はじめに
Azure Batch は、Azure 上で大規模な並列処理を行うためのサービスです。
Azure Batch を利用することで、コンピューティングノード(仮想マシン)での処理を自動的にスケジュールしたり、タスクの実行状況を監視したりできます。
ただ、Azure Batch に関する日本語の情報はあまり多くないため、なかなか手を出しにくいという方も多いのではないでしょうか。
今回は、Azure Batch を利用して物体検出モデル (YOLOv8) を動かしてみたので、その手順を共有したいと思います。
Azure Batch の諸概念
実際の実装をする前に、Azure Batch 特有の概念がいくつかあるので、まずはそれらを理解しておきましょう。
ノード
ノードは実際に処理を実行するコンピューティングリソース(仮想マシン)です。
ノードのサイズによって、CPU のコア数やメモリの量を指定できます。
また、ノードでは Windows と Linux の両方を利用できます。
プール
プールは、ノードの集合体です。
アプリケーションのインストールやノードのスケーリングなど、プール単位で管理します。
プールはノードに一意の IP アドレスを割り当てることができ、プール内のノードは割り当てられた IP アドレスを使用して通信をします。
異なるプール間での通信は、Azure Virtual Network を利用する必要があります。

タスク
タスクは、実際にノードで実行するためのプログラム(スクリプト)です。
タスクは、プールに対して送信され、ノードが一杯の場合はキューで待機します。
また、タスクには 開始タスク と 終了タスク があり、それぞれノードのセットアップやクリーンアップを行うことができます。
ですので、ライブラリのインストールやデータのダウンロードなどは開始タスクで行い、タスクの実行終了後、不要になったデータの削除などを終了タスクで行うことができます。

ジョブ
ジョブは、タスクの集合体です。
タスクの最大試行回数やタイムアウト時間などを一括で指定できます。
全体像
上記の概念を組み合わせると、以下のような全体像になります。

予め、Blob Storage にプログラムで実行するための資材をアップロードしておき、ジョブを作成するとタスクがプールに送信され、ノードで実行されます。
実行結果はノードの中に置いておくのではなく、Blob Storage にアップロードし、ノードが削除されても実行結果が消えないようにしておきましょう。
実装編
ここからは、実際に Azure でリソースを作成し、物体検出モデル (YOLOv8) を動かしてみます。
Azure Batch アカウントの作成
まずは、Azure Batch アカウントをポータルでポチポチして作成します。
検索ボックスから「batch アカウント」を検索し、batch アカウントの画面を開きます。
作成画面で前の手順で作成した、リソースグループ名、batch アカウント名とリージョンを指定します。
その後、ストレージ アカウントの選択 をクリックし、ストレージ アカウントを作成します。

