はじめに
2023 年 1 月に Azure OpenAI Service の一般提供 (GA) が開始されました。そこで、本記事では Azure OpenAI Service の概要、関連情報へのリンク、利用開始までの手順についてまとめました。
- General availability of Azure OpenAI Service expands access to large, advanced AI models with added enterprise benefits
- Azure OpenAI Service の一般提供開始 大規模かつ高度な AI モデルへのアクセスを拡大し、企業に付加価値を提供
なお、本記事には個々のモデルのアルゴリズムの解説は含みません。
また、本記事に含む情報 (利用可能なモデル・リージョン等) は執筆時点のものです。
アップデートが激しいため最新の情報は OpenAI や Microsoft の公式ドキュメントも合わせてご確認ください。
- Introduction (OpenAI 公式)
- Azure OpenAI Service とは (Microsoft 公式)
- Azure OpenAI Service とは (Microsoft Official)
- What's new in Azure OpenAI Service
Azure OpenAI Service とは
概要
Azure OpenAI Service とは、OpenAI が開発した GPT-3、Codex、Embeddings、ChatGPT (GPT-3.5)、GPT-4 などのモデルを Web API として利用することができるサービスです。Azure Cognitive Services の一部として位置づけられていて、他の Cognitive Services と同じく、利用者が機械学習に関する高度な知識を持たなくても "人工知能 (AI) パーツ" として人間の認知機能をアプリケーションに組み込むことができます。
Azure OpenAI Service と OpenAI の比較
企業としての OpenAI が開発したサービスとしての OpenAI (本家) と Azure OpenAI Service の間にはいくつか違いが存在します。

これらの違いから、強いて両者を使い分けるとすれば、最新のモデルをいち早く取り入れたい場合は本家 OpenAI、企業等の本番環境利用を想定する場合は Azure OpenAI Service という選択肢になると思います。
個々の違いについて補足説明していきます。
1. 利用規約
両者にはそれぞれ独立した利用規約が存在し、利用者が入力したデータの取り扱い等が異なります。詳細は原文を参照してください。
- Terms of use (本家 OpenAI)
- Code of conduct for Azure OpenAI Service
- 本家 OpenAI と Azure OpenAI Service の ChatGPT API の比較 - 1. 利用規約
2. API 公開のサイクル
Azure OpenAI は OpenAI と共に API を共同開発し、互換性を確保し、一方から他方へのスムーズな移行を保証します
Azure OpenAI Service は OpenAI と共同開発されています。新しいモデルの API は先に本家 OpenAI で公開された後に順次 Azure OpenAI Service に移植されていきます。
ただし、最近公開されたモデルについては本家 OpenAI と Azure OpenAI Service でほぼ同じタイミング (本家で API が公開されてから数週間以内) で公開されるようになってきています。
3. Azure OpenAI Service 独自の特徴
3.1. セキュリティ
Microsoft Azure のセキュリティ機能を使用できます
おそらくデータセンター建屋の物理的なセキュリティも含む Azure サービスに共通するインフラストラクチャのセキュリティ保護全般について指しているものと思われます。
ちなみに、Azure OpenAI Service は他の Azure サービス同様に ロールベースアクセス制御 (RBAC) に対応しています。執筆時点では Azure OpenAI Service 向けに 2 つの Azure 組み込みロール が存在しています。
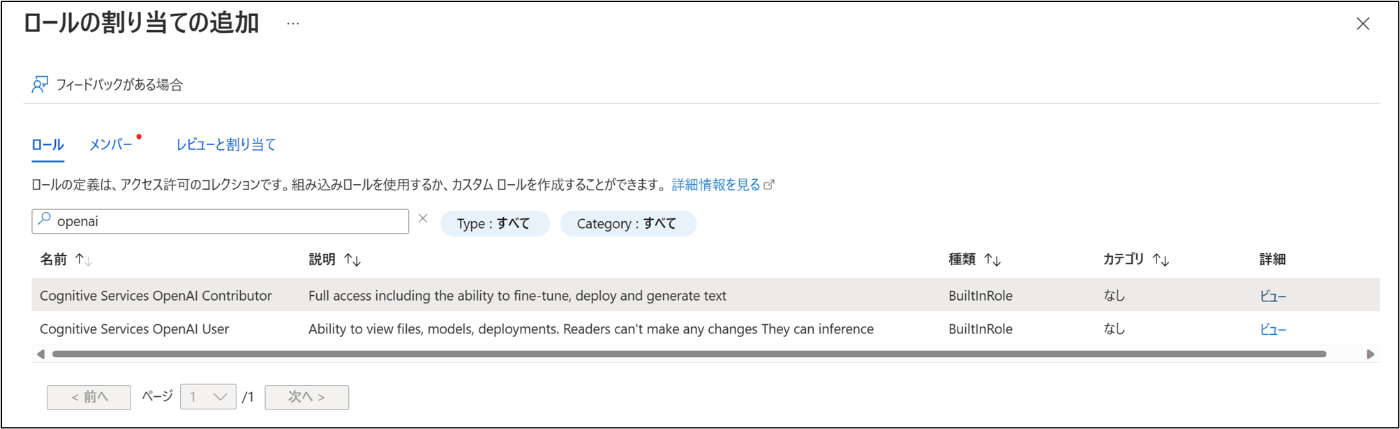
3.2. ネットワーク
プライベート ネットワーク
他の Cognitive Services と同じく指定した Azure VNet からのみアクセスを許可したり、Private Endpoint 経由でのアクセスを行うことが可能です。

