AWSのECSってなんやねん
自己紹介
どもども、フリーランスエンジニアとして働いている井上弥風です。
ずっとバックエンドメインで仕事をしてきたのですが、インフラ側がヨワヨワ過ぎたので勉強を始めました
ECSを自分で設定して開発時に利用して~~とかまで全部できる自信がなかったので学習していきます
対戦よろしくお願いします
初めに
記事の内容
この記事は「そもそもDockerって何?」から始まり、そのあとにECSを理解していきます
ECSに関する内容だけを学びたい方は上記目次から「実際に使ってみた」まで飛んでいただけると読みやすいかと思います
記事のゴール
記事のゴールは下記です
- Dockerに対する理解をすること
- ECSに対する基礎知識を理解すること
- ECSに関わるサービス(ECRなど)の理解をすること
そもそもDockerとは何か
ECSの前にDockerってそもそも何者なんっていうのを僕が完全に理解できていなかったので、まずはDockerに関して完全に理解する
Dockerとは特定の技術や特定の処理のことを指すのではなく、Docker社が開発・提供しているコンテナ型の仮想環境を作成、配布、実行することができるソフトウェアプラットフォームです
コンテナ型とか仮想環境とかソフトウェアプラットフォームとか専門用語ばっか使いやがってって感じですが、単純に「Dockerとはアプリを素早く構築したりテストしたりデプロイして実際に使えるようにする基盤を提供してくれる野郎~~!!」っていう理解で今はOK
次に、Dockerをより明確に理解していくために下記の内容について触れていく
- Dockerfile
- Dockerイメージ
- docker-compose.yml
Dockerfile
気になる方は見てね
Dockerfileはアプリケーションの実行環境を構築するための「手順書」
つまりDockerfileはアプリが実行されるために必要な環境を作るための手順書・レシピみたいなもの

「具体的にどういった内容をDockerfileに設定するの?」という質問に対する答えが下記
- ベースとなるOSの設定(Alpine Linux, Ubuntu,Debian...)
- 利用言語のインストール(Go言語を利用してるならGo言語の)
- 依存関係のインストール
- ビルドプロセスの定義
- アプリを実行可能な状態にするために必要なコマンドの定義
- 例としてGo言語ではmain.goという「アプリを実行するためにまず呼び出す必要がある実行エンドポイント」のようなものが存在する
- main.goを実行することで各処理の初期化・環境変数のセットアップなどが行われるため、アプリを実行可能な状態にするうえで特定のファイルを実行する必要がある場合などは設定する
.
.
.
「Dockerfileを使う事のメリットっていうか~、使わないとどういうデメリットがあって利用することでどのようなメリットがあるのかが気になる~~~、何だか腑に落ちない~~~」と思ってるあなたにメリデメを説明していきます
例として、あなたはTypeScriptを利用してアプリ開発をしています
(前提としてこのプロジェクトではDockerを利用していない)
- 開発者みふたんはTypeScriptのバージョン10.1.3(バージョンは超適当)をインストールして実装し
- 開発者ネギ兄はバージョン10.1.5を利用し
- 開発者ポン酢はバージョン16.1.2を利用している
皆の目的は「素晴らしいサービスを世に出すこと」で、皆仲も良い
「これから頑張って開発していこうぜ!!」状態で最高のチームなのに、開発者みふたんがgithubにpushしたコードを他の開発者がpullして実行しようとするとめちゃくちゃにエラーが出る...といった場面を想像してほしい

ここでの問題はまず言語のバージョンの違いによる互換性の無さ
- 古いバージョンでは存在しないメソッドが最新のバージョンでは存在する
- 古いバージョンでは廃止になっていないメソッドが最新のバージョンでは廃止になっている
ここで、優秀な開発者みふたんが神の一声「Dockerを利用して開発しよう!!」と声を上げた(素晴らしい)
実際にDockerを導入したことでどういった問題が解決されたかと言うと、上記で記載した通りDockerfileには利用するOSや言語のバージョン設定、依存関係のインストールなどを定義するため、そしてそのDockerfileをみんなが共通して利用するため、バージョンの差異による問題などが生じなくなった
また、Dockerfileに記載しているTypeScriptのバージョンを上げた際も、その修正したDockerfileをpush→その修正分を開発者全員がpull→その新しいDockerfileを基に実行環境を作成することで、皆が利用している言語のバージョンが一致するため、バージョンアップなどの作業も容易に行うことができるようになった
に行える
(みふたんの一声があったからこそですねうんうん)
整理するとDockerfileを利用することで
- 開発者全員が同じ環境・同じ条件で作業をすることができる
- 利用しているOSやバージョンの変更も容易に行える
Dockerイメージ
気になる方は見てね
Dockerイメージについて調べてみると下記のような説明をよく目にする
- Dockerコンテナを立ち上げる基になるのがDockerイメージ
- DockerイメージはDockerコンテナのひな型コード
- DockerイメージはDockerコンテナのテンプレート...

僕はDockerについて学習し始めたばかりの頃、下記のような疑問を持っていた
- Dockerfileがコンテナの元になるんじゃないの?
- Dockerイメージがコンテナの基になるならDockerfile作らないで最初からDockerイメージ作ればいいじゃん
.
.
.
その辺りの疑問も解消しつつDockerイメージについて説明していく
Dockerイメージとは、Dockerfileに記述された手順に従ってビルドされた、アプリケーションとその実行環境をパッケージとしてまとめたもの
つまり、Dockerイメージは開発者が実際に実装しているソースコード + コードを動作させるための実行環境(この場合は主にDockerfile)を一つのパッケージとしてまとめたものといったイメージ

Dockerイメージの中身って具体的に何なのかと言うと
- バイナリファイル
- Javaだったらjarファイル、Go言語だったら実行可能バイナリなど
- アプリが必要とするライブラリや依存関係
- 実行環境
- OSやミドルウェア、ランタイムなど
- 設定ファイル
- 環境変数など...
つまり、Dockerfile + アプリのソースコードとか色々を合体させたのがDockerイメージって理解でok
詳細は後で後述するが、このDockerイメージを基にDockerコンテナが作成される
docker-compose.yml
気になる方は見てね
出ましたdocker-compose.yml。
DockerfileだったりDockerイメージだったりこれだったり種類多すぎだろと思ってたんですがこれも超簡単なので説明していく
後述するDockerコンテナはDockerイメージを基に作成・起動する
.
.
.
例えば特定のDockerイメージで一つのコンテナを起動させたい場合、下記コマンドで起動させることができる
docker run -d -p 8080:80 myapp
アプリケーションのコンテナを作成するのと同時に、DBのコンテナも作成する場合、下記コマンドで起動させる
docker run -d --name database postgres
docker run -d --name myapp --link database:db -p 8080:80 myapp
アプリケーションとDBとその他いくつかのコンテナを起動させる場合、下記コマンドで起動させる
docker run -d --name database postgres
docker run -d --name myapp --link database:db -p 8080:80 myapp
docker run -d --name ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
docker run -d --name ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
docker run -d --name ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
というように、純粋に「毎回コマンド打つのめっちゃめんどくさくね?」を解消してくれるのがdocker-compose.ymlって訳
具体的にはdocker-compose.ymlに起動させたいコンテナの定義やコンテナ同士の依存関係、Portの紐づきなどを設定しておくことで、下記コマンドを実行するだけですべてのコンテナを一斉に起動させることができる
docker-compose up
つまり、docker-compose.ymlは各コンテナの実行を一元化でき、またコンテナ間の管理などもできちゃうファイルって感じ!
Dockerの詳細あれこれ
ここからはDockerの内部構成に関して軽く説明していく
- Dockerエンジン
- Dockerクライアント
- Dockerデーモン
- コンテナレジストリ
- 仮想化
- Dockerコンテナ
Dockerエンジン(DockerクライアントとDockerデーモン)
気になる方は見てね
Dockerエンジンって具体的に何だろうと思って調べてみた
「Dockerエンジンとは主にDockerクライアント(CLI)とDockerデーモン(サーバー)の2つからなるクライアント・サーバー型のアプリ...」
.
.
.
はい????って感じになったので整理する
まず登場するのが
- Dockerクライアント(CLI)
- Dockerデーモン(サーバー)
Dockerクライアントは何をするのか、Dockerデーモンは何をするのかっていうところなんだけど、理解してみたらめっちゃ簡単だった

まず、下記はDockerコマンドの一例
例
docker run -d -p 8080:80 myapp
docker-compose up
任意のDockerコマンドを入力すると、まずDockerクライアントがそのコマンドを内部APIを通じてDockerデーモンに送信する
その後、Dockerデーモンは受け取ったコマンドに基づき、実際にコンテナの起動、削除、またはDockerfileのビルドなどの操作を行う流れ

このプロセスは一般的なWeb開発におけるクライアントとサーバーの関係に似ており、クライアントが特定の操作を要求し、サーバーがそれに応じて処理を実行するのとほぼほぼ一緒
ただ、DockerクライアントとDockerデーモン間の通信は主にローカルマシン内で行われ、Unixソケット(LinuxやmacOS)や名前付きパイプ(Windows)を介して直接的に行われることが一般的
コンテナレジストリ
気になる方は見てね
Dockerイメージを作成した場合、作成したイメージを保存、共有、配布したりできるのがコンテナレジストリ
githubのコンテナ版みたいなイメージでok
(コンテナレジストリにはmysqlだったり様々な言語のイメージだったりがたくさん存在する)
一番の謎、「仮想化」
気になる方は見てね
- 仮想化とは、ソフトウェアによって複数のハードウェアを統合し、自由なスペックでハードウェアを再現する技術
- 仮想化とはハードウエアを抽象化し、リソースを効率よく利用できるようにするための技術
- 仮想化とは、サーバー、ストレージ、ネットワーク、クライアントPCなどのハードウェアリソースを、ソフトウェアを用いて統合・分割する技術
。。。。
1mmも意味が分からないので深堀りしていく

