ProseMirror Guide(日本語訳)
この記事は、リッチテキストエディタを構築するためのツールキットを提供するProseMirrorのライブラリガイドを日本語訳した記事です。
製作者の許諾を得て翻訳・公開いたします。
このガイドでは、ライブラリで使われているさまざまな概念と、それらの相互関係について説明します。システムの全体像を把握するためには、少なくともビューコンポーネントのセクションまでは提示された順序で通して読むことをお勧めします。
Introduction
ProseMirrorはリッチテキストエディタを構築するためのツールとコンセプトの両方を提供します。 what-you-see-is-what-you-getに触発されたUIを使用しつつ、その編集スタイルの落とし穴を避けることを目指しています。
ProseMirrorの大原則は、ドキュメント全体とその中で起こることを書いたコードが完全に制御することです。この「ドキュメント」はHTMLのblobではないですが、あなたが明示的に許可し、かつ指定した関連の要素のみを含むカスタムデータ構造です。すべての更新は一ヵ所を経由し、そこでチェックし対応できます。
コアライブラリはすぐに利用可能なドロップインコンポーネントというわけではありません。私たちはシンプル性よりもモジュール性やカスタマイズ性を重視しています(将来的には人々がProseMirrorをベースとしたドロップインエディタを配布してほしいという願いも込めて)。これはマッチボックス カーというよりレゴのセットです。
編集する上で必要な4つのモジュールがあり、またコアチームによって保守され、サードパーティモジュールと同様に便利な機能を提供する数々の拡張モジュールがあります。それらを組み合わせたり、取り除いたり、または同様の機能を実装し置き換えることができます。
必須モジュールは以下です:
- prosemirror-model … エディタのドキュメントモデルで、記事コンテンツを表すために使われるデータ構造です。
- prosemirror-state … エディタの状態(ステート)を表すデータ構造で、選択範囲や、1つのステートから次に遷移するためのトランザクションシステムを含みます。
- prosemirror-view … 与えられたエディタのステートをブラウザで編集可能な要素として表示するインタフェース・コンポーネントを実装し、その要素とのユーザーインタラクションを処理します。
- prosemirror-transform … 記録と再生が可能な形でドキュメントの修正ができる機能を含み、それはstateモジュールのトランザクションを基本とし、さらに取り消し履歴や共同編集を可能にしています。
加えて、基本の編集コマンドや、キーバインディング、取り消し履歴、入力マクロ、共同編集、シンプルなドキュメントスキーマなど、さらに多くの拡張モジュールがprosemirrorのGitHub Organizationに用意されています。
ProseMirrorはブラウザでロード可能な単一のスクリプトとして配布されていないため、利用する際は何らかのバンドラーを必要とするかもしれません。バンドラーとは自動的にスクリプトの依存を自動的に検出し、ウェブページがロードしやすいように1つの大きなファイルとして結合します。ウェブ向けのバンドリングについてはこちらのexampleを読むと良いでしょう。
My first editor
このようにレゴのピースを組み合わせて、非常にミニマルなエディタを作ることができます。
import {schema} from "prosemirror-schema-basic"
import {EditorState} from "prosemirror-state"
import {EditorView} from "prosemirror-view"
let state = EditorState.create({schema})
let view = new EditorView(document.body, {state})
ProseMirrorはドキュメントが準拠するスキーマ(schema)を指定する必要があります。ということで、まず最初は基本スキーマを含むモジュールをインポートします。
そのスキーマを使ってステートが作られ、スキーマに準拠した空のドキュメントが生成され、さらにデフォルトの選択範囲がドキュメントの開始位置に設定されます。最後にビューがステートから作成され、 document.body に挿入されます。これはステートのドキュメントが変更可能(editable)なDOMノードとしてレンダリングされ、そしてユーザーが入力する度にステートトランザクションを生成します。
エディタはまだあまり使い勝手が良くありません。たとえばEnterキーを押しても何も起きません、なぜならコアライブラリはEnterキーが何をすべきかについて何の意見も持っていないからです。その話はまた今度。
Transactions
ユーザーが入力するなどしてビューと対話するとき、ステートトランザクションが生成されます。それがどういう意味かというと、単にドキュメントを直接更新し、暗黙のうちにそのステートを更新するのではないことを意味します。その代わりにすべての変更はステートに対する変更を記述したトランザクションが作成されることによって引き起こされます。
デフォルトではこれらはすべて暗黙のうちに行われますが、プラグインを書いたりビューを設定することによってフックできます。たとえばこのコードは dispatchTransaction プロップ を追加しており、これはトランザクションが作成されるたびに呼び出されます。
// (importは省略)
let state = EditorState.create({schema})
let view = new EditorView(document.body, {
state,
dispatchTransaction(transaction) {
console.log("Document size went from", transaction.before.content.size,
"to", transaction.doc.content.size)
let newState = view.state.apply(transaction)
view.updateState(newState)
}
})
ステートの更新はすべてupdateStateを経由する必要があり、すべての通常の編集はトランザクションをディスパッチすることによって行われます。
Plugins
プラグインは、エディタの振る舞いやエディタのステートをさまざまな方法で拡張するために使用されます。比較的簡単なものとしては、キーボード入力にアクションをバインドするkeymapプラグインのようなものがあります。ほかにはより深く関わるものとして、トランザクションを監視し、ユーザーが戻したい場合に備えてその逆を保存しておき取り消し履歴を実装するhistoryプラグインのようなものもあります。
それではこれらの2つのプラグインを追加し、1つ前に戻る/1つ先に進む機能を手に入れましょう:
// (繰り返しのimportは省略)
import {undo, redo, history} from "prosemirror-history"
import {keymap} from "prosemirror-keymap"
let state = EditorState.create({
schema,
plugins: [
history(),
keymap({"Mod-z": undo, "Mod-y": redo})
]
})
let view = new EditorView(document.body, {state})
プラグインはステート作成時に登録されます(なぜならプラグインはステートトランザクションにアクセスできるからです)。その後履歴が有効なステートのビューが作成され、Ctrl-Z(macOSではCmd-Z)で前の変更に戻すことができます。
Commands
前の例でキーにバインドした undo と redo は、コマンドと呼ばれる特殊な関数です。ほとんどの編集操作はコマンドとして記述され、キーにバインドされたり、メニューに追加されたり、ユーザーに公開されます。
