生成AIの隆盛に伴い、ベクトル検索やベクトルデータベースが注目されています。
ベクトルについてより理解するために簡単なデモサービスを作ってみました。
この記事では作ったサービスをもとにベクトルについて説明し、後半では生成AIとベクトルの関連について紹介します。
つくったもの
「しもふりサーチ」 - お笑いコンビ「霜降り明星」のYouTubeチャンネル、「しもふりチューブ」の過去動画を検索できるサービスです。
このサービスには以下の2つの機能があります。
1. 文章での動画検索
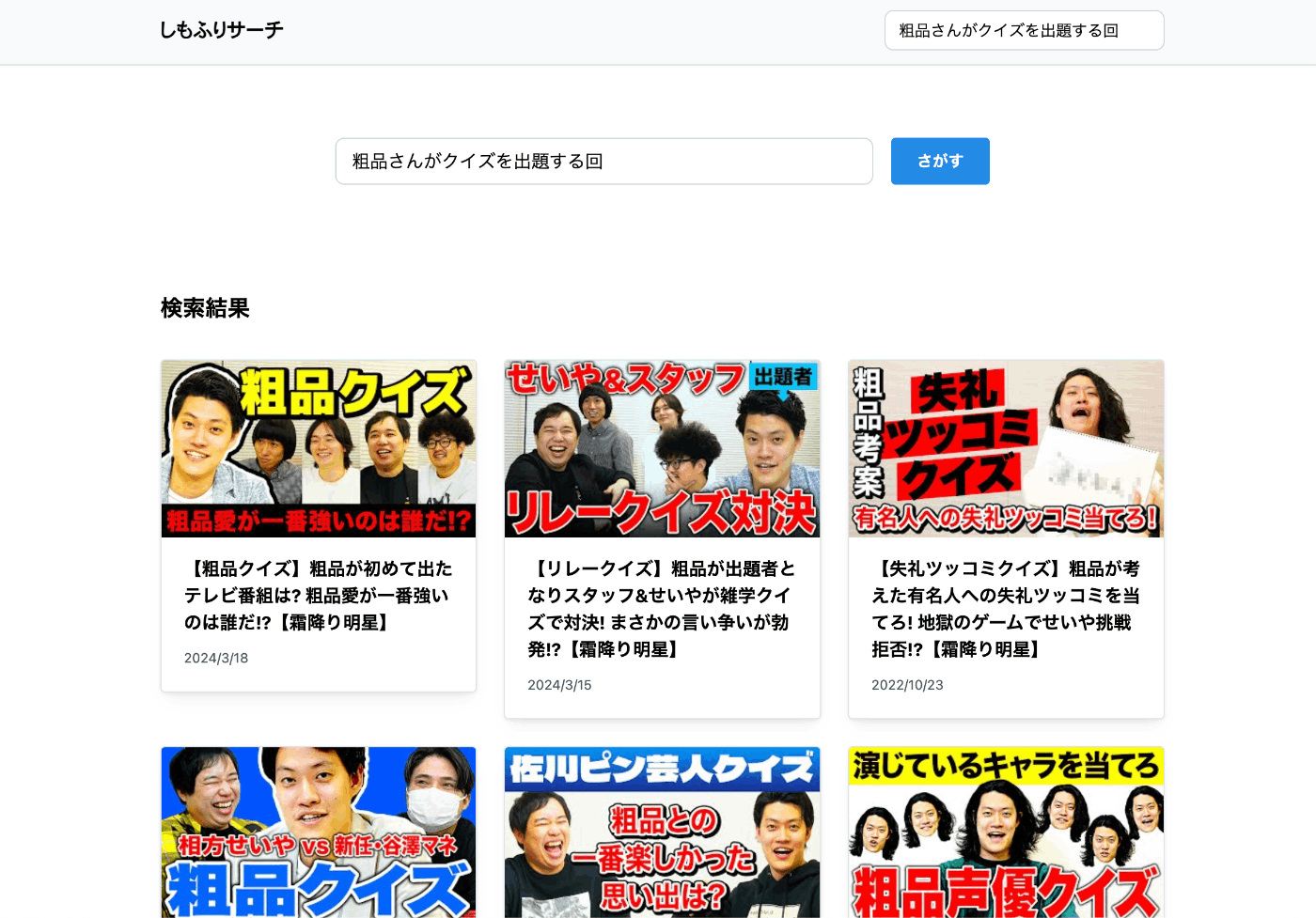
文章で動画を検索する