まず仮想化を理解するには前提として下記を理解する必要がある
- ハードウェア
- ホストOS
- ハードウェアリソース
- ハイパーバイザー
ハードウェア
まずハードウェアっていうのが何なのかと言うと、超絶簡単で「現実世界に物理的に存在する機器」のこと
皆がよく使っているTwitter(X)だったりLineだったりzennも存在はしているけど、これらは触れられるものではなくインターネット上に存在しているもので、「現実世界に物理的に存在しているかどうか」でいうと存在していない
まあ現実世界とか物理的とか出てきたけど、超簡単で下記の整理でok
- ハードウェア
- 触れる
- CPUとか
- メモリとか
- HDD・SSDとか
- 触れる
- ソフトウェア
- 触れない
- Twitter(X)
- Line
- zenn
- ソフトウェアは無数にあるね
- 触れない
ハードウェアとソフトウェアの区別は大きく分けるとこれだけ
CPU、メモリ、HDD・SSDが具体的に何かとかまでは説明しないけど、とりあえずPCの中に物理的に存在していてPCを動かすために必要な部品っていう事だけ覚えてもらえればok!!
ホストOS
フロント・バックエンド開発を主にやってきたワイからするとCPUとかメモリとかOSとか分からなさすぎるんだけど、超絶簡単だった
まずOS(Operating System:オペレーティングシステム)は、ハードウェアとソフトウェア(アプリなど)のやり取りを仲介してくれる奴
上記で記載した通り、ハードウェアは物理的な機器でソフトウェアはアプリとか
そして物理的な機器とソフトウェアの仲介役として存在するのがOS

例を書いてみる
- アプリが動作する
- CPU(色々計算したり処理してくれる機器)に処理してほしいけど、アプリは恥ずかしがり屋さんだから直接CPUに声をかけられない
- OSがアプリの気持ちを汲み取って代わりにCPU(CPUを含むハードウェアたち)に声をかけてくれる
- アプリの思いがハードウェアに伝わる
↑こんな関係性
「OSとは何か」を深掘りすぎるととんでもなく沼なんだけど、当記事ではこの関係性だけ理解してくれればok
そして、ホストOSとは物理マシン上で直接実行されるOSのことを指す
→「直接実行されないOSがそもそもあるの..??」っていう疑問はこれから解説していく
ハイパーバイザー
「ハイパーバイザーとは仮想マシンを作成・管理するためのソフトウェア」なんだけど、仮想化の説明と一緒に説明したほうが分かりやすいので詳細は後述する
色々調べてみて、結局仮想化とは
「仮想化とは1台のコンピューターで、複数のコンピューターを仮想的に存在しているように振舞う技術...」
.
.
.
何を言ってんだって感じなので例を挙げて分かりやすく記載してみる
- 私は現在WindowsのPCを使っている(WindowsOS)
- けどできればMacのPCも欲しい(MacOS)
- そこでお財布さんに「新しいPC買っていい?」と聞いてみたところ、思いっきり右ストレートで殴られた
- どうやら買えない..けど欲しい...
- そこで、私はWindowsOSで動いているPCの中にMacOSを突っ込んじゃうことにした
- 私のPC自体はWindowsOSなんだけど、WindowsOS上に上手ーくMacOSを突っ込むことに成功した

この「上手ーく突っ込む作業」が仮想化そのものと言える
実際には仮想化は新しいPCを買うお金がない時のためだけに利用する技術ではないんだけど、例としてはこんな感じ(というかWindows上でMacOSを動かすことは実際にはライセンス上の制限で難しいかもだけどとりあえず無視)
ここからはより具体的にしていく
仮想化の具体的な特徴や構成要素
- 仮想マシン(VM)
- 仮想化によって作成された、物理マシン上で動作する独立したコンピュータのこと
- それぞれのVMは、専用のOS、アプリケーション、およびその他のリソースを持っている
- 上記の例で言うとWindowsにぶっこんだMacOSがVMに該当するね
- 物理マシン
- 実際に物理的に存在し、仮想マシンをホストするために使用されるコンピュータ
- 上記の例で言うとワイが実際に利用しているWindowsのPCが物理マシンに該当するね
- リソース分離
- 各仮想マシンは独立していて、他のVMや物理マシンの操作から隔離されている。これにより、一つのVMで問題が発生しても他のVMには影響しない
- 上記の例で言うとワイのWindowsとぶっこんだMacOSはそれぞれが独立している、つまり、MacOSで何かしらのエラーが起きてもWindows側には何ら影響を与えない
- 各仮想マシンは独自のOS(WindowsOS,MacOS,Linux,ubuntu...)を持つことができ、他の仮想マシンと干渉することなく独立して動作する
- つまり物理マシンのOSに制限されず、各仮想マシンは使いたいOSを利用することができちゃう(これ強い)
- ハードウェア利用の最適化
- 物理マシンのリソース(CPU、メモリ、ストレージ)を複数のVMで共有し、利用率を向上させることができる
- 逆に言うと仮想マシンが複数存在していたとしても各仮想マシンが依存するリソース元は物理マシンのリソースでしかない(CPU、メモリ、ストレージ)
- つまりスペックが低かったりするとそれだけ全体の処理も遅くなる
- 逆に言うと仮想マシンが複数存在していたとしても各仮想マシンが依存するリソース元は物理マシンのリソースでしかない(CPU、メモリ、ストレージ)
- 物理マシンのリソース(CPU、メモリ、ストレージ)を複数のVMで共有し、利用率を向上させることができる
「3つの仮想マシンが動作していたとして、1つの仮想マシンが物理マシンのリソースを全て専有してしまう事とかあるの?そしたら他の仮想マシンは動かなくなる?」という疑問が生まれたんだが、この疑問を解決してくれるのが「ハイパーバイザー」だった!!!なんと!!
まず先ほどの内容の整理として、物理マシンのリソース(CPUやメモリなど)は有限
そのうえで、ハイパーバイザーはこれらの有限なリソースを複数の仮想マシンに「公平に分配」してくれる
ここで面白いのが、ハイパーバイザーによる物理マシンのリソースの割り当ては、仮想マシンがそれを必要としているときに、必要な分だけ割り当てる
つまり、10リットルの水を求めている人が10人いたとしたら、全員に1リットルずつ分配するのではなく、各々がのどの乾いたタイミングで必要な分だけを渡してあげるイメージ
そうすることでリソースを割り当ててはいるけど利用していないため無駄にリソースを食うことなどもなくなるため効率的
結果としてハイパーバイザーがリソースを「専有してしまい、他から利用できなくする」という疑問は、ある程度正確ではあるものの、その過程は非常に動的である
ハイパーバイザーは、各VMの現在のニーズに基づいて、リソースを動的に再割り当てするため、一つのVMが多くのリソースを使用していない場合、それらのリソースは必要としている他のVMに割り当てることができる
ハイパーバイザーの種類によって仮想化にも違いがある
ハイパーバイザーには種類があり、種類によって仮想化の仕組みも変わってくる
ハイパーバイザーの種類は大きく分けて下記の二つ
- タイプ1ハイパーバイザ(ベアメタル型)
- タイプ2ハイパーバイザ(ホスト型)
タイプ1ハイパーバイザ(ベアメタル型)
タイプ1ハイパーバイザーの特徴・メリット・デメリットなどを下記に記載したが、簡略化すると「ホストOSが不要 & 物理ハードウェア上で直接稼働する & オーバーヘッドが少ない」というのが大きな特徴
- 特徴
- 物理ハードウェア上に直接インストールされる
- ホストOSが不要で、ハイパーバイザ自体がOSの役割を担い、仮想マシン(VM)の管理とリソースの割り当てを直接行う
- ホストOSが不要というのは、逆に言うとホストOSがない状態からハイパーバイザーを導入していく必要があるのでそれなりの知識が必要ともいえる
- 高性能とセキュリティが要求される企業環境やデータセンターでよく使用される
- メリット
- 高性能: OSを介さない直接的なハードウェアアクセスにより、オーバーヘッドが少なく、パフォーマンスが高い
- ホストOSを返してハードウェアにアクセスしないのでその分早いよねって感じ
- 高いセキュリティ: より少ないソフトウェア層が存在するため、攻撃面が小さい
- 信頼性と安定性: 少ないオーバーヘッドと直接的なハードウェアコントロールにより、システムが安定して稼働する
- 高性能: OSを介さない直接的なハードウェアアクセスにより、オーバーヘッドが少なく、パフォーマンスが高い
- デメリット
- 設定の複雑さ: ベアメタルハイパーバイザの設定と管理は、ホスト型に比べて複雑な場合がある
- ハイパーバイザーのインストールがそもそも大変そう
- コスト: 専用のハードウェアが必要であり、一部の商用ハイパーバイザはライセンス料が発生する
- 設定の複雑さ: ベアメタルハイパーバイザの設定と管理は、ホスト型に比べて複雑な場合がある
タイプ2ハイパーバイザ(ホスト型)
タイプ2ハイパーバイザーの特徴・メリット・デメリットなども下記に記載したが、簡略化すると「ホストOS上で動作する & ホストOSを介してハードウェアへアクセスする & オーバーヘッドが大きい & セットアップが簡単」というのが大きな特徴
- 特徴
- 既存のオペレーティングシステム(ホストOS)上にインストールされる
- ハイパーバイザはホストOSのアプリケーションの一つとして動作し、そのOSを通じてハードウェアリソースにアクセスする
- 個人使用や開発、テスト用途に適している
- メリット
- 簡単なセットアップと管理: 既存のOS上にインストールするだけでよく、使用するのが容易
- 柔軟性: 異なるOSのVMを簡単に設定し、同一のハードウェア上で複数の異なる環境を同時に実行できる
- コスト効率: 専用のハードウェアを購入する必要がなく、多くのタイプ2ハイパーバイザは無料または比較的低コストで利用可能
- デメリット
- 低下したパフォーマンス: ハードウェアリソースへのアクセスがホストOSを経由するため、タイプ1に比べてオーバーヘッドが大きくなりがち
- セキュリティリスクの増加: ホストOS上で動作するため、ホストOSの脆弱性がハイパーバイザに影響を与える可能性がある
そもそも仮想化って何のためにやるの?
超寄り道して仮想化を深堀してみたけど、「そもそも仮想化って何のためにやるの?意味あるの?」という部分を最後に見てみる
仮想化には下記のようなメリットや目的が存在する
- リソースの効率的な利用
- コスト削減
- 柔軟性とスケーラビリティの向上
- 災害復旧とビジネス継続性の向上
- データセンターの管理と自動化の簡素化
- アプリケーションの分離とセキュリティの向上
- テスト環境と開発環境の向上
全ては説明しないが、概要だけ説明していく
仮想化技術が普及する前は「1つのハードウェア = 1つのソフトウェア」という構成が基本だったのに対して、仮想化技術が普及してからは「1つのハードウェア = 複数のソフトウェア」という構成が可能になった
これは1つのハードウェアを効率的に使用することができ、未使用のリソースを有効的に使用することができるためメリットが大きい
(合わせてハードウェア機器のコスト削減も期待できるのは強い)
また、ソフトウェアの数だけハードウェアを管理する必要がなくなるため機器の管理・運用が従来に比べて楽になるなど、メリットが多い
上記では上げきれない様々なメリットが存在するため、仮想化は利用され、また利用する目的となる
ちなみにワイが面白いなと思ったのは、仮想化技術は現在のAWSやAzureの基盤だという事
僕も含めAWSやAzureを利用するユーザーは数えきれないほどいると思うが、利用用途に応じて、つまり一つのソフトウェアを稼働させるためにAWSやAzureが一つのハードウェアを毎回用意しているかと言うとそういうわけではない
つまり、AWSやAzureはハードウェアを仮想化によって複数の用途で利用できるようにしており、物理マシンの上に構築した仮想環境を我々に提供している
つまりAWSやAzureには様々なサービスが存在するが、それら根底にあるのは「仮想化技術」であり、当記事を書く上で仮想化技術がどれだけ便利かつすごいものなのかを学べたのは良かった
「仮想化技術」がもし普及していなかったとしたらAWSやAzure、その他クラウドサービスなども今ほど普及していなかったかも??
色々寄り道したけどDockerコンテナとは何なのか
気になる方は見てね
Dockerコンテナを理解する前に下記について調べていく
- プロセスとは?
- プロセスの隔離とは?
- 仮想化とコンテナ仮想化の違いとは?
前提①: プロセスとは?
OSに関わる「プロセス」とは一言で言うと「実行中のプログラム」を指す
「実行中のプログラムとは何か」というと、CPUがプログラムの命令を読み込んで実行する際、その実するプログラムそのものをプロセスと呼ぶ(プロセスはOSによって管理される)
補足として、プロセスはあくまで「実行中のプログラム」を指す
つまりプログラムが実際にメモリ上で実行されている状態をプロセスと呼ぶ
まだ実行されていない、つまりメモリに読み込まれてCPUによって処理されていないプログラムは、プロセスとは呼ばない
プログラムがディスク上のファイルとして存在しているだけの状態では、それは「実行ファイル」や「プログラムファイル」と呼ばれる