3.3. リージョン・可用性
リージョンの可用性
執筆時点で 3 つのリージョン(East US (米国東部) 、South Central US (米国中南部)、West Europe (西ヨーロッパ))で利用可能です。一部特定のリージョンでしか利用できないモデルもありますが、複数リージョンで利用可能なモデルの場合はリージョン障害に備えたマルチリージョン構成を考えることもできます。
また、可用性に関して Azure Cognitive Services の SLA は99.9%と設定されています。
一方で執筆時点で本家 OpenAI には SLA が設定されていませんでした。

Pricing のページではすぐ来るとされています。

3.4. コンテンツフィルタリング
責任ある AI コンテンツのフィルター処理
Azure OpenAI Serivce には Web API で利用できるモデル自体に加えて、不適切なユーザー入力やモデル出力 (コンテンツ生成) を防ぐためのコンテンツフィルタリングの仕組みが不随しています。
執筆時点では、コンテンツフィルタリングの改善のために有害コンテンツのアノテーションを行っている段階とのことでデフォルトで機能は無効になっていますが、サポートリクエスト (SR) により有効化のリクエストを行うこともできるようです。
モデル
Azure Open AI Service では下記シリーズのモデルが利用可能です。
- GPT-3 - 2023 年 1 月~
- Codex - 2023 年 1 月~
- Embeddings - 2023 年 1 月~
- DALL-E 2 - 2023 年 1 月~
- ChatGPT - 2023 年 3 月~
- GPT-4 - 2023 年 3 月~ (登録制プレビュー)
【追記】一部モデルはレガシーモデルとして廃止されることが発表されました。詳細は下記の記事を参照してください。
### 1. GPT-3 シリーズ
GPT-3 シリーズ のモデルは自然言語の理解と生成を行うことができます。Text Completion により利用者が入力したテキストに続くテキストを出力することができ、要約・分類・コンテンツ生成などのタスクを行わせることができます。
GPT-3 モデルには 4 種類(Davinci (D)、Curie (C)、Babbage (B)、Ada (A))が存在しています。D > C > B > A の順にモデルの性能が高くその分推論時間もかかります。各モデルが得意とされる用途は下記のとおりです。
Davinci: Complex intent, cause and effect, summarization for audience / 複雑な意図、因果関係、対象者向けの要約Curie: Language translation, complex classification, text sentiment, summarization / 言語翻訳、複雑な分類、テキストセンチメント、要約Babbage: Moderate classification, semantic search classification / 中程度の分類、セマンティック検索分類Ada: Parsing text, simple classification, address correction, keywords / テキストの解析、単純な分類、住所修正、キーワード
参考
- Web API で公開されているモデル名と論文の対応関係について: Model index for researchers
- モデル名について:
GPT-3.5 と呼ばれるモデルたちもここに含まれる-
InstructGPT モデルもここに含まれる
OpenAI のドキュメントにて GPT-3.5 は独立したセクションで記載されるようになりました- 参考: GPT-3.5
-
執筆時点で昨今話題の人間のような自然な対話に特化した ChatGPT、ChatGPT Plusに相当する API はまだ公開されていない
2023 年 3 月に ChatGPT API が公開されました (後述)