「粗品さんがクイズを出題する回」 や 「せいやさんがギターを弾く回」 など、自然言語で動画を検索できます。
2. 関連動画レコメンド
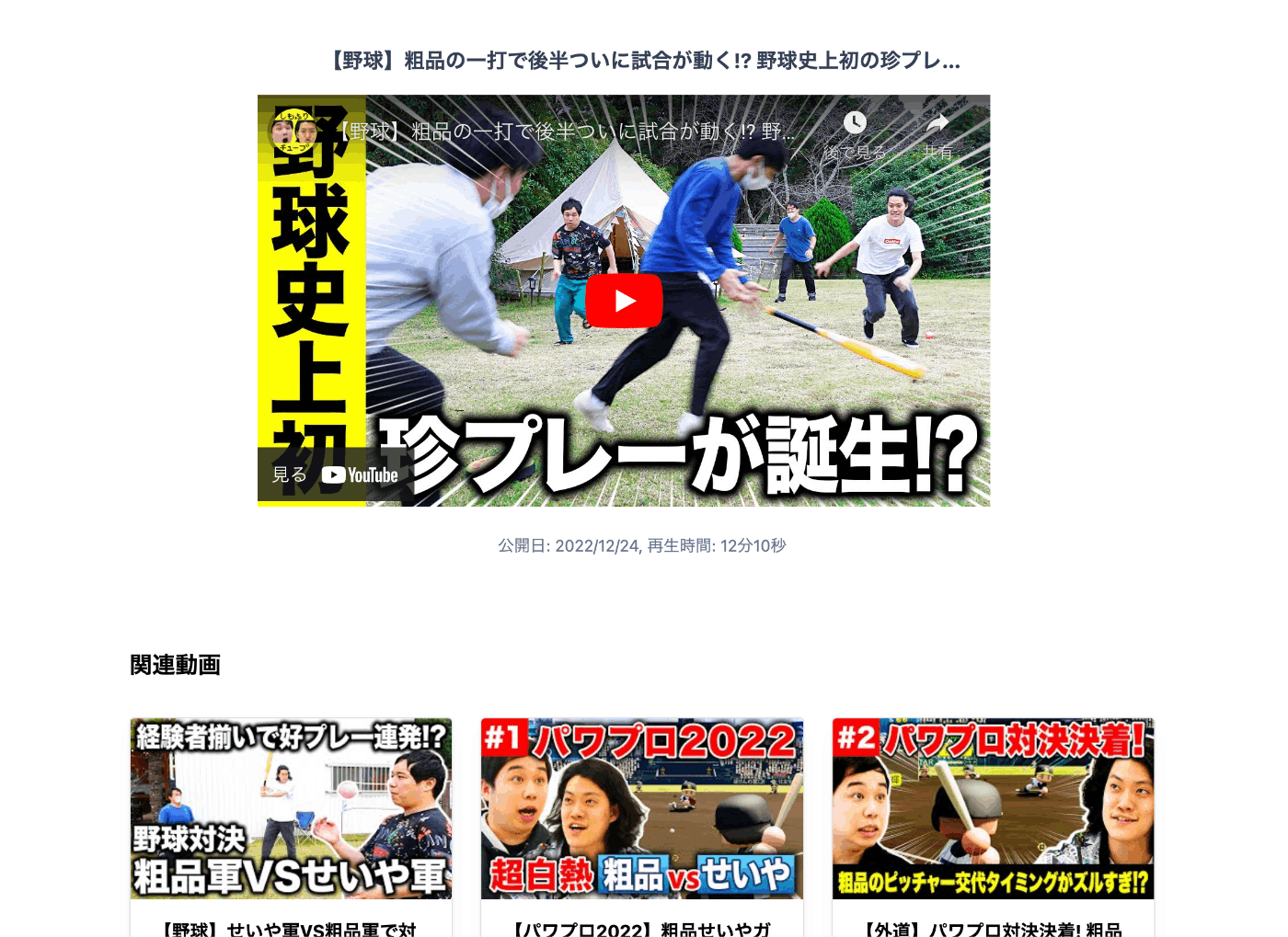
内容の近い動画をレコメンドする
動画を選ぶと、過去動画の中から内容の近い動画をレコメンドします。
これらの機能はベクトル検索で実現されています。詳細を説明していきます。
しもふりサーチ 処理の流れ
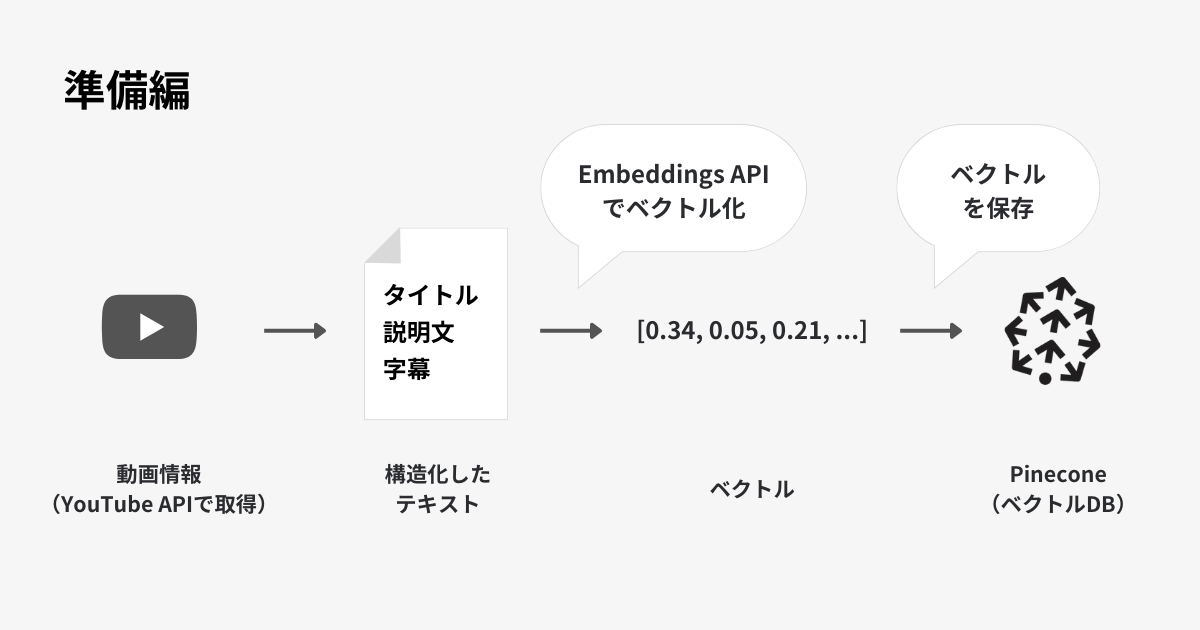
動画の情報をベクトル化し、Pineconeに保存する
(準備編)
- YouTubeから動画を取得します
- タイトルと説明文、字幕をひとつの文字列にします