プロセスにはプログラムのコードを実行するために必要なリソース(CPU時間、メモリ空間、ファイルハンドルなど)がOSによって割り当てられ、OSはプロセス間でこれらのリソースを効率的に共有し、プロセスが他のプロセスと干渉しないように管理する
下記は具体的な「プロセス」の例
-
LINEを利用している場合
- LINEアプリが開かれ、メッセージの送受信やビデオ通話などを行っている状態がプロセス
- このプロセスでは、メッセージを管理する機能、通知を管理する機能など、複数のタスクを同時に行っている
-
YouTubeを視聴している場合
- ブラウザが開かれ、YouTubeのウェブサイトにアクセスしてビデオを視聴している状態もプロセス
- この場合、ブラウザ自体が一つの大きなプロセスであり、ブラウザ内で動作している各タブや拡張機能も独自のプロセスやスレッドとして管理されることがある
-
Twitterを利用している場合
- スマホやPCでTwitterアプリまたはウェブサイトを使用している状態
- アプリが開かれ、タイムラインの読み込みやツイートの投稿などを行っている状態がプロセスに該当する
// TODO: OSのプロセスを深掘りしようとすると当記事の本質から逸れ過ぎるのでまた今度
前提②: プロセスの隔離とは?
いくつかの記事を読んでみたけど、プロセスの隔離とは「異なるプロセスが互いに干渉しないように、それぞれのプロセスを独立した環境で実行すること」みたいな説明がされていた
具体的に理解していくと、「プロセスを隔離する」というのは特定のプロセスがシステムの一部分だけを参照できるようにする技術
例を挙げると「株式会社みふたんズ」に出入りできるのはみふたんズの従業員のみであり、そのほかの人は出入りできない
当然ながら株式会社みふたんズの事務所にある事務所類(リソースなど)も外部からは見ることができず、「株式会社みふたんズ(プロセス)は外部から隔離されている」と言える

実際にどのようにプロセスを隔離、つまり特定のプロセスがシステムの一部分だけを参照できるようにするかと言うと、「名前空間」というのがそれを実現する
名前空間はプロセスがアクセスできるリソースの範囲を限定する
つまり名前空間を利用するとプロセスは自分自身の名前空間内で定義されたリソースのみを参照・操作できるようになるため、他のプロセスや名前空間のリソースへのアクセスが制限される
※隔離されたプロセスから他のプロセスへのアクセスはできず、その逆もまた然り
が、、、、そもそもなぜプロセスを隔離するのか、隔離しないとどういったデメリットがあり隔離することでメリットがあるのかが気になって次に進めないのでボリボリ深掘りする
なぜ隔離するのか
「隔離する理由 = 隔離しないと生じる問題」には下記のようなものが存在した
- セキュリティの強化
- システムの安定性の確保
セキュリティの強化
プロセスを隔離した場合、隔離したプロセスは他のプロセスと独立した環境で実行されるため、他のプロセスへの影響を及ぼさない、また他のプロセスからの影響を受けにくい
プロセスを隔離しない場合、悪意のあるプロセスが他のプロセスのリソースにアクセスし、データを盗んだり、システムに損害を与える可能性が存在する
※「悪意のあるプロセス」とは、悪意あるウェブサイトへのアクセスや、信頼できないソースからのプログラムのダウンロードによって、侵入(実行)されてしまうプロセスのこと
システムの安定性の確保
例としてLINEを動作させるために実行されている一つのプロセスが過剰にリソースを消費している場合、他のプロセスが正常に稼働するためのリソースが不足してしまうため、システム全体が不安定な動作になってしまう可能性がある
しかしプロセスを隔離することによりリソースの適切な分配と制御を行うことができ、システムの安定性が向上する
※具体的には隔離をすることにより安定性が向上するのではなく、隔離をする際に利用する技術の一つであるコントロールグループ (cgroups)を使用することにより、各プロセスグループに割り当てられるリソースの上限を利用でき、一つのプロセスがリソースを独占してしまうことを防いでくれる
※コントロールグループ(cgroups)はプロセスの隔離とは別概念のためコントロールグループ(cgroups)単体でもリソース制御は可能みたい(ただ、コントロールグループ(cgroups)とプロセスの隔離がセットで利用されることも一般的みたい)
MEMO
プロセスを隔離するための手段として名前空間を利用し、隔離したプロセスに均等にリソースが分配されるようにコントロールグループ(cgroups)などが利用される
結論: Dockerコンテナとは?
Dockerコンテナとは他のプロセスから隔離されたプロセス
コンテナが実行されるとき、まずコンテナ専用の名前空間が作成される
コンテナ専用の名前空間が作成されるのに伴いコンテナ専用のファイルシステムなどをも作成されるため、そのコンテナは外部から参照・アクセスされず、隔離されたプロセスと呼べる
つまり隔離されたプロセスとは名前空間やコントロールグループ(cgroups)を利用して実現し、コンテナとはそれらを利用して作成した隔離されたプロセスそのもの
コンテナが外部に影響を及ぼすこともなく、外部がコンテナに影響を及ぼすこともない