GPT-3 基本モデルと利用可能リージョンの一覧表
各モデルが利用可能なリージョンは下表のとおりです。Azure OpenAI Service の公式ドキュメントの記述に沿って、GPT-3 としてまとめていますが、OpenAI の公式ドキュメントでは text-davinci-003 と text-davinci-002 は GPT-3.5 世代に位置づけられています。
参考: GPT-3 モデル
GPT-3 Fine-tuning 対応モデルと利用可能リージョンの一覧表
一部モデルは Fine-tuning に対応しています。Fine-tuning の機能を有効化するためには Azure OpenAI Service 自体の利用申請とは別に申請が必要です。(Azure OpenAI Service 利用承認通知メール中のリンクから申請)
参考: GPT-3 モデル
2. Codex シリーズ
Codex シリーズ は GPT-3 から派生したモデルで、ソースコードを理解して生成することができます。Codex シリーズのモデルは自然言語と GitHub 上のパブリックコードの両方を使ってトレーニングされていて、Code Completion により利用者が入力した自然言語をコードに翻訳して生成することができます。また、Inserting Code によりコード中の穴埋めを行うこともできます。特に Python の能力が最も高いとされていて、その他にも JavaScript、Go、Perl、PHP、Ruby、Swift、TypeScript、SQL、Shell、C# などのプログラミング言語を扱うことができます。
Codex シリーズではモデルの性能別に 2 種類(Davinci、Cushman)が存在していて、GPT-3 シリーズと同様にモデルの性能と推論時間のトレードオフが存在します。
参考: Codex
Codex ベースモデルと利用可能リージョンの一覧表
各モデルが利用可能なリージョンは下表のとおりです。OpenAI の公式ドキュメントでは code-davinci-002 は GPT-3.5 世代に位置づけられています。
参考: Codex モデル
Codex Fine-tuning 対応モデルと利用可能リージョンの一覧表
Codex シリーズも一部モデルは Fine-tuning に対応しています。GPT-3 シリーズと同様に、Fine-tuning の機能を有効化するためには Azure OpenAI Service 自体の利用申請とは別に申請が必要です。(Azure OpenAI Service 利用承認通知メール中のリンクから申請)
参考: Codex モデル
3. Embeddings シリーズ
Embeddings シリーズ は自然言語とソースコードの Embedding (埋め込み) を行って Distributed Representation (分散表現) を生成することができます。つまり、自然言語やソースコードを固定次元数のベクトルに変換することができます。これにより、本来は可変長文字列である自然言語の文章間の比較やクラスタリングを行ったり、自然言語で書いたクエリでソースコードを検索するといった応用が可能になります。
Embeddings シリーズには、目的に応じた 3 つのサブシリーズ (Similarity (類似性)、Text Search (テキスト検索)、Code Search (コード検索)) が存在しています。また、GPT-3 シリーズと同じくモデルの性能別に 4 種類(Davinci、Curie、Babbage、Ada)が存在しています。Embeddings シリーズの場合は各モデルごとに出力される分散表現の次元数が異なり、GPT-3 シリーズと同様にモデルの性能と推論時間のトレードオフが存在します。
OpenAI の公式ドキュメントにて、最新の V2 モデル (text-embedding-ada-002) が全ての V1 モデルを置き換えるものとされ、以前の V1 モデル (以下取り消し線で消した部分) の使用は非推奨 になりました。