- OpenAI Embeddings APIでベクトル化します
- ベクトル化したものをベクトルデータベース(今回はPinecone)に保存します
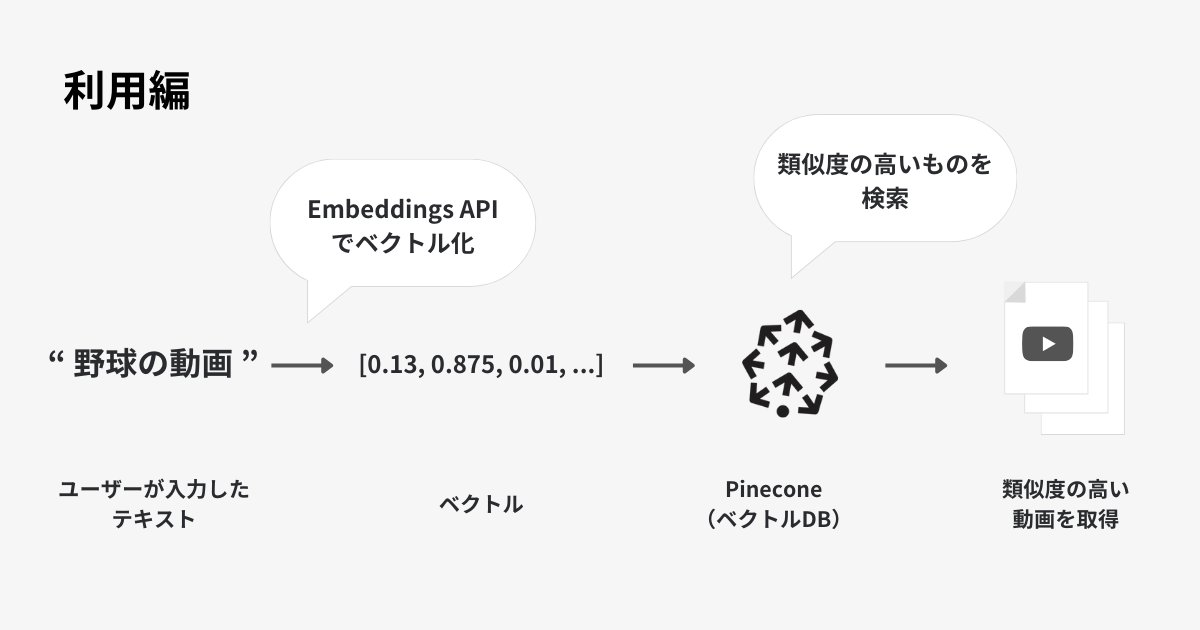
入力された文章をベクトル化し、Pineconeにクエリして類似度の高い動画を取得する
(利用編)
文章での検索
- 入力した文章を、OpenAI Embeddings APIを使ってベクトル化します
- Pineconeにクエリし、類似度の高い動画を取得します
関連動画レコメンド
- 閲覧している動画のベクトルの値を取得します
- Pineconeにクエリし、類似度の高い動画を取得します
処理の詳細な説明
ベクトルとは?