また開発時にコンテナを利用して誤ってプロセスから参照できるファイルシステムを削除してしまった場合も、そのファイルシステムは名前空間内のファイルシステムにとどまるため、外部に影響を及ぼさない
結論、Dockerコンテナとは隔離されたプロセス
ただ、単に隔離されたプロセスとDockerコンテナには大きな違いがある
もちろんDockerコンテナも隔離されたプロセスであることに違いはないのだが、Dockerコンテナはそのプロセスが実行されるための完全な実行環境も提供する
「実行環境」には、
- アプリケーションのコード
- ランタイム
- ライブラリ
- 環境変数...
など、そのアプリケーションが正しく実行されるために必要な全てが含まれている
これにより、コンテナはアプリケーションとその依存関係を隔離された環境内でパッケージ化し、一貫した方法で実行することを可能にする
つまりDockerコンテナは隔離されたプロセスでありながら、アプリケーションを実行する環境をパッケージ化し、一貫した方法で実行させることができる優れもの
仮想化とコンテナ仮想化は違う?
仮想化(VM)はハイパーバイザーを利用してハードウェアの上で直接稼働する(ホストOS上では稼働しない)
そのため各仮想マシンには専用のゲストOSやアプリケーション、ライブラリが必要とされるため、リソース消費量が大きくなる
それに対してコンテナ仮想化はホストOS上で稼働するため、リソースを共有することでリソース消費量を抑えることができる
- ハイパーバイザーを利用した仮想化
- ハードウェアレベルの仮想化
- ハイパーバイザーは物理ハードウェアから一歩離れたレイヤーに位置し、複数の仮想マシン(VM)を実行する。各VMには独自のOS、アプリケーション、必要なライブラリが含まれる
- リソースの重複
- 仮想マシンは、それぞれが完全なゲストOSを持っているため、リソース消費が比較的大きくなる。つまりCPU、メモリ、ストレージなどの物理的リソースを効率的に使用することに制約があることを意味している
- 強い隔離性
- 仮想マシンはハードウェアレベルで互いに完全に隔離されているため、セキュリティと安定性が高まる一方、この強い隔離性は追加のオーバーヘッドをもたらす
- ハードウェアレベルの仮想化
- コンテナ仮想化
- OSレベルの仮想化
- コンテナは、ホストOSのカーネルを共有しながら、それぞれが独立したユーザー空間を持つ。これにより、コンテナは軽量であり、起動が速く、少ないリソースで多くのコンテナを実行できる
- リソースの共有と効率
- コンテナはホストOSのカーネルと一部のライブラリやバイナリを共有するため、リソース消費が少なく、効率的
- 隔離性とセキュリティ
- コンテナはプロセスレベルで隔離されているため、仮想マシンほどの強い隔離性はない。
- OSレベルの仮想化
実際に使ってみた
ECRの設定
前提知識: ECRとは?
ECRとは?
ECRとはDockerコンテナのイメージを保存するためのサービス
ECRはDockerfileやdocker-compose.ymlではなく、ビルドされたDockerイメージを保存する
ECRの構成要素
ECRには下記の要素が存在する
- レジストリ
- 認証トークン
- リポジトリ
- イメージ
レジストリ
AWSアカウントごとに用意されており、レジストリの中にリポジトリを作成する
認証トークン
Dockerイメージをpush・pullする際に利用できる認証機能
リポジトリ
実際にDockerイメージを保存する場所
例として、
- Dockerイメージは商品そのもの
- レジストリは倉庫
- 認証トークンは商品棚に置く作業員がスパイじゃないかを監視する監視員
- リポジトリは商品を実際に配置する商品棚
ECSとの関係性
ECSはコンテナを実行、管理するサービス
それに対してECRはコンテナのDockerイメージを保存するサービス
ECSでコンテナを起動する際、ECRに保存しているDockerイメージを指定して使用することができるため、アプリケーションにはDockerfileを設定しなくてもコンテナを起動することができる
※ただ、開発時はローカルでコンテナを起動させたかったりするのでよくルートディレクトリ配下とかにDockerfile置いてるよねー
ECR以外に利用できるサービスは無いの?
調べてみたところ、ECR以外にも
Docker Hub
Google Container Registry
Azure Container Registry
などからもイメージを取得してECSで実行することが可能みたい
(ECSで動かすなら同じAWSサービスのECRを利用するって選択肢が割と多そう?ね)
リポジトリ作成
まずECRのリポジトリを作成する
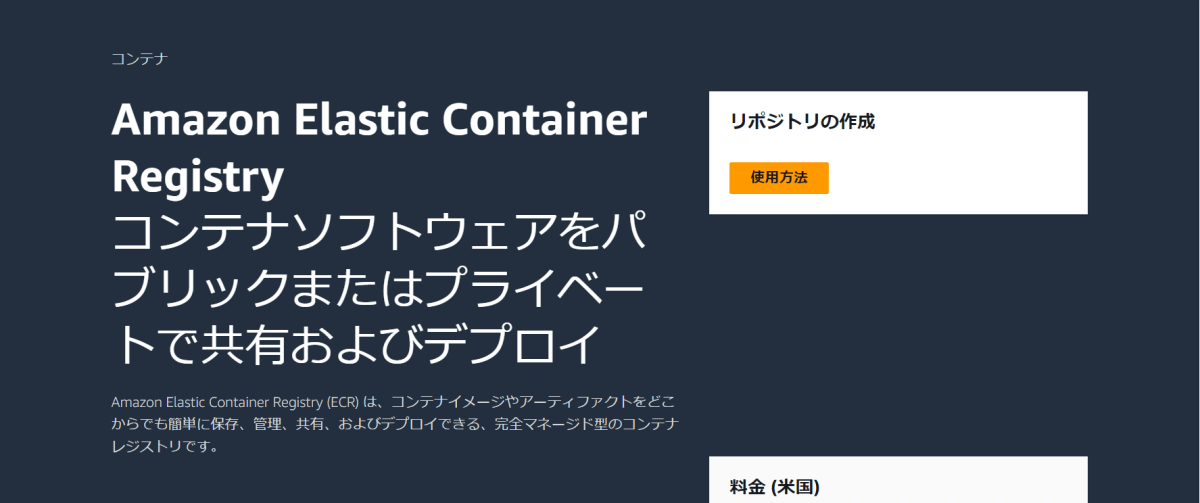
- 下記項目を設定
- 可視性設定
- プライベート
- リポジトリ名
- test-go-ecr
- タグのイミュータビリティ
- 有効
- よく分からんが面白そうなので有効にしたった
- 有効
- 可視性設定
設定項目詳細
- 可視性設定
- プライベートの場合、Dockerイメージのpushやpullには認証が必要
- パブリックの場合、Dockerイメージのpushやpullには認証が不要なため、誰でもアクセス可能
- 主にDockerイメージの配布などに使われる
- リポジトリ名
- リポジトリ名はレジストリ内で一意
- タグ
- 有効にするとDockerイメージのバージョンや状態を識別することができる
- バージョニング
- イメージにバージョン番号(例:1.0、1.1、2.0など)をタグとして付けることで、バージョン管理を行うことができる
- この方法を用いるとイメージを明確に識別できる
- 状態の特定
- latest、stable、developmentなどのタグを使って、イメージの状態や開発段階を示すことができる
- バージョニング
- 有効にするとDockerイメージのバージョンや状態を識別することができる

- 下記項目を設定
- イメージスキャン
- 有効
- 暗号化設定
- 有効
- イメージスキャン
設定項目詳細
- イメージスキャン
- 有効にするとDockerイメージがpushされたタイミングでDockerイメージが自動的にスキャンされ、問題がないかチェックされる
- 有効にすることでセキュリティ脆弱性などがある場合に検出することができる
- 有効にすることでスキャンによるビルド時間の延長など運用上の制約は発生してしまうが、セキュリティの重要性を考えると有効にすることが推奨されるみたい
- 暗号化設定
- KMS暗号化も有効にするのが推奨されているらしい
- 有効にすることでリポジトリに保存されているDockerイメージが暗号化されて保存されるため、セキュリティ強化につながる

