Azure Databricks のベクトル検索機能
この記事では Azure Databricks のベクトル検索機能についてご紹介します。
Azure Databricks のベクトル検索とは
ベクトル検索機能は 2023 年の 12 月にパブリック プレビューで発表されました。ベクトル検索は情報検索や RAG (Retrieval Augmented Generation) アプリケーションで使用される手法で、検索クエリとの類似性に基づいて関連する文書を検索します。この機能によって、PDF や Office ドキュメントなどの非構造化データに対する類似検索を通じて生成 AI アプリケーションの精度を向上させることを可能にします。ベクトル検索機能を搭載した Azure 製品は Azure AI Search や Azure Cosmos DB for MongoDB vCore などがありますが、レイクハウスに保存されたデータを活用した生成 AI アプリケーションを考える場合は Azure Databricks も選択肢の 1 つとなります。
前述のとおりベクトル検索の選択肢としては複数ありますが、ここでは簡単に Azure Databricks のベクトル検索機能の特徴をご紹介します。詳しくはこちらをご参照ください。
Databricks Vector Search パブリック プレビューのご紹介
自動データ取り込み
自動データ取り込み機能では、新たなデータパイプラインを構築・維持することなく、自動的にデータを取り込み、そのデータを埋め込むことができます。Delta Sync API を用いてソースデータとベクトル インデックスを自動的に同期させ、データベースへのデータの埋め込みを簡素化します。ソースデータが追加、更新、削除されると、Delta Sync API によって対応するベクトル インデックスが自動的に更新されます。この自動同期の機能は有効にも無効にもすることができます。方法については後述します。
一元化されたガバナンス
Databricks のベクトル検索は Unity Catalog と統合され、データに対する強固なセキュリティとアクセス制御を提供します。この一元化されたアプローチにより、ベクトル インデックスは Unity Catalog 内のエンティティとして管理され、データのセキュリティとガバナンスを強化しながら複雑さとコストを削減します。
事実、現時点では Azure Databricks のベクトル検索を使用するための前提条件として Unity Catalog を有効にする必要があります。Unity Catalog については以下をご参照ください。
Unity Catalog とは - Azure Databricks
本記事のポイント
なお、この記事のポイントとして、 Azure OpenAI Service の Embedding モデルによってベクトル化するための手順をご紹介します。Databricks のベクトル検索に関してさまざまなブログを拝見し参考にさせていただきましたが、調べた限りでは text-embedding-ada-2 のような Azure OpenAI Service の Embedding モデルを使用する方法は案内されていなかったと思います。もし Azure OpenAI Service Embedding モデルを利用可能な方はぜひこのブログを参考にベクトル検索を試していただきたいと思います。
参考にさせていただいたブログをご紹介します。利用される方はこちらもご参照ください。
Databricks の Vector Search
ベクトル検索のプログラムの書き方比較 ~Databricks Vector Search、FAISS、ChromaDB~
手順
今回は Azure Databricks のベクトル検索機能の使用方法を End-to-End で紹介するのが目的です。したがって、使用するための前提条件から、クエリを投げるまでの流れを見ていこうと思います。
前提条件
Azure Databricks のベクトル検索を利用するための前提条件は少し多いです。記事作成時点では以下が必要となります。
- Unity Catalog 対応の Azure Databricks ワークスペース
