Phi-3とは
大規模言語モデル(LLM: Large Language Models)は、高度な推論/データ分析/コンテキストの理解を含む複雑なタスクの組み合わせが必要なアプリケーションに適しています。一方の小規模言語モデル(SLM: Small Language Models)は、データを自社内に保持したいことがある規制産業やクラウドにネットワーク接続されていないエッジで動作するスマートフォンなどのモバイル機器、車載コンピューター、交通管理システム、工場フロアのスマートセンサー、監視カメラ、環境適合性を監視するデバイスなどでの動作に適しています。
また、低レイテンシが求められるシーンでも活用できます。レイテンシとは、LLM がクラウドと通信し、ユーザーのプロンプトに対する回答を生成するための情報を取得する際に発生する遅延のことです。高品質な回答を待つ価値がある場合もあれば、ユーザー満足度のためにはスピードの方が重要な場合もあります。SLM はオフラインで動作するため、これまでは不可能だった方法で生成AIを活用できる可能性があります。
そんな中、Microsoftは、2024年4月にオープンソースのSLMである「Phi-3」を公開しました。Phi-3 モデルは、高性能でコスト効率に優れた、SLMで、さまざまな言語、推論、コーディング、数学のベンチマークで、同サイズのモデルよりも優れたパフォーマンスを発揮しています。詳しくは「Tiny but mighty: The Phi-3 small language models with big potential」を参照してください。
そして、Microsoftは5月23日に開催された開発者向けイベント「Microsoft Build 2024」で、SLMであるPhi-3ファミリーに、新しくマルチモーダルAIモデルである 「Phi-3 vision」 を追加しました。Phi-3 visionは、画像とテキストを入力し、テキスト応答を出力する機能があります。たとえば、図表に関する質問や、画像に関する質問をすることができます。
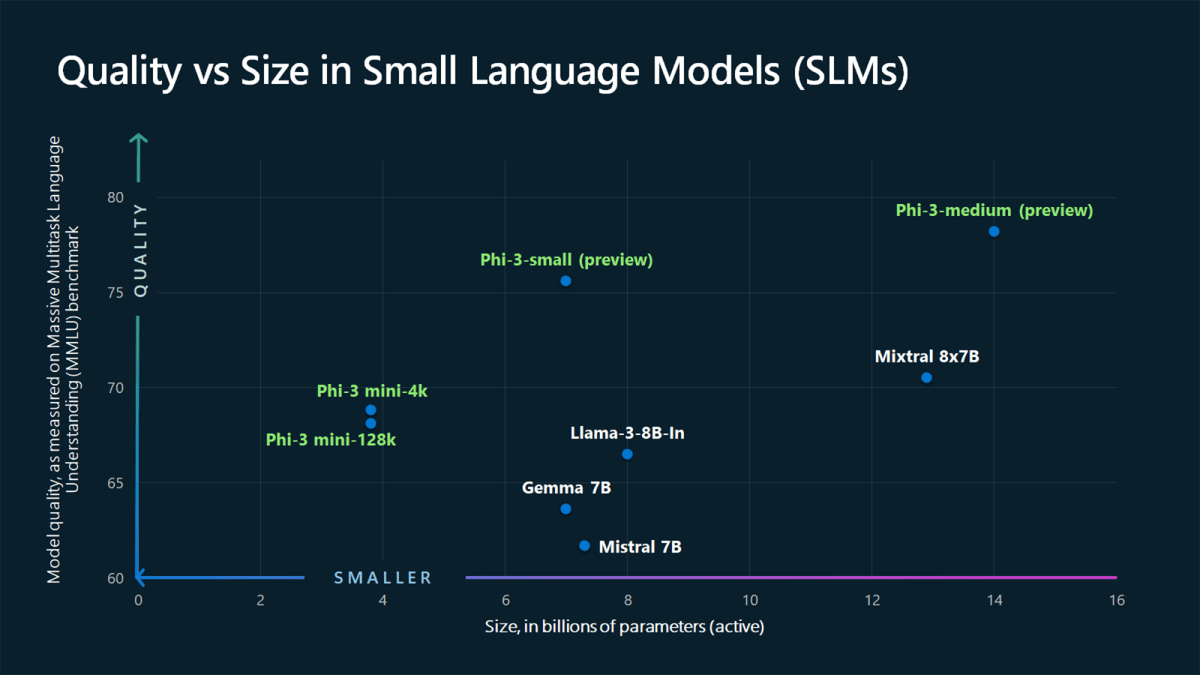
執筆時点では、Phi-3 ファミリには次の4つのモデルがあります。
| モデル名 | 説明 |
|---|---|
| Phi-3-vision | 言語と視覚機能を備えた 42 億パラメータのマルチモーダル モデル |
| Phi-3-mini | 3.8B パラメータの言語モデルで、2 つのコンテキスト長 ( 128Kと4K ) |
| Phi-3-small | 7B パラメータの言語モデルで、2 つのコンテキスト長 ( 128Kと8K ) |
| Phi-3-medium | 14B パラメータの言語モデルで、2 つのコンテキスト長 ( 128Kと4K ) |
現在Phi-3は、Azure AI StudioとHugging FaceとOllamaで利用可能です。
ただし、最も新しいPhi-3 visionは、Azure AI Studioと、Hugging Faceのみで利用可能で、Ollamaについては、こちらのissueにあるように、まだ利用できません。Ollama ユーザなので、なんとかOllamaで動作できるようソースコードをがんばって追いかけていきたいと思います。
この記事では、ローカルPCでHugging Faceを使ってPhi-3 visionを動かす方法を紹介します。
事前準備
まず、Hugging Face CLIをインストールします。
pip install -U "huggingface_hub[cli]"
Hugging Faceからtokenを使って、ログインします。tokenは、Hugging Faceの[Settings]-[Access Token]から取得できます。
huggingface-cli login
ログインが成功すると次のようになります。
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
To login, `huggingface_hub` requires a token generated from https://huggingface.co/settings/tokens .
Token:
Add token as git credential? (Y/n)
Token is valid (permission: write).
Your token has been saved in your configured git credential helpers (store).
