この記事は MICIN Advent Calendar 2023 の 12 日目の記事です。
前回は Mimu-Salon さんの「MICIN で未経験エンジニアとしての 1 年半、成長と学びの挑戦」でした。
はじめに
本稿では App Mesh を採用するに至った経緯と導入時の大まかな手順、そして App Mesh を用いたカナリアリリース実施についてのナレッジや導入後の小話について記載します。
以下公式ドキュメント記載の用語は断りなく使用します。
使用している技術
| 技術カテゴリ | 名前 |
|---|---|
| サーバ | ECS / Fargate |
| モニタリングサービス | Datadog |
| トレーシングライブラリ | dd-trace |
採用の経緯
分散トレーシングの実現
MICIN のプロダクトでは従来より、マイクロサービスとの通信において分散トレーシングが実現されておらずエラー発生時の調査に苦戦することがありました。その問題を解決するために以下の案が挙がりました。
- 各サーバにトレーシングの実装する
- Service Mesh を導入する
しかし、プロダクトは Ruby, JavaScript, Go など複数言語で実装されています。そのため、分散トレーシング実現に用いるツールは各言語に対応していることが望ましいと考えました。また、プロダクト数に対しての SRE の人数が少ないことから、Service Mesh の導入作業はなるべく少ない作業で済むことが期待されました。そこで、全社統一的に Service Mesh 導入することで効率の良い分散トレーシング導入を狙いました。
カナリアリリースを用いた安全なリリース手法の確立
MICIN では多数のプロダクトが依存するマイクロサービスである、ビデオ通話基盤を開発・運用しています。このビデオ通話基盤はオンライン診療事業を主としている MICIN にとって高い信頼性を担保すべきサーバです。しかし、ブルーグリーンデプロイやカナリアリリース等のリリース方式を採用していなかったためリリース担当者は不安に苛まれながら毎回リリースしていました。
そこで、以下を同時に実現できる Service Mesh 導入し、サービスの信頼性向上を狙いました。
- トレーシングの導入
- 安全なリリース手法の確立
MICIN ではすべてのプロダクトは ECS / Fargate にてホスティングされています。そのため、Fargate で使用可能な Service Mesh である App Mesh を採用することとしました。
ちなみに、プロダクトにカナリアリリースのみを導入することが目的であれば、ALB Listener Rule を用いる方法も AWS 公式ドキュメントでは紹介されています。
App Mesh の導入
アーキテクチャ
App Mesh 導入前後でどのようにアーキテクチャが変更されたかについて記載します。
App Mesh 導入前
App Mesh 導入前のアーキテクチャは下図の通りです。
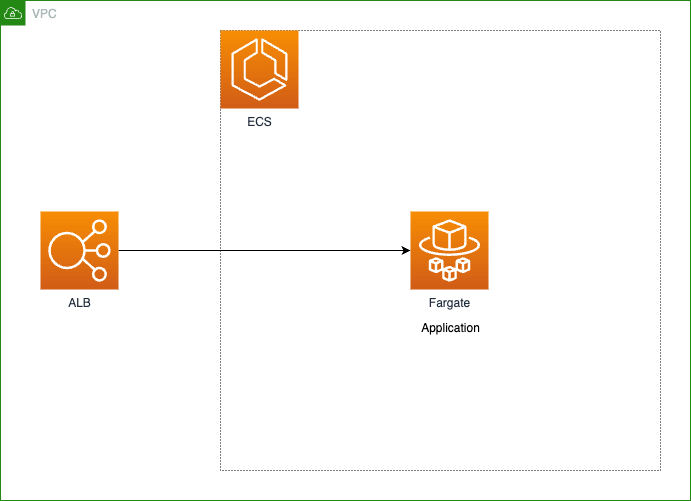
App Mesh 導入前のアーキテクチャ図 [1]
ALB Target Group にはアプリケーションタスクを直接アタッチしていました。
App Mesh 導入後
App Mesh 導入後のアーキテクチャは下図の通りです。
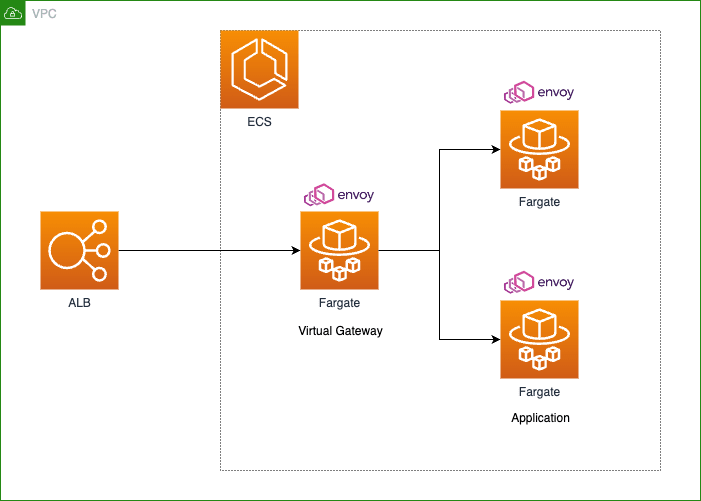
App Mesh 導入後のアーキテクチャ図
ALB Target Group には Virtual Gateway の役割を持つ ECS タスクをアタッチしています。Virtual Gateway タスクの後ろには Envoy コンテナをサイドカーとしてデプロイしたアプリケーションタスクを配置しています。アプリケーションタスクは stable / canary フェーズをそれぞれ配置しています。フェーズについては後述します。
導入手順
上記のアーキテクチャの変更点を踏まえ、App Mesh 導入時にダウンタイムが発生しない手順を作成しました。大まかな手順は以下の通りです。
- Virtual Service や Virtual Node 等の App Mesh リソースを作成