- サーバーレス コンピューティングの有効化
- 変更データ フィードの有効化
- 作成するソース テーブルの親カタログ スキーマに対する CREATE TABLE 特権
- 個人用アクセス トークンの有効化
今回はベクトル検索機能を使用するための流れをご紹介するのが目的なのですべてを説明しませんが、簡単な内容と参考となる Web サイトをご紹介します。
Unity Catalog 対応の Azure Databricks ワークスペース
前述のとおり Azure Databricks のベクトル検索機能の大きな特徴の 1 つに Unity Catalog との統合があります。Unity Catalog とは、Azure Databricks アカウント内のすべてのワークスペース間でユーザーとデータへのアクセスを一元的に管理するガバナンス機能であり、この機能が有効なワークスペース上でベクトル検索を使用することができます。
2023 年 11 月ごろから Unity Catalog の自動有効化 が開始されているので、そこまで手間はかからないかもしれません。公式ドキュメントを参考に有効化してください。
筆者は以下のブログを参考に作成しました。多少時間はかかるものの、Azure Databricks ワークスペース管理者・メタストア管理者・一般開発者とロールをわけて Unity Catalog 環境を作成します。それぞれの権限を意識した管理について学ぶことができます。
Azure Databricks Unity Catalog をセットアップしてみる
サーバーレス コンピューティングの有効化
Azure Databricks の Premium プランを選択すれば、既定でサーバーレス コンピューティングが有効になります。詳しくは以下をご参照ください。
(サーバーレス コンピューティング - Azure Databricks)[https://learn.microsoft.com/ja-JP/azure/databricks/serverless-compute/]
変更データ フィードの有効化
Azure Databricks で変更データ フィードを使うと、Delta テーブルのバージョン間で行レベルの変更を追跡することができます。おそらくこちらを有効にしないと自動同期の機能が使えないのでは、と思っています。
実際には、ソースとなる Delta テーブルを作成後、変更データ フィードを有効にします。ノートブックを使用するため、以下のような SQL マジック コマンドを利用します。
%sql
ALTER TABLE <table 名> SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
詳細はドキュメントをご参照ください。
変更データ フィードを有効にする
作成するソース テーブルの親カタログ スキーマに対する CREATE TABLE 特権
Unity Catalog を有効にした後、ベクトル インデックスのソースとなる Delta テーブルを作成するためには、テーブルおよびベクトル インデックスを作成するアカウント (以下作成者) が作成したいカタログとスキーマに対して CREATE TABLE 特権をもっていなければいけません。ただ、こちらは最低限の権限となっており、必要に応じて権限を持つ必要があります。
前提条件 1 でご紹介した Unity Catalog の有効化の方法を利用している場合、メタストア管理者が親となるカタログを作成し、カタログに対して USE CATALOG 特権 (カタログを作成者に表示・使用させる)・CREATE SCHEMA 特権 (作成者にスキーマを作成させる)・CREATE TABLE 特権 (ソース Delta テーブルの作成に必要) 等を作成者 (一般開発者) に付与します。権限を付与する方法は カタログ エクスプローラーを利用した UI での方法や、SQL クエリがあります。
個人用アクセス トークンの有効化
最後の要件として、 個人用アクセス トークンを有効にしなければなりません。このトークンは Azure OpenAI Service のモデルを外部モデルとして使用する際に、API キーを登録するための認証で使用します。
