はじめに
2023 年 3 月からパブリックプレビューが開始した Computer Vision の Image Retrieval を使って画像のベクトル検索を行うための方法をまとめました。記事の中では、テキストクエリによる画像検索と画像クエリによる画像検索 (類似画像検索) の 2 パターンの検証を行いました。
方法
1. 準備
1.1. Python パッケージ
以下のパッケージを Pyhton 実行環境にインストールします。今回は Faiss を使ってローカルマシン上でベクトル検索を行います。実行環境に応じて faiss-gpu か faiss-cpu を選択します。PyTorch は今回使用するサンプルデータの準備に使います。バージョンは執筆時点での最新版です。
-
faiss-gpu 1.7.2
- もしくは faiss-cpu 1.7.4
- numpy 1.25.0
- torch 2.0.1 (サンプルデータ準備用)
- torchvision 0.15.2 (サンプルデータ準備用)
1.2. Computer Vision
Computer Vision のリソースを作成します。価格レベルは Standard S1 を選択します。リージョンは執筆時点で Image Retrieval が利用可能な以下の中から選択します。

参考
2. データ準備
今回は COCO dataset を使います。
2.1. ダウンロード
ダウンロードページ から、2014 Val images と 2014 Train/Val annotations をダウンロードして任意のフォルダに解凍します。

2.2. データセット読み込み
以下のコードでデータセットを読み込みます。<your-base-folder-path> は画像ファイルとアノテーションファイルを配置したフォルダーのパスと置き換えます。
import torch
from torchvision import transforms, datasets
from IPython.display import Image
base_folder = "<your-base-folder-path>"
image_folder = base_folder + "val2014/"
ann_file = base_folder + "annotations/captions_val2014.json"
transform = transforms.Compose([transforms.ToTensor()])
val_dataset = datasets.CocoDetection(
root=image_folder,
annFile=ann_file,
transform=transform
)
loading annotations into memory...
Done (t=0.30s)
creating index...
index created!
2.3. 確認
画像とラベルを確認します。1 枚の画像に対してそれを説明するキャプションが複数付加されています。なお、本記事では Jupyter Lab での実行を想定しています。
_, label = val_dataset[1]
for l in label:
print(l)
image_file_name = "COCO_val2014_" + str(label[0]["image_id"]).zfill(12) + ".jpg"
Image(image_folder + image_file_name)

3. 画像のベクトル化
3.1. 環境変数の設定
Computer Vision のキーとエンドポイントを環境変数に登録しておきます。キーとエンドポイントは Azrue Portal から確認できます。