prosemirror-commands パッケージは基本的な編集コマンドとともに最小限のキーマップが提供されており、EnterやDeleteといった操作をエディタで行うことができます。
// (繰り返しのimportは省略)
import {baseKeymap} from "prosemirror-commands"
let state = EditorState.create({
schema,
plugins: [
history(),
keymap({"Mod-z": undo, "Mod-y": redo}),
keymap(baseKeymap)
]
})
let view = new EditorView(document.body, {state})
この時点で、基本的に動作するエディタが完成しました。
メニューを追加したり、スキーマ固有のキーバインディングを追加したりする場合、prosemirror-example-setupパッケージを見ると良いでしょう。これは基本的なエディタをセットアップするプラグインの配列を提供するモジュールですが、その名の通りプロダクションレベルとしてではなくあくまで一例という意味です。現実世界にデプロイするためには、自身のコードに置き換えて希望通りの設定にすることをおすすめします。
Content
ステートのドキュメントはdocプロパティにいます。これはreadonlyなデータ構造で、ドキュメントをノードの階層として表現し、ブラウザのDOMに多少似ています。シンプルなドキュメントとしては、 doc ノードが2つの paragraph ノードを含み、それらは単一の text ノードを持ちます。ドキュメントのデータ構造についてはこのガイドで詳しく説明されています。
ステートが初期化された時、初期ドキュメントを付与できます。スキーマはドキュメントから取得できるため、 schema フィールドは省略可能です。
ここでは content IDのDOM要素で見つかったコンテンツを解析してステートを初期化します。DOMパーサの機構を利用し、どのDOMノードがスキーマのどの要素に対応するかの情報を得ています。
import {DOMParser} from "prosemirror-model"
import {EditorState} from "prosemirror-state"
import {schema} from "prosemirror-schema-basic"
let content = document.getElementById("content")
let state = EditorState.create({
doc: DOMParser.fromSchema(schema).parse(content)
})
Documents
ProseMirrorはドキュメント内容を表現する独自のデータ構造を定義します。ドキュメントはエディタのほかの部分を構成する中心的な要素のため、ドキュメントがどのように機能するかを理解することは有用です。
Structure
ProseMirrorのドキュメントはノードで、それは0個以上の子ノードが含まれたフラグメントを持ちます。
これは再帰的でツリー型である点でブラウザのDOMによく似ています。しかしDOMとはインラインコンテンツの保存方法で違いがあります。
HTMLでは、マークアップがある段落はツリーで表現されます。このように:
<p>This is <strong>strong text with <em>emphasis</em></strong></p>

一方ProseMirrorでは、インラインコンテンツはフラットなシーケンスでモデル化され、マークアップはメタデータとしてノードに付与されます。

この方が、私たちがこのようなテキストについて考え、扱う方法に近いと思います。これにより段落内の位置をツリー内のパスではなく文字のオフセットで表現できるようになり、さらにやっかいなツリー操作なしに分割やコンテンツのスタイル変更の操作をすることを簡単にしました。
これはまた、すべてのドキュメントがそれぞれ1つの有効な表現を持つことを意味します。同じマークアップを持つ隣接するテキストノードは常に一緒に結合され、空のテキストノードは許されません。マークが表出する順序はスキーマによって定義されます。
つまり、ProseMirrorのドキュメントはブロックノードのツリーであり、ほとんどのリーフノード[1]はテキストブロックで、テキストが含まれたブロックノードになります。また単純な空のリーフブロックを持つこともでき、たとえば区切り線や動画要素で使われます。
ノードオブジェクトには、ドキュメント内で果たす役割を反映したいくつかのプロパティが付属しています:
-
isBlockisInline… 与えられたノードがブロックかインラインかを示します。 -
inlineContent… インラインノードをコンテンツとして想定しているノードの場合trueとなります。 -
isTextBlock… インラインコンテンツを持つブロックノードの場合trueとなります。 -
isLeaf… ノードがどのコンテンツも許可しないことを示します。
つまり典型的な paragraph ノードはテキストブロックになり、その一方で blockquote はほかのブロックからなるブロック要素です。テキストや、改行、画像はインラインなリーフノードで、区切り線ノードはブロックリーフノードの一例です。
スキーマはどこに何を表示するかについて正確な制約を指定できます。すなわち、あるノードがブロックコンテンツを許可していても、それはすべてのブロックノードをコンテンツとして許可することを意味しているわけではありません。
Identity and persistence
DOMツリーとProseMirrorドキュメントのもう1つの重要な違いは、ノードを表すオブジェクトの動作方法です。DOMにおいてノードは同一性を持つミュータブルなオブジェクトであり、それはノードが1つの親ノードにのみ表示でき、またノードオブジェクトが更新された時に変化されることを意味します。
一方ProseMirrorではノードとは単なる値であり、数字の「3」を表す値にアプローチするのと同じようにアプローチする必要があります。「3」は複数のデータ構造で同時に表示でき、現在所属しているデータ構造に対して親へのリンクを持ちません。またそれに1を足した場合「4」という新しい値を得ることができ、それはオリジナルである「3」を何も変えずに実行できます。
ProseMirrorドキュメントでもそうです。ドキュメント自体は変更せずに、変更されたドキュメントの一部を計算するための開始値として使用できます。それらは自身が含まれているデータ構造が何かを知りませんが、複数の構造の一部として所属でき、1つの構造体に複数回出現することもあります。これらは値であり、ステートフルなオブジェクトではありません。
つまり、ドキュメントを更新する度に新しいドキュメントの値が得られることを意味します。元のドキュメントの値から変更がなかったすべてのサブノードを共有することになり、新しいドキュメントの値を比較的安価に作成できます。
これにはたくさんのアドバンテージがあります。新しいドキュメントを含む新しいステートを瞬時に入れ替えることができるため、アップデート中にエディタが無効なステートになることがありません。また、ドキュメントをある程度数学的に推論することを簡単にします。これはもし値が知らないところで変更し続けられていたとしたら難しいことです。これは共同編集を可能にし、ProseMirrorがビューに描画された最後のドキュメントと現在のドキュメントを比較することで、DOMの更新アルゴリズムを効率的に実行できるようになります。
ノードは通常のJavaScriptオブジェクトで表現されており、そのプロパティをフリーズするとパフォーマンスが低下するため実際には変更は可能です。しかしそのような行為はサポートされていません。またそういった行為はだいたいの場合複数のデータ構造間で共有されるため破壊を引き起こします。注意してください!