- ALB Target Group がアタッチされた Virtual Gateway をデプロイ
- App Mesh 管理下の Envoy コンテナをサイドカーとして設定したアプリケーションをデプロイ
- Virtual Gateway にアタッチした ALB Target Group を ALB Listener にトラフィックレート 0% で登録
- ECS タスクが再デプロイされるため、完了するまで待つ
- 新環境へのリクエストが Virtual Gateway 経由で正常に行われていることを確認
- Virtual Gateway にアタッチした ALB Target Group を ALB Listener にトラフィックレート 100% に変更
- リクエストが Virtual Gateway 経由で正常に行われていることを確認
- 不要なリソースの後片付け
設定値
Datadog 上でマイクロサービス間の通信を適切にトレーシングできるように、App Mesh 管理下の Envoy ログのフォーマットを Terraform を用いて設定しています。以下は Terraform ファイルの抜粋です。
locals {
appmesh_log_format = {
# 中略
response_code = "%RESPONSE_CODE%"
method = "%REQ(:METHOD)%"
path = "%REQ(X-ENVOY-ORIGINAL-PATH?:PATH)%"
duration = "%DURATION%"
response_duration = "%RESPONSE_DURATION%"
response_flags = "%RESPONSE_FLAGS%"
request_id = "%REQ(X-REQUEST-ID)%"
trace_id = "%REQ(X-DATADOG-TRACE-ID)%"
span_id = "%REQ(X-DATADOG-PARENT-ID)%"
}
}
resource "aws_appmesh_virtual_node" "api" {
# 中略
spec {
# 中略
logging {
access_log {
file {
path = "/dev/stdout"
format {
dynamic "json" {
for_each = local.appmesh_log_format
content {
key = json.key
value = json.value
}
}
}
}
}
}
}
}
余談(喧伝)
aws_appmesh_virtual_node リソースの spec.logging.access_log.file.format.json フィールドについてです。以前は terraform-provider-aws はこちらの設定が実装されていませんでしたが、修正する Pull Request を送信したところ merge してもらいました。
リリースノートに自分のコミットが載るのは初めての経験でした。
その日は一日中ウキウキでした。業務終了後にオフィス近くの日本橋三越にて購入したお祝いのシャンパンを家族で乾杯したことを昨日のことのように覚えています。
デバッグする際に重要なログフィールドは以下の通りです。
| フィールド名 | 説明 |
|---|---|
response_flags |
主に Envoy 起因でエラーが発生した際に、こちらのフィールドの値によりエラーの内容が推測可能(リンク)。 |
trace_id |
マイクロサービス間の通信の際に一意の ID が振られる。一連のリクエスト全てが同一の値となる。この値により各リクエストの紐付けが可能(リンク)。 |
span_id |
リクエスト処理時の個々のオペレーションに対して一意の ID が振られる。(リンク) |
Datadog GUI 上にてトレーススパンを表示させるためには、ログに以下のフィールドを含めたうえで Datadog に送信する必要があります。
{
"dd": {
"trace_id": 111,
"span_id": 222
},
...
...
...
