はじめに
最近、本番環境で Azure OpenAI Service を導入する事例が増えてきているように感じます。
Azure OpenAI Service の素の API 自体がどれくらいのリクエストに耐えられるのか、個人的にも気になっていました。
そこで具体的なシナリオを想定して、JMeter と Taurus で負荷テストしてみたので、その手順と結果を共有したいと思います。
※筆者自身も負荷テストは初めてなので、間違っている点があればご指摘いただけますと幸いです。
JMeter と Taurus について
JMeter とは
JMeter は、Apache Software Foundation が開発しているオープンソースの負荷テストツールです。
HTTP 以外にも、FTP や JDBC などのプロトコルにも対応しており、様々なシナリオでの負荷テストが可能です。操作性も良く、GUI でもシナリオを作成できます。
Taurus とは
Taurus は、BlazeMeter 社が開発しているオープンソースの負荷テストツールです。
JMeter だけでは可視化や分析を直感的に行うことが難しいため、Taurus は JMeter のラッパーとして機能し、負荷テストの実行、可視化、分析ができます。
また、JMeter 以外の負荷テストツールとも連携できるため、負荷テストツールの選択肢を広げることができます。
インストールは以下のコマンドを実行するだけです。
pip install bzt
JMeter でシナリオを .jmx ファイルとして作成・保存し、以下のコマンドを実行することで負荷テストを実行し、簡単にブラウザ上にレポートを出力できます。
bzt sample-scenario.jmx -report
Taurus については、手軽に負荷テストができるツール「Taurus」がスゴいの記事で非常に分かりやすくまとめられているので、ぜひご覧ください。
今回テストするシナリオ
今回は、Azure OpenAI Service の Rest API である Chat Completions を利用したシナリオを想定しています。
Chat Completions はチャットにおける会話の続きを生成することを想定しているため、入力された文章に対して、会話の文脈を考慮して文章を生成してくれます。
今回テストするシナリオは以下の通りです。
質問トークン数を変化させている意図として、質問トークン数が多いほど、返答でより長い文章を生成させるため、レスポンス時間が大きく異なると想定されます。それにより、結果が変わるのかどうかを確認したいと考えています。
| シナリオ | チャットのトークン数 | ユーザー数/min | 各ユーザのチャット数/min |
|---|---|---|---|
| 001 | 50 | 10 | 2 |
| 002 | 50 | 100 | 2 |
| 003 | 200 | 100 | 2 |
| 004 | 50 | 10 | 20 |
| 005 | 200 | 10 | 20 |
各トークン数に応じた質問内容は以下の通りです。
- 50 トークン:「あなたの答えられる質問について教えてくださいませんでしょうか?」
- 200 トークン:「現代のアプリケーションの設計と拡張性に影響を与えるシステムの主要な原則と、負荷分散、データ整合性などの要因を考慮する際の説明をしていただけますか?さらに、組織が今日の急速に変化するテクノロジーで分散アプリケーションのセキュリティを確保する方法についても教えていただけますか?」
使用したモデルは gpt-35-turbo でキャパシティを 120 K トークンとしています。
また、システムプロンプト・各パラメータについてはすべて以下のように設定しています。
{
"messages": [
{
"role": "system",
"content": "Assistant is a large language model trained by OpenAI."