これはノードオブジェクトの一部である配列やプレーンオブジェクト、たとえばノードの属性を保存するためのオブジェクトや、フラグメントの子ノードの配列にも適用されることに注意しましょう。
Data structures
ドキュメントのオブジェクト構造はこのようになっています:

それぞれのオブジェクトはノードクラスのインスタンスとして表現されます。これはタイプによってタグづけされ、ノードの名前やそのノードに対して有効な属性などを知っています。 ノードタイプ(やマークタイプ)はスキーマごとに一度だけ作成されます。
ノードのコンテンツはフラグメントのインスタンスとして保存され、ノードの配列を保持します。コンテンツを持たない、あるいはコンテンツを許可しないノードに対しても、このフィールドは(共有された空のフラグメントで)満たされます。
ノードタイプは各ノードに保存される追加の値を属性として利用できます。たとえば image ノードはaltテキストや画像のURLを保存する必要があるかもしれません。
加えて、インラインノードはアクティブなマークの配列を保持できます。強調やリンクなどが該当し、それらはMarkのインスタンスの配列として表現されます。
全体のドキュメントも単なるノードです。ドキュメントのコンテンツは、トップレベルノードの子ノードとして表現されます。つまり、それは一連のブロックノードを含み、そのうちのいくつかはインラインコンテンツを含むテキストブロックかもしれません。しかしトップレベルのノードもテキストブロックそのものである場合もあり、その場合、ドキュメントはインラインコンテンツのみを含むことになります。
どのようなノードがどこに許されるかはドキュメントのスキーマによって決定されます。プログラムでノードを作成するためには、nodeメソッドやtextメソッドなどを使ってスキーマを経由する必要があります。
import {schema} from "prosemirror-schema-basic"
// (引数のnullは、必要に応じて属性(attributes)を指定する場所です)
let doc = schema.node("doc", null, [
schema.node("paragraph", null, [schema.text("One.")]),
schema.node("horizontal_rule"),
schema.node("paragraph", null, [schema.text("Two!")])
])
Indexing
ProseMirrorのノードは二種類のインデックス(indexing)をサポートします。個々のノードへのオフセットを使用してツリー構造として扱うことも、トークンのフラットなシーケンスとして扱うこともできます。
1つ目はDOMで行うのと同じようなことができます。単一のノードに対して、childメソッドやchildCountを使って直接子ノードにアクセスしたり、ドキュメントを走査する再帰的な関数を書くことが可能です。(すべてのノードを見たいだけならdescendantsやnodeBetweenを使います)
2つ目は、ドキュメントの特定のポジションを取り上げる場合に有効です。それはドキュメントのポジションをIntegerのトークンのインデックスとして表現します。これらのトークンは実際にはメモリ上のオブジェクトとしては存在しない、単なる数え方です。しかし、ドキュメントのツリー形状と、各ノードが自身のサイズを知っているという事実を利用して、ポジションによるアクセスは低コストに実現できます。
- ドキュメントの開始値、最初のコンテンツの直前がポジション「0」です。
- リーフノードでないノード(コンテンツを含められるノード)への入退出は1トークンと数えます。つまりドキュメントが
paragraphで始まる場合、paragraphの開始値は1と数えます。 - テキストノードの1文字は1トークンとして数えます。つまりもし
paragraphがドキュメントの開始でhiというワードを含んでいる場合、 ポジション2はhの後、ポジション3はiの後、ポジション4はparagraph全体の後にあります。 - リーフノードはコンテンツを含まないため(画像などのように)、それもまた1トークンと数えます。
つまりHTMLで表現すると、次のようなドキュメントがあるとします。
<p>One</p>
<blockquote><p>Two<img src="..."></p></blockquote>
ポジションを含むトークンシーケンスは次のようになります。
0 1 2 3 4 5
<p> O n e </p>
5 6 7 8 9 10 11 12 13
<blockquote> <p> T w o <img> </p> </blockquote>
それぞれのノードはnodeSizeプロパティを持ち、そのノード全体のサイズを提供します。また.content.sizeはノードのコンテンツのサイズにアクセスできます。なお最も外側のドキュメントノードでは開始と終了のトークンはドキュメントの一部とは見なされないため(カーソルをドキュメントの外側に置くことはできないため)、ドキュメントのサイズは doc.nodeSize ではなく doc.content.size になります。
このようなポジションを手作業で解釈するにはかなり多くの数え上げが必要です。Node.resolveを呼び出すと、ポジションについてのより詳細なデータ構造を取得できます。データ構造は親ノードのポジションや、親からのオフセット、どの祖先を親が持っているかなど多くの事柄を伝えます。
childCountによる子インデックス、ドキュメント全体のポジション、ノードローカルなオフセット(再帰的関数で現在処理されているノードのポジションを表すために使われる)を区別するように注意してください。
Slices
コピー&ペーストやドラッグ&ドロップを処理するために、ドキュメントのスライス、つまり2つのポジション間のコンテンツについて話す必要があります。スライスは、ノードやフラグメントとは異なり開始点や終点が「開いている」可能性があります。
たとえば、ある段落の途中から次の段落の途中までを選択した場合、選択したスライスには2つの段落が含まれます。段落そのものをノード選択するとノードに閉じた選択が行われるのに対して、1つ目の方は開始側が開き、2つ目の方は終了側が開きます。このようなオープンなノードでは必要なノードがスライスの外に出てしまっているため、ノードの全内容と同様に扱うとスキーマの制約に違反する場合があります。
スライスのデータ構造はそのようなスライスを表すために使われます。それは左右の開いている深さに沿ってフラグメントを保存します。ノードのsliceメソッドを使うと、ドキュメントをスライスして切り出すことができます。
// docは2つのparagraphを持ち, "a" と "b" のテキストを含む
let slice1 = doc.slice(0, 3) // 1つ目のparagraph
console.log(slice1.openStart, slice1.openEnd) // → 0 0
let slice2 = doc.slice(1, 5) // 1つ目のparagraphから開始し、2つ目のparagraphで終了している
console.log(slice2.openStart, slice2.openEnd) // → 1 1
Changing
ノードとフラグメントは永続的であるため、けっして更新(mutate)してはいけません。もしあなたがドキュメント(もしくはノードやフラグメント)のハンドル[2]を持っている場合、そのオブジェクトは同じままです。
ほとんどの場合はtransformを使ってドキュメントを更新するため、ノードを直接触ることはないでしょう。transformは変更の履歴も残します。これはドキュメントがエディタステートの一部である場合に必要です。
更新されたドキュメントを「手動で」導き出したい場合、ヘルパーメソッドが NodeとFragmentで利用可能です。ドキュメント全体の更新されたバージョンを作成するには、通常 Node.replaceを使用します。これは、ドキュメントの任意の範囲を新しいコンテンツのsliceで置き換えます。ノードを浅く(shallowly)更新する場合、copyメソッドを使うと新しいコンテンツが含まれた同様のノードを作成できます。フラグメントも replaceChildやappendのようなさまざまな更新メソッドを持ちます。
Schemas
それぞれのProseMirrorドキュメントにはスキーマが関連付けられています。スキーマは、ドキュメント内で出現する可能性のあるノードの種類と、それぞれのネスト方法が記述されています。たとえば、トップレベルのノードは1つかそれ以上のブロックを含むと宣言でき、またparagraphノードは任意の数のインラインノードを含み、それらにはいくつかのマークが付与されています。
これらはbasic schemaパッケージで利用可能ですが、ProseMirrorの素晴らしいことの1つはあなた自身でスキーマを定義できることです。
Node Types
ドキュメント内のすべてのノードはタイプを持ち、それはセマンティックな意味とプロパティが表現され、つまりエディタでどのようにレンダリングするかを表します。
スキーマを定義するとき、スペックオブジェクトを利用して現れる可能性のあるノードタイプを列挙できます。
const trivialSchema = new Schema({
nodes: {
doc: {content: "paragraph+"},