}
このあたりの仕様は Datadog 公式ドキュメントが参考になります。
Envoy ログを整形せずにそのまま Datadog に送信した場合上記のログフォーマットではないため、FireLens 上で Fluent Bit を用い Envoy ログを整形しています。
また、アプリケーションログについても Envoy ログ同様、上記のログフォーマットに準拠するように整形する必要があります。各サーバに対して dd-trace を導入可能である場合は trace_id / span_id は dd-trace により追加されるため導入作業が少なく済みます。しかし、dd-trace 未対応の言語や古いバージョンで動作しているプロダクトにおいては、リクエストヘッダの trace_id / span_id を取得しログに追加する実装を自前で行う必要があります。
上述のようにログフォーマットを整形することで以下画像のように Datadog GUI 上でトレーススパンが表示されます。

Datadog GUI 上でのトレーススパン
Datadog 上でトレーススパンを表示させることにより、マイクロサービス側で発生したエラーがどのような通信経路で発生したかを可視化できるようになりました。
例えば上図では、Envoy(黄色のスパン)が Rack(紫色のスパン)にリクエストを受け流しています。その後 Rack が DB(黄緑色のスパン)からデータを取得し、gRPC クライアント(あずき色のスパン)が gRPC サーバの Envoy(赤色のスパン)に 2 回リクエストを送信していることを読み取ることができます。
デグレチェック
Envoy コンテナをサイドカーとしてデプロイした際、レスポンスタイム等の非機能面においてデグレが生じていないことを確認するために grafana/k6 を用い簡単な負荷試験を行いました。負荷試験は以下の観点において許容範囲内の値であることの確認を目的として行いました。
- CPU / メモリの利用量は許容範囲内か
- レスポンスタイムは許容範囲内か
以下に負荷試験を行った際のサーバスペックや各種パラメータを記載します。
| パラメータ名 | 値 |
|---|---|
| 試験時間 | 600 [s] |
| レート | 0.5 [1/s] |
| CPU | 0.25 [vCPU] |
| メモリ | 0.5 [GB] |
ECS タスク数(desiredCount)は 1 つと 2 つの場合で負荷試験を行いました。過去の負荷試験の結果から、ECS タスク数の増減が結果に最も影響を与えるというナレッジがあったため、CPU / メモリを増減させての負荷試験は行っていません。
結果としては、レスポンスのステータスコードはすべて 200 が返り、CPU / メモリの利用量のトレンドに大きな変化は観測されませんでした。レスポンスタイムは App Mesh 導入前の平均 4ms から導入後の 13ms とデグレが観測されましたが、いずれも許容範囲内の値であったため App Mesh を導入することが決定しました。
カナリアリリースの導入
前述通りに設定したことで App Mesh の導入が完了しました。次にカナリアリリースを導入しました。
App Mesh を用いたカナリアリリースの概要
カナリアリリースのために 2 種類の ECS サービスを定義し、それぞれ stable / canary と名付けています。この stable / canary を総称してフェーズと呼んでいます。フェーズという概念や stable / canary という呼称は GCP Cloud Deploy のドキュメントを参考にしました。
それぞれのフェーズの役割は以下の通りです。
| フェーズ | 役割 |
|---|---|
stable |
安定したバージョンのアプリケーション。広範囲のユーザに公開されている、テスト済みの信頼性の高いバージョン。 |
canary |
新しいバージョンのアプリケーションを実際の本番環境でテストするためのバージョン。 |
App Mesh を用いてカナリアリリースをするには、Route の設定において stable / canary フェーズそれぞれの Virtual Node に対してのトラフィックレートを増減させることで実現可能です。実際の設定方法については後述します。
インフラの管理
App Mesh のリソースを管理する際に Terraform を用いて管理するリソースと AWS CLI を用いて管理するリソースがあります。それぞれ以下の観点に基づいて管理するツールを選択しています。
Terraform を用いて管理するリソース