},
{
"role": "user",
"content": "<トークン数に応じた質問内容>"
}
],
"max_tokens": 800,
"temperature": 0.7,
"frequency_penalty": 0,
"presence_penalty": 0,
"top_p": 0.95,
"stop": [
"<|im_end|>"
]
}
テスト環境
今回は Azure の Virtual Machine を使用して、負荷テストを行いました。
OS は Windows 11 で、VM サイズは Standard_B4s_v2(4 vcpu, 16 GiB メモリ)です。
テスト結果のレポート
50トークン|10ユーザー|2チャット
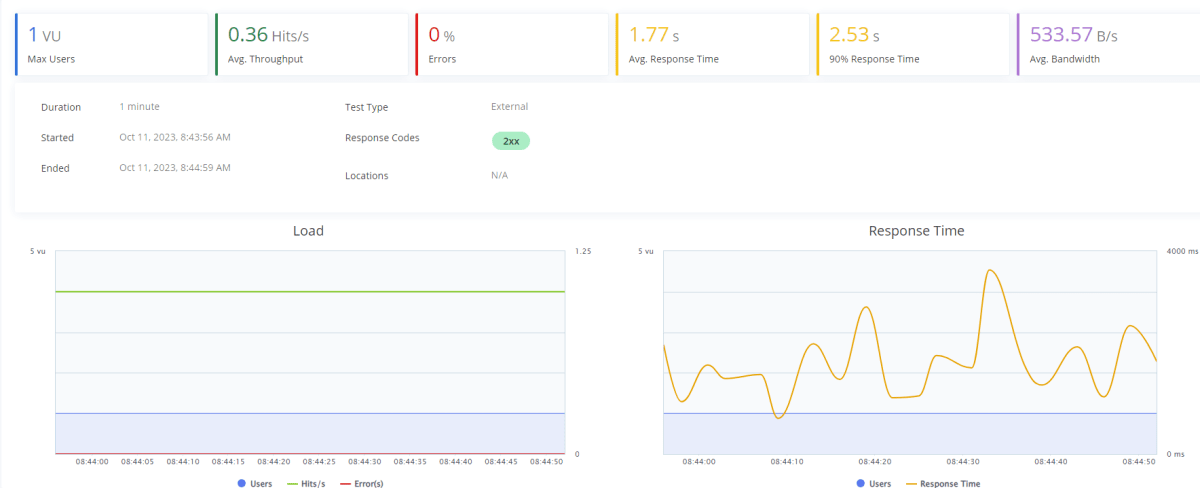
流石に楽勝ですね。もう少し負荷がかかるようにユーザー数を増やしてみます。
50トークン|100ユーザー|2チャット
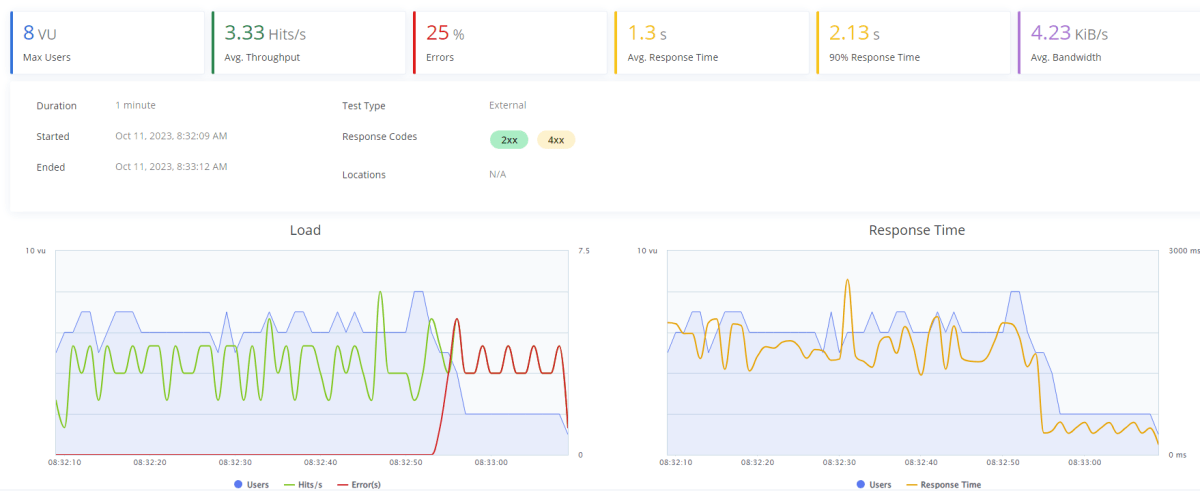
ユーザは最大でも 8 人しか溜まっていないものの、許容トークン数を超えているため、後半でエラーが発生しています。
エラーはすべてトークン数を超過したというエラーが出ています。
{
"error":{
"code":"429",
"message": "Requests to the ChatCompletions_Create Operation under Azure OpenAI API version 2023-07-01-preview have exceeded token rate limit of your current OpenAI S0 pricing tier. Please retry after 7 seconds. Please go here: https://aka.ms/oai/quotaincrease if you would like to further increase the default rate limit."