paragraph: {content: "text*"},
text: {inline: true},
/* ... 続く */
}
})
このスキーマではドキュメントは1つかそれ以上の paragraph が含まれることを定義しており、またそれぞれの paragraph は任意の数の text を含むことができます。
スキーマは1つ以上のトップレベルなノード(デフォルトでは doc という名前ですが設定もできます)が必要であり、また text タイプはテキストコンテンツです。
インラインとして数えられるノードは inlineプロパティで宣言する必要があります。(ただし定義上インラインであるテキストタイプでは省略できます)
Content Expressions
上に挙げた例のスキーマにあるcontentフィールドの文字列は、コンテンツ式(content expressions)と呼ばれるものです。それらは一連の子ノードがノードタイプに対しての正しさを制御できます。
たとえば「1つのparagraph」を表す paragraph や、「1つかそれ以上のparagraph」を表す paragraph+のように表現できます。同様に paragraph* は0個かそれ以上のparagraphを意味します。 また caption? は0個か1個のcaptionを表します。正規表現のように幅を表すこともでき、たとえば {2} は2つのみ、 {1,5} は1〜5、 {2,} は2つかそれ以上を示します。これらをノード名の後に記載します。
コンテンツ式では連結されたシーケンスを作成できます。たとえば heading paragraph+ は「1つ目はheading、その後1つかそれ以上のparagraph」を表します。さらにパイプオペレータ(pipe operator)を使えば (paragraph | blockquote)+ のように2つの式のOR条件を表すこともできます。
いくつかの要素タイプのグループはスキーマに複数回出現します。たとえばあなたがブロックノードという概念を持っているとして、それはトップレベルにありますが、 blockquote ノードの中にネストされていることもあります。このような表現をしたい場合、ノードスペックの groupプロパティを使ってノードグループを作ることができます。次に示すのはグループを表現したものです。
const groupSchema = new Schema({
nodes: {
doc: {content: "block+"},
paragraph: {group: "block", content: "text*"},
blockquote: {group: "block", content: "block+"},
text: {}
}
})
この block+ は (paragraph | blockquote)+ と一致します。
常に1つ以上の子ノードを必須とするノードは、ブロックコンテンツ(たとえば doc や blockquote)を持たせることを推奨します。なぜならブラウザはノードが空の場合完全に壊れてしまい、編集がかなり困難になってしまいます。
OR式(or-expression)ではノードの順序は重要です。子ノードを必須とするノードに対してデフォルトのインスタンスを作成する際、たとえばreplace stepの後などでドキュメントがスキーマに適合しているかを確認するために、OR式の最初のノードタイプが使われることになります。それがグループの場合、グループの最初のノードタイプ(スキーマで定義される、グループに含まれるノードタイプの順番で決定される)が使われます。上記の paragraph と blockquote の位置を切り替えた場合、エディタがブロックノードを作成しようとするやいなやスタックオーバーフローになるでしょう。 blockquote ノードを作成しようとした時にそのノードが必須とするコンテンツは1つ以上のブロックノードで、また別の blockquote を作成しようとして…といった具合に。
ライブラリ内のすべてのノード操作関数が、有効なコンテンツを扱っているかをチェックするわけではありません。transformのような上級概念はそうですが、プリミティブなノード作成関数は行わないため、代わりに正しい情報を提供する責任は呼び出し側にあります。たとえばNodeType.createを使って無効なコンテンツを持つノードを作成することは完全に可能です。 スライスの端で「開かれた」ノードについてはこれは合理的なことであるとさえ言えるでしょう。
与えられたノードのコンテンツが有効であることを保証するためには、NodeType.create の代わりに使えるcreateChecked関数と、事後チェックで使えるcheck関数があります。
Marks
マークは、スタイリングを追加したり他の情報をインラインコンテンツに追加するために使われます。スキーマはすべてのマークタイプを明示し許可する必要があります。マークタイプはノードタイプに似たオブジェクトで、マークオブジェクトにタグをつけ、そのオブジェクトに関する追加情報を提供するために使われます。
デフォルトでは、インラインコンテンツを含むノードでは、スキーマで定義されたすべてのマークがその子に適用されます。
ノードスペックのmarksプロパティで設定できます。
これは太字や強調のマークが段落内のテキストでサポートされたシンプルなスキーマですが、見出しではマークは許可されていません。
const markSchema = new Schema({
nodes: {
doc: {content: "block+"},
paragraph: {group: "block", content: "text*", marks: "_"},
heading: {group: "block", content: "text*", marks: ""},
text: {inline: true}
},
marks: {
strong: {},
em: {}
}
})
マークの集合は、スペースで区切られた文字列のマーク名またはマークグループとして解釈されます。 _ はワイルドカードとして機能し、空文字列は空の集合に対応します。
Attributes
ドキュメントスキーマはそれぞれのノードやマークが持つ属性(attribute)もまた定義できます。たとえば見出しノードのレベルなど、ノードタイプで追加のノード定義情報の保存を必要としたい場合、それは属性で行うのが最も良い方法です。
heading: {
content: "text*",
attrs: {level: {default: 1}}
}
このスキーマでは、すべての見出しノードのインスタンスは .attrs.level にレベル属性を持ちます。ノードが作成される際に定義されなかった場合、デフォルトの1になります。
デフォルト値を属性に与えなかった場合、属性を指定せずにそのノードの作成を試みた際にエラーが発生します。
また、変換時やcreateAndFillの呼び出しなど、ライブラリがスキーマの制約を満たしながらそのノードの生成をできなくなります。このため、このようなノードをスキーマの必須位置に置くことはできません。スキーマ制約を適用するために、エディタはコンテンツに欠けている部分を埋めるために空のノードを生成できる必要があります。
Serialization and Parsing
ブラウザで編集できるようにするために、ブラウザのDOMでドキュメントノードを表現できなければなりません。それを行う最も簡単な方法は、ノードスペックのtoDOMフィールドを使用してそれぞれのノードのDOM表現に関する情報をスキーマに含むことです。
このフィールドには、ノードを引数として呼び出されたときにそのノードのDOM構造の説明を返す関数を格納する必要があります。これは、たとえば直接的なDOMノードであったり、それを記述した配列であったりします。
const schema = new Schema({
nodes: {
doc: {content: "paragraph+"},
paragraph: {
content: "text*",
toDOM(node) { return ["p", 0] }
},
text: {}
}
})
["p", 0] という表現は、段落がHTMLの <p> タグとしてレンダリングされることを表しています。0はそのコンテンツがレンダリングされるべき「枠」です。また、 ["div", { class: "c"}, 0] のようにタグ名の後にHTML属性を持つオブジェクトを含むこともできます。リーフノードはコンテンツを持たないため、DOM表現に「枠」は不要です。
マークスペックはtoDOMと近いものが可能ですが、コンテンツを直接含む単一のタグとしてレンダリングされることを必要とするため、コンテンツは常に直接ノードに入り、枠を指定する必要はありません。
利用者がペーストしたりドラッグして何かをエディタに追加した時などで、DOMデータをもとにドキュメントをパースする必要があります。modelモジュールにはそのための機能も搭載されており、parseDOMプロパティを使ってスキーマに直接パース情報を含めることが推奨されています。
これは、指定されたノードやマークに対応するDOM構成を記述したパースルールの配列です。たとえば、basic schemaは強調のマークを持っています。
parseDOM: [
{tag: "em"}, // <em>ノードにマッチ
{tag: "i"}, // <i>ノードにマッチ
{style: "font-style=italic"} // インラインの'font-style: italic'にマッチ