文章や画像、動画などを数値表現したものです。数値で表現することで類似度を計算できるようになります。
今回は動画にまつわる情報、「タイトル」「説明文」「字幕」を合わせた文字列をベクトル化しています。
#タイトル
{title}
#説明
{description}
#字幕
{caption}
↑見出しをつけてこういうフォーマットにしました
ベクトル化するには?
ベクトル化はいろんなやり方がありますが、今回はOpenAI Embeddings APIを利用しています。
ベクトル化したいテキストを指定し、モデルの種類と次元数を選んでベクトル化します。
Pythonの場合は以下のように実装します。
response = openai.embeddings.create(
input=text,
model="text-embedding-3-small",
dimensions=512
)
レスポンスを見ると以下のような情報が返ってきます。
[0.038623873, 0.08829282, -0.05441223, ..., -0.040826112]
dimensions=512 と指定したので、512次元のベクトル(数値の行列)に変換されています。
次元数は高いほど表現力があがりますが、その分データの容量や計算コストがかかります。
ベクトルデータベース
大量のベクトルを高速に検索するにはインデックスが必要です。また、ベクトル化したデータ以外のメタ情報(例えば動画の再生時間)と組み合わせてフィルタリングしたい場合もあるでしょう。
こういった要望を叶えるために、ベクトルデータベースを利用します。
ベクトルデータベースにも色々種類がありますが、今回はPineconeを利用しました。
Pineconeにベクトルを保存するには、以下のような実装になります。
index.upsert(
vectors=[
{
"id": id,
"values": embedding_vector,
"metadata": {"title": title,
"thumbnail": thumbnail,
"duration": duration}
}
])
Pineconeに保存されたデータは以下のように表示されます。
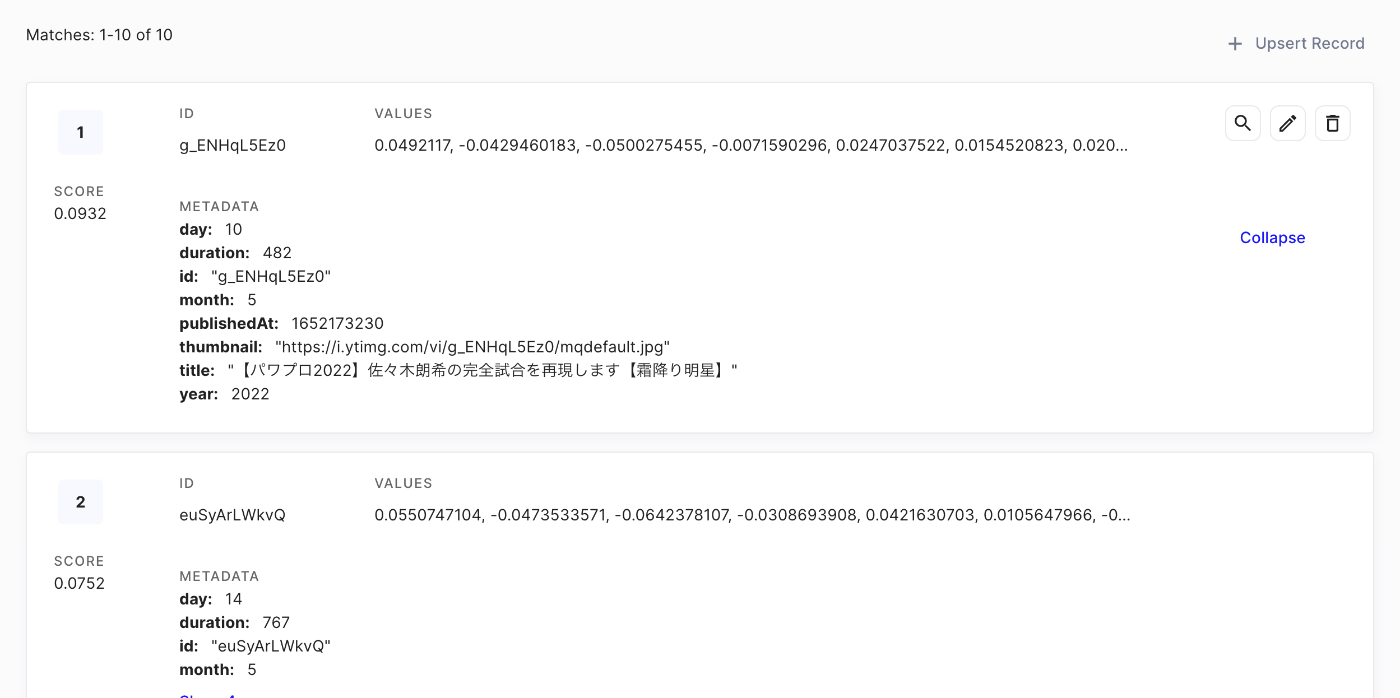
Pineconeの管理画面。ベクトルが保存されていることがわかる
類似度の高いものを検索する
ここまでで、動画の情報をベクトル化して保存するところまで完了しました。
それでは保存したベクトルを利用して機能を作っていきましょう。おさらいですが、「文章での動画検索」と「関連動画レコメンド」が今回作った機能です。
