKEWNESS(trip_distance) AS skewness_trip_distance, KURTOSIS(trip_distance) AS kurtosis_trip_distance, MIN(fare_amount) AS min_fare_amount, MAX(fare_amount) AS max_fare_amount, AVG(fare_amount) AS avg_fare_amount, STDDEV(fare_amount) AS stddev_fare_amount, SKEWNESS(fare_amount) AS skewness_fare_amount, KURTOSIS(fare_amount) AS kurtosis_fare_amount, MIN(trip_minutes) AS min_trip_minutes, MAX(trip_minutes) AS max_trip_minutes, AVG(trip_minutes) AS avg_trip_minutes, STDDEV(trip_minutes) AS stddev_trip_minutes, SKEWNESS(trip_minutes) AS skewness_trip_minutes, KURTOSIS(trip_minutes) AS kurtosis_trip_minutes FROM spark_ai_temp_view_b381fe
+-----------------+-----------------+------------------+--------------------+----------------------+----------------------+---------------+---------------+------------------+------------------+--------------------+--------------------+----------------+----------------+------------------+-------------------+---------------------+---------------------+
|min_trip_distance|max_trip_distance| avg_trip_distance|stddev_trip_distance|skewness_trip_distance|kurtosis_trip_distance|min_fare_amount|max_fare_amount| avg_fare_amount|stddev_fare_amount|skewness_fare_amount|kurtosis_fare_amount|min_trip_minutes|max_trip_minutes| avg_trip_minutes|stddev_trip_minutes|skewness_trip_minutes|kurtosis_trip_minutes|
+-----------------+-----------------+------------------+--------------------+----------------------+----------------------+---------------+---------------+------------------+------------------+--------------------+--------------------+----------------+----------------+------------------+-------------------+---------------------+---------------------+
| 0.0| 30.6|2.8528291993434225| 3.4399536210623523| 2.9481979314980196| 9.883741567944265| -8.0| 275.0|12.348726974284153|10.327887859233357| 4.046665866270324| 46.316478092854304| 0.0| 1438.85|15.116011307678296| 52.84315453644745| 25.259522197097617| 662.9053824614193|
+-----------------+-----------------+------------------+--------------------+----------------------+----------------------+---------------+---------------+------------------+------------------+--------------------+--------------------+----------------+----------------+------------------+-------------------+---------------------+---------------------+
7.5. データの確認
verify() メソッドを使うことで、データの確認を行うことができます。結果は True か False で返されます。
# 訳: tpep_pickup_datetimeとtpep_dropoff_datetimeがdatetime型であることを期待しています。
df_triptime.ai.verify("Expect the pickup and dropoff are datetime data type.")
出力には確認に使われた Python コードが含まれます。結果は True ですので期待どおりのようです。
INFO: LLM Output:
def check_datetime(df) -> bool:
from pyspark.sql.types import TimestampType
# Get the data type of pickup and dropoff columns
pickup_type = df.schema["tpep_pickup_datetime"].dataType
dropoff_type = df.schema["tpep_dropoff_datetime"].dataType
# Check if the data types are datetime
if isinstance(pickup_type, TimestampType) and isinstance(dropoff_type, TimestampType):
return True
else:
return False
result = check_datetime(df)
INFO: Generated code:
def check_datetime(df) -> bool:
from pyspark.sql.types import TimestampType
# Get the data type of pickup and dropoff columns
pickup_type = df.schema["tpep_pickup_datetime"].dataType
dropoff_type = df.schema["tpep_dropoff_datetime"].dataType
# Check if the data types are datetime
if isinstance(pickup_type, TimestampType) and isinstance(dropoff_type, TimestampType):
return True
else:
return False
result = check_datetime(df)
INFO:
Result: True
もうひとつ、fare_amount (運賃) がゼロ以上であることを確認してもらいます。
# 訳: fare_amountがゼロ以上であることを確認してください。
df_triptime.ai.verify("Verify that fare_amount is greater than zero or equal to zero.")