前提条件 1 の Unity Catalog 有効化 を終えた時点ではワークスペース管理者がアクセス トークンの管理者にもなっているため、こちらもベクトル インデックスの作成者に権限を付与する必要があります。
UI での操作では、ワークスペース管理者がサインインし、[管理者設定] → [Advanced] へ移動し、Permission Setting から作成者に権限を付与します。

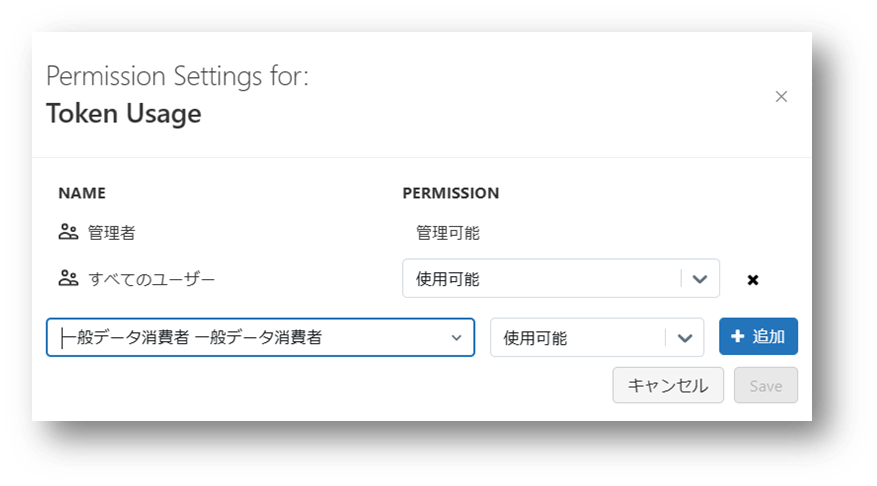
その後、一般開発者はサインインし、[ユーザー設定] → [開発者] へ移動し、個人用アクセス トークンを発行します。
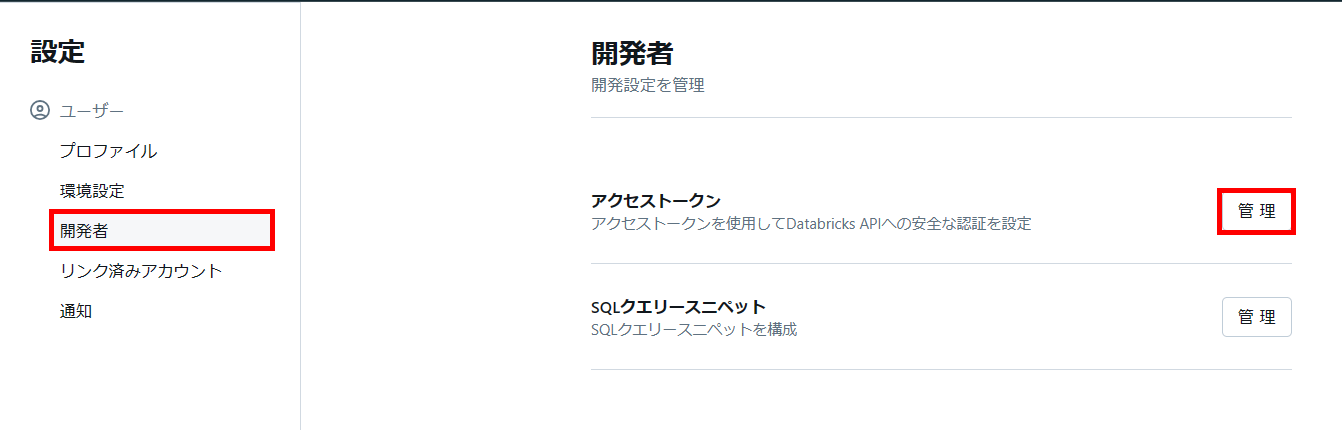
トークンの値は一度しか表示されないため、大切に管理してください。
なお、5 つの前提条件はドキュメントに記載されている要件でしたが、ご紹介する方法を試す場合はそのほかにもいくつか事前に準備する必要があります。
Azure OpenAI Service の Embedding モデルを使用する際はモデルをデプロイしていただく必要があります。
個人用アクセス トークン認証を行う際に、Databricks CLI を使用します。事前にインストールしていただく必要があります。詳しくはこちらをご参照ください。Azure Databricks 個人用アクセス トークン認証
こちらもお忘れずに!
ソース テーブルの準備
ここから実際にベクトル インデックスを作成する手順に入ります。
まずはベクトル インデックスのもととなるソース Delta テーブルを作成する必要があります。実際には、ベクトル化したいテキストが含まれるテーブルを作成する作業が必要です。
今回は チュートリアル: Azure OpenAI Service の埋め込みとドキュメント検索を確認する で使用されている CSV ファイルのデータを使用します。このデータは米国議会およびカリフォルニア州の法案のデータセットとなっております。このデータセットの元となった学術論文については、BillSum プロジェクトの GitHub リポジトリ をご参照ください。
基本的には紹介したチュートリアルと同じコードでデータを整形し、テーブルに変換します。
CSV ファイルとなっているため、まずはスキーマ配下にボリュームを作成し、CSV ファイルをアップロードします。
メニューから [データの取り込み] を選択し、[ファイルをボリュームにアップロード] を選択します。その後アップロード先のボリューム パスを指定し、アップロードします。

その後アップロード先のボリューム パスを指定し、アップロードします。

アップロードが終わったら、あとはチュートリアルと同様ノートブック上でテーブル作成のための Python コードを書いていきます。今回の目的と直接関係ないため、詳細の説明等は省略します、詳しく知りたい方はドキュメント チュートリアル: Azure OpenAI Service の埋め込みとドキュメント検索を確認するをご参照ください。
まずはボリュームからデータフレームへ読み取ります。
import pandas as pd
df = pd.read_csv('/Volumes/quickstart_catalog/quickstart_schema/quickstart_csv/bill_sum_data.csv')
df

bill_id, text, title という列だけ取り出します。この部分がドキュメントと異なりますが、(後述しますが) これはベクトル インデックスを作成する際にプライマリ キーが必要なため bill_id 列を入れています。
df_bills = df[['bill_id', 'text', 'title']]
df_bills
次に、冗長な空白を削除したり句読点をクリーンアップしたりして軽いデータ クリーニングを行い、トークン化の準備をします。
import re
pd.options.mode.chained_assignment = None
def normalize_text(s, sep_token = " \n "):
s = re.sub(r'\s+', ' ', s).strip()
s = re.sub(r". ,","",s)
s = s.replace("..",".")