Embeddings モデルのリスクと制約
Embeddings モデルを利用する場合は、下記リンク先に記載されているリスクと制約に留意する必要があります。これらは OpenAI に限らず Embedding 全般の課題になるかと思います。

例えば、モデルはステレオタイプや特定のグループに対する否定的な感情などを通じて社会的バイアスもエンコードします。

また、執筆時点で Azure OpenAI Service にて利用可能な V1 モデルの場合、2020 年 8 月以降に発生した事象についての知見を欠いています。

#### Similarity (類似性) Embeddings シリーズ
Similarity Embeddings シリーズは、2 つ以上の文章間の類似性を捉えることに適しています。
利用可能なリージョンの一覧は下表のとおりです。
参考: 埋め込みモデル
#### Text Search (テキスト検索) Embeddings シリーズ
Text Search Embeddings シリーズは、長い文章とそれに対する短い検索クエリの間の関連性を測定するのに適しています。このファミリーには 2 つの役割のモデル (doc、query) が含まれています。docモデルは長い文章の分散表現を生成するために使います。一方でqueryモデルは検索クエリの分散表現を生成するために使います。
利用可能なリージョンの一覧は下表のとおりです。
参考: 埋め込みモデル
#### Code Search (コード検索) Embeddings シリーズ
Code search embedding シリーズは、コードスニペットとそれに対する自然言語の検索クエリの間の関連性を測定するのに適しています。このファミリーにも、テキスト検索と同様に 2 つの役割のモデル (code、text) が含まれています。codeモデルはコードスニペットの分散表現を生成するために使います。一方でtextモデルは自然言語検索クエリの分散表現を生成するために使います。
利用可能なリージョンの一覧は下表のとおりです。
参考: 埋め込みモデル
DALL-E 2
画像生成モデルである DALL-E については執筆時点で完全招待制になっています。後述する利用申請フォームを記入する際に DALL-E も同時にチェックを入れてしまうと承認プロセスに非常に時間がかかってしまう可能性があるため、言語モデルと画像モデルは申請を分けた方が良さそうです。
DALL-E 2 の "invite only" の記述は消えましたが、依然として申請に対する返信までの期間が明記されていません。やはり言語系のモデルと画像系のモデルは申請を別々に行った方がよさそうです。

ChatGPT API (GPT-3.5 世代) シリーズ
ChatGPT API では Chat completions によって対話形式でのテキスト生成を行うことができます。OpenAI の公式ドキュメントにて ChatGPT API は GPT-3.5 世代に位置づけられています。
利用するためには、後述する Azure OpenAI Service の利用申請を行い承認されている必要があります。ChatGPT API (GPT-3.5 世代) に関しては別の記事でまとめました。
- ChatGPT is now available in Azure OpenAI Service (公式発表)
- 本家 OpenAI と Azure OpenAI Service の ChatGPT API の比較
GPT-4 シリーズ
2023 年 3 月から GPT-4 の登録制プレビューが開始しました。利用するためには後述する Azure OpenAI Service の利用申請を行い承認されたうえで、GPT-4 プレビューの Wait List に登録する必要があります。GPT-4 に関しては別の記事でまとめました。
価格
Azure OpenAI Service には下記 3 つの課金要素が存在します。
- モデル入出力トークン (1,000 トークン単位、切り捨て) - 後続セクションで補足説明します
- Fine-tuning 済みモデルのホスティング
- Fine-tuning の際のコンピューティング
詳細な金額は Azure OpenAI Service の価格ページ に記載されています。また、本家 OpenAI の Pricing ページの下部に価格に関する FAQ が記されています。
ちなみに、執筆時点では Azure OpenAI Service と本家 OpenAI は同じ価格設定でした。(直接比較可能な部分のみ)
Azure OpenAI Service