運賃にマイナスの値が含まれているようです。
INFO: LLM Output:
def verify_fare_amount(df) -> bool:
from pyspark.sql.functions import col
# Check if fare_amount is greater than or equal to zero
if df.filter(col("fare_amount") < 0).count() > 0:
return False
else:
return True
result = verify_fare_amount(df)
INFO: Generated code:
def verify_fare_amount(df) -> bool:
from pyspark.sql.functions import col
# Check if fare_amount is greater than or equal to zero
if df.filter(col("fare_amount") < 0).count() > 0:
return False
else:
return True
result = verify_fare_amount(df)
INFO:
Result: False
件数を確認します。
# 訳: fare_amountがゼロ未満であるレコードを数えてください。
df_triptime.ai.transform("Count records with fare_amount less than zero.").show()
5 件運賃がゼロ未満のレコードが含まれているようです。
INFO: Creating temp view for the transform:
df.createOrReplaceTempView("spark_ai_temp_view_e7ed68")
INFO: Using cached result for the transform.
INFO: SQL query:
SELECT COUNT(*) FROM spark_ai_temp_view_e7ed68 WHERE fare_amount < 0
+--------+
|count(1)|
+--------+
| 5|
+--------+
7.6. クレンジング
5 件運賃がゼロ未満のレコードを取り除いてもらいます。
# 訳: fare_amountがゼロ未満のレコードを取り除いてください。
df_cleansed = df_triptime.ai.transform("Remove records with fare_amount less than zero.")
# 訳: fare_amountがゼロ未満であるレコードを数えてください。
df_cleansed.ai.transform("Count recrds with fare_amount less than zero.").show()
無事取り除かれたようです。
INFO: Creating temp view for the transform:
df.createOrReplaceTempView("spark_ai_temp_view_0d76f9")
> Entering new AgentExecutor chain...
Thought: I will write a query to select all records where fare_amount is greater than or equal to zero.
Action: query_validation
Action Input: SELECT * FROM spark_ai_temp_view_0d76f9 WHERE fare_amount >= 0
Observation: OK
Thought:I now know the final answer.
Final Answer: SELECT * FROM spark_ai_temp_view_0d76f9 WHERE fare_amount >= 0
> Finished chain.
INFO: SQL query:
SELECT * FROM spark_ai_temp_view_0d76f9 WHERE fare_amount >= 0
INFO: Creating temp view for the transform:
df.createOrReplaceTempView("spark_ai_temp_view_739540")
> Entering new AgentExecutor chain...
Thought: I will query the count of records where fare_amount is less than zero.
Action: query_validation
Action Input: SELECT COUNT(*) FROM spark_ai_temp_view_739540 WHERE fare_amount < 0
Observation: OK
Thought:I now know the final answer.
Final Answer: SELECT COUNT(*) FROM spark_ai_temp_view_739540 WHERE fare_amount < 0
> Finished chain.
INFO: SQL query:
SELECT COUNT(*) FROM spark_ai_temp_view_739540 WHERE fare_amount < 0
+--------+
|count(1)|
+--------+
| 0|
+--------+
クレンジング後の総レコード数を確認します。
df_cleansed.ai.transform("Count records.").show()
元は 21,932 件でしたので、5 件減っていることが分かります。
INFO: Creating temp view for the transform:
df.createOrReplaceTempView("spark_ai_temp_view_38a2bf")
> Entering new AgentExecutor chain...
Final Answer: SELECT COUNT(*) FROM spark_ai_temp_view_38a2bf
> Finished chain.
INFO: SQL query:
SELECT COUNT(*) FROM spark_ai_temp_view_38a2bf
+--------+
|count(1)|
+--------+
| 21927|
+--------+
7.7. プロット
plot() メソッドを使うことで、DataFrame のプロットを行うことができます。pyspark-ai は内部的に Plotly のコードを生成してプロットを行います。
# 訳: trip_minutesのヒストグラムを描いてください。
df_cleansed.ai.plot("Plot trip_minutes in a histogram.")