MICIN ではすべてのプロダクトにおいてアプリケーションリポジトリとインフラリポジトリを分離しています。インフラリポジトリでは主に Terraform を用いてインフラリソースを管理しています。分離している理由はアプリケーションとインフラのリリースサイクルの違いによるものです。一般的にアプリケーションのリリースはインフラのリリースと比較すると高頻度に行われることが多いです。MICIN ではリリースサイクルの異なるリポジトリを分離することで、リポジトリの肥大化や CI の複雑化を防いでいます。
インフラリポジトリで Terraform を用いて管理するリソースは以下の通りです。リンクは AWS リソースに対応する Terraform リソース名です。
- Mesh :
aws_appmesh_mesh - Virtual Gateway :
aws_appmesh_virtual_gateway - Gateway Route :
aws_appmesh_gateway_route - Virtual Router :
aws_appmesh_virtual_router - Virtual Service :
aws_appmesh_virtual_service - Virtual Node :
aws_appmesh_virtual_node
Route(aws_appmesh_route)以外のすべての App Mesh リソースを Terraform を用いて管理しています。
AWS CLI を用いて管理するリソース
Terraform を用いて管理するリソース以外の App Mesh リソースは AWS CLI を用いて管理しています。AWS CLI を選定した理由は以下の通りです。
- カナリアリリースはアプリケーションリリースごとに行われるため、リリースサイクルの観点からアプリケーションリポジトリで管理したい
- なるべくメンテナンスコストがかからず認知負荷の小さい構成としたい
前述の通り、Route のみ Terraform ではなく、AWS CLI を用いて管理しています。アプリケーションリポジトリには stable / canary フェーズそれぞれ専用の Route の設定を json ファイルとして配置しています。
{
"priority": 100,
"httpRoute": {
"match": {
"prefix": "/",
"port": 8080
},
"action": {
"weightedTargets": [
{
"virtualNode": "stable",
"port": 8080,
"weight": 100
},
{
"virtualNode": "canary",
"port": 8080,
"weight": 0
}
]
},
"timeout": {
"perRequest": {
"unit": "s",
"value": 60
}
}
}
}
{
"priority": 100,
"httpRoute": {
"match": {
"prefix": "/",
"port": 8080
},
"action": {
"weightedTargets": [
{
"virtualNode": "stable",
"port": 8080,
"weight": 95
},
{
"virtualNode": "canary",
"port": 8080,
"weight": 5
}
]
},
"timeout": {
"perRequest": {
"unit": "s",
"value": 60
}
}
}
}
2 つのファイルの差分は httpRoute.action.weightedTargets[*].weight の値のみです。こちらの値を増減させることで stable / canary フェーズのトラフィックレートを変更できます。stable.json では 100% stable フェーズにリクエストします。canary.json では 95% のリクエストを stable フェーズに、5% のリクエストを canary フェーズにリクエストするように設定しています。
毎リリース時にそれぞれ設定すべき方のファイルを選択し、AWS CLI を用いて Route の設定を更新しています。例えば、canary フェーズへと移行する際は以下のコマンドを実行し、Route の設定を変更します。
aws appmesh update-route \
--mesh-name="sample-mesh" \
--virtual-router-name="sample-virtual-router" \
--route-name="sample-route" \