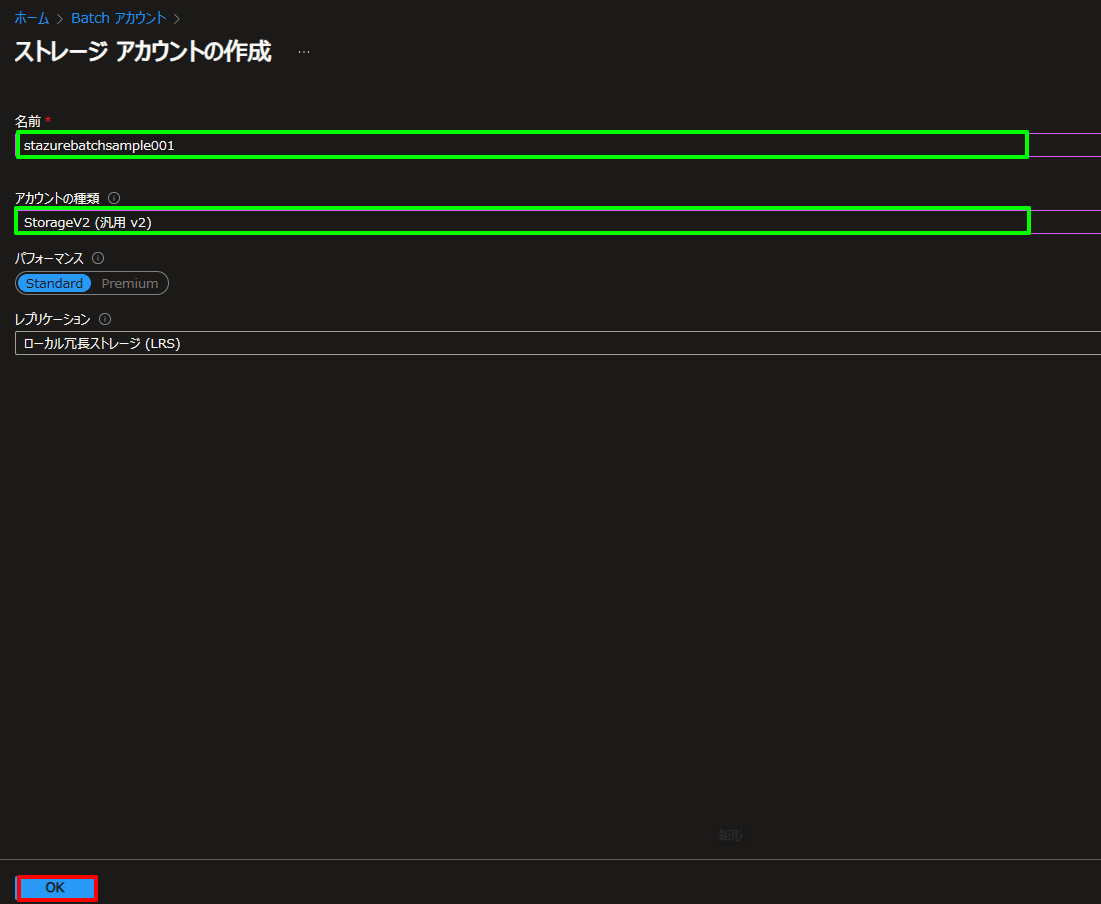
ストレージ アカウントの選択 をクリックすると、ストレージ アカウントの作成画面が開きます。
今回は新規作成を選択し、ストレージ アカウント名とリージョンを指定します。
実行資材の準備
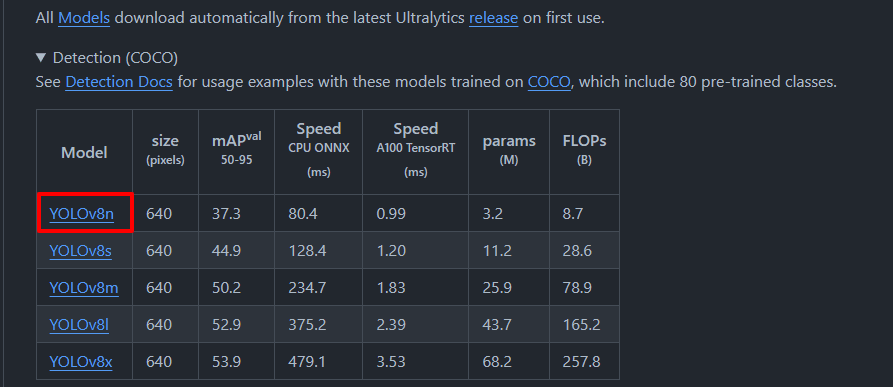
まずは GitHub から物体検出モデル (YOLOv8) の事前学習済みモデルをダウンロードします。
README.md の中盤辺りに書かれているモデル一覧の表から、YOLOv8n のモデルをダウンロードします。
ついでにサンプル画像もダウンロードしておきます。