出力にはプロットに使われた Python コードが含まれます。また、コードの説明も添えられています。
INFO: Here is the Python code to visualize the result of `df` using plotly:
```
import plotly.graph_objects as go
from pyspark.sql import SparkSession
# Start Spark session
spark = SparkSession.builder.getOrCreate()
# Assuming that df is already a Spark DataFrame
df_pd = df.toPandas()
# Create a histogram
fig = go.Figure(data=[go.Histogram(x=df_pd['trip_minutes'])])
# Set layout properties
fig.update_layout(
title='Distribution of Trip Duration',
xaxis_title='Trip Duration (minutes)',
yaxis_title='Count',
bargap=0.2,
bargroupgap=0.1
)
fig.show()
```
This code first converts the Spark DataFrame `df` to a pandas DataFrame `df_pd` using the `toPandas()` method. Then it creates a histogram using the `go.Histogram` function from plotly, with the `trip_minutes` column as the x-axis. The layout of the plot is then updated with titles for the plot, x-axis, and y-axis, and the gap between bars is set. Finally, the plot is displayed using the `show()` method.
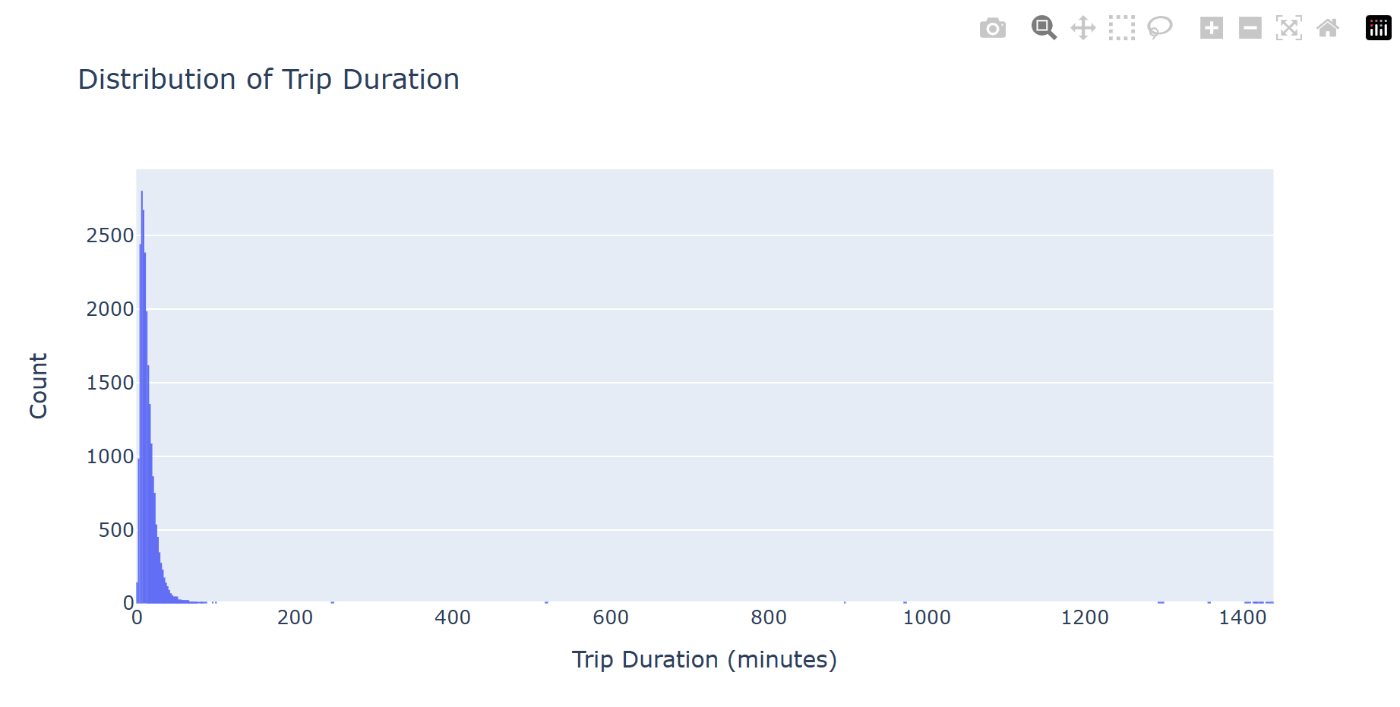
7.8. 集計
日別集計を行ってみます。
# 訳: 日別平均trip_minutesに集計してください。有効数字は2桁にしてください。日付は昇順で並べてください。
df_daily = df_cleansed.ai.transform("Summarize to average daily trip_minutes. Round to two significant digits. Sort dates in ascending order.")
