はじめに
2022 年 8 月 から、Azure Databricks の サーバレス SQL が登録制のパブリックプレビューになっています。本記事では、Azure Databricks のサーバレス SQL に関連する概念とクイックスタートのための情報についてまとめました。
概念
Databricks SQL とは
Databrticks ワークスペースの UI は利用者のペルソナ (データチーム内での役割) に合わせて 3 種類から切り替えて使うことができます。

Databricks SQL とは、企業の事業部門に所属するデータアナリストなどの必ずしもエンジニアとしての技術的背景を持たない利用者による、SQLベースのデータ分析やダッシュボード作成などを想定しています。
Databricks には他にも下記のペルソナが存在していています。
- Data Science & Engineering: データエンジニアによるデータエンジニアリングやデータサイエンティストによるノートブックベースの探索的データ分析 (EDA) などを想定
- Machine Learning: 機械学習エンジニアによるノートブックベースの機械学習モデル開発・公開・ライフサイクル管理などを想定
なお、UI のペルソナを切り替えても Databricks ワークスペースに紐づく Azure Databricks Hive メタストアへアクセスすることができるため、データチーム内で共通のデータを見ながらコレボレーションをすることができるようになっています。
また、本記事の内容からはそれますが、Unity Catalog を 使うことにより、複数ワークスペースの間でメタストアや利用者のデータアクセスを一元管理することもできます。
SQL ウェアハウスとは
SQL ウェアハウスとは、Databricks SQL ペルソナにおけるコンピューティングを抽象化した概念です。Data Science & Engineering や Machine Learning ペルソナにおけるクラスターに相当します。SQL ウェアハウスでは、クラスターサイズとスケーリングによりコンピューティングの設定を行います。以前は SQL エンドポイントと呼ばれていましたが、Databricks 社の方針により名称が変更されました。
なお、SQL ウェアハウスでは、Databricks 社が開発した高速クエリエンジンである Photon が既定で有効化されています。
クラスターサイズ
クラスターサイズはいわゆる T シャツサイジングのような設定方法になっています。背後ではインメモリアプリケーション向けの Azure VM シリーズである Edsv4 シリーズ が使われていて、指定したクラスターサイズに応じて ドライバーノードのサイズやワーカーノード数が変わります。

スケーリング
スケーリングは、利用者から複数のクエリが投げられる状況でリクエストキュー上の予想処理時間に応じて設定した最小値と最大値に基づいて自動的にクラスター数が増減します。

自動停止
自動停止を有効にすることで、一定時間アイドル状態が続いた時に SQL ウェアハウスを自動停止することができます。
サーバレス SQL とは
サーバレス SQL とは、SQL ウェアハウスを作成する際に選択できる種類の 1 つです。Azure Databricks は Azure Portal からリソースを作成できる Microsoft Azure の 1st パーティーサービスの位置づけですが、コントロールプレーン (e.g. ワークスペースの Web UI) は Databricks 社のサブスクリプション上で構築されています。これまでも存在していたサーバレス以外の SQL ウェアハウスでは、コンピューティングリソースの実体は利用者のサブスクリプション上のマネージドリソースグループ内に存在していましたが、サーバレス SQL では、コンピューティングリソースが Databricks 社のサブスクリプション上に存在していて、PaaS というよりは Web サービス的な印象を受けます。
サーバレス SQL の最大の特徴であり長所としては、コンピューティングリソースが Databricks 社のサブスクリプション上でホットスタンバイしている点で、クエリを投げると数秒以内で SQL ウェアハウスが起動します。サーバレス以外の SQL ウェアハウスでは起動までに数分程度は待つ必要があります。
サーバレス SQL にはコスト面での長所も存在します。サーバレス SQL は Databricks Units (DBU) のみについて課金されます。サーバレス SQL の DBU は高めに設定されていますが、サーバレス以外の SQL ウェアハウスは DBU に加えて前述のクラスターサイズに応じた Azure リソース料金が発生するため[1]、結果的にサーバレス SQL はより低コストで使うことができます。
これらの長所の一方で、サーバレス SQL には短所も存在します。コンピューティングリソースが Databricks 社のサブスクリプション上に存在しているため、いわゆる閉域構成[2]を考える場合の制約が存在します。具体的には、当たり前ですが VNet Injection を行うことができず、Private Link [3] も使えません。さらに、前述の制約に関連して、利用者の任意の Azure ストレージ (e.g. Azure Data Lake Storage Gen2) に VNet から Private Endpoint 経由でアクセスすることもできません。サーバレス SQL からこうしたデータソースにアクセスしたい場合は、利用者の VNet 側で サーバレス SQL が使用している Databricks 社サブスクリプション上の VNet に対する通信を許可する必要があります。現状ではストレージから各リージョンにつき複数のサブネットにベタに通信を許可する必要あり、まだ発展途上である印象を受けます。このあたりは将来的には Azure Synapse Analytics や Azure Data Factory と同様にマネージド VNet を追加してもらえるとありがたいです。
参考
サーバーレス コンピューティングと他の Databricks アーキテクチャの比較

