Azure Databricks を ADLS Gen2 に接続する方法
Azure Databricks を Azure Data Lake Storage Gen2 (以下 ADLS Gen2) に接続する方法はいくつかあります。
- Unity Catalog を使用する方法
- Azure の資格情報を使用する方法
- Azure サービスプリンシパルを使用した OAuth 2.0
- Shared Access Signature (SAS)
- ストレージアカウントキーの使用
この中で今回は Azure サービスプリンシパルを使用して ADLS Gen2に接続していきます。
今回は チュートリアル: Azure Data Lake Storage Gen2 への接続 という記事をもとに作成しており、実装はそれほど難しくありませんが行間を埋めるという意義をもってこの記事を書いております。
手順
前提条件
ADLS Gen2 に Azure Databricks を接続する手順に入る前に、前提として以下のリソースを作成する必要があります。
- Azure Databricks ワークスペース
- Azure ストレージアカウント (ADLS Gen2)
- Azure Key Vault (キーコンテナ―)
Azure Databricks は Standard でも Premium でも構いません。(Unity Catalog は Premium で使用可能) 今回は Premium で作成しています。ワークスペース作成後、コンピューティングクラスターも併せて作成しておきます。
Azure ストレージアカウント作成の際、階層型名前空間を有効にするボックスにチェックを入れ有効にすることで ADLS Gen2 を作成することができます。

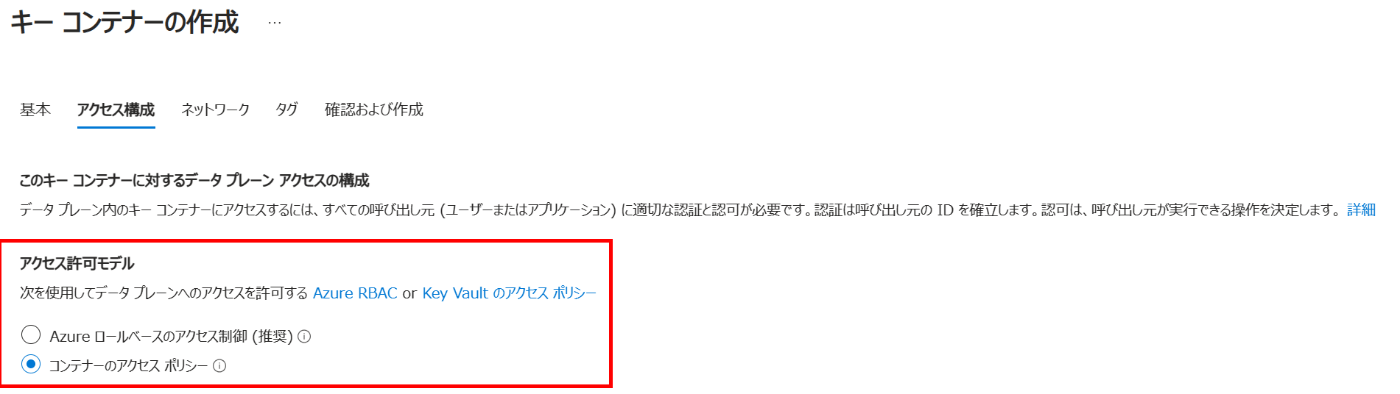
Azure Key Vault を作成する際、アクセス構成のページでアクセス許可モデルをコンテナーのアクセスポリシーとしています。手順の中でサービスプリンシパルにアクセス権を付与する形とします。
手順1:Azure サービスプリンシパルを作成する
まずはじめに、Azure のサービスプリンシパルを作成します。
Azure Portal で Entra ID と検索し、選択します。

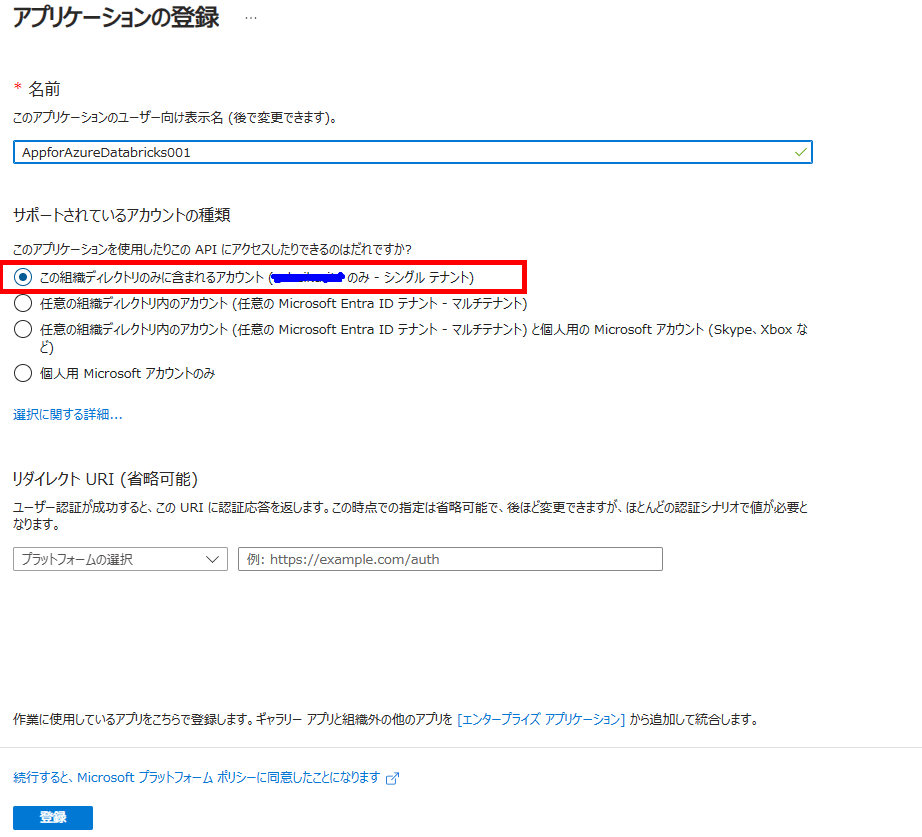
[アプリの登録] -> [新規登録]の順にクリックします。

アプリケーションの名前を入力し、アカウントの種類を選択します。アカウントの種類は、シングルテナントのものにチェックを入れます。その後、ページ下にある[登録]をクリックします。
手順2:サービスプリンシパルのクライアントシークレットを作成する
次に、手順1で作成したサービスプリンシパルのクライアントシークレットを作成します。
左のブレードで[証明書とシークレット]をクリックし、[クライアントシークレット]タブの[新しいクライアントシークレット]をクリックして進みます。
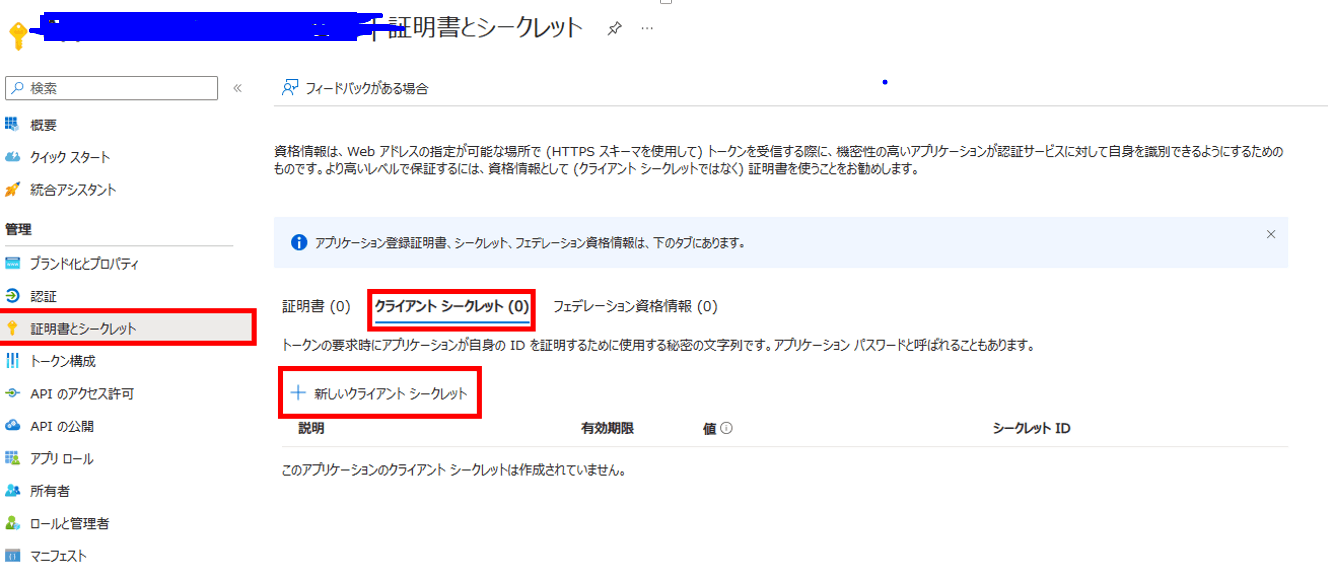
そうするとクライアントシークレットの説明を記述するフィールドと、有効期限を指定するフィールドがでてくるので、入力・選択してください。