]
tagに提供された値はCSSセレクタにできるので、 div.myclass のようなことも可能です。同様に、styleはインラインのCSSスタイルにマッチします。
スキーマがparseDOMのアノテーションを含む時、DOMParser.fromSchemaを使ってDOMParserオブジェクトを作ることができます。これはエディタがデフォルトのクリップボードパーサを作成するために行われますが、オーバーライドもできます。
ドキュメントはビルトインのJSONシリアライズ用のフォーマットも搭載しています。オブジェクトのtoJSONを呼び出すことでJSON.stringifyに安全に渡せるオブジェクトを取得でき、またschemaオブジェクトはこの表現を解析してドキュメントに戻すことができるnodeFromJSONメソッドを持っています。
ドキュメントはビルトインのJSONシリアライズ用のフォーマットも搭載しています。オブジェクトのtoJSONを呼び出すことでJSON.stringifyに安全に渡せるオブジェクトを取得でき、またschemaオブジェクトはこの表現を解析してドキュメントに戻すことができるnodeFromJSONメソッドを持っています。
Extending a schema
Schemaのコンストラクタに渡されるノードやマークのオプションは、プレーンなJavaScriptオブジェクトと同様のOrderedMapオブジェクトとして取得できます。スキーマのspec.nodesやspec.marksのプロパティの結果は常にOrderedMapであり、さらなるスキーマのベースとして使用できます。
このmapは更新版を簡単に作成するいくつかの方法をサポートしています。たとえば schema.markSpec.remove("blockquote") はblockquoteノードが取り除かれたノードの集合を返し、それを新しいスキーマのノードフィールドとして渡すことができます。
schema-listモジュールはこれらのモジュールがエクスポートするノードをノードの配列に追加するための便利なメソッドをエクスポートします。
Document transformations
トランスフォームはProseMirrorの動作の中心です。トランスフォームはトランザクションのベースとなり、履歴の追跡や共同編集を可能にするものです。
Why?
なぜドキュメントを更新(mutate)して終わりにできないのでしょうか?もしくは、少なくとも新しいバージョンのドキュメントを作成しエディタに入れるだけでよいのでは?
それはいくつかの理由があります。1つはコードの明確化です。イミュータブルデータストラクチャは本当にシンプルなコードを推進します。トランスフォームシステムが行う主なことは、個々のステップを表す値という形で、古いバージョンのドキュメントから新しいバージョンに移行するための更新の痕跡を残すことです。
取り消し履歴はこれらのステップを保存し逆に戻すことができます。(ProseMirrorは選択的な取り消しを実装しており、それは単に以前のステートにロールバックすることよりも複雑です)
共同編集システムはこれらのステップを他のエディタに送信し、最終的に全てのエディタを同じドキュメントにするために必要があれば再整理します。
より一般的には、エディタプラグインでは変更が入るたびに検査し適応できるため、非常に便利です。自分自身のステートを他のエディタのステートと矛盾しないようにするためでもあります。
Steps
ドキュメントの更新は、更新を記述するステップ(steps)に分解されます。通常、これらを直接操作する必要はありませんが、どのように機能するかを知っておくと便利です。
ステップの例としては、ドキュメントの一部を置き換えるReplaceStepや、与えられた範囲にマークを付与するAddMarkStepがあります。
ステップはドキュメントに適用することで、新しいドキュメントを生み出すことができます。
console.log(myDoc.toString()) // → p("hello")
// ポジション3~5までのコンテンツを削除するステップ
let step = new ReplaceStep(3, 5, Slice.empty)
let result = step.apply(myDoc)
console.log(result.doc.toString()) // → p("heo")
ステップを適用することは比較的単純なプロセスです。スキーマ制約を守りながらノードを挿入したり、スライスを適合させるために変形させたりといった、気の利いたことは何もしません。それはステップの適用が失敗できることを意味します。たとえばノードの開始トークンだけを削除しようとした時、それはトークンのバランスを崩してしまい、意味のないことになってしまいます。このようにapplyはresultオブジェクトを返し、新しいドキュメントかエラーメッセージのどちらかを返します。
通常は、ヘルパー関数でステップを生成させることで、これらのような細かいことを気にする必要がなくなります。
Transforms
編集アクションは1つかそれ以上のステップを生成します。一連のステップを処理する最も便利な方法は、Transformオブジェクトを作成することです(もしくは、エディタステートで作業している場合はTransformのサブクラスであるTransaction)。
let tr = new Transform(myDoc)
tr.delete(5, 7) // ポジション5~7を削除
tr.split(5) // ポジション5の親ノードを分割
console.log(tr.doc.toString()) // 編集されたドキュメント
console.log(tr.steps.length) // → 2
多くの変形メソッドはTransform自身を返し、チェーンに便利です。tr.delete(5).split(5) のようにできます。
削除や置換、追加やマークの削除、分割や結合、持ち上げ(lift)や折り返し(wrapping)などのツリー操作のための変形メソッドなどがあります。
Mapping
ドキュメントを変更するとき、ドキュメント内のポジションが無効になったり意味が変わったりする可能性があります。たとえば文字列を1つ挿入するとき、その文字以降の全てのポジションは以前のポジションの1つ前のトークンを指すようになります。同様に、ドキュメント内のコンテンツを全て削除する時、コンテンツを指す全てのポジションは全て無効になります。
ドキュメントの変更に伴うポジションの保持が必要な場合はよくあります。たとえば選択範囲の境界線など。これを助けるために、ステップはステップを適用する前と後のドキュメント内のポジションを変換できるマップを与えることができます。
let step = new ReplaceStep(4, 6, Slice.empty) // 4-5を削除
let map = step.getMap()
console.log(map.map(8)) // → 6
console.log(map.map(2)) // → 2 (変更前と何も変わらない)
Transformオブジェクトは、マッピングと呼ばれる抽象化機能を用いて、その中のステップのマップを自動的に蓄積し、一連のステップマップを一度に見ることができます。
let tr = new Transform(myDoc)
tr.split(10) // ノードを分割し、ポジション10にトークンを+2する
tr.delete(2, 5) // ポジション2にトークンを-3する
console.log(tr.mapping.map(15)) // → 14
console.log(tr.mapping.map(6)) // → 3
console.log(tr.mapping.map(10)) // → 9
あるポジションが何にマッピングされるべきか、全くわからないケースもあります。上の例の最後の行を考えてみましょう。ポジション10は、ノードを分割してトークンを2つ挿入するポジションに正確に指し示します。この場合、挿入されたコンテンツの後ろのポジションにマップされるべきでしょうか、それとも前のポジションに止まるべきでしょうか?この例では、トークンの後に移動しているようです。
しかし、時には他の振る舞いが欲しくなることもあります。そのため、ステップマップとマッピングのmapメソッドでは、2番目の引数で bias を受け付けます。 bias に -1 を設定するとコンテンツがその上に挿入されてもポジションを維持できます。
console.log(tr.mapping.map(10, -1)) // → 7
個々のステップを小さくわかりやすく定義しているのは、反転ステップをロスレスで実施したり、マッピングステップでお互いのポジションマップを確認するなど、これらのようなマッピングを可能にするためです。
Rebasing
たとえば独自の変更追跡機能を実装したり、共同編集機能を統合するなど、ステップやポジションマップより複雑なことをする場合、ステップをリベースする必要が出てくるかもしれません。
必要だと確認するまでは、わざわざ勉強する必要はないかもしれません。
リベースのシンプルなケースとしては、同じドキュメントから始まる2つのステップを取得し、片方を変形させて、もう片方で作成したドキュメントに適用できるようにすることがあります。擬似的なコードとしては:
stepA(doc) = docA
stepB(doc) = docB
stepB(docA) = MISMATCH!