s = s.replace(". .",".")
s = s.replace("\n", "")
s = s.strip()
return s
df_bills['text']= df_bills["text"].apply(lambda x : normalize_text(x))
df_bills
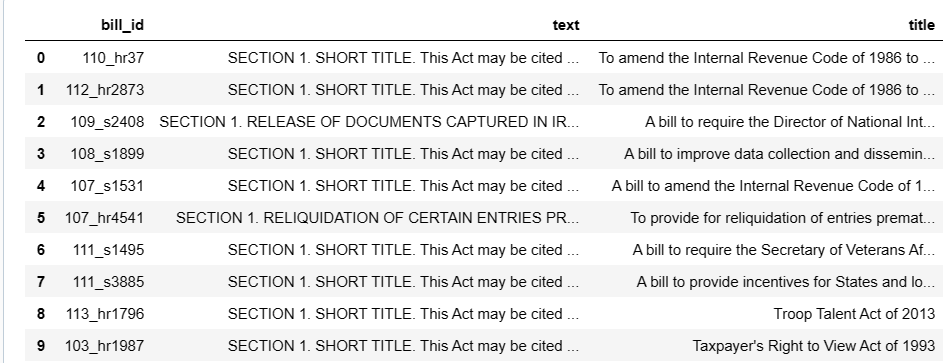
改行がなくなっていることがわかります。
ここからは、データフレームをスキーマ配下のテーブルに格納します。以下は一例です。もっと簡単に格納する方法があるかもしれません。
spark_df = spark.createDataFrame(df_bills)
catalog_name = "quickstart_catalog"
schema_name = "quickstart_schema"
source_table_name = "bill_sum_table"
table_path = f"{catalog_name}.{schema_name}.{source_table_name}"
for row in spark_df.collect():
bill_id = row['bill_id']
text = row['text'].replace("'", "''")
title = row['title'].replace("'", "''")
sql_query = f"""
INSERT INTO {table_path} (bill_id, text, title) VALUES ('{bill_id}', '{text}', '{title}')
"""
spark.sql(sql_query)
これでソース Delta テーブルが完成しました。このタイミングで変更データ フィードを有効にします。
%sql
ALTER TABLE quickstart_catalog.quickstart_schema.bill_sum_table SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
外部モデル エンドポイントの作成
ソース Delta テーブルの準備ができたので、次に外部モデル エンドポイントを作成します。 Azure Databricks が提供する基盤モデルを利用することも可能ですが、今回は Azure OpenAI Service の Embedding モデルである text-embedding-ada-002 を使用する方法をご紹介します。
手順としては、まず Azure OpenAI Service の OpenAI API キーを Azure Databricks のシークレットに登録し、UI または SDK を利用して外部モデル エンドポイントを作成することになります。
シークレットを作成して登録するのもいくつか方法がありそうですが、Databricks CLI を使った方法をご紹介します。事前に Databricks CLI をインストールしておく必要があります。
Databricks CLI を使用して次のコマンドを実行し、Azure Databricks 構成プロファイルを作成して個人用アクセス トークン認証を行います。
databricks configure --token
Databricks host: <Azure Databricks のワークスペースごとの URL>
Personal access token: <お使いのワークスペースの Azure Databricks 個人用アクセス トークン>
ワークスペース URL の確認方法は ワークスペース単位のURL - Azure Databricks が参考になります。