}
}
それでは 1 人当たりの質問トークン数を増やして質問を複雑にすることで、レスポンスに時間がかかるようにしてみましょう。
200トークン|100ユーザー|2チャット
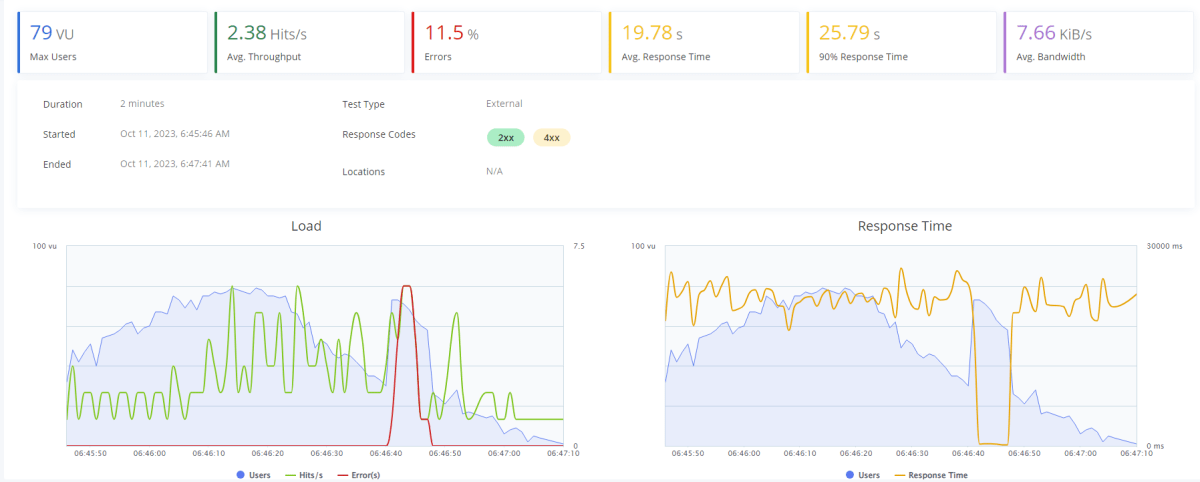
最大 79 ユーザを蓄積していますが、一時的に許容トークンを超えてエラーが発生しているものの、時間が経過するにつれてエラーは減少しています。
結果的にエラーを返す割合は簡単な質問よりも割合が低くなっています。
つまり質問が複雑なほど待ち時間が発生して、その間にクオータが解放されていると考えられます。興味深いですね。
それでは、逆に 1 分間で 20 回チャットするようなものすごく話すユーザが 10 ユーザーいたらどうなるのでしょうか。
50トークン|10ユーザー|20チャット
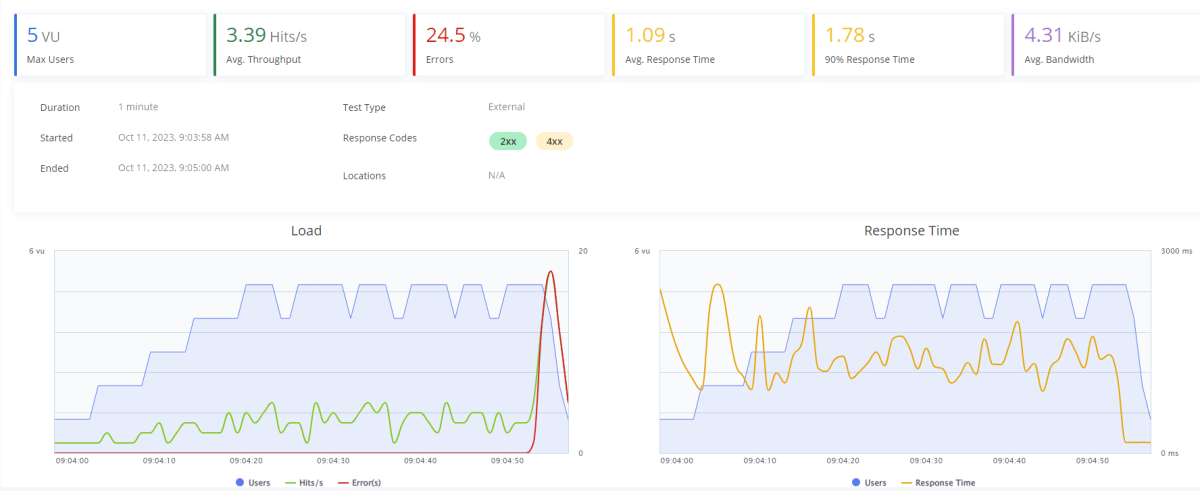
ユーザー数は 10 人しかいませんが、1 人当たり 20 回チャットしているため、許容トークン数を超えてエラーが発生しています。しかし、急激なスパイクで 429 エラーが出るので、チャットを使用できる時間は長いです。