INFO: Creating temp view for the transform:
df.createOrReplaceTempView("spark_ai_temp_view_57608f")
INFO: Using cached result for the transform.
INFO: SQL query:
SELECT DATE(tpep_pickup_datetime) AS Date, ROUND(AVG(trip_minutes), 2) AS Avg_Trip_Minutes FROM spark_ai_temp_view_57608f GROUP BY Date ORDER BY Date ASC
結果を確認します。
df_daily.show()
日別平均乗車時間が集計されました。
+----------+----------------+
| Date|Avg_Trip_Minutes|
+----------+----------------+
|2016-01-01| 20.14|
|2016-01-02| 28.16|
|2016-01-03| 11.02|
|2016-01-04| 11.46|
|2016-01-05| 19.85|
|2016-01-06| 12.33|
|2016-01-07| 16.93|
|2016-01-08| 17.25|
|2016-01-09| 15.67|
|2016-01-10| 15.01|
|2016-01-11| 13.01|
|2016-01-12| 12.41|
|2016-01-13| 16.68|
|2016-01-14| 17.54|
|2016-01-15| 17.76|
|2016-01-16| 16.17|
|2016-01-17| 11.12|
|2016-01-18| 13.39|
|2016-01-19| 14.35|
|2016-01-20| 15.82|
+----------+----------------+
only showing top 20 rows
7 日間の移動平均の列を追加します。
# 訳: 7日間の移動平均の列を追加してください。有効数字は2桁にしてください。日付は昇順でならべてください。
df_daily_ma = df_daily.ai.transform("Add 7 day moving average column. Round to two significant digits. Sort dates in ascending order.")
INFO: Creating temp view for the transform:
df.createOrReplaceTempView("spark_ai_temp_view_f1e3e1")
INFO: Using cached result for the transform.
INFO: SQL query:
SELECT Date, Avg_Trip_Minutes, ROUND(AVG(Avg_Trip_Minutes) OVER (ORDER BY Date ROWS BETWEEN 6 PRECEDING AND CURRENT ROW), 2) AS Moving_Average FROM spark_ai_temp_view_f1e3e1 ORDER BY Date ASC
結果を確認します。
df_daily_ma.show()
移動平均の列が追加されました。
+----------+----------------+--------------+
| Date|Avg_Trip_Minutes|Moving_Average|
+----------+----------------+--------------+
|2016-01-01| 20.14| 20.14|
|2016-01-02| 28.16| 24.15|
|2016-01-03| 11.02| 19.77|
|2016-01-04| 11.46| 17.7|
|2016-01-05| 19.85| 18.13|
|2016-01-06| 12.33| 17.16|
|2016-01-07| 16.93| 17.13|
|2016-01-08| 17.25| 16.71|
|2016-01-09| 15.67| 14.93|
|2016-01-10| 15.01| 15.5|
|2016-01-11| 13.01| 15.72|
|2016-01-12| 12.41| 14.66|
|2016-01-13| 16.68| 15.28|
|2016-01-14| 17.54| 15.37|
|2016-01-15| 17.76| 15.44|
|2016-01-16| 16.17| 15.51|
|2016-01-17| 11.12| 14.96|
|2016-01-18| 13.39| 15.01|
|2016-01-19| 14.35| 15.29|
|2016-01-20| 15.82| 15.16|
+----------+----------------+--------------+
only showing top 20 rows
最後にプロットを行います。
df_daily_ma.ai.plot("Draw a line chart.")