クイックスタート
1. サーバレス SQL の有効化
まず初めにサーバレス SQL を有効化します。プレビュー登録フォームから申請してしばらくすると ( 不定期 )、Databricks SQL の管理コンソールにチェックボックスが出現します。このチェックをオンにすると、SQL ウェアハウス作成時にサーバレス SQL を選択できるようになります。
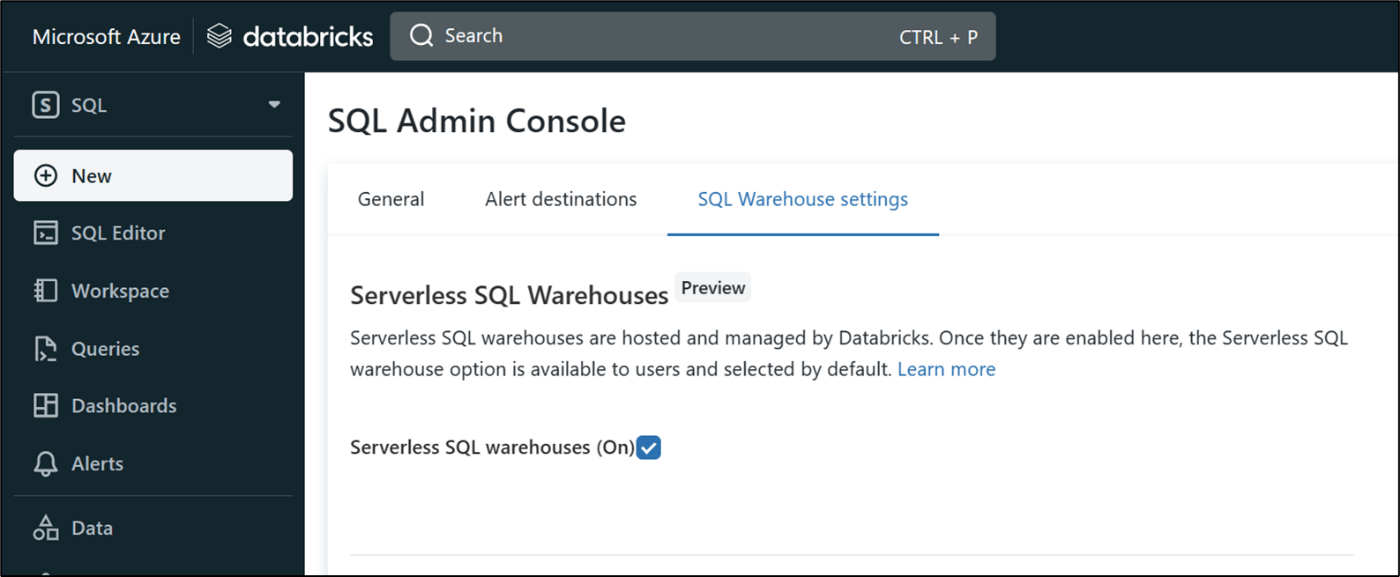
なお、サーバレス SQL を含む Databricks SQL を使う場合、ワークスペースの価格レベルは Premium を選択する必要があります。また、本記事執筆時点では米国東部 (eastus)、米国東部 2 (eastus2)、西ヨーロッパ (westeurope) リージョンのみに対応しています。その他の条件はこちらに記載されています。