--spec="$(cat canary.json)"
ログフォーマットの修正
アプリケーションサーバにリクエストを送信した際に stable / canary のどちらのサーバのレスポンスログであるかを判別可能とするフィールドをログに追加します。こちらのフィールドの値をもとにそれぞれのフェーズのエラーレートを計測します。以下はアプリケーションログの抜粋です。
{
...
"_raw": {
...
"controller": "Api::HealthcheckController",
"method": "GET",
"duration": 1.07,
"path": "/healthcheck",
"view": 0.21,
"action": "healthcheck",
"request_id": "cdd6b482-a4d6-9f91-8619-dfe52198cfa3",
"status": 200,
...
},
...
"hash": "eda3f4f88441002e91140ccb9b46e1fe11fa7d2c",
"phase": "stable",
...
}
既存のログフィールドに加え、カナリアリリース導入済みのアプリケーションに対しては hash 及び phase というフィールドを追加しています。
追加されたログフィールドはそれぞれ以下の役割を担っています。
| フィールド名 | 役割 |
|---|---|
hash |
Git のコミットハッシュを格納。調査時に該当ログがどの時点の実装であるかを判別するために使用。 |
phase |
stable もしくは canary の値のどちらかを格納。該当ログがどちらのサーバが出力したログであるかを判別するために使用。 |
後述しますが、これらの値はダッシュボード上にアプリケーションのエラーレートを監視するために使用します。
ブランチ運用
カナリアリリース導入済みのアプリケーションでは 5 種類のブランチを使用しています。それぞれの名前と役割は以下の通りです。
| ブランチ名 | 役割 |
|---|---|
main |
機能開発する際にこちらのブランチから新規ブランチを作成。 |
feat |
機能開発する際に使用するブランチ。 |
fix |
機能修正する際に使用するブランチ。 |
release/canary |
canary フェーズにリリースする際に使用。 |
release |
stable フェーズにリリースする際に使用。hotfix 等の例外を除き release/canary をベースブランチとして期待する。 |
カナリアリリースのフロー
リリースフローは下図に詳細を記載しています。
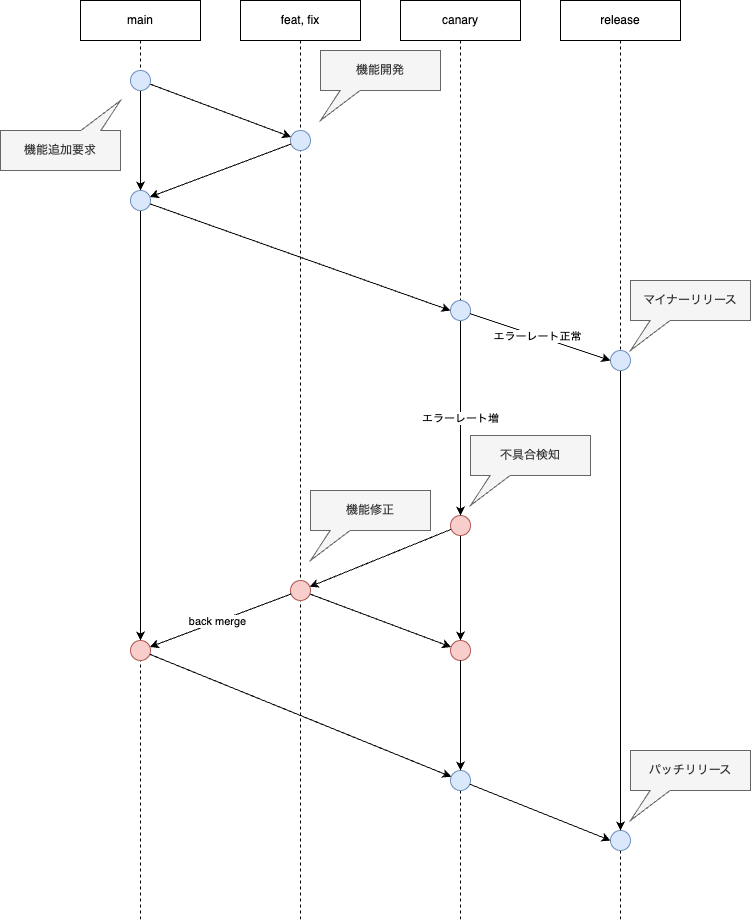
リリースフロー
以下ではリリース成功時及び失敗時の具体的なフローについて記載します。
リリース成功時
リリースが期待通り成功した場合の手順について記載します。
release/canary ブランチに push しエラーレートが許容範囲内の値であることを確認したあとに release ブランチに push します。
ブランチの使用法は以下のドキュメントを参考にしました。
以下、参照箇所の抜粋です。
一方の VirualNode A (仮の名前として用います) からもう一方の VirtualNode B へカナリーリリースを実施すると通常時にリクエストを受ける環境は VirtualNode B とります。その次のリリースタイミングでは逆に VirtualNode B -> VirtualNode A と切り替えなくてはいけないのか?またアプリケーションのデプロイワークフローの対象リソースが A なのか B なのか、という問題が浮上してきます。
これにより、VirtualNode A は通常時用 ECS 環境という前提を守ることが出来ます。また、A -> B, B -> A とカナリーリリースの流れの向きを切り替える問題も解消されます。
MICIN では以下の手順でカナリアリリースしています。
-
mainブランチからrelease/canaryブランチに merge し、canaryフェーズにリリースする -
canaryフェーズへのトラフィックレートを指定の値(例 : 5%)とするために Route の設定を更新する -
canaryフェーズのエラーレートを監視する - (
canaryフェーズのエラーレートが許容範囲内で推移) -
release/canaryブランチからreleaseブランチに merge し、stableフェーズにリリースする(リリースフロー図の「マイナーリリース」に対応) -