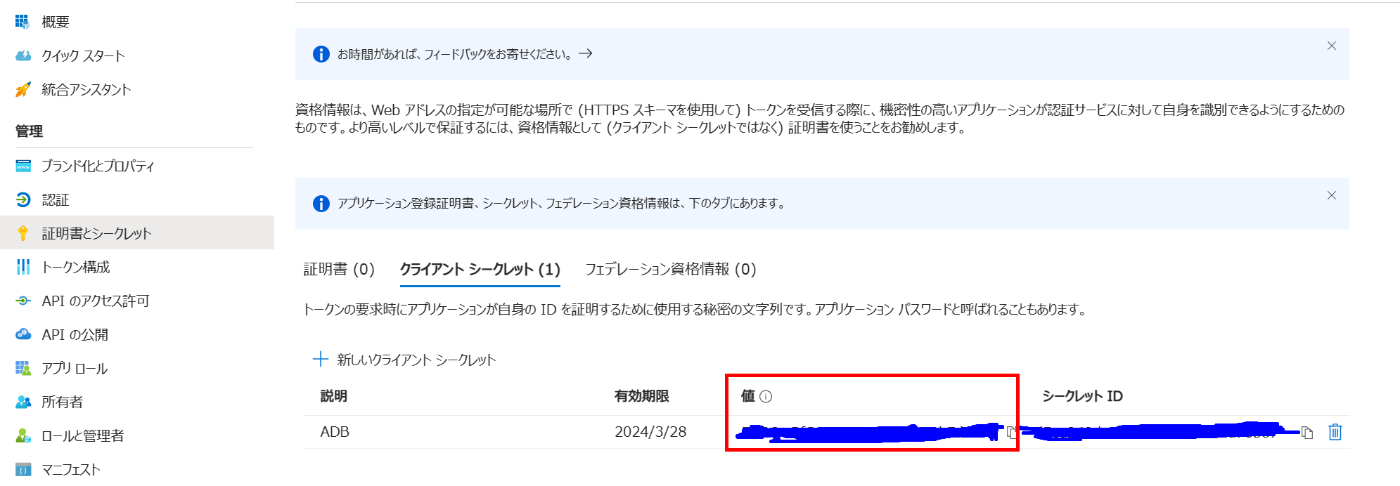
クライアントシークレットの作成が完了すると、以下のイメージのようになっていると思います。クライアントシークレットの値をコピーして、安全に保管しておきます。この値は、アプリケーションのパスワードのようなものですので、他人には共有しないようご注意ください。
[概要]ページに戻り、アプリケーション(クライアント)IDとディレクトリ(テナント)IDもコピーして、安全に保管します。これらもアプリケーションがリソースにアクセスするためのIDとして必要となります。

手順3:サービスプリンシパルに ADLS Gen2 へのアクセス権を付与する
次に、手順1で作成したサービスプリンシパルに、ストレージアカウントへのアクセス権を付与する方法を示します。
事前に作成したストレージアカウントに移動します。[アクセス制御(IAM)] -> [+追加] -> [ロールの割り当ての追加] の順にクリックし、ADLS Gen2 にサービスプリンシパルからのアクセスを許可するロールを割り当てます。
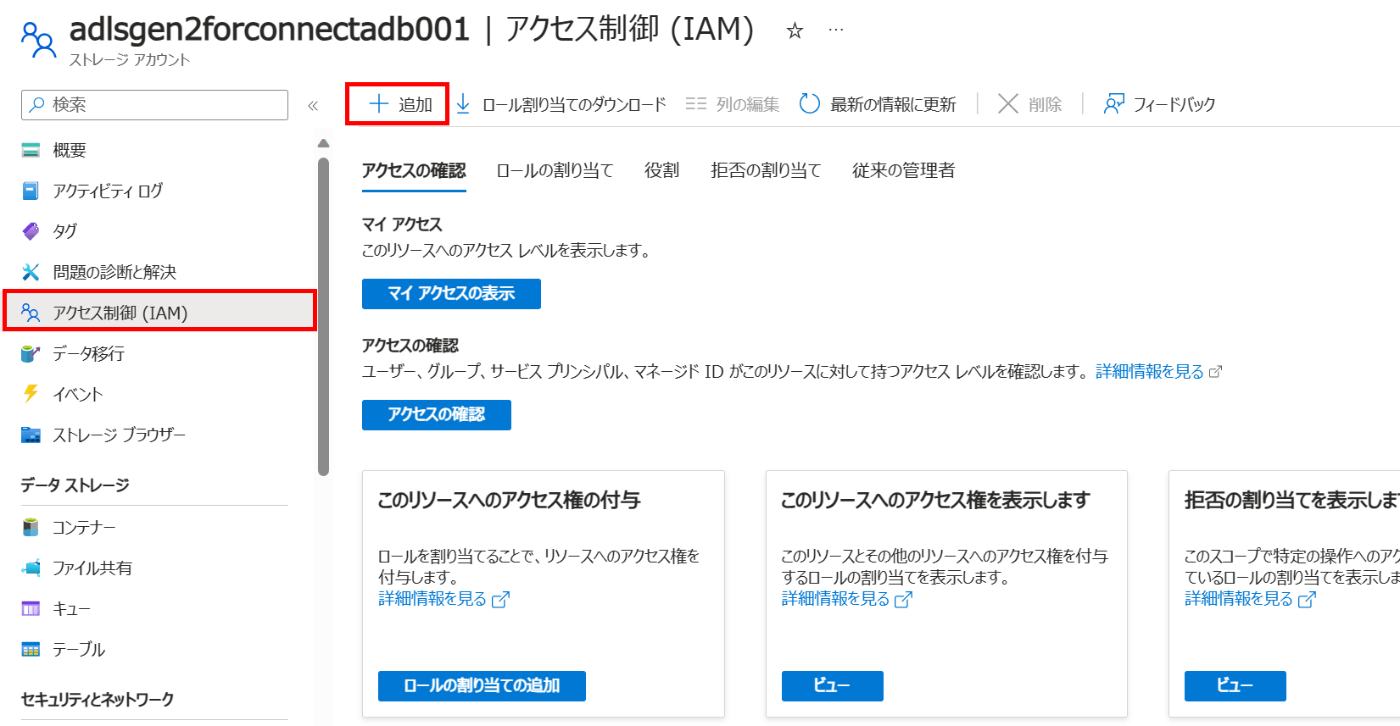
ロールの割り当ての追加ページ内の、ロールタブで[ストレージBLOB データ共同作成者]を選択し、次へ進みます。
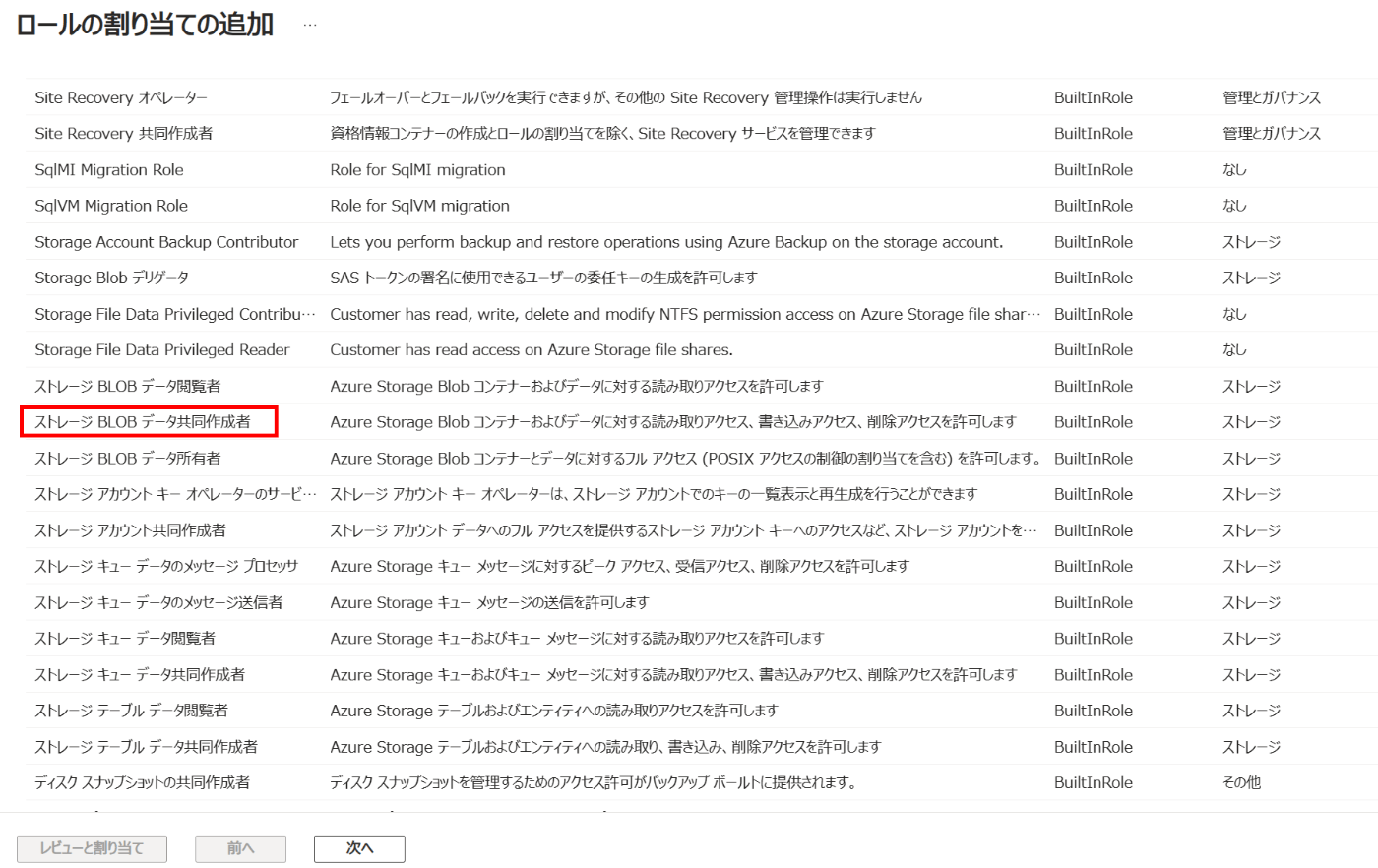
メンバータブでは、[アクセスの割り当て先]にユーザー、グループ、またはサービスプリンシパルになっていることを確認し、[メンバーを選択する]をクリックします。選択フィールドに作成したサービスプリンシパルの名前を検索し、選択して[レビューと割り当て]をクリックし、ロールを付与します。