平均乗車時間と 7 日間の移動平均の折れ線グラフがプロットされました。
INFO: Here is the Python code to visualize the result of `df` using plotly:
```
import plotly.graph_objects as go
from pyspark.sql import SparkSession
# Start Spark session
spark = SparkSession.builder.getOrCreate()
# Convert Spark DataFrame to Pandas DataFrame
pandas_df = df.toPandas()
# Create line chart
fig = go.Figure()
# Add traces
fig.add_trace(go.Scatter(x=pandas_df['Date'], y=pandas_df['Avg_Trip_Minutes'], mode='lines', name='Avg_Trip_Minutes'))
fig.add_trace(go.Scatter(x=pandas_df['Date'], y=pandas_df['Moving_Average'], mode='lines', name='Moving_Average'))
# Set layout
fig.update_layout(title='NYC Taxi Trips: Average Trip Minutes and Moving Average', xaxis_title='Date', yaxis_title='Minutes')
# Display the plot
fig.show()
```
This code first converts the Spark DataFrame to a Pandas DataFrame, which is necessary for plotly. Then it creates a line chart with two traces: one for the average trip minutes and one for the moving average. The x-axis represents the date, and the y-axis represents the minutes. The plot is displayed directly using the `show` method.

7.9. メソッドチェーン
transform() や plot() はメソッドチェーンで呼ぶことも可能です。
df_cleansed.ai.transform("Summarize to average daily trip_minutes. Round to two significant digits. Sort dates in ascending order.").ai.transform("Add 7 day moving average column. Round to two significant digits. Sort dates in ascending order.").ai.plot("Draw a line chart.")
INFO: Creating temp view for the transform:
df.createOrReplaceTempView("spark_ai_temp_view_47a968")
INFO: Using cached result for the transform.
INFO: SQL query:
SELECT DATE(tpep_pickup_datetime) AS Date, ROUND(AVG(trip_minutes), 2) AS Avg_Trip_Minutes FROM spark_ai_temp_view_47a968 GROUP BY Date ORDER BY Date ASC
INFO: Creating temp view for the transform:
df.createOrReplaceTempView("spark_ai_temp_view_9a2ac9")
INFO: Using cached result for the transform.
INFO: SQL query:
SELECT Date, Avg_Trip_Minutes, ROUND(AVG(Avg_Trip_Minutes) OVER (ORDER BY Date ROWS BETWEEN 6 PRECEDING AND CURRENT ROW), 2) AS Moving_Average FROM spark_ai_temp_view_9a2ac9 ORDER BY Date ASC
INFO: Here is the Python code to visualize the result of `df` using plotly:
```
import plotly.graph_objects as go
from pyspark.sql import SparkSession
# Start Spark session
spark = SparkSession.builder.getOrCreate()
# Convert Spark DataFrame to Pandas DataFrame
pandas_df = df.toPandas()
# Create line chart
fig = go.Figure()
# Add traces
fig.add_trace(go.Scatter(x=pandas_df['Date'], y=pandas_df['Avg_Trip_Minutes'], mode='lines', name='Avg_Trip_Minutes'))
fig.add_trace(go.Scatter(x=pandas_df['Date'], y=pandas_df['Moving_Average'], mode='lines', name='Moving_Average'))
# Set layout
fig.update_layout(title='NYC Taxi Trips: Average Trip Minutes and Moving Average', xaxis_title='Date', yaxis_title='Minutes')
# Display the plot
fig.show()
```
This code first converts the Spark DataFrame to a Pandas DataFrame, which is necessary for plotly. Then it creates a line chart with two traces: one for the average trip minutes and one for the moving average. The x-axis represents the date, and the y-axis represents the minutes. The plot is displayed directly using the `show` method.