stableフェーズへのトラフィックレートを 100% とするために Route の設定を更新する -
canaryフェーズの ECS Service のdesiredCount(ECS タスク数)を 0 とする
リリース失敗時
canary フェーズにリリース後、canary フェーズにてエラーレートが急増した場合の手順について記載します。
具体的な手順は以下の通りです。
-
mainブランチからrelease/canaryブランチに merge し、canaryフェーズにリリースする -
canaryフェーズへのトラフィックレートを指定の値(例 : 5%)に変更する -
canaryフェーズのエラーレートを監視する - (
canaryフェーズのエラーレートが急増する)(リリースフロー図の「エラーレート増」に対応) -
stableフェーズへのトラフィックレートを 100% に戻す -
canaryフェーズの ECS Service のdesiredCount(ECS タスク数)を 0 とする -
release/canaryブランチからfixブランチを切り、エラーを修正しfixブランチに push する(リリースフロー図の「機能修正」に対応) -
fixブランチをrelease/canaryブランチに merge し、canaryフェーズにリリースする -
canaryフェーズのエラーレートを監視する - (
canaryフェーズのエラーレートが許容範囲内で推移) -
fixブランチをmainブランチに back merge する
カナリアリリースを実施しない場合
カナリアリリースを実施しない場合があります。例えば以下の場合です。
- 軽微な実装の場合
- 本番環境にて hotfix で修正すべきエラーが発生した場合
-
canaryフェーズとstableフェーズの実装が非互換である場合
軽微な実装の場合
軽微な実装の場合は、カナリアリリースの運用コストがリリース失敗時のコストよりも大きいため、カナリアリリースを実施しない選択肢を視野に入れると良いかもしれません。
本番環境にて hotfix で修正すべきエラーが発生した場合
データ不整合や影響範囲が広いエラーが出てしまった場合、ユーザに対して修正されたアプリケーションを迅速にデリバリする必要があります。したがって、カナリアリリースを実施しません。
canary フェーズと stable フェーズの実装が非互換である場合
2 つのフェーズ間の実装が非互換である場合、クライアントがアクセスするたびに接続されるサーバのフェーズが異なるとデータ不整合等の問題の原因となる可能性があります。基本的にはフェーズ間の実装は互換性を保つように実装することが望ましいとされていますが、どうしようもない場合はカナリアリリースを実施しません。
モニタリング用のダッシュボード
カナリアリリースではモニタリングサービスのダッシュボードやアラート等でアプリケーションのエラーレートを監視し、リリースの継続可否を判断することが肝となります。MICIN では Datadog にてエラーレートを監視するダッシュボードを作成しました。ダッシュボードはサイトリライアビリティワークブック 16 章掲載のダッシュボード画像を参照しつつ作成しました。
下図が現状 MICIN で運用している Datadog ダッシュボードです。
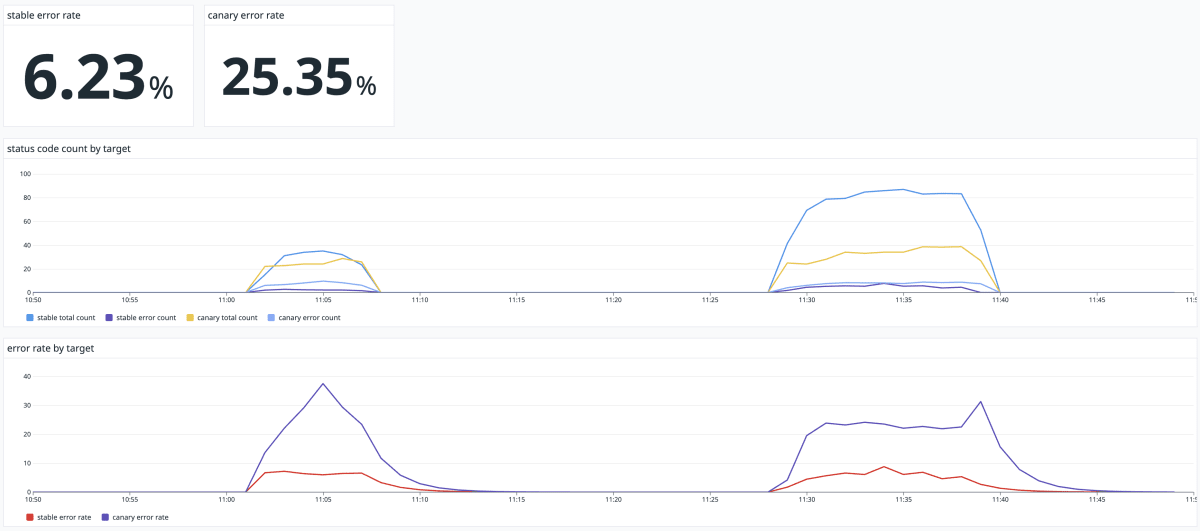
エラーレート監視のためのダッシュボード
仮に canary フェーズ側でのエラーレートが急増した場合、リリースを切り戻す判断は各リリース担当者が行います。そしてエラーの修正を hotfix で行うか、もしくは次回の定常リリースに修正を含めるかは各プロダクトチームのステークホルダが議論したうえで決定します。
現在はリリースを切り戻すエラーレートの閾値は明確には定められておらず、各リリース担当者の裁量に委ねられています。ただし、stable / canary フェーズそれぞれのエラーレートの差分が大きい場合はリリースを切り戻す 1 つの指標としています。
現状のダッシュボードの課題として、アプリケーション全体のエラーレートの監視のみではリクエスト数が少ないエンドポイントをリリースした際に、該当エンドポイントのエラーレートが急増したとしても見過ごされる可能性があります。そのためエンドポイントごとにエラーレートの監視が可能な可視化の方法を検討しています。
また、アプリケーションの実装が GraphQL の場合はエンドポイントではなく、Mutation / Query ごとにエラーレートを監視する必要がありそうです。こちらについても追って対応方法を検討したいと考えています。
カナリアリリースを導入する際に検討すべきこと