個人用アクセス トークンは前提条件 5 で管理したものを入力してください。
次に、Databricks CLI を利用して シークレット スコープを作成し、Azure OpenAI API キーを格納していきます。
databricks secrets create-scope "<scope 名>"
databricks secrets put-scope "<scope 名>" "openai_api_key"
put-scope コマンドを実行すると、値の入力を問われるので、そこでAPI キーの値を入力します。
ここまでできれば、あとは UI もしくは SDK を使用して Embedding モデルを登録するだけです。それぞれご紹介します。
・ UI 上で外部モデル エンドポイントを作成する
メニューから [サービング] を選択し、[エンドポイントの作成] をクリックします。

上記の画像において、[Entity details] の [Entity] をクリックすると、以下の画面がでてくるので [External model] を選択し、[OpenAI] をクリックします。
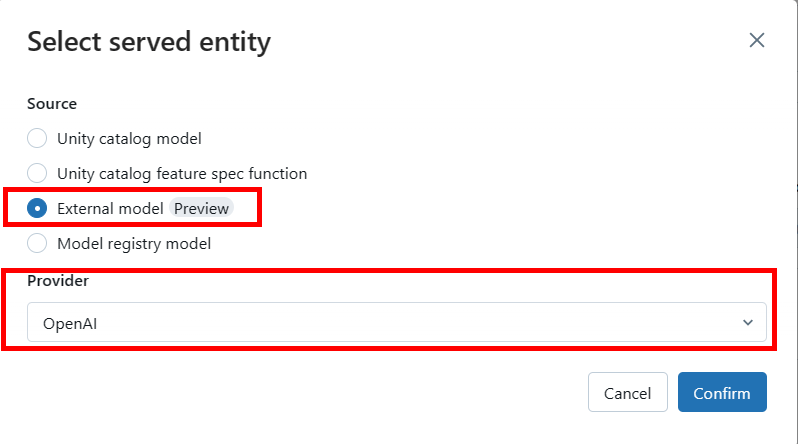
[OpenAI] をクリックすると、追加でモデルの情報を入力する必要があります。以下の画像を参考に、入力してください。
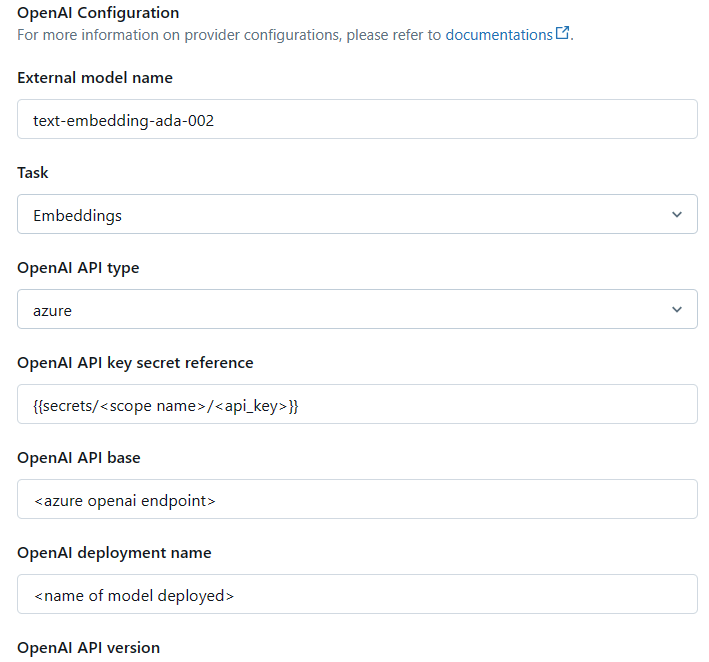
必要な情報としては、以下になります。
- External model name: Embedding モデル名 (e.g. text-embedding-ada-002)
- Task: Embeddings
- OpenAI API type: azure
- OpenAI API key secret regerence: {{secrets/<scope 名>/openai_api_key}}
- OpenAI API base: Azure OpenAI Service のエンドポイント
- OpenAI deployment name: モデルのデプロイ名
- OpenAI API version: API バージョン
特に {{secrets/<scope 名>/openai_api_key}} は Databricks CLI で格納した際のスコープ名を入力することで接続を確立します。
・ SDK で外部モデル エンドポイントを作成する
本記事作成時点でパブリック プレビューである MLflow Deployments SDK を使ってノートブック上で外部モデル エンドポイントを作成します。
必要とする構成情報は UI の場合と同じです。
import mlflow.deployments
mlflow_deploy_client = mlflow.deployments.get_deploy_client("databricks")
embedding_model_endpoint_name = "text-embedding-ada-demo"
mlflow_deploy_client.create_endpoint(
name=embedding_model_endpoint_name,
config={
"served_entities": [
{
"name": <serving endpoint name>,
"external_model": {
"name": "text-embedding-ada-002",
"provider": "openai",
"task": "llm/v1/embeddings",
"openai_config": {
"openai_api_type": "azure",