2. サーバレス SQL ウェアハウスの作成
Databricks SQL ペルソナから、SQL ウェアハウスを作成します。

サーバレスを選択します。クラスターサイズは一番小さいものを選択しておきます。

3. DBFS へファイルを配置する
サーバレス SQL から既定で参照可能なワークスペースのルート DBFS 上にファイルを配置します。前述のアーキテクチャ図の赤線で囲った部分です。

参考
3.1. サンプルデータのダウンロード
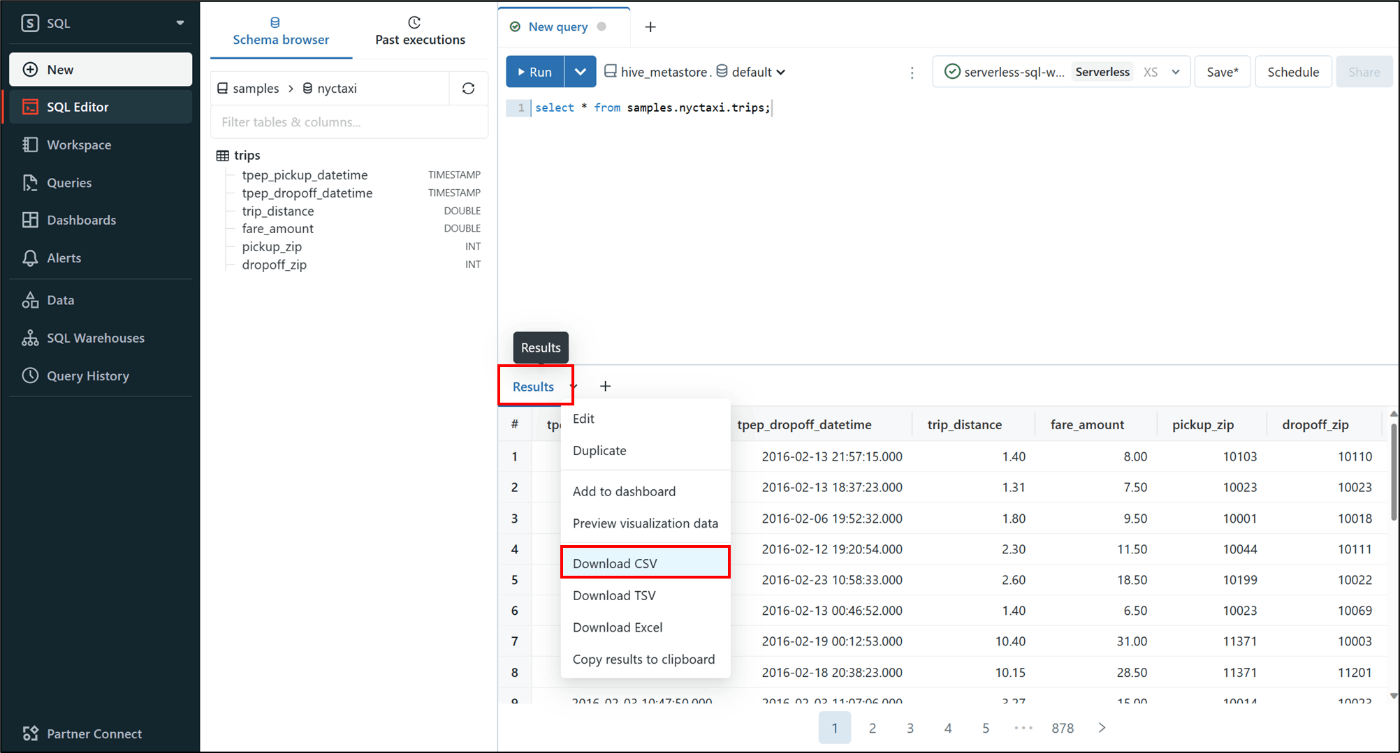
Databricks にあらかじめ含まれているサンプルデータを CSV 形式でダウンロードします。SQL エディターで前項で作成したサーバレス SQL ウェアハウスを選択してから以下のクエリを実行します。その際、全件データを取得するためにLIMIT 1000 のチェックを外しておきます。
SELECT * FROM samples.nyctaxi.trips;



結果を CSV 形式でダウンロードします。
3.2. DBFS へのアップロード
ダウンロードした CSV ファイルを DBFS へアップロードします。アップロードは Data Science & Engineering ペルソナに切り替えて行います。