「○○はプライベートレジストリに正常に作成されました」と表示されていれば作成完了
Dockerイメージをpushしてみる
作成したリポジトリを選択して「プッシュコマンドを表示」を選択するとpushするまでの手順が記載されている(親切)
ワイのPCがWindowsのためWindowsを利用したpushの流れを記載する(が、基本的にはmacOS/Linuxも表示された手順に沿って進めればOK)
認証トークンの取得とレジストリに対するDockerクライアントの認証
(Get-ECRLoginCommand).Password | docker login --username AWS --password-stdin 1111111111.dkr.ecr.ap-northeast-1.amazonaws.com
(Get-ECRLoginCommand).Passwordを実行するとECRへログインするためのパスワード(認証トークン)を取得する
|の右側は取得した認証トークンを利用し、レジストリに対してDockerクライアントを認証する
(--username AWSのAWS部分はECRにログインする際に使用する特定のユーザー名であり、変更する必要はない。一律AWSが使用される)
AWS CLIインストールしてなかったのでインストールした & 個人メモ
AWS CLIインストールしてなかった
新しいPCにAWS CLIをインストールしてなかったのでインストールしました
インストールされているか気になる方は下記コマンドでチェック(windowsの場合、他も一緒かもだけど)
aws --version
下記サイトで紹介されているようにアクセスキー・シークレットキーなどを取得後、下記コマンドを実行することでAWS CLIの初期設定は完了
(CLIインストール後にvscodeとか使ってる方はvscodeの再起動しないとコマンド使えないかも)
設定
$ aws configure
AWS Access Key ID [None]:アクセスキーIDを入力
AWS Secret Access Key [None]:シークレットアクセスキーを入力
Default region name [None]:ap-northeast-1 // 東京リージョンであれば
Default output format [None]:"JSON"
設定確認
aws configure list
Name Value Type Location
---- ----- ---- --------
profile <not set> None None
access_key ****************aaaa shared-credentials-file
secret_key ****************aaaa shared-credentials-file
region ap-northeast-1 config-file ~/.aws/config
ちなみに設定した情報はローカルの~/.aws/configに格納されている
DockerクライアントがECRとやり取りをするの?
ECRへpush or pullするとDockerクライアントがECRとやり取りをするのか気になったんだが、ECRへpushやpullを行う際はDockerクライアントがDockerデーモンに命令を出し、Dockerデーモンがその命令を実際に実行する
つまりDockerデーモンがリモートのECRサーバーと通信してイメージのアップロードやダウンロードを行うので、流れとしては下記
ワイがコマンド入力(例えばDockerイメージのpush)
↓
Dockerクライアントがコマンドを受け付けDockerデーモンに渡す
↓
DockerデーモンがECRサーバーと通信してDockerイメージをpushする
(Get-ECRLoginCommand).Password~~~でエラー出んぞオイィィィィィィィイ
Windowsで (Get-ECRLoginCommand).Password~~~を実行しようとしたら~~~~~~+ FullyQualifiedErrorId : CommandNotFoundExceptionっていうエラーが出た
管理者権限でPowerShellを開き下記コマンドを実行、vscode再起動(vscodeでコマンド入力している場合)で行けた
$ Install-Module -Name AWS.Tools.Installer
$ Install-AWSToolsModule AWS.Tools.ECR -CleanUp
vscode再起動
$ (Get-ECRLoginCommand).Password~~~
Dockerfileのビルド
下記コマンドでDockerfileをビルド
docker build -t test-go-ecr .
-tはタグ名を指定する際に利用するが、上記の場合リポジトリ名がtest-go-ecr、タグ名はデフォルトでlatestとなる
任意のタグ(latest、development、productionや1.0.0、1.0.1など)を指定したい場合は下記のように指定する
docker build -t test-go-ecr:[任意のタグ名] .
Dockerイメージの確認
タグ名を明示的に指定しない場合
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
test-go-ecr latest 27e15c0e0960 About a minute ago 234MB
タグ名を明示的に指定した場合
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
test-go-ecr 1.0.0 27e15c0e0960 About an hour ago 234MB
すげええええええ、ちゃんとできてるゥうううう
ワイのDockerfileとmain.goはこれだよ
Dockerfile
FROM Go言語:1.21.1-alpine
WORKDIR /go/src/app
RUN apk update && apk add git
COPY main.go .
COPY go.mod .
RUN go mod tidy
CMD go run main.go
main.go
package main
import "fmt"
func main() {
fmt.Println("これ実行してログとか出力されたら成功ってことだよね?さらに成長しちゃうってことだよね??まじいいい??")
}
イメージへタグ付け
docker tag test-go-ecr:1.0.0 1111111111.dkr.ecr.ap-northeast-1.amazonaws.com/test-go-ecr:1.0.0
pushするイメージにタグを付与(今回は1.0.0)
docker tagコマンドの詳細が下記
docker tag [元のイメージ名]:[元のタグ名] [新しいイメージ名]:[新しいタグ名]
このコマンドを実行すると、ローカルで作成したDockerイメージに新しいタグ(リモートレジストリのアドレスを含む)を追加することができ、同一のイメージが異なるタグで参照されるようになる(新しくイメージが作成されるのではなく元のイメージに対する参照が作成される)
基のDockerイメージはそのまま保持され、新たにタグ付けされたイメージが追加されるわけではなく、元のイメージに新しいタグが追加される形
またDockerイメージにリモートレジストリのアドレスを含めるタグを付けることで、Dockerはどのレジストリにそのイメージをプッシュすべきかを明確に理解できる
基のDockerイメージからpush用のDockerイメージを作成した結果
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
1111111111.dkr.ecr.ap-northeast-1.amazonaws.com/test-go-ecr 1.0.0 27e15c0e0960 About an hour ago 234MB
test-go-ecr 1.0.0 27e15c0e0960 About an hour ago 234MB
タグのイミュータビリティを有効にした場合の豆知識マメマメ
タグのイミュータビリティ(不変性)を有効にしたECRリポジトリの場合、同一のタグを持つ新しいイメージのプッシュは拒否される
つまり一度プッシュされたタグ名(例えば、1.0.0)が再利用されることを防ぎ、イメージのバージョンが一意であることが保証されるため、不変性を保証したい場合は新しいバージョンのイメージには新しいタグを使用する必要がある
(タグのイミュータビリティを無効にしていると同じタグでpushすると元のDockerイメージが上書きされてしまう)
イメージをpush
docker push 1111111111.dkr.ecr.ap-northeast-1.amazonaws.com/test-go-ecr:1.0.0
docker push コマンドを使用する際は[リポジトリ名]:[タグ名] の形式で、プッシュしたいイメージを指定する
このコマンドは指定されたタグを持つローカルのDockerイメージを、リモートのDockerレジストリ(この例ではAmazon ECR)にプッシュする
イメージスキャンを有効にしたので脆弱性チェックとかされてる?
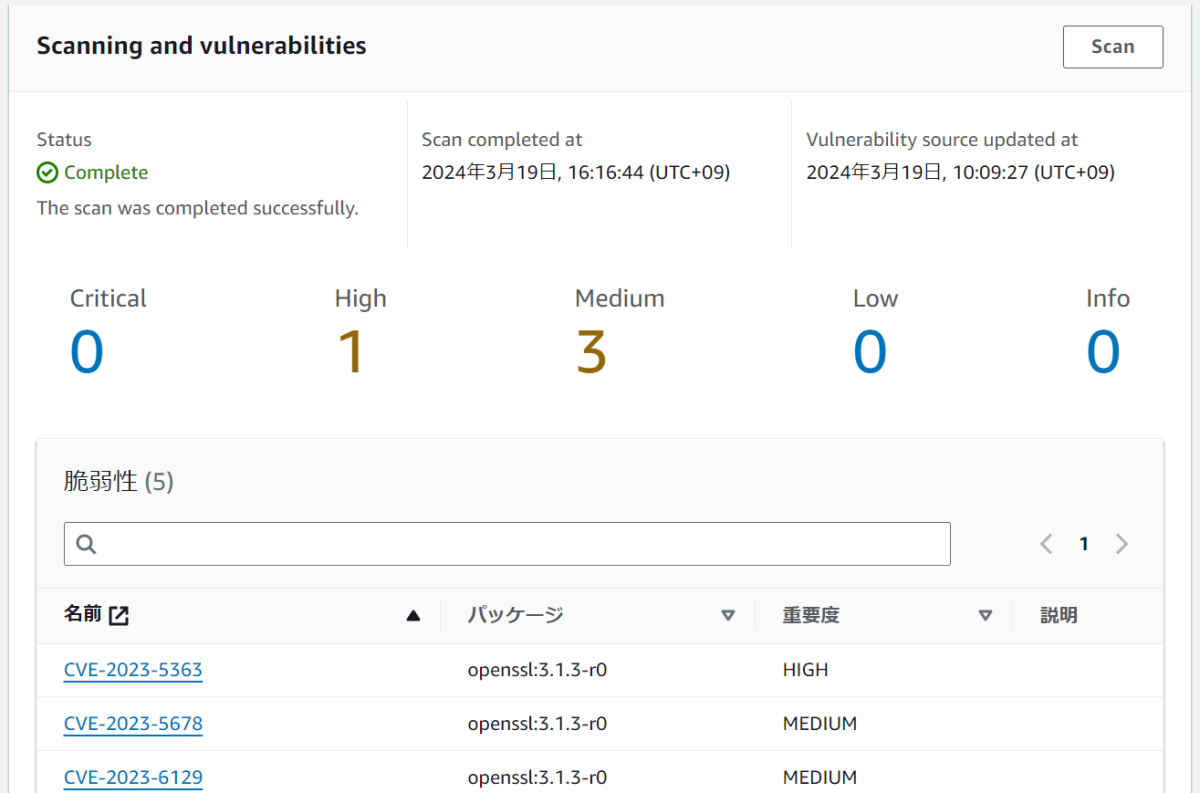
されてた
危険度は上から順に高いみたい(今回は適当にDockerfileを作成しただけなので詳細までは確認しない)
- クリティカル (Critical)
- 最も危険度が高く、直ちに対応が必要な脆弱性
- ハイ (High)
- 重大な影響を与える可能性がある脆弱性で、攻撃者による悪用の可能性が高い
- ミディアム (Medium)
- 中程度の影響を与える可能性がある脆弱性で、攻撃の成功には特定の条件が必要な場合がある
- ロー (Low)
- 比較的影響が小さく、攻撃者による悪用が困難、または影響が限定的な脆弱性
- インフォメーション (Info)
- 実際の脆弱性ではなく、セキュリティに関連する情報や推奨事項を提供する項目
ECSの設定
ECRへDockerイメージをpushするところまでは完了したので、これから実際にECSのあれこれを設定していく
そもそもECSとは?
ECSとはAWSが提供するフルマネージドのコンテナオーケストレーションサービス
フルマネージド・コンテナオーケストレーションとは?
フルマネージド
「フルマネージド」とは、AWSがサーバーの設定、メンテナンス、アップデートなどの運用管理を全て行うサービス形態を指す
利用者はアプリケーションの開発に集中できるため、インフラの複雑な管理から解放される
コンテナオーケストレーション
「コンテナオーケストレーション」とは、複数のコンテナを効率的に自動管理するプロセスとツールを指す
これにより下記のような管理作業を事項化することができる
- デプロイ
- スケーリング
- ネットワーキング
- ロードバランシング
主要なツールとしてECS、Kubernetes、Docker Swarmなどがあり、これらのオーケストレータを使用することで、手動での複雑な管理作業を減らし、運用効率を向上させることができる
手動管理に比べ、オーケストレーションツールを活用することでオペレーションミスを避けつつ、コンテナ環境をスムーズに管理することができる
ECSを利用することで、Dockerコンテナのスケーリング、実行、停止、管理をより簡単に行うことができる
ECSでは
- EC2
- Fargate
- AWS外のオンプレミス環境で実行されるコンテナ環境
上記の三つをECSで簡単に管理するための起動タイプがコンテナ実行環境としてサポートされている
クラスターを作成
そもそもクラスターってなんやねん
クラスターはserviceやタスクの実行基盤
クラスターでは下記の項目を設定する
- クラスター名
- 利用するVPCとサブネット
- 利用するインフラの種類(Fargate or EC2インスタンス or オンプレミスの仮想マシンまたはサーバーなど)
マネジメントコンソールのクラスターの画面に行き、画面右上の「クラスターの作成」ボタンを選択
- 下記項目を設定
- クラスター名
- test-cluster
- インフラストラクチャ
- AWS Fargate(サーバーレス)
- クラスター名
画面下部の作成ボタンを押して作成
EC2とFargateの違いって?
EC2とFargateの共通点
EC2とFargateのどちらにも共通するのはそれらが「AWS上でコンテナを実行するためのサービス」であり、コンテナの実行環境として機能する点
EC2とFargateの違い
主に下記の違いがある
- EC2
- 自分でEC2インスタンス(仮想サーバー)を作成する必要がある
- EC2インスタンスの作成から運用までを自分で行う必要がある
- EC2インスタンスのOSや必要なソフトウェア(Docker Engineなど)、ミドルウェアのインストールを行い設定する必要がある
- Fargate
- コンテナ実行環境の作成などをする必要が無い
- 作成から運用までのプロセスすべてから解放される
- OSやソフトウェア、ミドルウェアのインストールや設定を行う必要が何
じゃあFargateを選択した場合、コンテナはどこで稼働しているの?
↓
結論、EC2インスタンス
起動タイプとしては「EC2インスタンス」と「Fargate」に分けられているけど、コンテナが稼働するサーバーはどちらもEC2インスタンスである
起動タイプが分けられているのはコンテナが実行されるサーバーが違うからではなく、単にユーザーがサーバーのことを意識するか否かの違い
じゃあFargateの方が楽だし良くね?
デメリットとしては下記が存在する
- パブリックIPの固定割り当てができない
- sshやdockerコマンドが使えない
パブリックIPの固定割り当てができない理由と対処法
AWS FargateではパブリックIPの固定割り当てが直接できない理由は、Fargateが提供するサービスの運用モデルとその設計哲学に基づいているとかなんとからしい
Fargateは前提としてユーザーがインフラストラクチャの管理から解放され、アプリケーションとその実行に集中できるように設計されている
↓
このようなサービス設計のため、特定のインスタンスに固定のパブリックIPアドレスを割り当てるという操作は、サービスの抽象化レベルに反してしまうとかなんとか
(正直設計思想まで追いきれないのでここでは深掘りしない)
パブリックIPの固定割り当てができないことへの対処法としては、主にロードバランサーや他のAWSサービスを利用することで間接的に対処することが可能
例としてApplication Load Balancer (ALB) を使用してFargateサービスへのトラフィックをルーティングすることが一般的みたい
当記事でALBは扱わないけどどこかのタイミングでここらへんはやってみたい
sshやdockerコマンドが使えない理由と対処法
前提としてSSHやdocker execを使用する主な理由は、実行中のコンテナやサーバーに対して、デバッグや設定の変更、環境の検査などを行うため
Fargateでこれらのコマンドが直接使用できない理由は、Fargateがサーバーレスコンピューティング環境であり、ユーザーが物理的または仮想的なサーバーにアクセスすることなくコンテナを実行することを目的としているため
対処法としてはAWSはECS Exec機能を提供してるみたい
ECS Execを使用することでFargate上で実行されるコンテナに対してコマンドを実行したり、コンテナ内でシェルセッションを開始することが可能になるみたい
結論どっち使えばいいの?
一般的にはFargateでいいみたい
けど特定の理由などがある場合はEC2インスタンスを起動タイプとして採用するっていう選択肢もあるみたい
詳しくは下記で説明されてるので気になる方はぜひ
金銭的な部分で考えるとFargateの方が若干高いみたいだけどEC2インスタンスの場合はサーバーの管理が必要なのでどっちにしろ人件費がかかる→Fargateの方が安く済むよねってパターンも多そうね(ボソッ)
でけた
次はタスクを作っていく
タスク定義を作成
そもそもタスク定義ってなんやねん
タスク定義とは「どのようなコンテナをどのようなインフラストラクチャでどのようにいくつ作成するのか」などを定義したもの
主に下記のような設定項目が存在する
- ファミリー名
- コンテナ名
- イメージURI
- ポートマッピングでのポート番号
- 環境変数の設定
- ボリューム名
- 実行ロールの設定
- ネットワークモードの設定
イメージとしてはタスク定義は作成する住宅地の設計図
そしてタスク定義を基に作成した実際の住宅地が「タスク」
住宅地の各家がコンテナ
- タスクは実際に作成されたコンテナの集合
- 1つのタスクに複数のコンテナが紐づく(一つの住宅地に複数の家が紐づく)
- タスク定義は作成するタスクの設計図
クラスターの中にサービスがあり、サービスの中にタスクがあるんだよね?なんでサービスを作成する前にタスクを作るんだい?
後述するが、サービスとは特定のタスク定義を基にタスクを管理するもの
つまり特定のサービスに特定のタスク定義を設定することでタスクの起動、停止、スケーリングといったライフサイクルの管理が可能になる
そのため、まずは特定のサービスがどのタスク定義を管理するかを設定する必要があり、それがサービスより先にタスク定義を作成する理由
「新しいタスク定義の作成」を選択する
「新しいタスク定義の作成」ボタンを押すと下記の選択パターンが表示される
- 新しいタスク定義の作成
- JSONを使用した新しいタスク定義の作成
「タスク定義なんてちょちょいのちょいだぜ」って人は多分JSONの方が楽??なのかもだけどワイは一旦「新しいタスク定義の作成」を選択した
JSONだとこんな感じで設定していくみたい
{
"requiresCompatibilities": [
"FARGATE"
],
"family": "",
"containerDefinitions": [
{
"name": "",
"image": "",
"essential": true
}
],
"volumes": [],
"networkMode": "awsvpc",
"memory": "3 GB",
"cpu": "1 vCPU",
"executionRoleArn": ""
}