"openai_api_key": "{{secrets/<scope name>/<api_key>}}",
"openai_api_base": "https://XXX.openai.azure.com",
"openai_deployment_name": <name of model deployed>,
"openai_api_version": "2024-02-15-preview"
},
},
}
],
},
)
UI 上で作成した外部モデル エンドポイントをクライアントで取得することもできます。
mlflow_deploy_client.get_endpoint(embedding_model_endpoint_name)
ベクトル検索エンドポイントの作成
外部モデル エンドポイントを作成した後、ベクトル検索エンドポイントを作成します。簡単に説明するとベクトル検索エンドポイントとは、外部モデルエンドポイントとベクトル インデックスをつなぐためのものです。
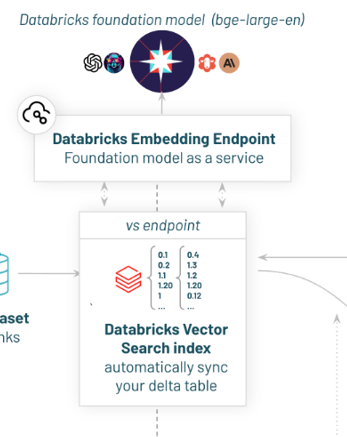
・ UI 上でベクトル検索エンドポイントを作成する
執筆時点ではメニュー上にベクトル検索エンドポイントはなく、[クラスター] もしくは [SQL ウェアハウス] からベクトル検索エンドポイントを作成することができます。
右上の作成ボタンをクリックし、エンドポイント名を入力して作成に進むだけです。
・ SDK でベクトル検索エンドポイントを作成する
以下のコードを実行します。ライブラリの更新や再インストールとそれに伴うPython環境のリセットを行うための一連の操作となります。
%pip install --upgrade --force-reinstall databricks-vectorsearch
dbutils.library.restartPython()
databricks-vectorsearch ライブラリを使用して、Databricks のベクトル検索機能を活用するための Python クライアントを初期化します。
from databricks.vector_search.client import VectorSearchClient
vsc = VectorSearchClient(disable_notice=True)
VectorSearchClient インスタンスの create_endpoint メソッドを呼び出して新しい検索エンドポイントを設定します。
vector_search_endpoint_name = "vector-search-demo"
vsc.create_endpoint(
name=vector_search_endpoint_name,
endpoint_type="STANDARD"
)
また、UI 上で作成したベクトル検索エンドポイントを取得することもできます。
vsc.get_endpoint(
name=vector_search_endpoint_name
)
databricks-vectorsearch ライブラリについては、databricks.vector_search package をご参照ください。
ベクトル検索インデックスの作成
ベクトル検索エンドポイントの作成が終わったら、あとはベクトル検索インデックスを作成するだけです。ソース Delta テーブル、外部モデル、ベクトル検索エンドポイントを情報をもとにベクトル インデックスを作成します。
作成手順に入る前に、Azure Databricks の提供するベクトル インデックスの種類について説明します。
ベクトル インデックスは 2 種類あります。