サンプル画像
画像を Blob Storage から読み込んで、物体検出したあと、結果を Blob Storage に書き込むプログラムを sample.py として作成します。
import os
from azure.storage.blob import BlobServiceClient
from ultralytics import YOLO
TARGET_FILE_NAME="bus.jpg"
CONTAINER_NAME="output"
CONNECTION_STRING="<Blob ストレージの接続文字列>"
def upload_to_blob():
blob_service_client = BlobServiceClient.from_connection_string(CONNECTION_STRING)
container_client = blob_service_client.get_container_client(container=CONTAINER_NAME)
with open(f"./runs/detect/predict/{TARGET_FILE_NAME}", "rb") as data:
container_client.upload_blob(name=TARGET_FILE_NAME, data=data)
# ファイル削除
os.remove(f"./runs/detect/predict/{TARGET_FILE_NAME}")
if __name__ == "__main__":
model = YOLO("yolov8n.pt")
result = model.predict("bus.jpg", save=True)
upload_to_blob()
また、 CONNECTION_STRING には、Blob ストレージの接続文字列を入れておきます。(本番環境ではソースコードにハードコートせず、環境変数から読み込むなど工夫してください)
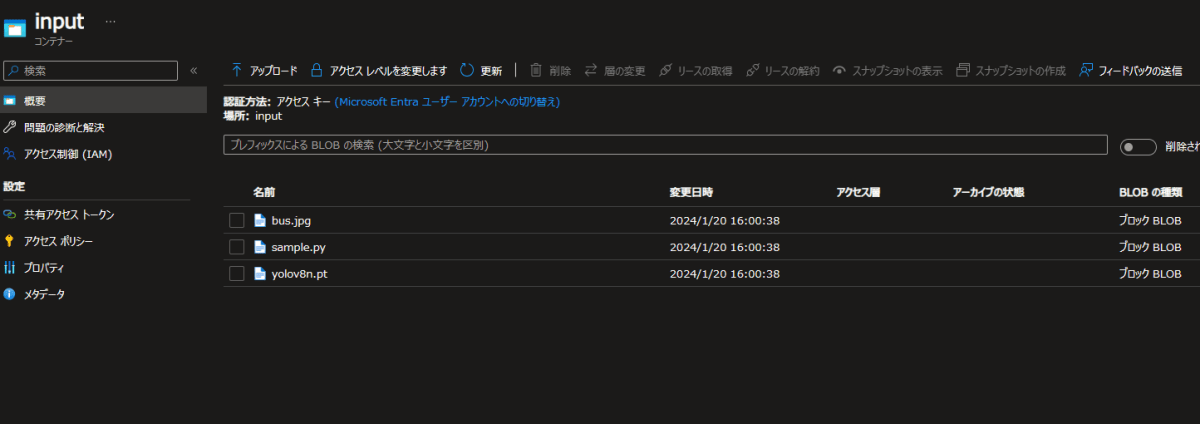
資材を準備したあと、Blob Storage に input と output という名前のコンテナを作成し、sample.py bus.jpg yolov8n.pt を input コンテナにアップロードします。
プールの作成
次に、ノードを実行するためのプールを作成します。
今回は Python の azure-batch ライブラリを利用してプールを作成します。
create_pool.py を作成し、以下のコードを記述します。
create_pool.py
import azure.batch.models as batchmodels
import azure.batch.batch_auth as batchauth
from azure.batch import BatchServiceClient
BATCH_ACCOUNT_ID = '<ポータルで作成した Batch アカウント名>'
BATCH_ACCOUNT_KEY = '<Batch アカウントキー>'
BATCH_ACCOUNT_LOCATION = 'japaneast'
BATCH_ACCOUNT_URL = f'https://{BATCH_ACCOUNT_ID}.{BATCH_ACCOUNT_LOCATION}.batch.azure.com'
BATCH_POOL_ID = 'pool-sample-001'
BATCH_POOL_IMAGE_SIZE = 'Standard_D2S_v3'
BATCH_POOL_VM_COUNT = 2
# 開始タスクで実行するコマンド
BATCH_START_COMMANDS = [
# パッケージの更新・インストール
'apt-get -y update && apt-get -y upgrade',
"apt-get install -y software-properties-common ffmpeg libsm6 libxext6",
'add-apt-repository -y ppa:deadsnakes/ppa',
# python3.10 インストール
'apt-get install -y python3.10',
'ln -sfn /usr/bin/python3.10 /usr/bin/python',
# pip インストール
'curl -fSsL https://bootstrap.pypa.io/get-pip.py | python',
# 必要なライブラリのインストール
"pip install ultralytics==8.0.235",
"pip install azure-storage-blob==12.19.0",
"pip install cffi",
]
def get_batch_client() -> BatchServiceClient:
"""BatchServiceClient インスタンスを取得する"""
credentials = batchauth.SharedKeyCredentials(
BATCH_ACCOUNT_ID,
BATCH_ACCOUNT_KEY
)
batch_client = BatchServiceClient(
credentials,
batch_url=BATCH_ACCOUNT_URL
)
return batch_client
def create_pool(batch_client: BatchServiceClient):
"""Batch Pool を作成する"""
# 実行権限を付与
user = batchmodels.AutoUserSpecification(
scope=batchmodels.AutoUserScope.pool,
elevation_level=batchmodels.ElevationLevel.admin
)
pool = batchmodels.PoolAddParameter(
id=BATCH_POOL_ID,
virtual_machine_configuration=batchmodels.VirtualMachineConfiguration(
image_reference=batchmodels.ImageReference(
publisher='Canonical',
offer='0001-com-ubuntu-server-focal',
sku='20_04-lts-gen2',
version='latest'
),
node_agent_sku_id='batch.node.ubuntu 20.04'
),
vm_size=BATCH_POOL_IMAGE_SIZE,
target_dedicated_nodes=BATCH_POOL_VM_COUNT,
start_task=batchmodels.StartTask(
command_line=(
f'/bin/bash -c '
f'\'set -e; set -o pipefail; {";".join(BATCH_START_COMMANDS)}; wait\''
),
user_identity=batchmodels.UserIdentity(auto_user=user),
wait_for_success=True
),
)
batch_client.pool.add(pool)
if __name__ == '__main__':
batch_client = get_batch_client()
create_pool(batch_client)
BATCH_START_COMMANDS には、ノードで開始タスクとして実行するコマンドを記述します。
ここでは、Python 3.10 のインストールと、必要なライブラリのインストールを行っています。
また、ノードの実行環境は Ubuntu 20.04 で実行するように設定しています。
コードを作成したら、実行してみましょう。
python create_pool.py
プールの作成が完了したら、プールの状態をポータルで確認してみましょう。

