cowriterという AIライティング補助ツールを作ってこっそりローンチした話
はじめまして。 microAI と申します。
自己紹介
お家DCが趣味で、
Raspberry Pi 5 x 5, GEEKOM Mini Air 12 x 2, Jetson Orin Nano NX 16G x 2 で Kubernetes でクラスターを組んでお家DCを運営しています。
CloudFlare Tunnel を使ってインターネットにいろいろなサービスを公開して遊んでいます。
ライティング補助ツールをこっそりローンチしました
ウェブメディアの運営もしているのですが、一人で記事を書くのが疲れるので、自分用にAIライティング補助ツールを作っていましたが、せっかくなので、一般公開しました。
大きく、簡易的なウェブサイト形式とエージェント型のChrome拡張機能の2つがあります。
ウェブサイト (横断検索+簡易記事生成/登録不要・無料)

書きたい記事のタイトルや内容を入力すると、PRTimesさんや、@Pressさん、ValuePressさんなどから出されているプレスリリースを横断検索することができます。
プレスリリースをクリックで復数選択し、AIに指示をだすと記事を作成してくれます。

書いた記事に対して、「もっと詳しく」などの修正指示を出すこともできますが、現状のAI(chatGPT 4o-mini)では、まるっと記事を書いても、読者のためになる記事は作ることができませんでした。
※私のプロンプト作成能力の低さが一番の原因
Chrome拡張機能 (横断検索+段落単位の記事生成/登録必要・無料)
こちらは、ウェブサイト版とは違い、エージェント型で、記事全体を一気に書き上げるというよりは、段落ごとにAIエージェントと一緒に作っていくイメージです。
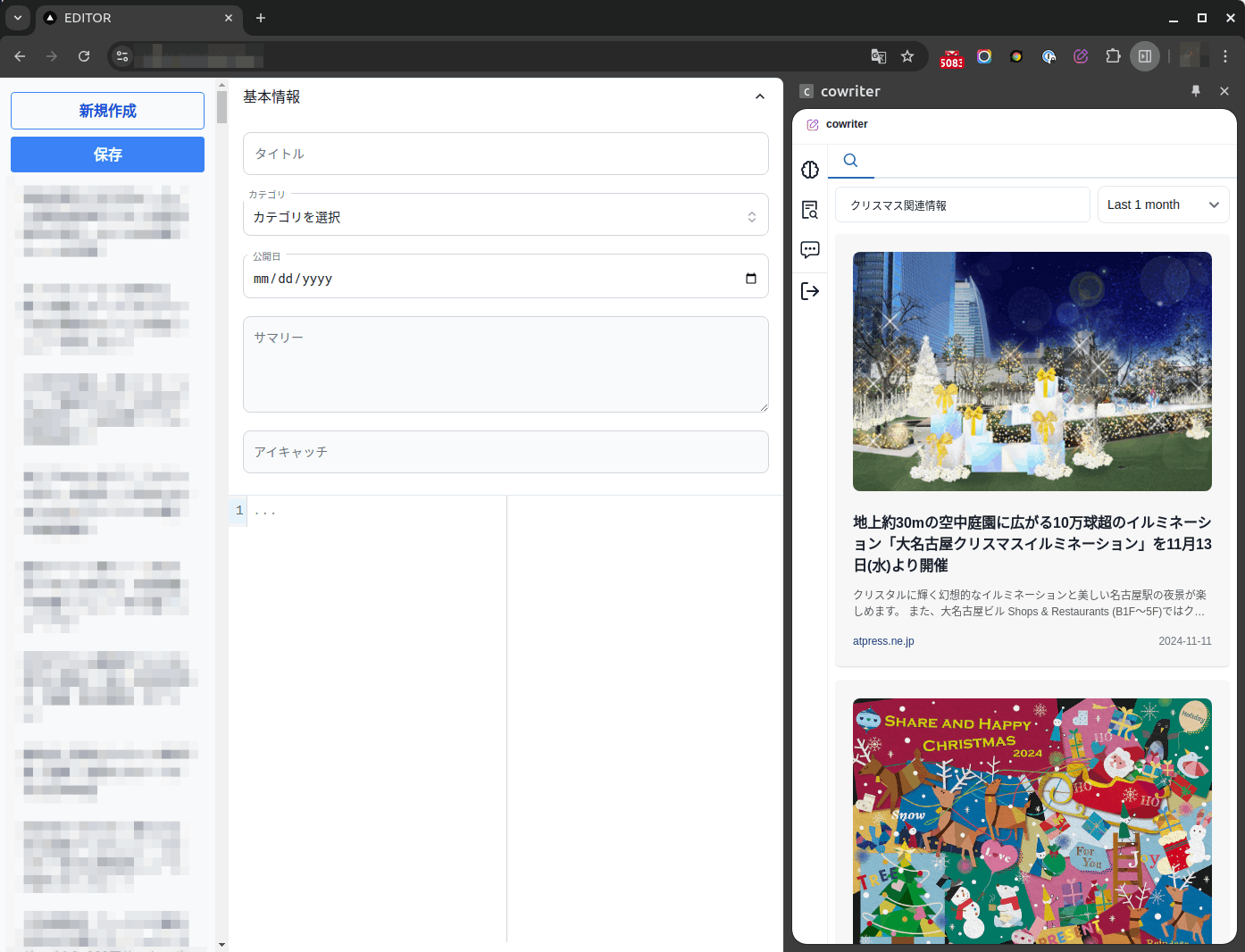
インストール後、アイコンをクリックするとサイドパネルが表示され、
- プレスリリース検索&選択機能
- 文体指定機能
- フリーチャット機能
を使用しながらAIと一緒に記事を作成できます。
詳しくは、マニュアル https://cowriter.jp/howto をご覧ください🙇
インストールはこちらから
cowriterのアーキテクチャ
cowriter がどのように作られているのか?などをご紹介します。
全体構成
フロントエンド: Next.js 14
バックエンド: Dify
クローラー: FastAPI
ベクトルデータベース: Weaviate
フロントエンド (Next.js 14)
Next.js で、Claude 先生と一緒にコードを書いています。
私程度が語る内容は特にないです・・・
バックエンド (Dify)
Next.js から直接 Dify のAPIをコールしています。
Next.js から Difyを直接叩くと、Dify のAPIキーが漏れるんですよね。
ただ、cowriter に特化したAPI仕様になっているので、悪用される可能性は極めて低いので一旦良しとしています。
クローラー (FastAPI)
PRTimesさんや、@Pressさん、ValuePressさんに迷惑がかからないように最新のニュースのみをゆっくりクリローリングさせていただいています。
クローリング部分は、簡易的なプログラムで作り、HTMLに一定の前処理を行った後、
trafilatura で本文抽出を行っています。
trafilaturaは、非常にすぐれた本文抽出エンジンなのですが、画像抽出機能がまだベータ版なので、かなりの割合で、画像のURLが取得できません。
また、少し変わった形式のリンクなども削除してしまうため、trafilatura が抽出しやすいように前処理を少し行っています。
画像系の前処理は をかなり参考にさせていただきました。
ベクトルデータベース (Weaviate)
クローリングした結果を、Difyのナレッジ用にもつかっている Weaviate に挿入しています。
Weaviate は、k8sのクラスターには入れておらず、RTX 4090搭載のゲーミングPCで運用しています。