ここまでカナリアリリースの導入方法や運用について記載しました。
カナリアリリースを導入することにより一定程度安全にリリースが可能であるため、プロダクトのステークホルダにカナリアリリースを用いた安全なリリース戦略を採用したいかということを質問すると、おそらく「採用したい」という返答が来ると考えられます。
しかし、App Mesh を用いたカナリアリリース導入にあたり、様々なメリットがありつつも見過ごせないデメリットもいくつか存在します。カナリアリリースについてはメリットのみが語られることが多いですが、こちらではデメリットの方にフォーカスしたい思います。
カナリアリリースを導入した際のデメリットについて列挙します。
- リリースパイプラインの煩雑化
- 料金コスト増
- エラーレート監視体制の組成
- 通信経路の煩雑化
リリースパイプラインの煩雑化
カナリアリリースを導入することにより導入前と比較すると、必要なブランチ数やリリース時のルールが増加しリリースパイプラインが煩雑化します。
料金コスト増
App Mesh を用いたカナリアリリースにおいては、Virtual Gateway をホスティングするためのサーバが新規で必要となるため、料金コスト増となります。
また、カナリアリリースにより stable / canary フェーズに対して少なくとも 1 回ずつリリースする必要があるため、リリース回数の増加により GitHub Actions 等のインテグレーションサービスの料金コストが増加します。
そして、Envoy は非常に軽量であるとはいえ CPU / メモリを多少は消費します。したがって、App Mesh 導入前の CPU / メモリ利用量が既に上限に近づいていた場合はサーバスペックを増強する必要があるかもしれません。
エラーレート監視体制の組成
カナリアリリースの実施後はエラーレートを監視する必要があるため、その体制を組成しなくてはなりません。また、エラーレートを監視のためにログデリバリやモニタリングツールを導入し、必要に応じてログフォーマットの修正等を行う必要があります。
通信経路の煩雑化
App Mesh を用いたカナリアリリースの導入により、アプリケーションサーバと通信するには Virtual Gateway やアプリケーションのサイドカーとしてデプロイされている Envoy コンテナを通過する必要があります。したがって、導入前と比較すると通信経路が煩雑化します。また、クライアントからアプリケーションサーバにリクエストが到達するまでにエラーが発生した場合のデバッグ方法は、それまでアプリケーション運用チームに蓄積されたナレッジには存在しない可能性があります。
問いかけ
本章ではカナリアリリースのデメリットについて箇条書きしました。カナリアリリースを導入する前に次の点を考えてみてください。
- 現在のリリース障害の対応コストは導入による料金コスト増を上回っていますか?
- 導入するプロダクトのチームはカナリアリリースの運用コスト増に対応できますか?
- SLA, SLO 等の安全なリリースを必要とする指標はありますか?
- 導入を検討しているプロダクトのリリース障害はユーザーに大きなインパクトを与えますか?
上記の質問に対して Yes が少ない場合はカナリアリリースを導入しないほうが幸せになれるかもしれません。
導入時に気づいたこと・ハマったこと
App Mesh 導入時にて気づいたことやハマったことがいくつかあったため、紹介します。
Virtual Gateway はクロスアカウントで使用することができない
Virtual Gateway デプロイ時に以下の gRPC ステータスコード 3 のエラー解決にハマりました。
MICIN のプロダクトのインフラのアーキテクチャでは、すべてのプロダクトが依存しうるリソースは専用の AWS アカウント(以下、「プロダクト間共有アカウント」)を作成し、そのアカウントにて各リソースのデプロイが行われています。App Mesh のメッシュ(名前が紛らわしいため terraform-provider-aws のリソース名で示すと aws_appmesh_mesh)はすべてのプロダクトが同一のメッシュを使用するとサービス間の名前解決等、諸々都合が良いかと思いプロダクト間共有アカウントに定義しました。
しかし、Virtual Gateway をデプロイする際に上記のエラーに遭遇しました。ECS サービスやタスクの設定を見直しても typo 等が見つからず解決まで時間を費やしてしまいましたが、公式ドキュメントより以下の記述を発見しました。
Owners can create virtual gateways and virtual gateway routes.