ジョブの作成
ジョブでは、タスクの実行に必要な情報を指定します。
今回は特に複雑なことはせず、タスクの実行に必要な場所を指定するだけです。
create_job.py を作成し、以下のコードを記述します。
import azure.batch.models as batchmodels
import azure.batch.batch_auth as batchauth
from azure.batch import BatchServiceClient
BATCH_ACCOUNT_ID = '<ポータルで作成した Batch アカウント名>'
BATCH_ACCOUNT_KEY = '<Batch アカウントキー>'
BATCH_ACCOUNT_LOCATION = 'japaneast'
BATCH_ACCOUNT_URL = f'https://{BATCH_ACCOUNT_ID}.{BATCH_ACCOUNT_LOCATION}.batch.azure.com'
BATCH_POOL_ID = 'pool-sample-001'
BATCH_JOB_ID = 'job-sample-001'
def get_batch_client() -> BatchServiceClient:
"""BatchServiceClient インスタンスを取得する"""
credentials = batchauth.SharedKeyCredentials(
BATCH_ACCOUNT_ID,
BATCH_ACCOUNT_KEY
)
batch_client = BatchServiceClient(
credentials,
batch_url=BATCH_ACCOUNT_URL
)
return batch_client
def create_job(batch_client: BatchServiceClient):
"""Batch Job を作成する"""
job = batchmodels.JobAddParameter(
id=BATCH_JOB_ID,
pool_info=batchmodels.PoolInformation(pool_id=BATCH_POOL_ID)
)
batch_client.job.add(job)
if __name__ == "__main__":
batch_client = get_batch_client()
create_job(batch_client)
コードを作成したら、実行してみましょう。
python create_job.py
ジョブの作成が完了したら、ジョブの状態をポータルで確認してみましょう。

タスクの作成
タスクでは、実際にノードで実行するプログラムを指定します。
create_task.py を作成し、以下のコードを記述します。
create_task.py
import azure.batch.models as batchmodels
import azure.batch.batch_auth as batchauth
from azure.batch import BatchServiceClient
BATCH_ACCOUNT_ID = '<ポータルで作成した Batch アカウント名>'
BATCH_ACCOUNT_KEY = '<Batch アカウントキー>'
BATCH_ACCOUNT_LOCATION = 'japaneast'
BATCH_ACCOUNT_URL = f'https://{BATCH_ACCOUNT_ID}.{BATCH_ACCOUNT_LOCATION}.batch.azure.com'
BATCH_POOL_ID = 'pool-sample-001'
BATCH_JOB_ID = 'job-sample-001'
BATCH_TASK_ID = 'task-sample-001'
BLOB_BATCH_SCRIPT_FILE_NAME = 'sample.py'
BLOB_BATCH_SCRIPT_CONTAINER_NAME = 'input'
def get_batch_client() -> BatchServiceClient:
"""BatchServiceClient インスタンスを取得する"""
credentials = batchauth.SharedKeyCredentials(
BATCH_ACCOUNT_ID,
BATCH_ACCOUNT_KEY
)
batch_client = BatchServiceClient(
credentials,
batch_url=BATCH_ACCOUNT_URL
)
return batch_client
def create_task(batch_client: BatchServiceClient):
"""Batch Task を作成する"""
task = batchmodels.TaskAddParameter(
id=BATCH_TASK_ID,
command_line=f'python {BLOB_BATCH_SCRIPT_FILE_NAME}',
resource_files=[
batchmodels.ResourceFile(
file_path=".",
auto_storage_container_name=BLOB_BATCH_SCRIPT_CONTAINER_NAME,
),
]
)
batch_client.task.add(job_id=BATCH_JOB_ID, task=task)
if __name__ == "__main__":
batch_client = get_batch_client()
create_task(batch_client)
BLOB_BATCH_SCRIPT_FILE_NAME には、実行するプログラムのファイル名を指定します。
今回は、Blob Storage にアップロードした sample.py を指定しています。
ポータルでジョブの状態を確認すると、タスクが追加され、ノードで実行されていることが確認できます。