本家 OpenAI

実際にかかったコストは Azrue Portral から確認できます。

トークン
OpenAI においてトークンは以下のように説明されています。

参考
例えば、英語の場合は概ね、文章をスペースで分割 (tokenize) した単語のリスト (tokens) またはその中の一つの単語 (token) を指します。入力した自然言語がいくつのトークンとして OpenAI API に認識されるか確認する方法はいくつか存在します。
Python パッケージの tiktoken
Python では tiktokenを使う事で確認できます。
>>> import tiktoken
>>> enc = tiktoken.get_encoding('gpt2')
>>> tokens = enc.encode('I like cats')
>>> print('tokens: %s' % tokens)
tokens: [40, 588, 11875] # OpenAI API によって割り当てられているトークン ID
>>> print('token count: %s' % len(tokens))
token count: 3
トークン化 (tokenize) を行う際のエンコーディングはモデルによって異なります。上の例では r50k_base (gpt2) を指定しています。モデルとエンコーディングについては別の記事でまとめました。
Azure OpenAI Studio の Playground
Azure OpenAI Service のリソース作成後は Studio の Playground でも確認できます。

日本語のトークン
OpenAI や Azure OpenAI Service で日本語を処理させる場合、トークン数は必ずしも人間の直感的な形態素数とは一致しません。実際には形態素数でも文字数でもバイト数でもない独自の数え方がされます。実際のアプリケーションに組み込む際は前述の tiktoken を使うなどして事前にトークン数を確認してから API リクエストを行う必要があります。
例えば、私は猫が好きですという日本語文のトークン数を OpenAI Tokenizer 確認すると、8 文字に対して 13 トークンと認識されます。それとなく、平仮名はそのまま 1 文字として扱い、それ以外のダブルバイト文字はバイト分割して扱っている印象を受けます。

Azure OpenAI Studio の Playground で試しても同じ結果です。

tiktoken の結果とも一致します。
>>> import tiktoken
>>> enc = tiktoken.get_encoding('gpt2')
>>> tokens = enc.encode('私は猫が好きです')
>>> print('tokens: %s' % tokens)
tokens: [163, 100, 223, 31676, 163, 234, 104, 35585, 25001, 121, 33778, 30640, 33623]
>>> print('token count: %s' % len(tokens))
token count: 13
[参考] 形態素数は 6 つですのでこれとは異なります。
>>> from janome.tokenizer import Tokenizer
>>> t = Tokenizer()
>>> for token in t.tokenize('私は猫が好きです'):
... print(token)
...
私 名詞,代名詞,一般,*,*,*,私,ワタシ,ワタシ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
猫 名詞,一般,*,*,*,*,猫,ネコ,ネコ
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
好き 名詞,形容動詞語幹,*,*,*,*,好き,スキ,スキ
です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス
[参考] 1 文字が 2 トークンや 3 トークンとして認識されている部分があったため UTF-8 エンコード時のバイト数ではないかと疑いましたが、UTF-8 の場合は合計 24 バイトとなり、こちらも 13 トークンとは一致しません。
>>> '私'.encode(encoding='utf-8')
b'\xe7\xa7\x81'
>>> 'は'.encode(encoding='utf-8')
b'\xe3\x81\xaf'
>>> '猫'.encode(encoding='utf-8')
b'\xe7\x8c\xab'
>>> 'が'.encode(encoding='utf-8')
b'\xe3\x81\x8c'
>>> '好'.encode(encoding='utf-8')
b'\xe5\xa5\xbd'
>>> 'き'.encode(encoding='utf-8')
b'\xe3\x81\x8d'
>>> 'で'.encode(encoding='utf-8')
b'\xe3\x81\xa7'
>>> 'す'.encode(encoding='utf-8')
b'\xe3\x81\x99'
[参考] 他言語のトークン数
いくつかの言語で同じ内容を表現した際のトークン数を比較してみました。圧倒的に英語がコスト面で優秀 (おそらくモデルの性能という面でも) でしたが、必ずしも日本語が最もコスト面で不利というわけではないようです。
英語: I like cats