テキストの埋め込みには
cl-nagoya/sup-simcse-ja-large
を
リランカーには
hotchpotch/japanese-reranker-cross-encoder-large-v1
を使用させていただきています。感謝
色々と試しましたが、この2つのセットが私のニーズにおいては精度が高かったです。
なにかの役に立てばと docker-compose.yml を公開しておきます。
services:
weaviate:
command:
- --host
- 0.0.0.0
- --port
- '8080'
- --scheme
- http
image: cr.weaviate.io/semitechnologies/weaviate:1.26.1
ports:
- 8080:8080
- 50051:50051
volumes:
- weaviate_data:/var/lib/weaviate
- /backup/weaviate:/var/lib/backup
restart: on-failure:0
environment:
ENABLE_MODULES: 'text2vec-transformers,sum-transformers,reranker-transformers,ref2vec-centroid,backup-filesystem'
BACKUP_FILESYSTEM_PATH: '/var/lib/backup'
# メモリ管理とパフォーマンス最適化
LIMIT_RESOURCES: "true"
MEMORY_LIMIT_PERCENT: "80"
QUERY_MAXIMUM_RESULTS: "10000"
QUERY_DEFAULTS_LIMIT: 25
PERSISTENCE_LSM_ACCESS_STRATEGY: "roaring"
ENABLE_TOKENIZER_GSE: 'true'
TRANSFORMERS_INFERENCE_API: 'http://t2v-transformers:8080'
SUM_INFERENCE_API: 'http://sum-transformers:8080'
RERANKER_INFERENCE_API: 'http://reranker-transformers:8080'
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'false'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
DEFAULT_VECTORIZER_MODULE: 'text2vec-transformers'
CLUSTER_HOSTNAME: 'node1'
AUTHENTICATION_APIKEY_ENABLED: 'true'
AUTHENTICATION_APIKEY_ALLOWED_KEYS: 'ここにキーを書く'
AUTHENTICATION_APIKEY_USERS: 'ここにユーザー名を書く'
deploy:
resources:
limits:
memory: 56G
reservations:
memory: 28G
tty: true
stdin_open: true
t2v-transformers:
image: ghcr.io/microaijp/transformers-inference:sup-simcse-ja-large
environment:
ENABLE_CUDA: '1'
NVIDIA_VISIBLE_DEVICES: 'all'
deploy:
resources:
limits:
memory: 8G
reservations:
memory: 4G
devices:
- capabilities:
- 'gpu'
tty: true
stdin_open: true
sum-transformers:
image: sum-transformers:facebook-bart-large-cnn-1.0.0
environment:
ENABLE_CUDA: '1'
NVIDIA_VISIBLE_DEVICES: 'all'
deploy:
resources:
limits:
memory: 8G
reservations:
memory: 4G
devices:
- capabilities:
- 'gpu'
tty: true
stdin_open: true
reranker-transformers:
image: ghcr.io/microaijp/reranker-transformers:japanese-reranker-cross-encoder-large-v1
environment:
ENABLE_CUDA: '1'
NVIDIA_VISIBLE_DEVICES: 'all'
deploy:
resources:
limits:
memory: 8G
reservations:
memory: 4G
devices:
- capabilities:
- 'gpu'
tty: true
stdin_open: true
volumes:
weaviate_data:
開発スタートから2ヶ月くらい経過していますので、2ヶ月間の各社のプレスリリースをすべて保存した状態の nvidia-smi の結果
Every 0.1s: nvidia-smi
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4090 On | 00000000:01:00.0 Off | Off |
| 0% 42C P8 24W / 450W | 8376MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1270 G /usr/lib/xorg/Xorg 99MiB |
| 0 N/A N/A 1423 G /usr/bin/gnome-shell 19MiB |
| 0 N/A N/A 3186 G gnome-control-center 6MiB |
| 0 N/A N/A 77560 C /usr/local/bin/python 3886MiB |
| 0 N/A N/A 77561 C /usr/local/bin/python 2392MiB |
| 0 N/A N/A 77562 C /usr/local/bin/python 1944MiB |
+---------------------------------------------------------------------------------------+
同じく、メモリの状況
$ ps aux --sort=-%mem | awk 'NR==1{print $0; next} {printf "%-10s %-10s %-10s %-10s %-10.2fGB %s\n", $1, $2, $3, $4, $6/1024/1024, $11}' | head -n 5
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 77330 23.4 81.1 50.84 GB /bin/weaviate
root 77561 0.3 3.0 1.91 GB /usr/local/bin/python
root 77560 2.2 1.8 1.19 GB /usr/local/bin/python
root 77562 0.2 0.1 0.10 GB /usr/local/bin/python
Weaviate 本体が 52G使用していますね。。。
Weaviate はデータをメモリ上で管理するため大量のメモリを使用します。このまま増えたらどうなるんだろう・・・また、別の記事で状況をシェアしていきいたいと想います。
まとめ
本記事では、cowriterをローンチした話と、そのアーキテクチャの概要だけ記載しました。
cowriter 無料で利用できますので是非ご利用いただき、コメントなどもらえると嬉しいです。
今後も、cowriterで使用した技術情報などをどんどん公開していきます。
Discussion