- 下記項目を設定
- タスク定義ファミリー
- test-task
- 起動タイプ
- AWS Fargate
- タスク定義ファミリー
タスク定義ファミリーって何?
結論、同じタスク定義の異なるバージョンをグループ化するための識別子
かみ砕くと、例としてバックエンドでは実際にプログラムが実行されるサーバーとDBが必要だとする
その場合、タスク定義で設定するコンテナは下記の二つ(命名超適当)
- server-container
- db-container
そして、これらを定義したタスク定義のタスク定義ファミリー名を「backend」に設定する
数か月後、db-containerのCPUをより高性能なものに変更したくなったため、タスク定義を修正しようとしたが、なんと「タスク定義は修正できない」
ではどうするかと言うと、元のタスク定義で修正したい箇所を反映した新しいタスク定義を作成する
その際にタスク定義ファミリー名を再度「backend」に設定する
現時点でタスク定義はもともと使っていたものと新しいタスク定義の二種類存在する
しかしフロント用のタスク定義、バックエンド用のタスク定義、その他のタスク定義が散在していた場合、どのタスク定義がどういった用途で使用されているのかが分からない
そういったときに、用途ごとにタスク定義ファミリー名を同一のものにすることで同じ目的のタスク定義をグループ化することができ、またタスク定義のバージョン(古い・新しい)なども把握することができる
タスク定義を更新したいときに新しいタスク定義を作成する理由は、先ほど説明した通りタスク定義は不変なリソースのため
なぜ不変なのか?
それは、デプロイなどの再現性・安定性を確保するためみたい
ふ、ふーん、、、
クラスターで起動タイプ選択したのに何でタスク定義でも起動タイプ選択するの?
クラスターを作成する際に起動タイプ(EC2またはFargate)を選択する理由は、そのクラスター内で実行されるタスクがどのようなインフラストラクチャ上で動作するかを決定するため
しかし、タスク定義で起動タイプを再度指定する理由は、タスク定義が異なるクラスター間で共有される可能性があるため、そのタスク定義が実行される環境を明示的に指定する必要があるから(なるふぉど)
タスク定義はクラスターに独立した設計書であり、同じタスク定義を異なるクラスターで再利用することができるが、この場合の「異なるクラスター」とは、異なる起動タイプを持つクラスターを意味するのではない
つまりFargate対応のタスク定義はFargateクラスターでのみ、EC2対応のタスク定義はEC2クラスターでのみ使用できる
タスク定義に起動タイプを指定するのは、そのタスク定義が特定の起動タイプに適していることを明確にするためであり、混乱を避けるためのもの
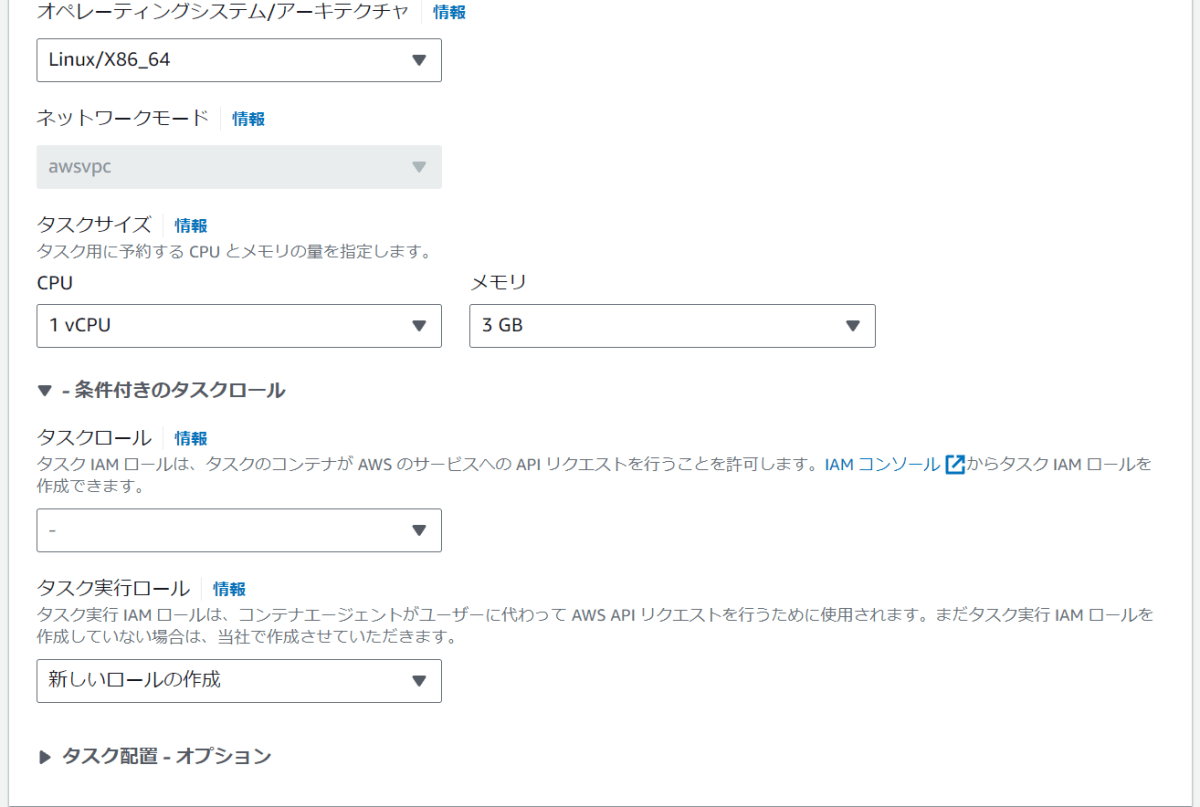
- 画面を下にスクロールして下記項目を設定
- OS/アーキテクチャ
- デフォルト
- ネットワークモード
- デフォルト
- タスクサイズ
- デフォルト
- タスクロール
- デフォルト
- タスク実行ロール
- 「新しいロールの作成」を選択
- OS/アーキテクチャ
タスクロール・タスク実行ロールって何ぞや?
タスクロールは、ECSタスク内で動作するコンテナがAWSサービスへAPIリクエストを行う際に使用するIAMロール
このロールを使用して、タスクがDynamoDBへのアクセス、S3バケットからのファイル読み取りなど、AWSのリソースとやり取りするための権限を付与できる
タスク実行ロールは、ECSタスク自体がAWSサービスとやり取りするために使用するIAMロール
例えばコンテナイメージをECRからプルする、AWS CloudWatch Logsにログを送信するといったタスク実行に必要なAPIコールを許可するためのもの
タスク実行ロールは、タスクのライフサイクル管理(起動、停止、管理)に必要な権限をタスクに付与する
- 画面を下にスクロールしてコンテナ詳細の設定
- 名前
- test-container
- イメージURI
- ECRに保存したイメージURIを設定
- その他はデフォルト
- 名前
プライベートレジストリ認証は有効にしておく必要がある?
ECSタスクでECRのプライベートイメージを使用する場合、タスク実行ロールがECRリポジトリにアクセスする権限を持っていれば、追加でSecrets Managerに認証情報を保存し、プライベートレジストリ認証を設定する必要はない
(タスク実行ロールに、ECRへのアクセス権限を付与するIAMポリシー(例:ecsTaskExecutionRole or AmazonEC2ContainerRegistryReadOnly...)が含まれている必要がある)
ECR以外のプライベートDockerレジストリ(例:Docker Hubのプライベートリポジトリ)からイメージを使用する場合は、そのレジストリへの認証情報を安全に管理するためにAWS Secrets Managerを使用し、プライベートレジストリ認証を有効にする必要がある
これにより、認証情報をセキュアに保存し、タスクが起動する際にこれらの認証情報を使用してプライベートレジストリからイメージをプルできるようになる
整理すると、ECRを使用していて適切なIAMロールとポリシーがタスク実行ロールに割り当てられている場合は、プライベートレジストリ認証を設定する必要はないが、他のプライベートレジストリを使用する場合は、Secrets Managerを使用して認証情報を管理し、これをタスク定義に組み込む必要がある