状態 が 完了 になったら、Blob Storage に output コンテナを開いてみましょう。
bus.jpg というファイルがアップロードされているはずです。

ダウンロードしてみると、物体検出の結果が書き込まれていることが確認できます。
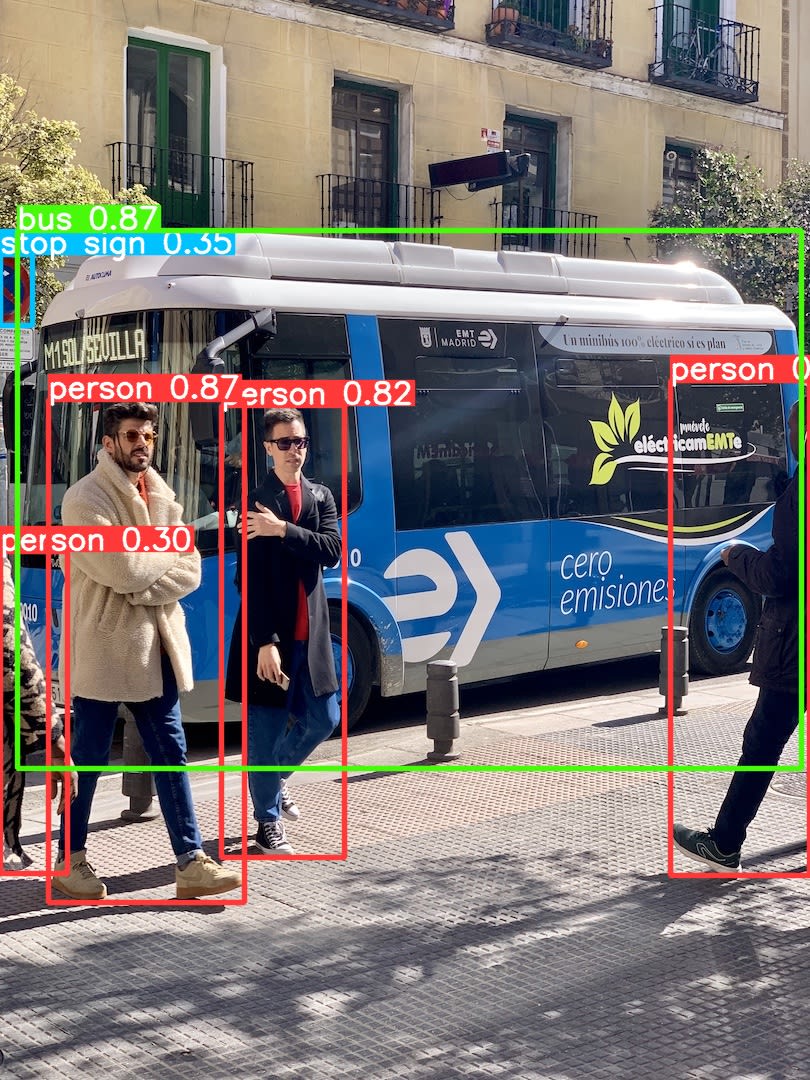
出力結果
まとめ
今回は、Azure Batch を利用して物体検出モデル (YOLOv8) を動かしてみました。
実運用する場合は、プログラムの再利用性を考慮したり、ノードのスケーリングを自動化したりするなどの工夫がさらに必要ですが、Azure Batch を利用することで大規模な並列処理を簡単に実現できます。
今回の記事を通して、Azure Batch の基本的な使い方を理解していただけたら幸いです。
参考文献

Discussion