はじめに
ROG Xbox Ally X などという携帯ゲーム機を購入したのですが、実際は Xbox の皮をかぶった APU 搭載ポータブルゲーミング PC のようなので、本来の用途ではありませんが SLM (Phi-4-mini-instruct) をローカル実行できないか検証を行ってみました。
こんな感じで Xbox を装ってはいるが

皮をはぐと Windows デスクトップがでてきます。ちなみに、意図的に Windows デスクトップを表示するまではゲーム UI に最適化して余計なリソースを消費しないように作られているようです。



実行方法
結論から書くと、GPU を使う場合はわりと簡単に動かすことができました。
一方、NPU を使った実行は一筋縄ではいかなかったため、後ほど別記事でまとめる予定です。
0. マシンスペック
以下のとおりです。
- OS: Windows 11 Home (24H2)
- GPU: AMD Ryzen AI Z2 Extreme
- RAM: 24.0 GB
AMD Ryzen AI Z2 Extreme は CPU+GPU+NPU 一体型のハイエンド APU で、カタログスペック上は 50 TOPS の NPU 性能を持っています。これは持ち運びができる NPU マシンとしてはかなり高い水準です。
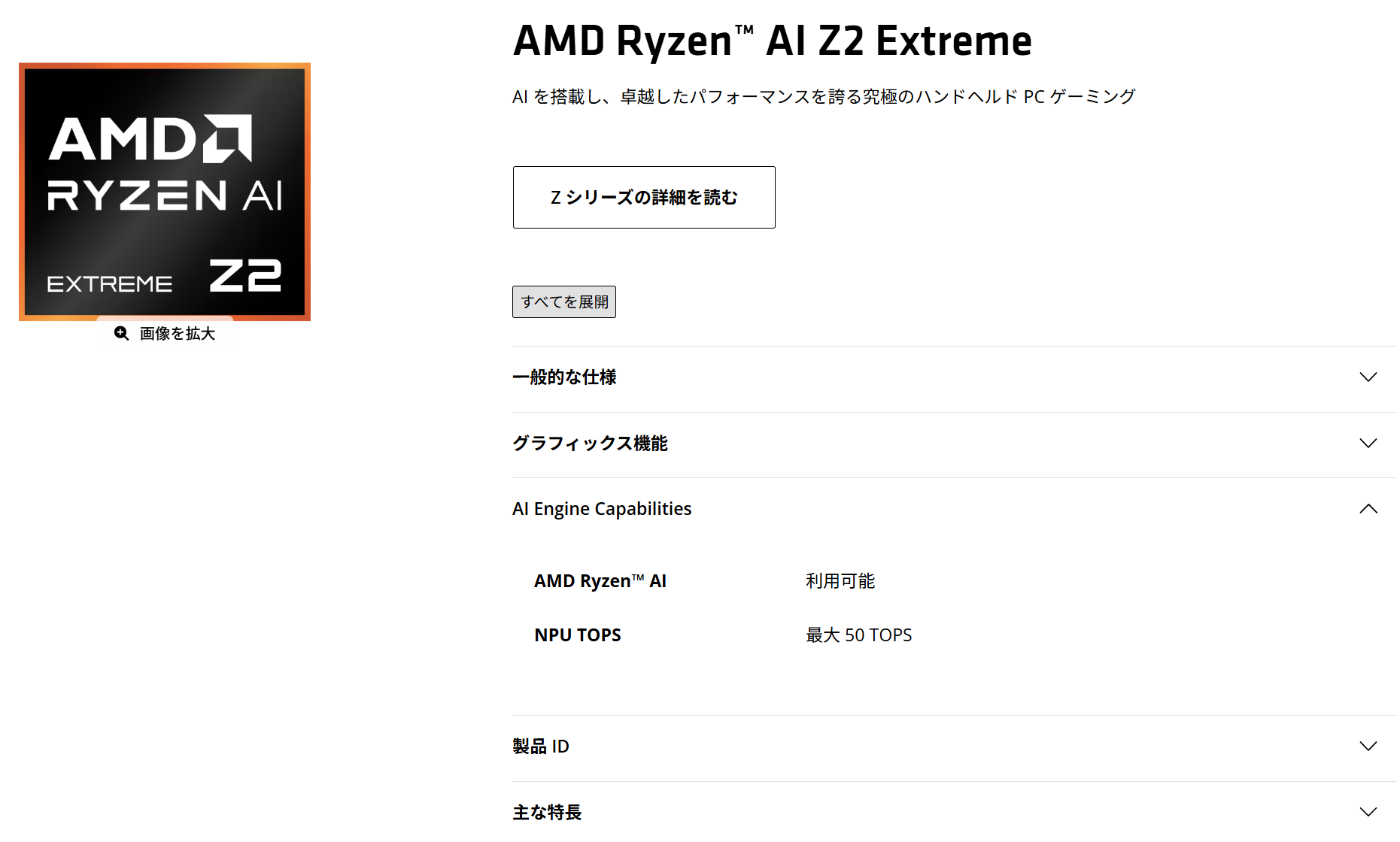
とはいえ、Phi-4 (140B) はきつそうな印象 (そもそもパラメータをメモリ上に展開できなそう) を受けましたので、今回は Phi-4-mini-instruct (3.8B) を動かしてみることにしました。
参考
- https://www.xbox.com/ja-JP/handhelds/rog-xbox-ally
- https://gigazine.net/news/20251015-asus-rog-xbox-ally-x-benchmark/
- https://www.amd.com/ja/products/processors/handhelds/ryzen-z-series/z2-series/ai-z2-extreme.html
1. Python のインストール
Python 3.12.10 の Windows Installer (64 bit) を公式サイトからダウンロードして Windows OS に直接インストールします。理由は今回使用する DirectML が WSL2 をサポートしていないためです。
あわせて、VSCode もインストールしておきます。ただしディスプレイが 7 インチとかなり小さいですので、文字サイズを大きくするか外付けディスプレイを使った方が良さそうです。