スペイン語: Me gustan los gatos

中国語 (簡体): 我喜欢猫

ヒンディー語: मुझे बिल्लियां पसंद हैं

利用開始までの手順
概要部分が長くなりましたが、ここからは実際に Azure OpenAI Service を利用開始するまでの手順をまとめます。
0. 前提
- Azure のサブスクリプションが存在している
- リソースグループが作成済み
- (オプション) Python 開発環境が構築済み
1. 利用申請
マイクロソフトは責任ある AI を非常に重視しています。そのため、Azure OpenAI Service を利用するためには下記リンク先のフォームから利用申請を行う必要があります。
必要事項を入力したら送信します。前述のとおり、画像系のモデル (DALL-E 2) を利用したい場合はテキスト系のモデルとは別に利用申請を行います。
参考
2. 利用承認
利用申請が承認されるとメールが届きます。 (承認までの時期は不定期) メールに書かれている内容をよく読みます。もしも Fine-tuning を行いたい場合は、メール中に記載されているリンクから別途申請を行います。
この時点で Azure Portal から Azure OpenAI Service のリソースが作成可能になっています。
3. リソース作成
Azure Portal の マーケットプレイスから Azure OpenAI を検索して作成を開始します。

必要事項を入力して作成します。価格レベルは Standard S0 しか存在しないためそれを選択します。

※ East US リージョンにリソースを作成する場合の例
参考
3. Azure OpenAI Studio の起動
リソースグループから、作成したリソースを選択します。

概要から探索 (英語表示の場合は Explore) をクリックすると Studio が起動します。


4. モデルのデプロイ
リソース作成直後はデプロイされているモデルが存在しないため、最初のデプロイを行います。
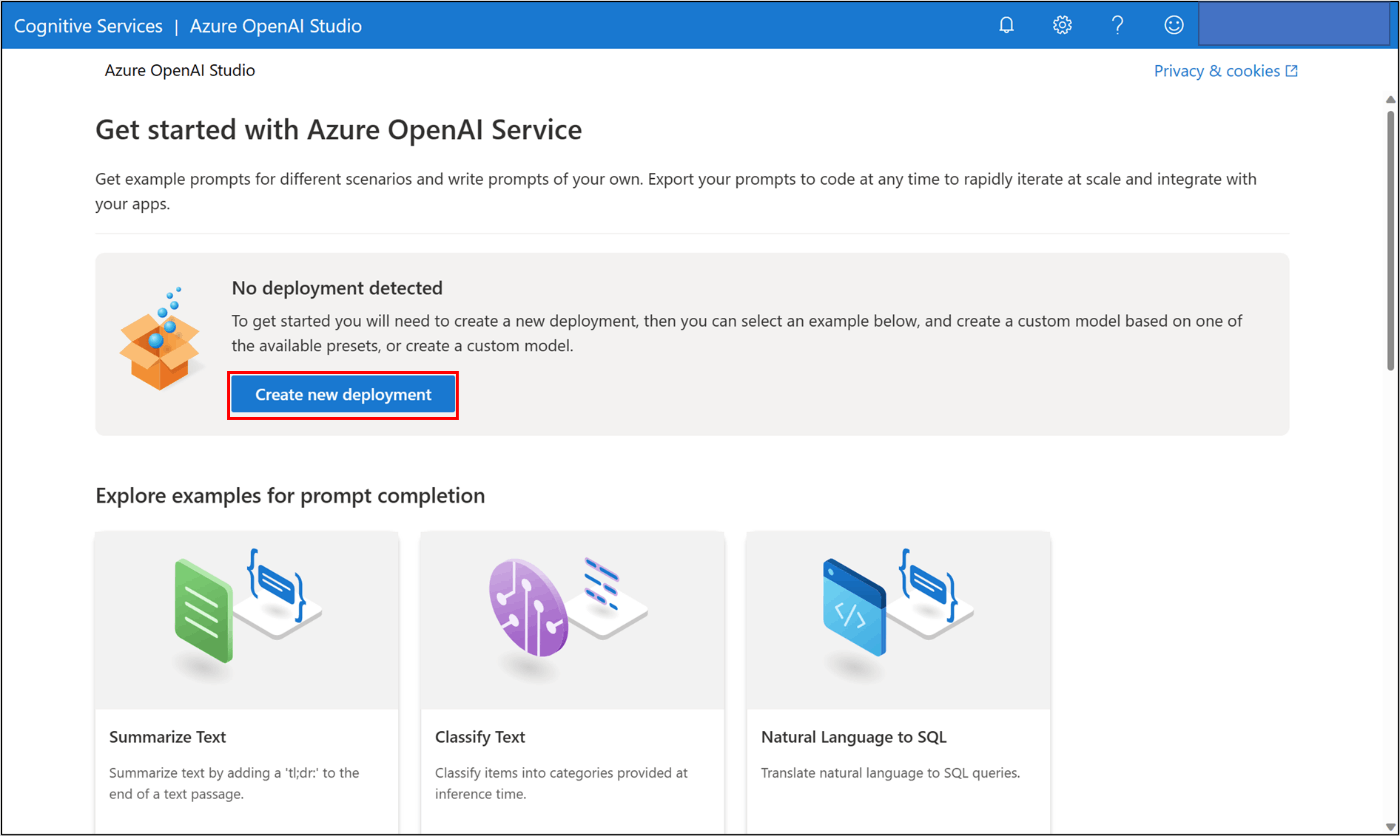