まだ有効にしていない場合、管理コンソールから DBFS ファイルブラウザーを有効化します。

DBFS ファイルブラウザーから CSV ファイルをアップロードします。
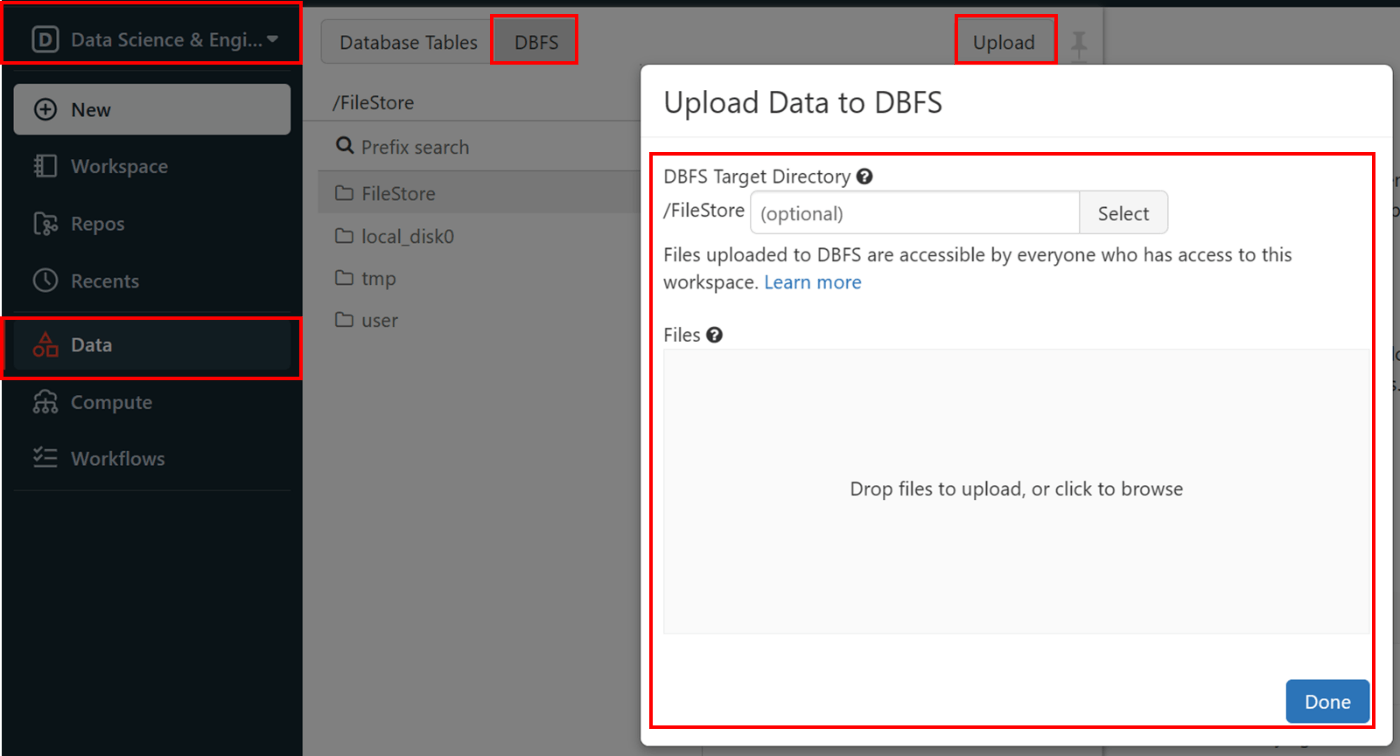
ファイルをアップロードしたら、ファイルパスを控えておきます。後ほどクエリの中で取り込み対象のファイルを指定する際に使います。


4. Delta Table への取り込み
DBFS にアップロードした CSV ファイルを Delta Table に取り込みます。再び Databricks SQL ペルソナに切り替えます。

SQL エディターで下記のクエリを実行します。このクエリではまず空の Delta Table を作成してから、COPY INTO にて DBFS 上にアップロードした CSV ファイルを取り込んでいます。FROM 句のパスは前項でコピーしておいたものに置き換えます。
DROP TABLE IF EXISTS default.nyctaxi_trips;
CREATE TABLE default.nyctaxi_trips;
COPY INTO
default.nyctaxi_trips
FROM
'dbfs:/FileStore/nyctaxi_trips.csv'
FILEFORMAT = CSV
FORMAT_OPTIONS (
'mergeSchema' = 'true'
,'delimiter' = ','
,'header' = 'true'
)
COPY_OPTIONS ('mergeSchema' = 'true')
;
SELECT * FROM default.nyctaxi_trips;

作成されたテーブルのスキーマはデータエクスプローラーから確認することができます。Delta のアイコンにより、Delta Table として作成されていることがわかります。

また、DESCRIBE HISTORY によって Delta Table の履歴を確認することができます。テーブル作成と COPY INTO の 2 つのバージョンが存在しています。例えば MERGE INTO により、既存のテーブルに複数回に分けてデータを追加した場合などは、ここに複数のバージョンが追加されていきます。
DESCRIBE HISTORY default.nyctaxi_trips;

おわりに
今回はクイックスタートのための最小限の情報という位置づけでサーバレス SQL を使って ルート DBFS からの取り込みを行いました。サーバレス SQL から利用者の任意のストレージ (e.g. Azure Data Lake Storage Gen2) へアクセスするパターンも後ほど情報をまとめたいと思います。

以上です。🍵

Discussion