- Delta Sync Index: ソース Delta テーブルと自動的に同期し、 データが変更されると増分更新される。
- Direct Vector Access Index: ベクトルとメタデータの直接読み取りおよび書き込みをサポート。REST API と SDK のみインデックスを更新できる。
ベクトル検索機能の概要で説明した自動同期の機能は、 Delta Sync Index を作成することで有効になります。今回は Delta Sync Index を作成する手順を紹介します。
・ UI 上でベクトル検索インデックスを作成する
メニューから [カタログ] を開き、ソース Delta テーブルまで移動します。右上の三点リーダーをクリックすると [ベクトル検索インデックスを作成] と表示されるので選択します。
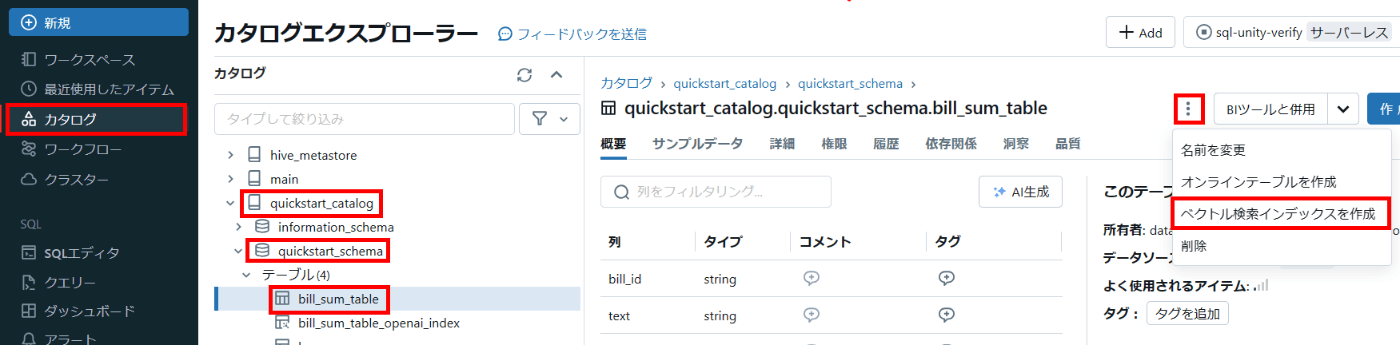
そうすると以下のような画面になります。
ベクトルインデックスを作成するための必要な構成情報を入力します。
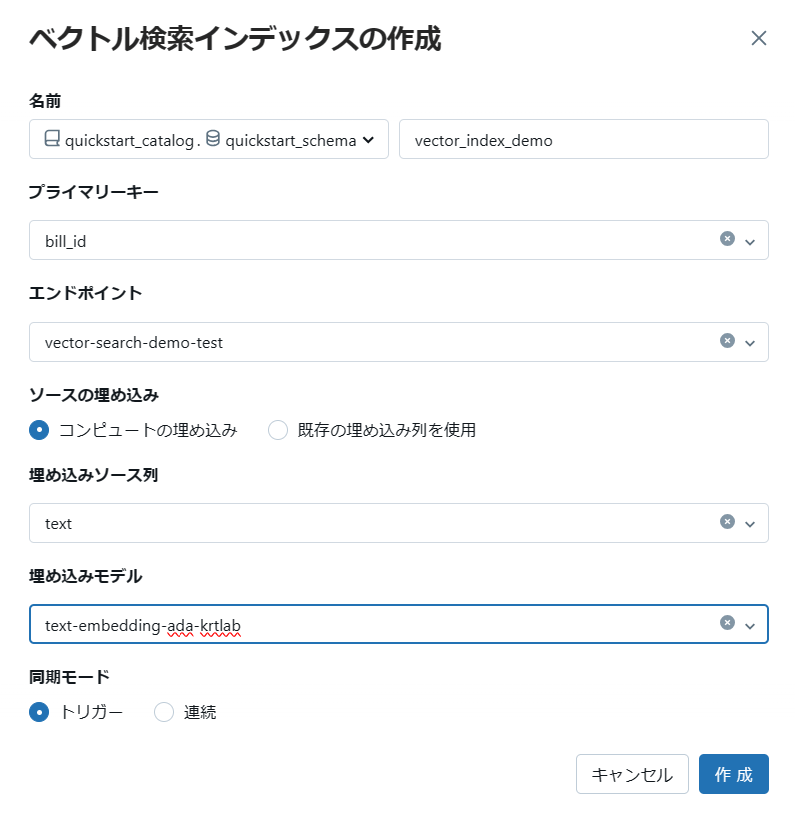
- ベクトル インデックス名: ベクトル インデックスの名前
- プライマリ キー: ソース Delta テーブルの プライマリ キー
- ベクトル検索エンドポイント: 作成済みのベクトル検索エンドポイント
- ソースの埋め込み
- コンピュートの埋め込み: 作成済みの埋め込みモデルによってソース Delta テーブルの特定列をベクトル化する
- 既存の埋め込み列を使用: すでにソース Delta テーブルにベクトル列がある場合
- 埋め込みモデル: 作成済みの外部モデルエンドポイント
-
同期モード: パイプライン実行モード
- トリガー: 実行時点で利用可能なデータに基づいてそれぞれのテーブルをアップデートし、パイプラインを実行していたクラスターを停止する。
- 連続: 連続的にテーブルを更新するため常時稼働のクラスターが必要。
必要な情報を入力したら、作成をクリックします。これでベクトル検索インデックスが作成できました。
・ SDK でベクトル検索インデックスを作成する
UI 上での方法と同様に、作成するために必要な情報をクライアントの引数に渡していきます。
catalog_name = "quickstart_catalog"
schema_name = "quickstart_schema"
source_table_name = "bill_sum_table"
table_path = f"{catalog_name}.{schema_name}.{source_table_name}"
vs_index = f"{source_table_name}_openai_index"
vs_index_fullname = f"{catalog_name}.{schema_name}.{vs_index}"
index = vsc.create_delta_sync_index(
endpoint_name=vector_search_endpoint_name,
source_table_name=table_path,
index_name=vs_index_fullname,
pipeline_type='TRIGGERED',
primary_key="bill_id",
embedding_source_column="text",
embedding_model_endpoint_name=embedding_model_endpoint_name
)
index.describe()['status']['message']
また、UI 上で作成したベクトル インデックスをクライアントから取得することもできます。