文章での検索も関連動画も、実装自体はほぼ同じです。ベクトルを投げて類似度の高い動画を取得しています。
Pineconeの場合は次のように実装します。
vector には、 「アンパンマンのクイズが見たい」 というテキストをOpenAI Embedding APIでベクトル化したものを渡しています。
result = index.query(
vector=vector,
top_k=10,
include_values=False,
include_metadata=True
)
クエリを実行すると、以下のような結果が得られます。
{'matches': [
{'id': 'H-XshXBP4JY',
'metadata': {'duration': 689.0,
'thumbnail': 'https://i.ytimg.com/vi/H-XshXBP4JY/mqdefault.jpg',
'title': '【アンパンマンクイズ】「あ」から始まるアンパンマンの短所は?【霜降り明星】'},
'score': 0.641346514,
'values': []},
{'id': 'ZShnVon--Bg',
'metadata': {'duration': 614.0,
'thumbnail': 'https://i.ytimg.com/vi/ZShnVon--Bg/mqdefault.jpg',
'title': '【アンパンマンクイズ】てんどんまん・カツドンマン。どんぶりまんトリオのもう1人は?【霜降り明星】'},
'score': 0.638652742,
'values': []}
// ...
]}
入力した文章に関連した結果が得られていますね。score の値が類似度を表しており、類似度の高い順に返却されています。
ここでは「アンパンマン」と直接的なワードで検索していますが、ベクトル検索では意味で調べられます。
例えば「ベースボール」で調べても野球関連の動画がヒットします。こういった表現の揺れに強いのもベクトルの特徴の一つです。
類似度の計算方法
ベクトル間の類似度を計算する方法も種類があります。Pineconeの場合、以下の3種類から選べます。
-
euclidean(ユークリッド距離) -
cosine(コサイン類似度) -
dotproduct(ドット積)
それぞれの特徴はPineconeの公式ドキュメントに任せますが、今回は cosine (コサイン類似度)を選択しました。
OpenAI Embedding APIでベクトル化したものは長さ1に正規化されているため距離は影響しません。OpenAIのヘルプでもコサイン類似度の利用が推奨されています。
なぜ生成AI時代にベクトルが注目されているのか?