どうやら、Virtual Gateway はメッシュを作成した AWS アカウントにのみデプロイ可能なようです。そこで、Virtual Gateway をデプロイする AWS アカウントに改めてメッシュを作成し、再度デプロイしたところ無事エラーは解決しました。
カナリアリリースを導入しない場合は Virtual Gateway は不要の可能性あり
Virtual Gateway の責務は、Virtual Gateway に到達したリクエストを Route に設定したトラフィックレートに基づきアプリケーションの Virtual Node に対してリクエストを振り分けることです。したがって、カナリアリリースを導入しない場合は Route でのトラフィックレートを管理する必要がないため Virtual Gateway は不要となります。
Virtual Gateway を使用しない場合は ALB Target Group をアプリケーションの ECS タスクにアタッチします。リクエスト時に Virtual Gateway を経由しないためリクエストの通信経路が簡略化されます。また、Virtual Gateway の分の ECS タスク数を減らすことができるため料金コストも抑えることができます。
App Mesh を導入する理由がマイクロサービス間の分散トレーシング実現のみである場合は Virtual Gateway を使用しないアーキテクチャを検討しても良いかもしれません。
response_flags が DC となっているリクエストが稀にある
App Mesh ログを Datadog APM ページで眺めていると、ヘルスチェックに使用しているエンドポイントが 1% 以下の割合でエラーが発生していることが目に付きました。しかし、アプリケーションログを見るとヘルスチェックエンドポイントに対するリクエストで 500 番台のエラーを出しているログは見当たりませんでした。つまり、Envoy レイヤではエラーが発生しているがアプリケーションレイヤではエラーが発生していないという状況でした。
前提として、当該アプリケーションタスクのヘルスチェックは以下の 3 箇所で行っています。
- Datadog Synthetic モニタリングによるアプリケーション外からのヘルスチェック
- ALB Target Group による VPC 内でのヘルスチェック
- アプリケーションタスクにデプロイした Envoy コンテナからのヘルスチェック
上記のうち、Envoy コンテナからのヘルスチェックのみエラーが確認されました(どのレイヤにおけるヘルスチェックであるかはリクエスト元の IP アドレスをもとに判断しています)。
Envoy エラーログを確認してみたところ、エラーログの response_flags の値はすべて DC となっていました。この値は Envoy 公式ドキュメントによると、Downstream connection termination. と記載があり、リクエスト元のサーバが通信を遮断したとのことです。
色々調べてみたところ、AWS 公式ドキュメントによるとデフォルトの最大リトライ回数は 2 という記載を見つけました。
アプリケーションタスクにデプロイした Envoy コンテナとアプリケーションコンテナ間の通信は稀に失敗するため Envoy のヘルスチェックではエラーが観測されました。しかしアプリケーション外からヘルスチェックを行った場合、Envoy コンテナとアプリケーションコンテナ間の通信で失敗していたとしても Envoy レイヤでリトライされていたため、アプリケーション外からはエラーが観測されなかったと推測しています。
Envoy レイヤでリトライしているためアプリケーションの外から観測した場合はエラーとして認知されないこと、そして、response_flags の値が DC となった際にヘルスチェックが失敗するレートが SLO で定めている値と比較して十分小さい値であることから Envoy を運用するうえで許容すべきエラーであると判断しました。
デフォルトのタイムアウトが少し短い
公式ドキュメントではデフォルトのタイムアウトは 15 秒であることが明記されています。タイムアウト起因のエラーはステージング環境におけるテストでは気づきにくく、データ量やトラフィック量の多い本番環境にてアプリケーションが稼働して初めてエラーに直面しがちです。ちなみに、MICIN では本番環境リリース前ギリギリのところでデフォルトのタイムアウトの存在に気づき、設定を修正することが出来ました。
さいごに
さいごまで読んでいただきありがとうございました。
本稿では MICIN における App Mesh 導入方法やカナリアリリースの運用フローについて記載しました。App Mesh 導入時には Envoy についてたくさん調べましたが、調べれば調べるほど機能が多くそして奥深いプロダクトだという印象を受けました。多少話が脱線してしまいますが、今回の導入調査時に面白いと感じたトピックがいくつかありましたので紹介します。
App Mesh 導入当初は Control Plane の役割がよく理解できなかったため、まずは Envoy 公式のサンプルを参考にしつつ Control Plane を実装し理解するところから初めてみました。
こちらのサンプルは Control Plane の実装を Go で行っています。クライアントとして動作する Envoy とそれらを中央で管理する Control Plane の関係性や、Control Plane での設定変更がどのように Envoy に反映されるかについての理解にとても役立ちました。
Proxy WASM の世界にも神秘を感じています。
キャッチアップのためひとまず Rust SDK を用いて超簡単な filter を書いてみました。ただ、現状では具体的にどういうユースケースで有用性が示せるのかというようなことはよくわかってはいません。
おそらく、App Mesh 管理下の Envoy に対して自作の filter をアタッチするとなると Envoy コンテナ内の設定ファイルを書き換える必要があり、運用を考慮すると少しリスキーであると思われます。とはいえ、技術的には非常に面白いトピックではあるため時間を見つけて挑戦していきたいとは考えています。
App Mesh 導入の調査から派生して Envoy やその周辺のプロキシの技術にとても興味を持つことができました。AWS では先日の re:Invent 2023 にて怒涛の新機能 GA がありました。GA された新機能の App Mesh 運用やカナリアリリースにおける使いどころを色々と想像しながらクリスマスを迎えたいと思います。
MICIN ではメンバーを大募集しています。
「とりあえず話を聞いてみたい」でも大歓迎ですので、お気軽にご応募ください!
-
図中に記載の Envoy ロゴは Apache 2.0 ライセンスで公開されています。 ↩︎

Discussion