index = vsc.get_index(endpoint_name=vector_search_endpoint_name,index_name=vs_index_fullname)
検索クエリ
これで Azure Databricks のベクトル検索機能のための準備がすべて終わりました。検索クエリを投げ、類似度の高い文書を返してくれるか試してみましょう。記事作成時点では、REST API もしくは SDK のみクエリをインデックスと照合することができるみたいですので、今回は SDK でご紹介します。
results = index.similarity_search(
query_text="Can I get information on cable company tax revenue?",
columns=["bill_id", "text", "title"],
num_results=4
)
rows = results['result']['data_array']
for (bill_id, text, title, score) in rows:
if len(text) > 32:
text = text[0:32] + "..."
print(f"bill_id: {bill_id} title: {title} text: '{text}' score: {score}")

query_text には LLM アプリケーション サイドで検索クエリとして投げられたテキストが想定されます。少し見にくいですが、各列の右側に類似度スコアが降順でソートされて表示されていることがわかります。
ちなみに text-embedding-3-large モデルを使用した場合の結果もお見せします。
index = vsc.get_index(endpoint_name=vector_search_endpoint_name,index_name="quickstart_catalog.quickstart_schema.large")
results = index.similarity_search(
query_text="Can I get information on cable company tax revenue?",
columns=["bill_id", "text", "title"],
num_results=4
)
rows = results['result']['data_array']
for (bill_id, text, title, score) in rows:
if len(text) > 32:
text = text[0:32] + "..."
print(f"bill_id: {bill_id} title: {title} text: '{text}' score: {score}")

類似度スコアが変化していることがわかります。
1 つ注意点があります。
以下のドキュメントに記載されていますが、類似度評価の指標が現時点だと L2 (ユークリッド距離) しか使用できません。SDK にも類似度指標の引数はありませんでした。
Azure OpenAI Service の Embedding モデルはコサイン類似度が推奨されているので、はやく実装されてほしいですね。
Azure Databricks ベクトル検索
さいごに
執筆時点では、 Databricks のベクトル検索機能はパブリック プレビュー機能となっております。さらにユーザー エクスペリエンスが向上されていくと思いますし、この記事と仕様が異なる状態になることも十分考えられるので、その点ご容赦ください。
長くなってしまいましたが、ここまで読んでくださりありがとうございました。

Discussion