手順4:クライアントシークレットを Azure Key Vault に追加する
手順4では、事前に作成したクライアントシークレットを Azure Key Vault (キーコンテナ―)に追加します。アプリケーションのパスワードを Azure Key Vault で安全に保管してくれます。
Azure Portal でキーコンテナ―に移動し、事前に作成したキーコンテナ―を選択します。
左のブレードにある[シークレット]を選び、[+生成/インポート]をクリックします。

シークレットの名前を決め入力し、シークレット値のところには手順2で保管したシークレットの値をペーストします。完了したら、[作成]をクリックします。

キーコンテナ―側で作成したシークレットの名前も、後々使用するので控えておいてください。
手順5:Azure Databricks ワークスペースのシークレットスコープを作成する
ここまでの手順では Azure のストレージアカウント、Key Vault 側のセットアップを行っていましたが、手順5では Azure Databricks のセットアップを行います。ここでは、Azure Key Vault でサポートされるシークレットスコープを作成します。
まずは、事前に作成した Azure Databricks のインスタンス名を確認します。Azure Databricks のワークスペースURI はadb-<workspaceID>.<random number>.azuredatabricks.netであり、これがインスタンス名でもあります。参考リンク:ワークスペース単位の URL
まずは作成した Azure Databricks ワークスペースに移動し、インスタンス名<azuredatabricks-instance>を確認します。そのうえで、以下にアクセスします。
https://<azuredatabricks-instance>#secrets/createScope
このURLでは小文字大文字が区別されるので、正しい入力にご注意ください。
すると、以下のようなページが現れます。

入力は以下の4点です。
- Scope Name を決めます。この名前は手順6で使用するので控えます。
- Manage Principal では、この手順で作成する Scope の管理を全ユーザーに付与する、もしくは作成者のみに限定するか選ぶことができます。(Premium でないと、作成者のみを選択することができません。)
- Azure key Vault の資格情報を入力する欄が DNS Name と Resource ID というようにありますので以下のように入力します。
# キーコンテナ―名を<azurekeyvault-name>に置き換え
https://<azurekeyvault-name>.vault.azure.net/
#サブスクリプションID、リソースグループ名、キーコンテナ―名をそれぞれ置き換え
/subscriptions/<subscriptionID>/resourcegroups/<resourcegroup-name>/providers/Microsoft.KeyVault/vaults/<azurekeyvault-name>
すべての入力が終わったら、[create] をクリックします。