作成完了
タスク実行ロールの設定で「新しいロールの作成」を選択しただけでまだ何も作成してないけどタスク実行ロールに「ecsTaskExecutionRole」ってやつが設定されてね?自動でやってくれたの?
yes
ECSはタスク実行ロールを自動的に設定する機能を提供してくれている
タスク実行ロールとして「新しいロールの作成」を選択すると、AWSは標準的な権限を持つecsTaskExecutionRoleを自動的に生成し、それをタスク定義に関連付けてくれる(神)
このロールには、ECRからコンテナイメージをプルするための権限やCloudWatch Logsにログを送信するための権限など、タスク実行に必要な最低限の権限が含まれている
サービスを作成
そもそもサービスってなんやねん
サービスはクラスター内で継続的に実行されるタスク(コンテナ群)を管理するための機能
(サービスを定義する際には、どのタスク定義を使用し、どのクラスター上で実行するかを指定する必要がある)
サービスはアプリケーションの運用において重要な役割を果たし、常に特定数のタスクが実行されるように管理してくれる
例として万が一タスクが失敗したり停止したとしても、サービスは自動的にタスク定義に基づいて新しいタスクを起動し、アプリケーションの要件を満たすための継続的な運用を保証してくれる
アプリケーションの可用性が高まったり、運用の手間が軽減されるのは強い
タスク定義の前に作成したクラスターの中に入るとサービスの作成ボタンが表示されるので、「作成」を選択
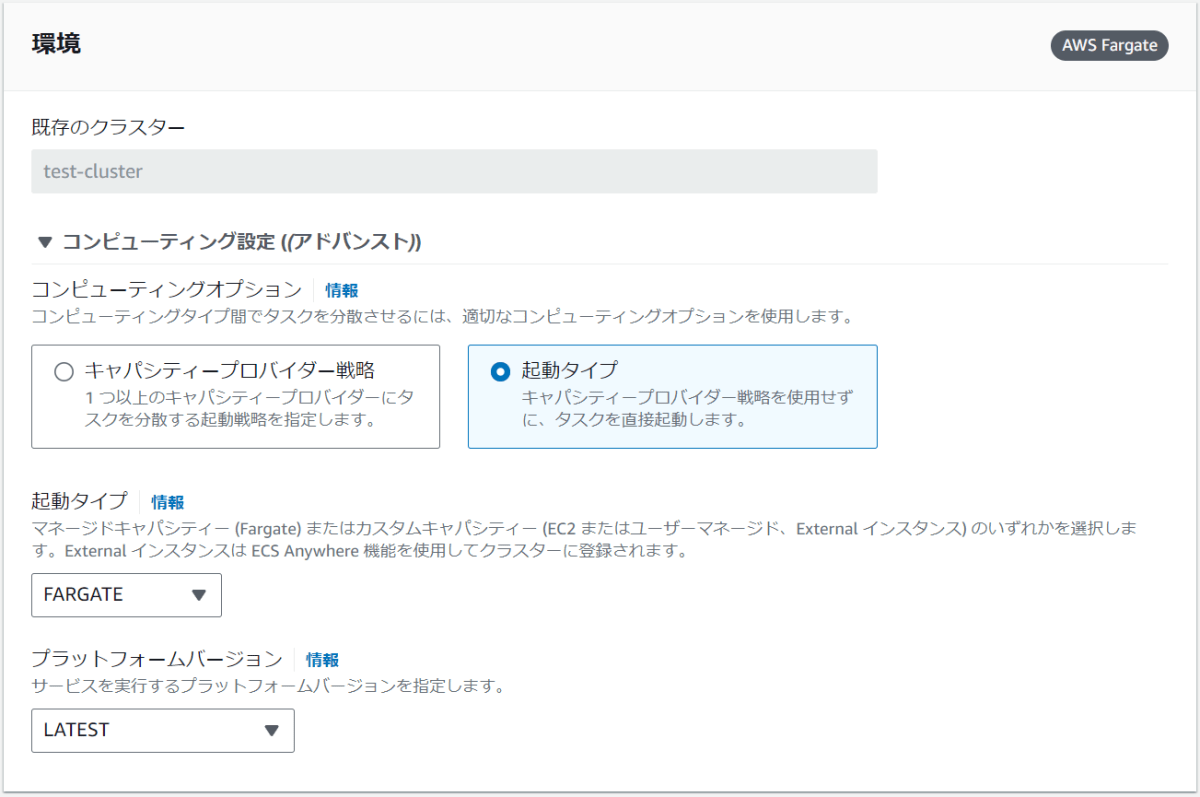
- 下記項目を設定
- 既存のクラスター名
- クラスターが一つしかないと自動でそのクラスターが設定されるっぽい
- コンピューティングオプション
- 起動タイプを選択
- 起動タイプ
- デフォルト
- プラットフォームバージョン
- デフォルト
- 既存のクラスター名
キャパシティープロバイダー戦略・プラットフォームバージョンってなんやねん
キャパシティープロバイダー戦略
キャパシティープロバイダー戦略はECSタスクやサービスをどのAWSリソース上で実行するかを制御するためのもの
// TODO: あんまりよく分からん、また今度ちゃんと調べる
プラットフォームバージョン
プラットフォームバージョンはFargateでタスクを実行する際に使用する基盤技術のバージョンを指すみたい
プラットフォームバージョンはFargate専用の概念であり、Fargateの各バージョンはネットワーク性能、セキュリティ機能、および利用可能な全般的な機能が異なる
利用例
最新の機能や改善を活用したい場合、プラットフォームバージョンとして「LATEST」を選択する
これにより、AWSが提供する最新のFargateプラットフォーム上でタスクが実行される
アプリケーションが特定のプラットフォームバージョンに依存する機能や性能を必要とする場合、そのバージョンを明示的に指定する
例として特定のネットワーキング機能やセキュリティ標準に対応する必要がある場合など
下にスクロールしてデプロイの設定を行う
- 下記項目を設定
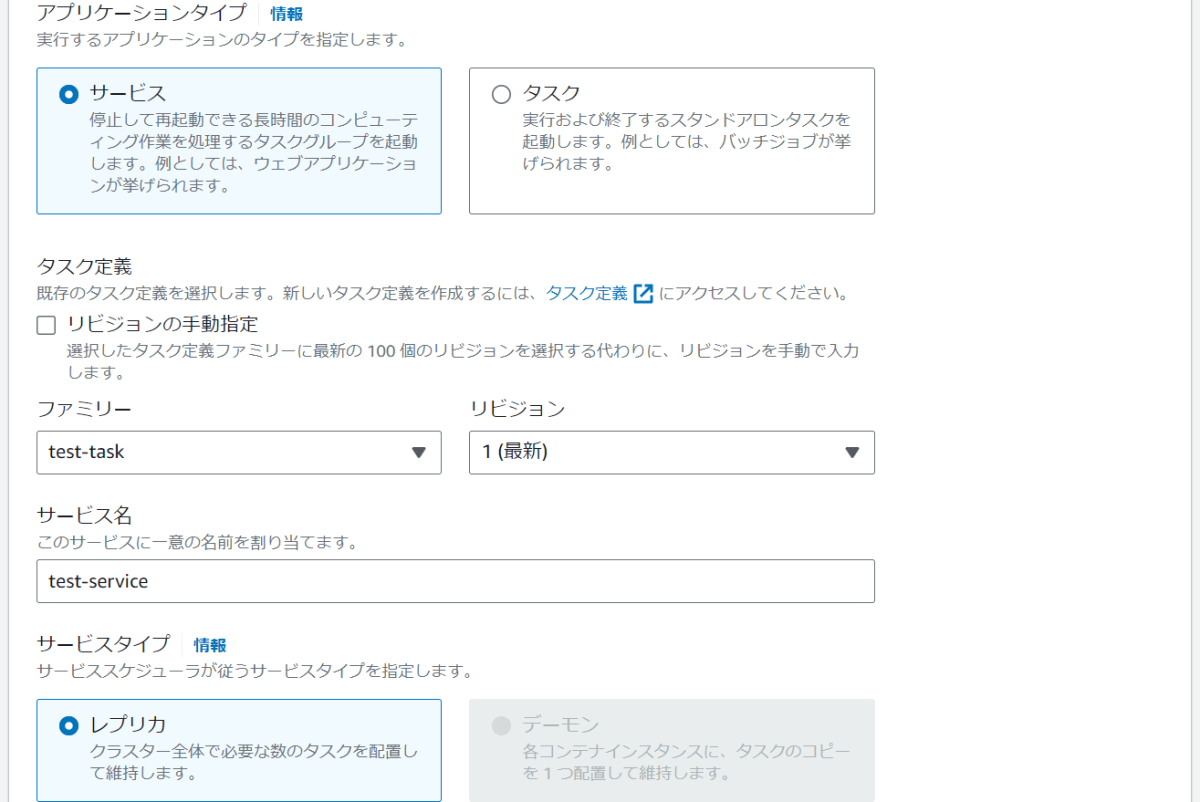
- アプリケーションタイプ
- サービス
- ファミリー
- 作成したタスク定義のタスク定義ファミリー
- サービス名
- test-service
- サービスタイプ
- レプリカ
- 必要なタスク
- デフォルトの1
- アプリケーションタイプ
アプリケーションタイプ・リビジョンってなにイイ??
アプリケーションタイプはECS内でデプロイするアプリケーションの種類を指す
サービスは長期間実行されるアプリケーションやバックエンドサービスに適しており、ECSがタスクのインスタンスを指定された数だけ常に稼働させるよう管理している
タスクが停止または失敗した場合には自動的に新しいインスタンスが起動され、アプリケーションの可用性が保たれる
タスクは一度きりの実行または特定の処理を行うバッチジョブに適しており、指定されたタスクが完了すると終了する
リビジョンは、タスク定義のバージョン管理を指す
タスク定義に変更を加えるたびに、新しいリビジョン番号が割り当てられ、特定のバージョンのタスク定義を明確に指定して、そのバージョンに基づいてタスクやサービスをデプロイすることが可能になる
タスク定義のリビジョンを管理することで、デプロイの履歴を追跡し、必要に応じて以前のバージョンにロールバックすることなどができるみたい
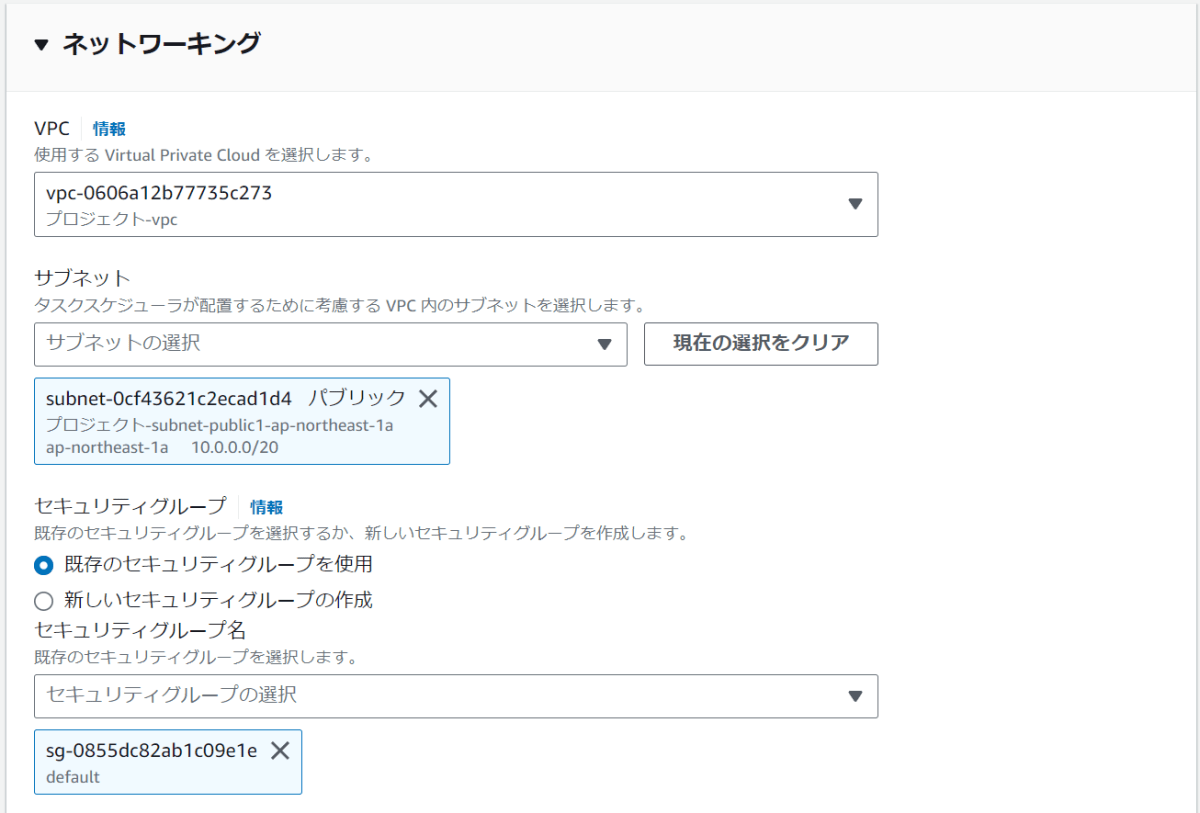
下にスクロールしてネットワーキングの設定を行う
- 下記項目を設定
- VPC
- 作成しているVPCを設定
- サブネット
- 作成しているパブリックサブネットを設定
- セキュリティグループ
- 既存のセキュリティグループを使用
- パブリックIP
- オン
- VPC
VPCが無い場合はまずVPCの作成をする必要がある
サービスやタスクをデプロイする前に、対象となるアプリケーションが通信を行うVPCが必要
VPCが存在しない場合はまずVPCを作成し、その中にサブネットを設定する必要がある
また、サービスやタスクがインターネットや他のAWSサービスと通信するためには適切なセキュリティグループとNATゲートウェイ(プライベートサブネット内のリソースがインターネットにアクセスするために必要)の設定も必要になる
パブリックIPをオンにすることで、インターネットからサービスやタスクにアクセスできるようになりますが、セキュリティ面での考慮も必要
(やること多いなあああああああああ)
サブネットはプライベートサブネットの方が望ましい?
セキュリティ要件が厳しい場合や、インターネットからの直接アクセスを必要としない内部用のアプリケーションをデプロイする場合はプライベートサブネットを選択
一方でWebアプリケーションのようにインターネットからアクセスされるサービスを提供する場合は、パブリックサブネットを選択
って感じかね
パブリックIPをオンってなにイイ??
「パブリックIPをオンにする」とはECSでサービスやタスクを起動する際に、それらのリソースにパブリックIPアドレスを割り当てることを意味するみたい
パブリックIPアドレスを割り当てることで、インターネットから直接そのリソースにアクセスできるようになるため、Webサービスや公開APIなど、外部からのアクセスを必要とするアプリケーションにとって必要な設定となる
ただ、パブリックIPアドレスを割り当てることは、そのリソースがインターネット上で公開されることを意味するため、セキュリティ面での考慮が必要
インターネットに公開しない内部用サービスや、セキュリティが重視される環境では、パブリックIPの割り当てを避けた方が良いみたい
サービス作成中...