Your token has been saved to /home/wauplin/.cache/huggingface/token
Login successful
次に、git large file system extensionをインストールします。
Windowsの場合
winget install -e --id GitHub.GitLFS
Linux(Ubuntu)の場合
apt-get install git-lfs
macOSの場合
brew install git-lfs
これで準備が整いました。
ONNX Runtime generate APIでPhi-3 visionを動かす
Phi-3 visionは、onnxruntime-genai 0.3.0-rc2 以降のバージョンでサポートされています。動作させるプラットフォームによって以下のいずれかを実行します。
1. NVIDIA CUDAの場合
次のコマンドを実行すると、「cuda-int4-rtn-block-32」というフォルダにモデルがダウンロードされます。
huggingface-cli download microsoft/Phi-3-vision-128k-instruct-onnx-cuda --include cuda-int4-rtn-block-32/* --local-dir .
もし、CUDA Toolkitがインストールされていない場合は、CUDA Toolkit ArchiveからCUDA Toolkitをダウンロードしてインストールしてください。
次のコマンドで、ONNX Runtimeのgenerate APIをインストールします。
pip install numpy
pip install --pre onnxruntime-genai-cuda --index-url=https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-genai/pypi/simple/
動作確認用のサンプルコードがあるので、ダウンロードします。
wget https://raw.githubusercontent.com/microsoft/onnxruntime-genai/main/examples/python/phi3v.py
ソースコードの中を覗いてみましょう。
import argparse
import os
import readline
import glob
import onnxruntime_genai as og
def _complete(text, state):
return (glob.glob(text+'*')+[None])[state]
def run(args: argparse.Namespace):
print("Loading model...")
model = og.Model(args.model_path)
processor = model.create_multimodal_processor()
tokenizer_stream = processor.create_stream()
while True:
readline.set_completer_delims(' \t\n;')
readline.parse_and_bind("tab: complete")
readline.set_completer(_complete)
image_path = input("Image Path (leave empty if no image): ")
image = None
prompt = "<|user|>\n"
if (len(image_path) == 0):
print("No image provided")
else:
print("Loading image...")
if not os.path.exists(image_path):
raise FileNotFoundError(f"Image file not found: {image_path}")
image = og.Images.open(image_path)
prompt += "<|image_1|>\n"
text = input("Prompt: ")
prompt += f"{text}<|end|>\n<|assistant|>\n"
print("Processing image and prompt...")
inputs = processor(prompt, images=image)
print("Generating response...")