シークレットスコープを作成するページが閉じます。
手順6:Python で ADLS Gen2 に接続する
最後になります。 Azure Databricks ワークスペースで[+新規] -> [ノートブック]の順に進み、接続するコードを書くための Notebook を作成します。
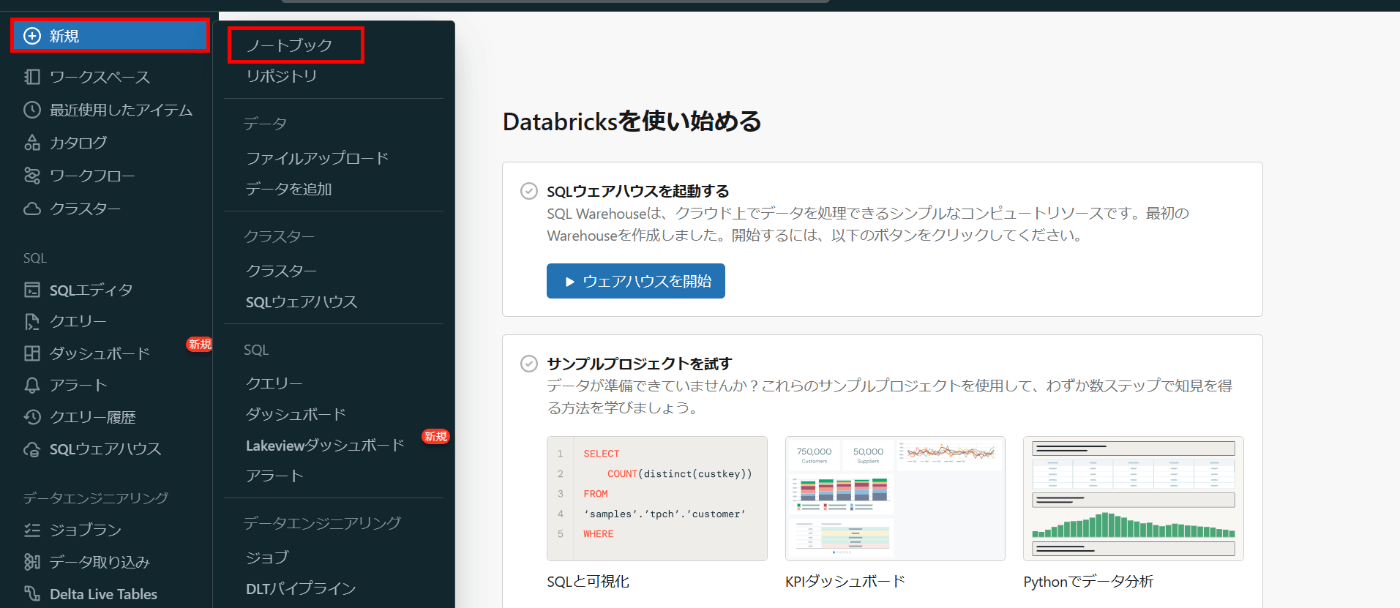
ノートブックを開いたら、ノートブックの名前を変更し、選択言語が Python になっているか確認します。なっていなければ変更してください。そして、[接続]をクリックし、前提で事前に作成したコンピューティングクラスターを Notebook に紐づけます。
Notebook のセルに以下のコードを入力します。
service_credential = dbutils.secrets.get(scope="<scope>",key="<service-credential-key>")
spark.conf.set("fs.azure.account.auth.type.<storage-account>.dfs.core.windows.net", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type.<storage-account>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id.<storage-account>.dfs.core.windows.net", "<application-id>")
spark.conf.set("fs.azure.account.oauth2.client.secret.<storage-account>.dfs.core.windows.net", service_credential)
spark.conf.set("fs.azure.account.oauth2.client.endpoint.<storage-account>.dfs.core.windows.net", "https://login.microsoftonline.com/<directory-id>/oauth2/token")
- <scope>:手順5で作成したシークレットスコープの名前
- <service-credential-key>:手順4で作成したクライアントシークレットの名前
- <storage-account> : Azure ストレージアカウントの名前
- <application-id> : 手順2で作成したサービスプリンシパルのアプリケーション(クライアント)ID
- <directory-id> : 手順2で作成したサービスプリンシパルのディレクトリ(テナント)ID
それぞれ置き換えてコードを実行すると、無事 Azure Databricks を ADLS Gen2 に接続することができます。
おわりに
Azure Databricks を ADLS Gen2 に接続することができると、様々なワークロードで Azure Databricks を体験することができるようになります。Azure Databricks 公式ドキュメントではほかにもさまざまなチュートリアルが公開されているので、ぜひ試してみてください。

Discussion