8. その他
8.1. ユーザー定義関数 (UDF) 生成
pyspark-ai は UDF の生成を行うことができます。関数の入出力の宣言と docstring を記述すると続きを生成します。
@spark_ai.udf
def convert_grades(grade_percent: float) -> str:
"""Convert the grade percent to a letter grade using standard cutoffs"""
...
INFO: Creating following Python UDF:
def convert_grades(grade_percent) -> str:
if grade_percent is not None:
if grade_percent >= 90:
return 'A'
elif grade_percent >= 80:
return 'B'
elif grade_percent >= 70:
return 'C'
elif grade_percent >= 60:
return 'D'
else:
return 'F'
8.2. Web 上のデータの取り込み
pyspark-ai は Web 上のデータを DataFrame に取り込むことができます。以下のようにして Web サイトの URL を指定すると、そのサイトのテキストが LLM により解析されて指定したフォーマットで DataFrame に取り込まれます。
best_albums_df = spark_ai.create_df('https://time.com/6235186/best-albums-2022/', ["album", "artist", "year"])
best_albums_df.show()
INFO: Parsing URL: https://time.com/6235186/best-albums-2022/
INFO: SQL query for the ingestion:
CREATE OR REPLACE TEMP VIEW spark_ai_temp_view_1ebd4c AS SELECT * FROM VALUES
('Motomami', 'Rosalía', 2022),
('You Can’t Kill Me', '070 Shake', 2022),
('Mr. Morale & The Big Steppers', 'Kendrick Lamar', 2022),
('Big Time', 'Angel Olsen', 2022),
('Electricity', 'Ibibio Sound Machine', 2022),
('It’s Almost Dry', 'Pusha T', 2022),
('Chloe and the Next 20th Century', 'Father John Misty', 2022),
('Renaissance', 'Beyoncé', 2022),
('19 Masters', 'Saya Gray', 2022),
('Un Verano Sin Ti', 'Bad Bunny', 2022)
AS v1(album, artist, year)
INFO: Storing data into temp view: spark_ai_temp_view_1ebd4c
+--------------------+--------------------+----+
| album| artist|year|
+--------------------+--------------------+----+
| Motomami| Rosalía|2022|
| You Can’t Kill Me| 070 Shake|2022|
|Mr. Morale & The ...| Kendrick Lamar|2022|
| Big Time| Angel Olsen|2022|
| Electricity|Ibibio Sound Machine|2022|
| It’s Almost Dry| Pusha T|2022|
|Chloe and the Nex...| Father John Misty|2022|
| Renaissance| Beyoncé|2022|
| 19 Masters| Saya Gray|2022|
| Un Verano Sin Ti| Bad Bunny|2022|
+--------------------+--------------------+----+
8.3. キャッシュ
pyspark-ai にはインメモリキャッシュ機能が含まれています。こちらに関しては細かく検証しませんでしたが、キャッシュに存在しているプロンプトを与えた場合はキャッシュの結果が再利用されるようです。以下のようにしてキャッシュへの書き込みを行います。
spark_ai.commit()
一方で、キャッシュを参照したくない場合は以下のように記述します。
df_daily_ma.ai.plot("<your-prompt>", cache=False)
おわりに
シンプルなクエリであれば自分で SQL を書いた方が早いですが、やや複雑なことを行おうとした場合はデータ分析の効率を上げることができると感じました。何より、DataFrame のスキーマを考慮したクエリを実行してくれるのがありがたいです。Spark 上でデータ分析を行う場合はぜひ pyspark-ai も活用して効率化していきたいです。
以上です。🍵

Discussion