import os
os.environ["VISION_ENDPOINT"] = "https://<your-resource-name>.cognitiveservices.azure.com"
os.environ["VISION_API_KEY"] = "<your-vision-api-key>"
3.2. 画像のベクトル化
Image Retrieval の Vectorize Image API を使って画像をベクトル化します。Image Retrieval には、画像をベクトル化する Vectorize Image API と、検索クエリのテキストをベクトル化する Vectorize Text API が対になって含まれています。
import json
import requests
import faiss
import numpy as np
images = []
labels = []
vectors = []
num = 1000 # 今回はデータセットのうち画像1,000枚をベクトル化
for i in range(num):
_, label = val_dataset[i]
labels.append(label)
image_file_name = "COCO_val2014_" + str(label[0]["image_id"]).zfill(12) + ".jpg"
images.append(image_folder + image_file_name) # 画像ファイルのパス
endpoint = os.getenv("VISION_ENDPOINT") + "/computervision/retrieval:vectorizeImage?api-version=2023-02-01-preview&modelVersion=latest"
headers = {
"Content-Type": "application/octet-stream", # リクエストボディは画像のバイナリデータ
"Ocp-Apim-Subscription-Key": os.getenv("VISION_API_KEY")
}
for idx, image in enumerate(images):
with open(image, mode="rb") as f:
image_bin = f.read()
# Vectorize Image API を使って画像をベクトル化
response = requests.post(endpoint, headers=headers, data=image_bin)
image_vec = np.array(response.json()["vector"], dtype="float32").reshape(1, -1)
vectors.append(image_vec)
ベクトルやメタデータは再利用できるように pkl ファイルで保存しておきます。
import pickle
with open("images.pkl", "wb") as f:
pickle.dump(images, f)
with open("labels.pkl", "wb") as f:
pickle.dump(labels, f)
with open("vectors.pkl", "wb") as f:
pickle.dump(vectors, f)
読み込む場合は以下のようにします。
import pickle
with open("images.pkl", "rb") as f:
images = pickle.load(f)
with open("labels.pkl", "rb") as f:
labels = pickle.load(f)
with open("vectors.pkl", "rb") as f:
vectors = pickle.load(f)
参考
4. Faiss インデックスの作成とベクトルの展開
4.1. インデックス作成
Faiss インデックスを作成します。今回はベクトル数が少なく総当たりでも問題ないため IndexFlatL2 (Exact Search for L2) を選択します。Vectorize Image API と Vectorize Text API はいずれも入力された画像もしくはテキストを 1,024 次元のベクトルに変換して返します。よって、Faiss の vector dimension も 1,024 に設定します。
dimension = 1024
index_flat_l2 = faiss.IndexFlatL2(dimension)
参考
4.2. ベクトル展開
Faiss 上にベクトルを展開します。
for vector in vectors:
index_flat_l2.add(vector)
ベクトル化した画像の数と合っていることを確認します。
print(index_flat_l2.ntotal)
1000
5. 検索
5.1. テキスト→画像検索
テキストのクエリによる画像検索を行ってみます。(下図のイメージ)
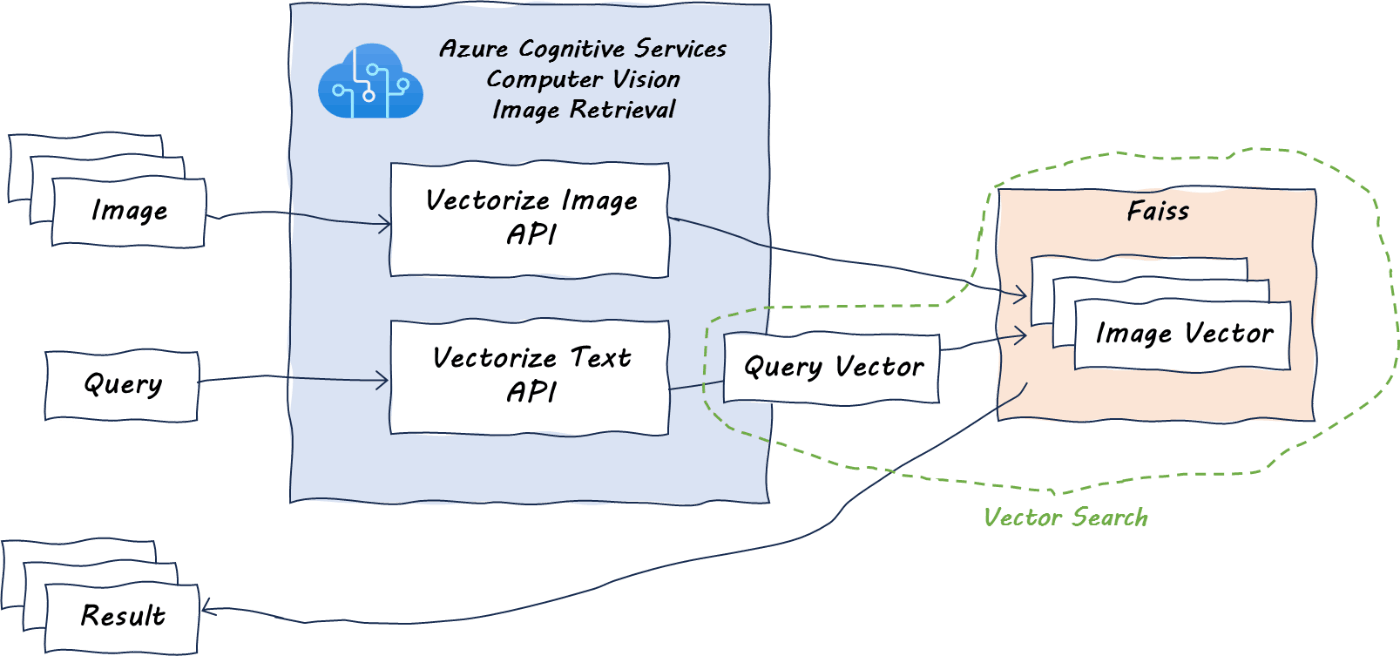
検索用の関数を作成します。
def search_faiss_by_text(query_text, n=3):
endpoint = os.getenv("VISION_ENDPOINT") + "/computervision/retrieval:vectorizeText?api-version=2023-02-01-preview&modelVersion=latest"
headers = {
"Content-Type": "application/json",
"Ocp-Apim-Subscription-Key": os.getenv("VISION_API_KEY")
}
data = {
"text": query_text
}
# Vectorize Text API を使ってクエリをベクトル化
response = requests.post(endpoint, headers=headers, data=json.dumps(data))
query_vector = np.array(response.json()["vector"], dtype="float32").reshape(1, -1)
# Faiss 検索
D, I = index_flat_l2.search(query_vector, n)
return D, I
今回はインデックス作成時に Exact Search for L2 を選択しているため、クエリベクトルと画像ベクトルを総当たりで比較して最もユークリッド距離が近いものが指定した個数だけ返されます。戻り値の D にはクエリテキストベクトルと対象画像ベクトルの間の距離、I には対象画像ベクトルのインデックスが含まれます。
n = 6
D, I = search_faiss_by_text("sports", n)
print(D)
print(I)
[[8427.406 8430.414 8430.715 8430.806 8431.069 8431.149]]
[[978 512 412 69 996 495]]
なお、Vectorize Text API は現状英語のみに対応しているようです。(日本語で書いたクエリを POST してもベクトルは返ってきますが検索結果が全然だめでした。)
参考
5.1.1. クエリ: people playing sports
いくつかのクエリで検索を行ってみます。以下は people playing sports で検索をした結果です。様々なスポーツの画像がヒットします。