params = og.GeneratorParams(model)
params.set_inputs(inputs)
params.set_search_options(max_length=3072)
generator = og.Generator(model, params)
while not generator.is_done():
generator.compute_logits()
generator.generate_next_token()
new_token = generator.get_next_tokens()[0]
print(tokenizer_stream.decode(new_token), end='', flush=True)
for _ in range(3):
print()
# Delete the generator to free the captured graph before creating another one
del generator
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-m", "--model_path", type=str, required=True, help="Path to the model")
args = parser.parse_args()
run(args)
このPythonスクリプトは、ユーザーからの入力(テキストと画像)を受け取り、指定されたモデルを使用して応答を生成します。
以下に、主な処理の流れを説明します:
- モデルのロード
og.Model(args.model_path)で指定されたパスからモデルをロードします。
- プロセッサの作成
model.create_multimodal_processor()でモデルからマルチモーダルプロセッサを作成します。このプロセッサは、テキストと画像の両方を処理できます。
- 入力の受け取り
ユーザーから画像のパスとテキストのプロンプトを入力として受け取ります。画像が提供された場合、その画像はロードされ、プロンプトと一緒にプロセッサに送信されます。
- レスポンスの生成
プロセッサが入力を処理した後、og.Generator(model, params)を使用して応答を生成します。
- 出力
生成されたトークンはデコードされ、ターミナルに出力されます。
次のコマンドでサンプルコードを実行しましょう
python phi3v.py -m cuda-int4-rtn-block-32
2. CPUの場合
次のコマンドを実行すると、「cpu-int4-rtn-block-32-acc-level-4」というフォルダにモデルがダウンロードされます。
huggingface-cli download microsoft/Phi-3-vision-128k-instruct-onnx-cpu --include cpu-int4-rtn-block-32-acc-level-4/* --local-dir .
次のコマンドで、ONNX Runtimeのgenerate APIをインストールします。GPU用のものとは異なるので注意してください。
pip install numpy
pip install --pre onnxruntime-genai
おなじく、動作確認用のサンプルコードをダウンロードします。
wget https://raw.githubusercontent.com/microsoft/onnxruntime-genai/main/examples/python/phi3v.py
次のコマンドでサンプルコードを実行します。
python phi3v.py -m cpu-int4-rtn-block-32-acc-level-4
精度の検証
今回は、こちらの画像を使って検証してみました。

「クルーズ・オリジン」は、本田技研工業がHonda GM Cruise Holdings LLC(以下Cruise)とゼネラルモーターズ(以下GM)とで共同開発している自動運転モビリティサービス専用車両です。自動運転レベル4相当の自動運転技術を搭載しているため運転席はなく、運転席分のスペースを客室として使用しており、最大6名まで乗車できます。また、さまざまなユーザーが乗り降りしやすいよう、低床プラットフォームを採用しているほか、量産車としては世界初となる左右両側の両開きスライドドアを実現しています。
参考: ホンダ、自動運転車両「クルーズ・オリジン」の試作車が完成─米国でのテスト走行や開発者のインタビュー映像を公開
Phi-3 visionの出力結果
まずは、 Phi-3 visionを使って画像に関する質問をしてみました。
A. 英語プロンプトの場合
次のプロンプトを入力しました。
Please explain this image.
出力結果
The image showcases a futuristic car, predominantly white in color, with a striking red roof. The car is equipped with two black spoilers on either side, adding to its sporty aesthetic. The front of the car is adorned with a black grille, and the wheels are black with silver rims, giving it a sleek and modern look. The car is positioned facing the left side of the image, with its doors open, suggesting a sense of readiness and openness. The background is a simple gray, which further accentuates the car's design and color. The car's position and the open doors might suggest it's ready for a journey or a test drive. The overall image gives a sense of a car that is not just a mode of transportation, but a statement piece in itself.
白を基調として赤いルーフがあるなど、画像の特徴をとらえているのが分かります。ただし、画像ではドアは閉まっているものの、ドアの状態が空いていると認識されているのが気になります。また、「The overall image gives a sense of a car that is not just a mode of transportation, but a statement piece in itself.」という表現も独自の考察をしていて興味深いです。ただし、この車がクルーズオリジンであるということは認識されていません。
B. 日本語プロンプトの場合
Phi-3に限らず、SLMはパラメータも少なくLLMに比べて日本語の処理が苦手なことが多いです。今回は、次のプロンプトを入力しました。
この画像を説明してください。
出力結果
This image shows a futuristic car with a sleek design, predominantly white with black and red accents. The car has a large front grille, two large air intakes on either side of the hood, and a prominent spoiler on the back. The roof is a vibrant red, contrasting with the white body of the car. The car has four doors, two of which are open, revealing the interior which includes two seats and a steering wheel. The wheels are black with silver rims. The car is positioned on a plain, light-colored background, which makes the car stand out prominently.