rebase(stepB, mapA) = stepB'
stepB'(docA) = docAB
ステップにはmapメソッドがあり、マッピングが与えられると、そのマッピングを通してステップ全体をマッピングします。これは失敗することもあります。たとえば、適用していたコンテンツが削除された場合、一部のステップは意味をなさなくなるからです。しかしそれが成功すると、新しいドキュメント、つまりマッピングした変更後のドキュメントを指すステップができます。上記の例では、 rebase(stepB, mapA) は単に stepB.map(mapA) を呼び出すだけでいいのです。
ステップの連鎖を別のステップの連鎖の上にリベースしたい場合は、もっと複雑になります。
stepA2(stepA1(doc)) = docA
stepB2(stepB1(doc)) = docB
???(docA) = docAB
stepB1 を stepA1 、 stepA2 の順にマップして stepB1' を得ることができます。しかし、 stepB1(doc) が生成したドキュメントを起点とし、 stepB1'(docA) が生成したドキュメントにそのマッピング版を適用しなければならない stepB2 では、より困難となります。それは、次のようなマップの連鎖の上にマップされなければなりません。
rebase(stepB2, [invert(mapB1), mapA1, mapA2, mapB1'])
つまりまず stepB1 の逆マップで元のドキュメントに戻り、 stepA1 と stepA2 を適用して生成したマップのパイプラインを経て、最後に stepB1' を docA に適用して生成したマップを経由することになります。
もし stepB3 があれば、上のパイプラインの前に invert(mapB2) をつけ、最後に mapB2' をつけることで、そのパイプラインを得ることができます。といった具合です。
しかし stepB1 が何らかのコンテンツを挿入し、 stepB2 がそのコンテンツに対して何かを行った場合、 stepB1 の逆は適用するコンテンツを削除するため、 invert(mapB1) を通して stepB2 をマッピングすると null を返します。とはいえこのコンテンツはパイプラインの後半で mapB1 によって再導入されます。マッピング抽象化は、そのようなパイプラインを追跡する方法を提供し、その中のマップの間の逆関係を含みます。上のような状況を乗り切るために、ステップをマッピングできます。
ステップをリベースしても、それが現在のドキュメントに有効に適用できる保証はありません。たとえば、ステップでマークを追加しても、別のステップでターゲットコンテンツの親ノードがマークを許可しないノードに変更されていた場合、そのステップを適用しようとすると失敗します。この場合、通常はそのステップを削除するのが適切な対応となります。
The editor state
エディタステートはどのように作れば良いのでしょうか?もちろん自身のドキュメントを持ち、現在の選択範囲もあります。また、マークを含むタイピングを始める前にマークが無効や有効かを示せるように、現在の変更されたマークを保存するための手段も必要です。
それらはProseMirrorのステートの3つの中心的なコンポーネントであり、ステートオブジェクトに存在するdoc, selection, storedMarksを指します。
import {schema} from "prosemirror-schema-basic"
import {EditorState} from "prosemirror-state"
let state = EditorState.create({schema})
console.log(state.doc.toString()) // 空の段落
console.log(state.selection.from) // 1, 段落の開始値
プラグインもまたステートに保存する必要があります、たとえば、 undo history は変更履歴を保持します。このようにアクティブなプラグインの配列もステートに保存され、プラグインは自身のステートに保存するための追加スロットを定義できます。
Selection
ProseMirrorはいくつかのタイプのセレクション(選択範囲)をサポートしています。(サードパーティのコードによる新しいセレクションのタイプの定義もできます)セレクションはSelectionクラス(またはそのサブクラス)のインスタンスとして表現されます。ドキュメントやその他のステートに関連する値のようにそれらはイミュータブルです。セレクションを変更するためには、新しいセレクションオブジェクトとそれを保持するための新しいステートを作成します。
セレクションは少なくとも、現在のドキュメントを指すポジションとして開始(from)と終了(to)を持ちます。多くのセレクションタイプはanchor(移動不可)側とhead(移動可能)側を区別し、それらは全てのセレクションオブジェクトで必須でもあります。
最も一般的なセレクションタイプはテキストセレクションで、それは通常カーソル( anchor と head が同一の時)やテキストの選択範囲として使われます。テキストセレクションの両端は、インラインのポジション、すなわちインラインコンテンツを許可するノードを指していることが必要です。
また、コアライブラリではノードセレクション(単一のドキュメントノードを選択すること)もサポートしており、たとえばノードをctrl/cmdクリックした時に得られます。この場合、選択範囲はノードの直前のポジションから直後のポジションです。
Transactions
通常の編集では、新しいステートはその前のステートから派生していきます。状況によっては新しいドキュメントの読み込みなど完全に新しいステートを作りたい場合がありますが、これは例外です。
ステートの更新は、既存のステートからトランザクションを適用(apply)することによって起こり、新しいステートを生み出します。概念として、古いステートとトランザクションが与えられたら、ステートの各要素について新しい値が計算され、それらが新しいステートの値としてまとめられます。
let tr = state.tr
console.log(tr.doc.content.size) // 25
tr.insertText("hello") // Replaces selection with 'hello'
let newState = state.apply(tr)
console.log(tr.doc.content.size) // 30
TransactionはTransformのサブクラスで、最初のドキュメントにステップを適用して新しいドキュメントを構築する方法を継承しています。これに加えて、トランザクションはセレクションや他のステートに関連する要素を監視し、replaceSelectionのようないくつかのセレクションに関連する便利なメソッドが得られます。
トランザクションを作成する最も簡単な方法は、エディタステートオブジェクトのtrゲッターを使うことです。これはステートをベースとした空のトランザクションを作成するので、ステップやその他の更新を追加できます。
デフォルトでは、古いセレクションはステップを通じてマッピングされ新しいセレクションを作成しますが、setSeelectionを使用して新しいセレクションを明示的に設定もできます。
let tr = state.tr
console.log(tr.selection.from) // → 10
tr.delete(6, 8)
console.log(tr.selection.from) // → 8 (前方に移動)
tr.setSelection(TextSelection.create(tr.doc, 3))
console.log(tr.selection.from) // → 3
同様に、ドキュメントやセレクションの変更によりアクティブなマークの配列が自動的にクリアされ、またsetStoredMarksかensureMarksメソッドによって設定されます。