ChatGPT、Gemini、最近ではClaudeなど、LLMの性能の高さに注目が集まっています。
LLMのアウトプットをより高品質なものにするために、以下を考えることが重要です:
- 専門知識を与えて、それをもとに答えられるようにする
- ハルシネーションを抑えて、正しい内容で答えられるようにする
これらを満たすために、RAGという手法が有効とされています。
RAG(Retrieval-Augmented Generation)とは
RAGとは、外部の情報を利用してLLMの回答精度を高める手法です。
外部の情報はGoogle検索、Notion、自社データベースなど様々なものがあります。ユーザーの入力に関連した情報を外部から取得し、それをプロンプトに挿入することで精度を高めるテクニックです。
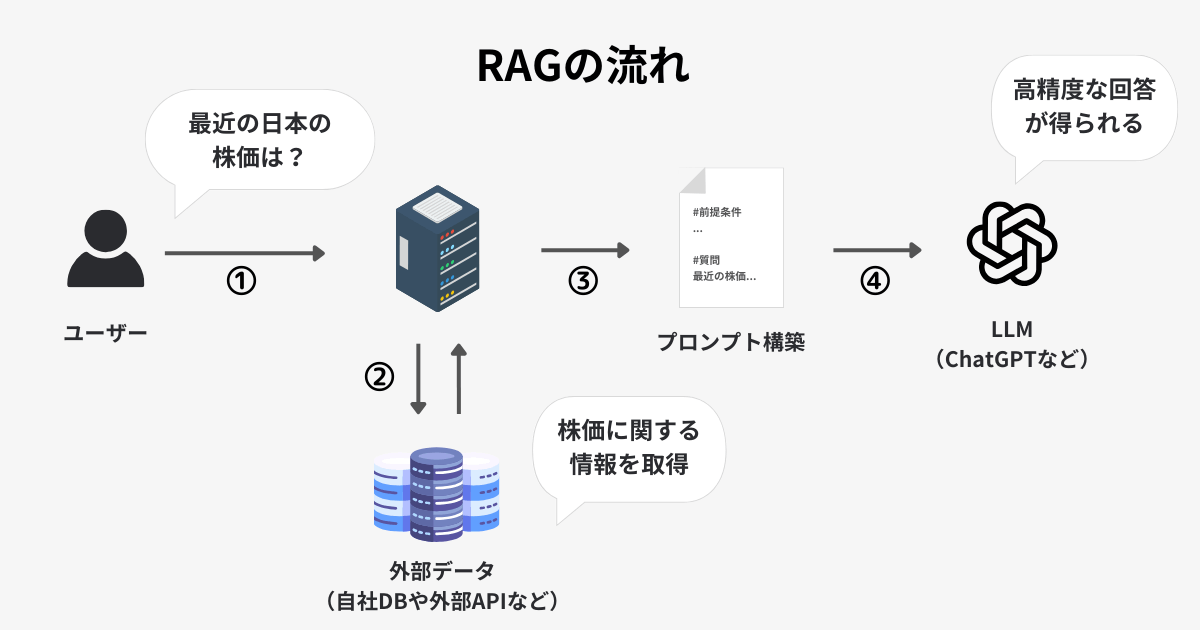
RAGの流れ。ユーザーの入力に合わせて外部データを利用することで回答の精度が高められる
RAGでのデータ取得にベクトル検索が有効
RAGの実例として、ユーザーの質問に対し、Notionにあるドキュメントを情報源に回答する場合を考えてみます。
ユーザーが 「風邪をひいたときは何食べたら良い?」 と聞いた場合、キーワード検索では「風邪」のような単語ベースで調べることになります。
一方でベクトル検索の場合、「栄養価」や「食事」、「健康」、「病気」などの近しい意味で関連ドキュメントを検索できます。周辺情報もまとめてプロンプトに挿入し、その上でAIが回答できるため、より精度の高い回答が期待できます。
また、ユーザーに欲しい商品の特徴を長文で教えてもらって、その情報から商品を推薦する場合はどうでしょうか。
キーワード検索の場合、最初に長文からキーワードを抽出するステップを踏むため、情報が欠落してしまいます。一方でベクトル検索の場合は文章全体をベクトル化して、それと各商品のベクトルとで類似度を計算します。ベクトル検索の方がより文脈や意図を汲むことができるはずです。
まとめ
ベクトルについて理解を深めるために、実際に動画検索のサービスを作りながら整理してみました。
今回は動画のタイトルや説明文などのテキストをベクトル化しましたが、サムネイル画像や動画そのものをベクトル化することも考えられます。どの方法が精度が高くなるのかは試してみたいところです。
後半ではなぜ生成AI時代にベクトルデータベースへの注目が高まっているかを考えてみました。
ベクトル検索自体は自然言語処理などのコミュニティでは古くから親しまれているものです。生成AIの台頭、またOpenAI Embeddings APIなどの登場で手軽にベクトル化できるようになったことが大きいのかなと考えました。

Discussion