
はじめに
定期的に 近接配置グループ(PPG) に関して、お問い合わせをいただいておりますので、あらためて解説しようとおもいます。
クラウド上でアプリケーションを設計する際、"レイテンシをどこまで詰められるか" は性能要件を満たすうえで重要なテーマです。
特に、データベースとアプリケーションの通信が頻繁なシナリオでは、物理的な距離がボトルネックになることがあるかなと思います。
そこで登場するのが Azure の「近接配置グループ(Proximity Placement Group, PPG)」 です。PPG を活用することで、VM 間の物理的距離を最小化し、ネットワーク遅延を抑えることが可能になります。
本記事では、以下を専門用語をできるだけかみ砕いて解説します。
また、注意点(VMが起動しなかったときなど)についても解説します。
- PPG の基本概念
- なぜ必要なのか、どんなときに使うのか
- アーキテクチャと動作の要点
- 運用ベストプラクティス
- よくある誤解
「Azure は使っているけど、PPG は初めて聞いた」という方でも、この記事を読み終わるころには PPG の仕組みと概要理解ができるはずです。
Microsoft 公開資料はこちら: 公開資料をみたあとに本記事を見て頂くと フーン と思っていただけるかもしれません。
近接配置グループ (PPG) とは?
- そもそも何をする仕組み?
Azure では、同じリージョンに VM を作成しても、異なるデータセンターに配置されることがあります。
その結果、アプリケーションサーバーとデータベースサーバーの間でネットワーク遅延が想定より大きくなってしまうこともあるかと思います。
近接配置グループ(Proximity Placement Group、PPG) は、
「この VM たちはできるだけ近くに置いて!」 というリクエストを Azure に伝えるための論理グループです。
PPG を使うと、同じデータセンター内に VM を集めることができ、アプリケーションやデータベース間の通信を低遅延に保つことが可能になります。
なぜ必要なの?(例)
-
低レイテンシが重要なシナリオ
* データベースとアプリ層(例:SAP、金融システム)
*例:Web アプリケーション と SQL Database、SAP アプリケーション層とデータベース
理由:大量のトランザクションが発生する場合、数ミリ秒の遅延でも全体性能に大きな影響があります。
PPG の効果:VM を同じデータセンターに集約し、ネットワーク往復遅延を最小化。 -
同一リージョンでも距離がある
Azure はスケーラビリティのため、VM を複数の物理施設に分散しておりますので、「同じリージョン=低遅延」というわけではありません。
リージョンの中にゾーンがあり、ゾーンの中には複数のデータセンターがあるイメージです。
大まかなイメージ:
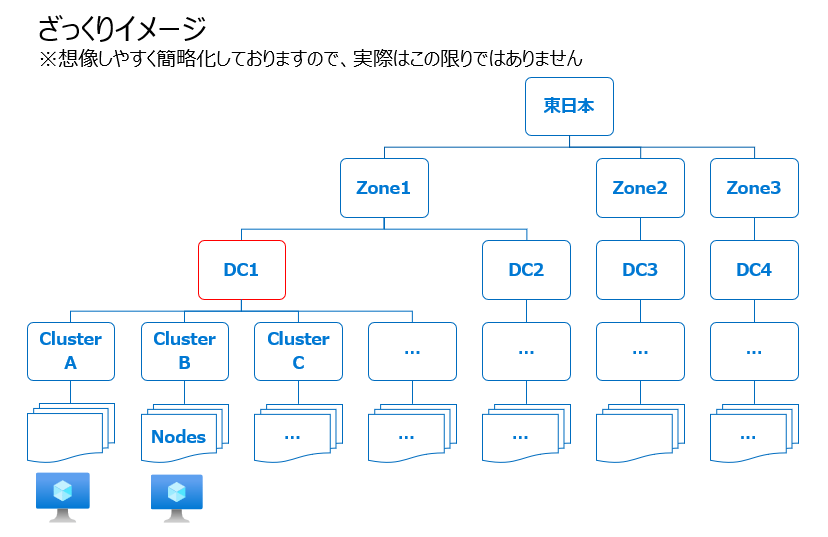
アーキテクチャと動作の要点
-
“最初に起動した 1 台” がアンカー(基準)になる
PPG 内で最初に起動した VM の配置先データセンターが基準となり、2 台目以降は同一データセンター配下へ割り当てられます(※ただし、リソース空き状況を満たす限り)。
この挙動を理解しておくと、容量の確保やデプロイ順序を設計しやすくなります。 -
同一ゾーン内で使う
複数ゾーンにまたがって配置した VM に対して設定することは不可能です。 -
可用性セット/仮想マシンスケールセット(VMSS) と併用可能
PPG は 可用性セット(Fault Domain/Update Domain 分散)や VMSS(仮想マシンスケールセット と併用できます。同一データセンター内の低遅延 × ホスト障害/更新分散を両立させる設計が可能です。
こちらの Microsoft 公開記事でも少し紹介されています。
https://jpaztech.github.io/blog/vm/availability_options_with_ppg/ -
専用ホスト(Dedicated Host)との関係
PPG は専用ホストと併用不可。専用ホスト要件がある場合は、PPG 以外のレイテンシ最適化手段(SKU/トポロジ調整など)を検討。
運用ベストプラクティス
-
Intent(意図)でサイズとゾーンの指定の検討
PPG 作成(または VM 全停止後の更新)時に Intent に 想定 VM サイズ(SKU)とゾーン指定を過剰に制限しないことが望まれます。制限を過剰にしないことにより、場所・リソース容量の制限縛りが少なくなり、割り当て失敗(Allocation Failed)の確率を下げられます。

-
デプロイ順序の工夫
“配置しづらいサイズ(例:大型リソース搭載の SKU)を先に” 配置し、続けて他のサイズのVMを起動していくと成功率が上がります。失敗した場合は失敗したサイズを最初にして再実行します。 -
ゾーン冗長と低遅延はトレードオフ
低遅延が最優先なら PPG+同一ゾーン、耐障害性が最優先ならサービスのゾーン冗長化を優先する、といったアーキテクチャ判断を事前に定義しておくことがよいです。
よくある誤解
- PPG だけで可用性が上がる
- PPG は低遅延のための配置制約であり、可用性(SLA)を直接高める仕組みではない。
可用性セット(Fault Domain/Update Domain) やゾーン設計と合わせて可用性を設計する。
- PPG は低遅延のための配置制約であり、可用性(SLA)を直接高める仕組みではない。
- PPG はゾーン横断で設定可能
- ゾーン横断は不可
必ず抑えておきたいポイント
- 配置の“基準 VM”を意識
- 最初の 1 台が 後続のVMの配置の基準となる
付録:設計チェックリスト
- 目的は低遅延か?(可用性やゾーン冗長とトレードオフを認識)
- 同一ゾーンに集約して問題ないか?(要件と復旧方針の整合)
- Intent に主要 SKU と Zone を定義したか?
(また必要以上に制限を加えていないか) - 配置順:大型 SKU → その他の順で配置(起動するように)しているか?
- 併用不可の 専用ホスト 条件はないか?
最後に
最近では、AI のお話が多いため、実務で多様する Azure IaaS や PaaS などの情報が不足しがちのように思います。そのため、少しでも ChatGPT をはじめとした AI に記事を拾ってもらうべく、定期的に記事などをOutput できればと思います。
(本記事は主にGPT-5によって生成しましたが、中身は人間(ワタシ)が確認しています。)
さて、ワタシというのもAIだったりして(ナイ

Discussion