最後に、scrollIntoViewメソッドを実行すると、次にステートが描画されるときに、セレクションがビューにスクロールされるようにできます。おそらくほとんどのユーザーアクションでこれを行いたいでしょう。
トランスフォームメソッドと同様に、多くのトランザクションメソッドはトランザクション自身を返すので、チェインに便利です。
Plugins
新しくステートを作るとき、利用するプラグインの配列を渡すことができます。これらはステートやそこから派生するステートに保存され、トランザクションの適用方法とステートの振る舞いに基づくエディタの動作の両方に影響を与えることができます。
プラグインはPluginクラスのインスタンスで、幅広い機能をモデル化できます。最もシンプルなものは、あるイベントに対応するためのいくつかのプロップをエディタビューに追加するだけです。より複雑なものではエディタに新しいステートを追加し、トランザクションに基づいてそれを更新できます。
プラグインを作成する際には、その動作を指定するオブジェクトを渡します。
let myPlugin = new Plugin({
props: {
handleKeyDown(view, event) {
console.log("キーが押された!")
return false // 何も処理しない
}
}
})
let state = EditorState.create({schema, plugins: [myPlugin]})
プラグインで自身のステートスロットが必要な場合、stateプロパティで定義できます。
let transactionCounter = new Plugin({
state: {
init() { return 0 },
apply(tr, value) { return value + 1 }
}
})
function getTransactionCount(state) {
return transactionCounter.getState(state)
}
この例のプラグインは、あるステートに適用されたトランザクションの数を単純に数えるという、非常にシンプルなステートのピースを定義しています。このヘルパー関数は、プラグインのgetStateメソッドを使用して、エディタステートオブジェクトからプラグインステートを取得します。
エディタステートはイミュータブルなオブジェクトであり、プラグインステートはそのオブジェクトの一部なので、プラグインステートの値もイミュータブルでなければなりません。すなわちプラグインステートのapplyメソッドは、それらが変更されるべき時に古いものを変更するのではなく新しい値を返さなければならず、他のコードはそれらを変更してはいけません。
プラグインがトランザクションに追加の情報を追加することはしばしば有用です。たとえば取り消し履歴は、実際に取り消しを実行するときに結果のトランザクションを保存します。プラグインがそれを見たとき、通常変更に対して行うこと(取り消しスタックに追加する)の代わりに、それを特別に扱い、取り消しスタックの一番上の項目を取り除き、代わりにこのトランザクションをやり直しスタックに追加するようにします。
この目的のために、トランザクションは自身にメタデータを添付できます。このように、マークされたトランザクションを数えないように、トランザクションカウンタープラグインを更新できます。
let transactionCounter = new Plugin({
state: {
init() { return 0 },
apply(tr, value) {
if (tr.getMeta(transactionCounter)) return value
else return value + 1
}
}
})
function markAsUncounted(tr) {
tr.setMeta(transactionCounter, true)
}
メタデータプロパティのキーには文字列を使用できますが、名前の衝突を避けるために、Pluginオブジェクトを使用することが推奨されます。たとえば addToHistory をfalseに設定するとトランザクションを取り消すことができなくなり、ペーストを処理するとエディタビューは結果のトランザクションの paste プロパティをtrueに設定するように、ライブラリによって意味が与えられている文字列キーがいくつかあります。
The view component
ProseMirrorのエディタビューは、利用者にエディタステートを表示し、その上で編集操作を行うためのユーザインターフェイスコンポーネントです。
編集操作の定義はかなり狭く、タイプ、クリック、コピー、ペースト、ドラッグなど、編集面との直接的なやりとりはできますが、それ以上のことはできません。つまり、メニューの表示やキーバインドなどは、コアビューコンポーネントの担当外であり、プラグインで対応する必要があります。
Editable DOM
ブラウザでは、DOMの一部を編集可能(contentEditable)にでき、フォーカスや選択を可能にします。エディタビューはそのドキュメントのDOM表現を作成し(デフォルトではスキーマのtoDOMメソッドを使用します)、それを編集可能にします。編集可能な要素がフォーカスされると、ProseMirrorはDOMのselectionがエディタステートでのセレクションと一致することを確認します。
また、多くのDOMイベントに対してイベントハンドラを登録し、イベントを適切なトランザクションに変換しています。たとえば、貼り付けを行う場合、貼り付けられたコンテンツはProseMirrorドキュメントスライスとしてパースされ、ドキュメントに挿入されます。
また、多くのイベントはそのまま通過させ、ProseMirrorのデータモデルの観点から再解釈されるだけです。たとえばブラウザはカーソルと選択範囲の配置に非常に長けているので(双方向テキストを考慮すると、これは本当に難しい問題です)、カーソルの動きに関連するキーとマウスアクションのほとんどはブラウザによって処理されます。その後、ProseMirrorは現在のDOMセレクションがどの種類のテキストセレクションに対応するものであるかをチェックします。もしそのセレクションが現在のセレクションと異なる場合は、セレクションを更新するトランザクションがディスパッチされます。
スペルチェックやモバイルの自動大文字入力などのネイティブの機能が壊れてしまうので、タイピングも通常はブラウザに任せます。ブラウザがDOMを更新すると、エディタはそれに気づき、ドキュメントの変更部分を再パースし、その差分をトランザクションに変換します。
Data flow
つまり、エディタビューは与えられたエディタステートを表示し、何かが起こるとトランザクションを作成し、これをブロードキャストするのです。このトランザクションは通常新しいステートを作成するために使用され、そのステートはupdateStateメソッドを使用してビューに与えられます。
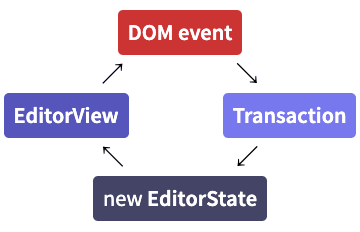
JavaScriptの世界では、多くの命令型イベントハンドラが複雑なデータフローの網を作る傾向がありますが、それとは対照的にこれは単純で周期的なデータフローを作成します。
dispatchTransactionプロパティでディスパッチされるトランザクションを「傍受」して、この周期的なデータフローをより大きな周期に配線することは可能です。
もしあなたのアプリがこのようなデータフローモデルを使用している場合、Reduxや同様のアーキテクチャと同様にProseMirrorのトランザクションをメインのアクションディスパッチサイクルに統合し、ProseMirrorのステートをアプリケーションの「ストア」に保持できます。
// アプリケーションのステート
let appState = {
editor: EditorState.create({schema}),
score: 0
}
let view = new EditorView(document.body, {
state: appState.editor,
dispatchTransaction(transaction) {
update({type: "EDITOR_TRANSACTION", transaction})