まさかの失敗でざんす

原因と対処
原因
そもそもgoのコードがログ吐いたら終了する
package main
import "fmt"
func main() {
fmt.Println("これ実行してログとか出力されたら成功ってことだよね?さらに成長しちゃうってことだよね??まじいいい??")
}
サービスのアプリケーションタイプでは「サービス」を選択している
→つまり上記のような一時的な実行やバッチ実行用のタイプではなく長期間実行するためのアプリケーションタイプを選択している
長期間実行するようなコンテナをECSは期待しているのに実行コードは一瞬で終わる→サービスが期待している挙動じゃないためエラーが起きてた
動作確認
ECS>クラスター>サービス>ログを開く
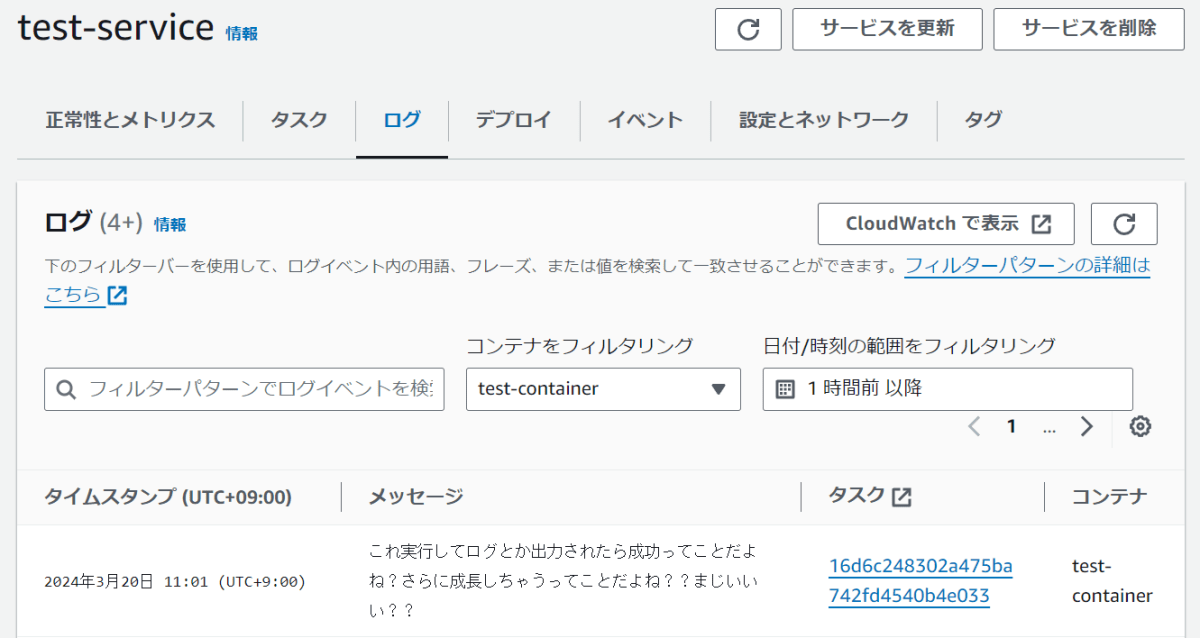
おっけーーーーーーーーー
まとめ
Docker・仮想化・OS・ECR・ECS...
一つの記事に詰め過ぎたので、どこかのタイミングで別記事へ切り出したり整理したりします
ここまで読んでくださった方ありがとうございましたー!!
参考サイト一覧
Discussion