執筆時点でどのリージョンでも選択可能なtext-davinci-002をデプロイします。

5. Playground のサンプルで遊ぶ
Playground に移動します。

先ほどデプロイしたモデルが選択されていることを確認します。Examples のドロップダウンリストを展開するといくつかサンプルが準備されています。今回はtext-davinci-002で動かせるSummarize Text (テキストの要約)を選択します。選択したらGenerateをクリックします。

事前に入力されていたテキストの続きの要約部分が生成されます。

サンプルを変えたり、入力を変えたり、パラメータを変えたりして心行くまで遊びながらテキスト生成の直感的な理解を行います。
6. Web API 経由でのリクエスト
Playground でしばらく遊ぶと Web API 経由での使い方が気になってきます。そこで、本記事の最後に REST API と Python API を試します。
6.1. サンプルコードの取得
先ほどの Playground の View Codeをクリックします。

先ほど実行したSummarize Textを Python で実行する場合のサンプルコードが表示されますのでコピーして控えておきます。

ドロップダウンリストを開くと json と curl のサンプルも取得することができます。今回は REST API でのリクエストも行いますので json のコードをコピーして控えておきます。後ほど REST API でリクエストを行う際のリクエストボディになります。


6.2. API キーの取得
Azure Portal から API キー (1 か 2 のどちらか) をコピーします。API キーは絶対に外部に漏らさないように注意します。

なお、API キーは下記のボタンから再生成が可能です。

6.3. REST API 経由でのリクエスト
Visual Studio Code の拡張機能の REST Client を使って REST API 経由でリクエストを行います。
Visual Studio Code に REST Client をインストールしたら、新規ファイルを作成して任意のファイル名で保存します。その際、拡張子を .rest にします。 作成した .rest ファイルに下記のフォーマットで入力を行います。
@api-key = <YOUR-API-KEY>
POST https://<YOUR-RESOURCE-NAME>.openai.azure.com/openai/deployments/<DEPLOYMENT-ID>/completions?api-version=<API-VERSION>
content-type: application/json
api-key: {{api-key}}
<REQUEST-BODY>
値は以下のように置き替えます。
-
<YOUR-API-KEY>: コピーしておいた API キー -
<YOUR-RESOURCE-NAME>: Azure OpenAI Service のリソース名 -
<DEPLOYMENT-ID>: 最初のデプロイ時に付けたデプロイ名 -
<API-VERSION>:2022-12-01(執筆時点で左記のみ選択可能) -
<REQUEST-BODY>: サンプルコードで控えた json 形式のリクエストボディ
POST https://xxx の上にある Send Request をクリックします。成功すると結果が返ってきます。