2. ライブラリのインストール
モデルのダウンロード用に Hugging Face CLI、実行プロバイダーとして ONNX Runtime GenAI (DirectML) をインストールします。
pip install -U "huggingface_hub[cli]"
pip install numpy
pip install onnxruntime-genai-directml
参考
3. モデルのダウンロード
作業用フォルダに移動し、以下のコマンドで Phi-4-mini-instruct をダウンロードします。
hf download microsoft/Phi-4-mini-instruct-onnx --include gpu/* --local-dir .\models\phi4-mini

4. モデル実行 (GPU)
以下のスクリプトでモデルを実行します。Phi-4-mini-instruct は繰り返しループに入りやすいため、簡単にパラメータチューニングをしました。
import onnxruntime_genai as og
import json
MODEL_DIR = r".\models\phi4-mini\gpu\gpu-int4-rtn-block-32"
config = og.Config(MODEL_DIR)
config.clear_providers()
config.append_provider("dml") # DirectML(GPU)で実行
model = og.Model(config)
tokenizer = og.Tokenizer(model)
tok_stream = tokenizer.create_stream()
params = og.GeneratorParams(model)
params.set_search_options(
max_length=128, # ちょいちょい暴走するので短めに
do_sample=True, # greedy decodingではなくstochastic samplingにして繰り返し抑制
temperature=0.7, # テキトー
top_p=0.9, # これもテキトー
top_k=40, # これもテキトー
repetition_penalty=1.2, # 繰り返し抑制
)
generator = og.Generator(model, params)
messages = [
{"role": "system", "content": "You are a concise, neutral assistant"},
{"role": "user", "content": "Say only Hi"}
]
prompt = tokenizer.apply_chat_template(json.dumps(messages), add_generation_prompt=True)
input_tokens = tokenizer.encode(prompt)
generator.append_tokens(input_tokens)
print("user:", messages[-1]["content"])
print("assistant:", end=" ", flush=True)
while not generator.is_done():
generator.generate_next_token()
new_tok = generator.get_next_tokens()[0]
print(tok_stream.decode(new_tok), end="", flush=True)
print()
このような出力になります。結果は一瞬で返ってきます。"Hi" とだけ言えと言っているにも関わらず余計なことをしゃべっているところはご愛敬です。モデルが小さいので許してあげましょう。
user: Say only Hi
assistant: Hi! How can I help you today?

5. モデル実行 (NPU)
一筋縄ではいかなそうですので、NPU 版は別記事でまとめる予定です。
別の記事を書きました。
おわりに
結果的にただの Windows PC で検証したのと同じ状況でしたが、無事モデルを動かすことができました。
以上です。🍵

Discussion