画像はクエリとの類似性が高いものから順に以下の順番で並んでいます。

5.1.2 クエリ: winter sports
winter sports で検索を行った結果です。雪景色です。

5.1.3. クエリ: tennis
より絞り込んで tennis で検索を行った結果です。テニスの画像のみがヒットします。

5.1.4. クエリ: animals
animals で検索を行った結果です。シマウマと羊率が高めですが、様々な動物の画像がヒットします。

5.1.5. クエリ: elephants
elephants で検索を行った結果です。ゾウの画像のみがヒットします。

5.1.6. クエリ: animals in river
より状況を絞り込んで、animals in river で検索を行った結果です。1 枚きわどいものがありますが、おそらく乾季の川でしょう。ギリギリ全て川にいる動物の画像です。

5.1.7. 複雑なクエリ
複雑なクエリも試してみます。最初にデータセットを確認した際に表示したバイクの画像のキャプションの An old motorcycle parked beside other motorcycles with a brown leather seat. をクエリにして検索を行います。
結果は、最初に表示したバイクの画像が 1 番目にヒットします。2 番目のバイクもどことなく An old motorcycle の部分を汲んでくれているように見えます。3 番目以降もきちんとバイクの画像が拾えています。

5.2. 画像→画像検索
クエリと検索対象の両方に対して Vectorize Image API を使うことで、画像による画像検索 (類似画像検索) を行うこともできます。(下図のイメージ)

クエリ画像をベクトル化して検索を行う関数を作成します。
def search_faiss_by_image(image_path, n=3):
endpoint = os.getenv("VISION_ENDPOINT") + "/computervision/retrieval:vectorizeImage?api-version=2023-02-01-preview&modelVersion=latest"
headers = {
"Content-Type": "application/octet-stream",
"Ocp-Apim-Subscription-Key": os.getenv("VISION_API_KEY")
}
with open(image_path, mode="rb") as f:
image_bin = f.read()
response = requests.post(endpoint, headers=headers, data=image_bin)
query_vector = np.array(response.json()["vector"], dtype="float32").reshape(1, -1)
D, I = index_flat_l2.search(query_vector, n)
return D, I
5.2.1. クエリ: ワインボトルとワイングラスが写った画像
こちらの画像をクエリにして検索を行ってみます。

image_path = "<your-base-folder-path>/val2014/COCO_val2014_000000000283.jpg"
n = 6
D, I = search_faiss_by_image(image_path, n)
print(D)
print(I)
[[ 0. 4217.7085 5924.0005 6420.4614 6780.1045 7455.822 ]]
[[ 13 839 250 261 808 937]]
今回はクエリ画像も Faiss 上に展開しているため、1 番目にヒットする画像はベクトルが完全一致するクエリ画像自身になります。2 番目以降の画像はワインボトルかワイングラスのようなものが写っている画像がヒットします。

5.2.2. クエリ: かごの上に靴とサンダルと犬が乗っている画像
被写体が少し分かり辛い画像をクエリにして検索を行ってみます。キャプションによると、以下のような状況らしいです。
- This wire metal rack holds several pairs of shoes and sandals
- A dog sleeping on a show rack in the shoes.
- Various slides and other footwear rest in a metal basket outdoors.
- A small dog is curled up on top of the shoes
- a shoe rack with some shoes and a dog sleeping on them

結果はこのようになります。2 番目以降にヒットする画像には、サンダル、犬、かごなど、クエリ画像の被写体に近い被写体を含む画像が返されるようです。最後の画像はよく見ると冷蔵庫の中に犬が寝転んでいます。

5.3. 画像→テキスト検索
テキストクエリによる画像検索が行えるため、その逆も論理的には可能だと思います。しかし、活用する状況が思い浮かばなかったため今回は検証を行いませんでした。
おわりに
以上です。🍵

Discussion