先日、PharmaX様 主催のLLM Night 〜LLM Ops編〜という勉強会で、MICINにおけるデータ基盤の取り組みを紹介させていただきましたので、その記録と補遺としてのエントリです。
イベントについて
PharmaX様が月例で開催されているテックイベントです。今回はLLM Night 〜LLM Ops編〜 というタイトルで、LLM Opsの工夫などの実践的な内容についてLTを行うというコンセプトのものでした。
主催のPharmaX様が「薬剤師のチャットサジェストの評価と実験管理の本番運用」 というタイトルで、ログラス様が「ログラスの継続的なプロンプト改善のためのLLMOpsの今」というタイトルでそれぞれLTがあり、これらはすでに本番運用を開始したLLMアプリケーションの改善サイクルや実験管理に関する話でした。
MICINでも4つの事業と10以上のプロダクトを対象に、LLMアプリケーションの開発・利用を推進しようとしています。MICINは継続的なLLMアプリケーション開発および改善のサイクルをきちんと回していくための基盤としての全社データ基盤のご紹介という形でLTをいたしました。
MICINのデータ&ML基盤について
当日の発表資料はこちらで、前半をデータプロダクトマネージャーの硴﨑さんが担当し、私は後半部分で実際のデータ基盤の取り組みをご紹介しました。
前回の記事 から一歩踏み込んだ内容のご説明にもなっているかと思います。
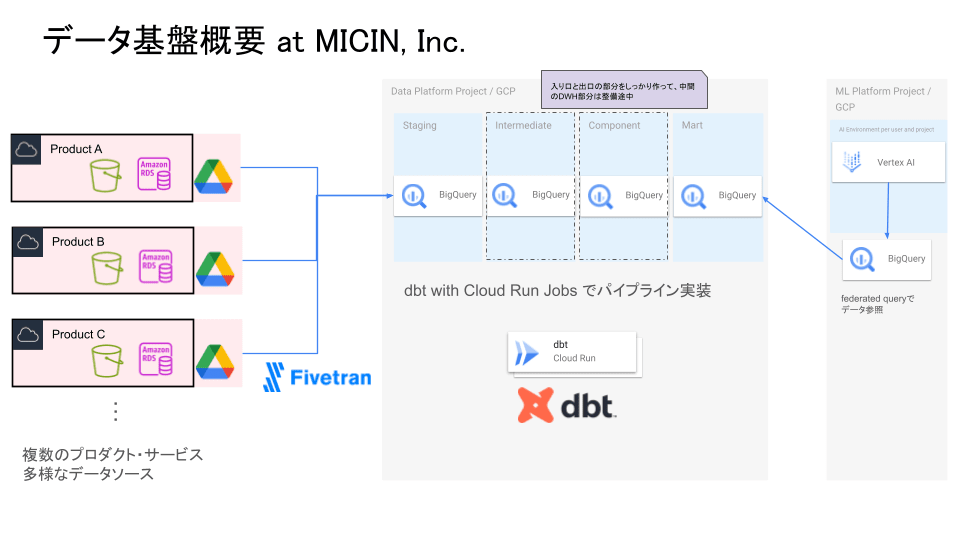
まず、MICINでのデータ基盤の概要を図に表すと上記のようになっています。
各プロダクトは大抵AWS上にあり、RDSとS3にデータがあります。その他にも、ビジネスメンバーが手元で持っているスプレッドシートのデータなど、アプリケーションが関与していない形のデータがあったりします。
社内では他社SaaSなどもありますがそれらを利用しているプロダクトに関しては組込がまだこれからということもあり、図には現れていません。
これらのデータソースをFivetranでBigQueryに集約し、dbtを利用してパイプラインを構築しています。
ML基盤はGCPの別プロジェクトという形で用意しており、案件×ユーザー(MLエンジニア)の単位でVertex AI Workbenchのインスタンスを作れるようにしています。
基盤設計・構築の際のポイント
こちら、データエンジニアリングを実践されているかたがたにとっては特に目新しい話はないのかな、とも感じておりまして、凡事徹底できちんとやりきることで事業価値に貢献するというのが横断組織としてのまずは最初の役割だと考えています。
そのなかでも、私たちのデータ&ML基盤のポイントについて、少しだけ説明させてください。
限られたリソースで成果を出すためのFivetran
今回ご紹介した中では、特にFivetranとdbtの導入が私たちのデータ基盤には欠かせないものとなっています。
これらに関する評価の記事も世の中にはたくさんありますので改めて書くのも冗長な気がするのですが、私たちにとってはどこがまず刺さったか、という観点で少しだけ触れます。
Fivetranは、
- コネクタを作成すればあとは自動でデータが同期される
- コネクタはTerraformで管理できる
- データ同期ジョブは完全にマネージドで、低遅延に行われる
といった点から、コネクタを増やす際の工数の少なさや日々のメンテナンスの必要性が限定されたものであるといったところが非常に魅力的でした。
SQL/ETLの管理はdbtで決まり
また、dbtはGitHubと組み合わせることでSQLを完全にバージョン管理できること、複雑な仕組みを導入せずともSQL同士の依存関係を表現できること、 target を切り替えることでdev環境とprod環境で同じSQLを使えること、あたりが非常に大きいです。
また、dbtの各種エコシステムは今後のデータ基盤の進化にも必要になってくるものだと考えています。
ML基盤を設計する際の考え方
MLエンジニアを護る基盤
さまざまなデータを扱うため、適切なアクセス管理を基盤側で保証してあげられるように、IAMの管理やデータセットの権限管理を行っています。
また、コストやリソースに関してもきちんとモニタリングできるようにすることで、MLエンジニアが個別に気にしなければいけないことを減らして、MLの中心的な課題に注力できる環境作りを目指しています。
MLエンジニアをチームとして強くする
これは、MLエンジニア側からも希望としてでてきたことではあるのですが、開発スタイルやプロセスを標準化し、チームとして技術力の底上げをしたいという話がありました。
そこで、先述のアクセス管理なども同時に実現する方法として、案件×ユーザーの単位でVertex AI Workbenchを建て、不要になったら壊せるというコンセプトでTerraformを整備しました。
データ(&ML)基盤のこれから
ご覧いただいてわかるとおり、まだまだやることはたくさんあるのですが、その中でも特に重点的にやっていきたいなというところを3つ挙げてみます
まずデータカタログ・メタデータの充実です。これは、データ利活用をもっと多くのメンバーの協働の場にしていきたいという想いがあります。
それから、非構造データの活用にトライしていきたいです。社内には映像や音声、画像などのデータを取り扱うプロダクトもありますが、これらは皆様ご想像の通り取扱には非常に配慮が必要です。そのあたりの調整からではあるのですが、事業的にも技術的にも非常にチャレンジングで面白いところだと思うので少しずつでも前に進めようとしています。
最後に、データオブザーバビリティやデータ品質など、データの信頼性を高めるような活動をきちんと推進していこうと考えています。
イベントに参加してみて
実際にLLMアプリケーションを開発・運用している2社様のリアルなお話を伺うことができて、現状デモや検証の範囲で回しているMICINとはまた異なった課題があるのだなと感じるとともに、ML基盤のアウトプットをデータ基盤側に取り込んで実験管理や評価など回していけるようにするというのも今後必要なことだなと改めて実感することができました。
一緒にデータ&ML基盤を育ててみませんか
ということで、積極採用中でございます。カジュアル面談からでも、私に個人的にコンタクトをいただく形でも大丈夫ですのでご興味を持っていただけた方は是非お声がけいただければと思います。

Discussion