それでは、より複雑な質問をしてレスポンス時間を稼いでみましょう。
200トークン|10ユーザー|20チャット
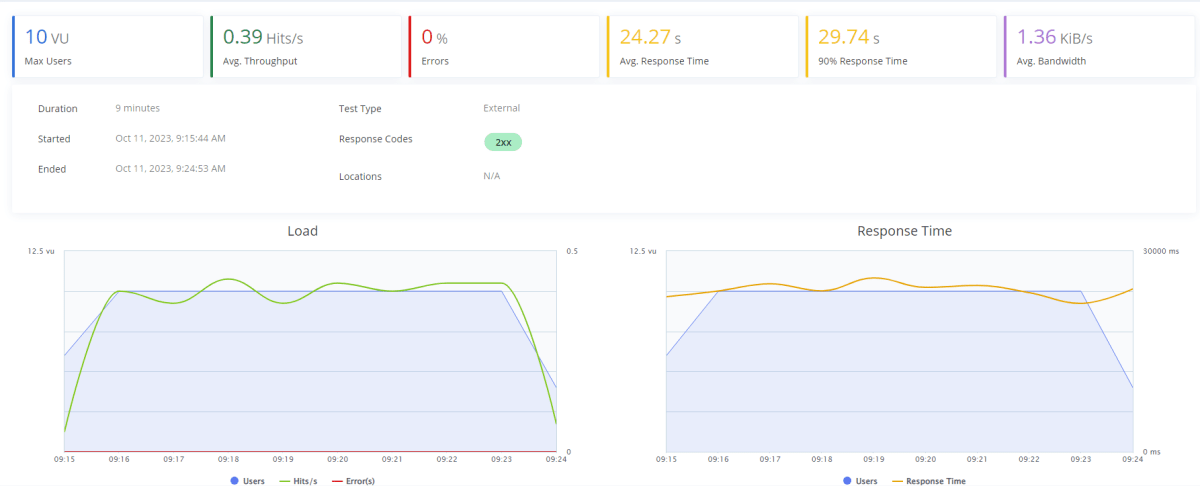
なんと質問の長さ以外は先程と同じ条件下であるのにも関わらず、エラーは発生していません。つまり質問が複雑なほど、レスポンス時間が長くなるため、その間にクオータが解放されていると考えられます。
まとめ
今回は Azure OpenAI Service の API を JMeter と Taurus で負荷テストしてみました。
結果として、質問がより複雑な場合にレスポンス時間が長くなり、その間にクオータが解放されることで、エラーの発生する割合が低くなると分かりました。
また、現在のクオータ制限において何も対策しない場合は、1 分あたり 100 ユーザ程度が同時に使用するとリミットに引っかかる可能性が上がると考えられます。
したがって、アクティブユーザが多い大規模なアプリケーションに導入する場合、モデルのデプロイを複数のリージョンに分散させたり、 1 回あたりのレスポンス時間を長めに取ってあげることで、より多くのユーザーが利用する環境にも対応できそうです。
参考文献

Discussion