参考
6.4. Python API 経由でのリクエスト
Python 開発環境に openai ライブラリ をインストールします。
pip install openai
新規ファイルを作成してコピーしておいた Python サンプルを貼り付けます。API キー取得部分を環境変数ではなく直接代入するように変更します。また、受け取った結果を出力するように変更します。
#Note: The openai-python library support for Azure OpenAI is in preview.
import os
import openai
openai.api_type = "azure"
openai.api_base = "https://<YOUR-RESOURCE-NAME>.openai.azure.com/"
openai.api_version = "2022-12-01"
openai.api_key = "<YOUR-API-KEY>" # 直接代入
response = openai.Completion.create(
engine="my_first_deploy",
prompt="A neutron star is the collapsed core of a massive supergiant star, which had a total mass of between 10 and 25 solar masses, possibly more if the star was especially metal-rich.[1] Neutron stars are the smallest and densest stellar objects, excluding black holes and hypothetical white holes, quark stars, and strange stars.[2] Neutron stars have a radius on the order of 10 kilometres (6.2 mi) and a mass of about 1.4 solar masses.[3] They result from the supernova explosion of a massive star, combined with gravitational collapse, that compresses the core past white dwarf star density to that of atomic nuclei.\n\nTl;dr",
temperature=0.7,
max_tokens=60,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
best_of=1,
stop=None)
print(response) # 結果を出力
値は以下のように置き替えます。
-
<YOUR-RESOURCE-NAME>: Azure OpenAI Service のリソース名 -
<YOUR-API-KEY>: コピーしておいた API キー
値を置き替えたらスクリプトを実行します。成功すると結果が返ってきます。
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": ": A neutron star is the collapsed core of a massive supergiant star."
}
],
"created": 1675407295,
"id": "cmpl-6fkGFw5cKwuwKO1RORcPH6RZoMbP9",
"model": "text-davinci-002",
"object": "text_completion",
"usage": {
"completion_tokens": 17,
"prompt_tokens": 143,
"total_tokens": 160
}
}
[参考] API キーの隠匿
上記の例ではとりあえず確認するために API キーをコード中に直に入力しましたが、実際の開発プロジェクトではそれでは良くないので環境変数や Azure Key Vault を使って API キーを隠匿します。下記の例では Azure OpenAI Service と Azure Key Vault のリソース名を環境変数に格納して、事前に Azure Key Vault に作成しておいたシークレット (API キーを格納) を取得しています。
import os
import openai
import json
from azure.keyvault.secrets import SecretClient
from azure.identity import DefaultAzureCredential
kv_name = os.environ["<KEY_VAULT_NAME>"]
kv_uri = f"https://{kv_name}.vault.azure.net"
openai_name = os.environ["<OPENAI_NAME>"]
openai_uri = f"https://{openai_name}.openai.azure.com/"
credential = DefaultAzureCredential()
client = SecretClient(vault_url=kv_uri, credential=credential)
openai.api_type = "azure"
openai.api_base = openai_uri
openai.api_version = "2022-12-01"
openai.api_key = client.get_secret("<SECRET-NAME>").value
response = openai.Completion.create(
# 略
)
print(response)
参考
- Python library
- openai/openai-python
- クイックスタート: Azure OpenAI を使用してテキストの生成を開始する (Python)
- クイックスタート: Python 用 Azure Key Vault シークレット クライアント ライブラリ
おわりに
今後は様々な API を試しつつ Azure OpenAI Service のアプリケーションへの適用シナリオについて考えていきたいと思います。
以上です。🍵

Discussion