日本語で質問しているにもかかわらず、英語での回答です。回答内容も英語の場合とほぼ同じですが、やや短い表現になっています。こちらも、クルーズオリジンであるということは認識されていません。
GPT-4oの出力結果
Microsoft Build 2024では、LLMのマルチモーダルモデルであるGPT-4oのGAも発表されました。この高速かつ高精度なマルチモーダルLLMと、Phi-3 visionとを比較してみたいと思います。GPT-4oはローカルではなく、Azure上のエンドポイントに対してCallしています。
この、GPT-4oを使って同じ画像に対して同じ質問をしてみました。
A. 英語プロンプトの場合
次のプロンプトを入力しました。
Please explain this image.
出力結果
This image shows a futuristic, autonomous vehicle designed by Cruise, a subsidiary of General Motors. The vehicle, known as the Cruise Origin, is an electric, self-driving car that is intended for ride-sharing services.
Key features of the vehicle include:
- Sensors and Cameras: The car is equipped with multiple sensors and cameras on the roof and sides, which are essential for its autonomous driving capabilities. These sensors help the vehicle navigate and detect obstacles in its environment.
- Design: The design is boxy and spacious, optimized for passenger comfort and maximizing interior space. It has large windows and sliding doors for easy entry and exit.
- No Driver Controls: Unlike traditional cars, the Cruise Origin does not have a steering wheel or pedals, as it is fully autonomous.
- Electric Power: The vehicle is electric, contributing to reduced emissions and a more sustainable mode of transportation.
The Cruise Origin represents a step towards the future of urban mobility, focusing on shared, autonomous, and electric transportation solutions.
きちんとのクルーズオリジンであるということが認識されています。また、車両の特徴も、見た目以外の情報も含めて出力されています。これは、おそらくモデルの中にクルーズオリジンに関する知識が含まれているのだとおもいます。ただし、Honda GM Cruise Holdings LLCとゼネラルモーターズとで共同開発されているという説明は入っていません。
B. 日本語プロンプトの場合
同じく日本語のプロンプトを入力しました。
この画像を説明してください。
出力結果
この画像には、未来的なデザインの自動車が写っています。この車は、白と黒を基調としたボディに、オレンジ色のアクセントが施されています。また、車の前後に大きなセンサーやカメラのようなものが取り付けられており、自動運転技術を搭載していることが示唆されます。全体的にコンパクトで四角い形状をしており、窓が大きく、視界が広いデザインとなっています。車の前面には「cruise」というロゴが見えます。この車は、都市部での自動運転車両として設計されている可能性があります。
Phi-3 visionの場合とは異なり、日本語で質問すると日本語で回答を返しました。クルーズというロゴが見えるというように画像を認識していますが、これがクルーズオリジンであるかどうかの言及はされていません。英語に比べると、情報量が少なく、画像から見た情報をそのまま返しているように見えます。
まとめ
Phi-3ファミリーはまだ出てきて間もないため、今後もモデルの改良が進められることと期待しています。ただし、今時点では、精度に関してまだまだLLMには及ばないという印象を受けました。あと、SLMを動作させるためのハードウエアの制約もまだまだ大きく、GPUがないと実用には耐えられない状況です。
とはいえ、ネットワーク的な制約や低レイテンシーが求められる車載コンピューター、交通管理システム、工場フロアのスマートセンサー、監視カメラ、環境適合性を監視するデバイスなどでの活用を考えると、マルチモーダルで処理できるPhi-3 visionは、今後の発展が楽しみです。
ただし、SLMを大規模に運用するとき、どのようにモデルを配布するのかや、モデルのバージョンをどう管理するのかなどのプラットフォームの整備も必要になってくると思います。また、今回の記事で取り上げた画像を使っての応答速度をみるため、いくつか条件を変えて測定したので後日まとめたいと思います。
というわけで、取り急ぎ、ローカルPCでPhi-3 visionを動かす方法を紹介しました。ぜひ、試してみてください。
参考

Discussion
Windows環境では、readlineパッケージが動かないので、pyreadline3で代替する必要があります。
このような感じで、最初、WSL2環境で動かそうとしたのですが、どうやら、CUDA-Toolkitの11.xが入っていないと動かなそうなので、まだ、11.xが入っているWindows環境のほうで試しました。