}
})
// updateオブジェクトを受け取る、粗いステート更新関数
// `appState` を更新し、UIを再読み込みする
function update(event) {
if (event.type == "EDITOR_TRANSACTION")
appState.editor = appState.editor.apply(event.transaction)
else if (event.type == "SCORE_POINT")
appState.score++
draw()
}
// さらに粗い描画機能
function draw() {
document.querySelector("#score").textContent = appState.score
view.updateState(appState.editor)
}
Efficient updating
updateStateを実装する1つの方法は、それが呼ばれるたびにドキュメントを単純に再描画することです。しかし大きなドキュメントの場合、それは本当に遅くなります。
更新時には、ビューは古いドキュメントと新しいドキュメントの両方にアクセスできるので、それらを比較し、変更されていないノードに対応するDOMの部分は残すことができます。ProseMirrorはこの処理を実施するので、通常の更新はほとんどコストをかけずに済みます。
入力されたテキストに対応する更新のようにブラウザ自身の編集操作によってすでにDOMに追加されているものもあり、この場合はDOMとステートの一貫性を確保するためにDOMを変更する必要はまったくありません(このような処理を行うトランザクションがキャンセルされたり何らかの方法で変更された場合、ビューはDOMの変更を元に戻してDOMとステートの同期を確保します)。
同様に、DOMのセレクションは実際にステートのセレクションと同期していないときのみ更新されます。これは、ブラウザがセレクションとともに保持しているさまざまな「隠れた」状態(たとえば、短い行を越えて下キーや上キーを押すと、次の長い行に入ったときに水平位置が元に戻る機能)を混乱させないようにするためのものです。
Props
'Props'は、Reactから取られた、やや曖昧ではあるが便利な用語です。プロップはUIコンポーネントのパラメータのようなものです。理想的には、コンポーネントが取得するプロップの集合はその動作を完全に定義します。
let view = new EditorView({
state: myState,
editable() { return false }, // readonlyの振る舞いを有効化
handleDoubleClick() { console.log("Double click!") }
})
そのため、現在のステートは1つのプロップとなります。コンポーネントを制御するコードがそれらを更新した場合など、他のプロップの値も時間の経過とともに変化することがありますが、コンポーネント自体はそれらを変更しないので、ステートとみなされることはありません。updateStateメソッドは、ステートプロップを更新するための単なる略語です。
プラグインはプロップを宣言できますが、ステートとdispatchTransactionは例外で、ビューに直接提供することだけが可能です。
function maxSizePlugin(max) {
return new Plugin({
props: {
editable(state) { return state.doc.content.size < max }
}
})
}
あるプロップが複数回宣言された場合、どのように処理されるかはプロップに依存します。一般的には直接提供されたプロップが優先され、その後に各プラグインが順番に対応します。domParserのようないくつかのプロップでは、最初に見つかった値が使用され他の値は無視されます。イベントを処理したかどうかを示すboolean値を返すハンドラ関数については、最初にtrueを返したものがイベントを処理することになります。最後に、属性(編集可能なDOMノードに属性を設定するために使用可能)や デコレーション(次のセクションで説明します)のようないくつかのプロップについては、提供されたすべての値の和が使用されます。
Decorations
デコレーションはビューがドキュメントを描画する方法をある程度制御できます。これらは、デコレーションプロップから値を返すことで作成され、3つのタイプがあります。
- ノードデコレーションは、1つのノードのDOM表現にスタイルやその他のDOM属性を追加します。
- ウィジェットデコレーションは、実際のドキュメントの一部ではないDOMノードを、指定されたポジションに挿入します。
- インラインデコレーションは、ノードデコレーションと同様に、指定された範囲内のすべてのインラインノードにスタイルや属性を追加します。
デコレーションを効率的に描画し比較するためには、デコレーションセット(実際のドキュメントのツリー形状を模倣したデータ構造)として提供される必要があります。デコレーションセットを作成するには、静的メソッド createを使用して、ドキュメントとデコレーションオブジェクトの配列を指定します。
let purplePlugin = new Plugin({
props: {
decorations(state) {
return DecorationSet.create(state.doc, [
Decoration.inline(0, state.doc.content.size, {style: "color: purple"})
])
}
}
})
デコレーションの数が多い場合、再描画のたびにその場でセットを再作成するのはコストがかかりすぎる可能性があります。このような場合デコレーションを維持する方法として推奨されるのは、プラグインのステートにセットを置き、変更時にそれをマッピングし、必要なときだけそれを変更することです。
let specklePlugin = new Plugin({
state: {
init(_, {doc}) {
let speckles = []
for (let pos = 1; pos < doc.content.size; pos += 4)
speckles.push(Decoration.inline(pos - 1, pos, {style: "background: yellow"}))
return DecorationSet.create(doc, speckles)
},
apply(tr, set) { return set.map(tr.mapping, tr.doc) }
},
props: {
decorations(state) { return specklePlugin.getState(state) }
}
})
このプラグインは、4番目のポジションごとに黄色い背景のインラインデコレーションを追加するデコレーションセットでステートを初期化します。これはあまり便利なものではありませんが、検索マッチや注釈付き領域を強調するような用途に似ています。
トランザクションがステートに適用されると、プラグインステートの applyメソッドはデコレーションセットを前方にマッピングし、デコレーションが所定のポジションにとどまり、新しいドキュメントの形状に「適合」するようにします。このマッピング方法はデコレーションセットのツリー形状を利用することで(典型的な局所的変更に対して)効率化されており、変更によって実際に触れるツリーの部分のみが再構築されるようになっています。
(実際のプラグインでは、applyメソッドは新しいイベントに基づいてデコレーションを追加または削除する場所でもあります。おそらくトランザクション内の変更を調べたり、トランザクションに添付されたプラグイン固有のメタデータに基づいて行います)
最後に、デコレーションプロップはプラグインのステートを返し、デコレーションをビューに表示させるだけです。
Node views
もう1つエディタビューの描画方法に影響を与える方法があります。ノードビューはドキュメント内の個々のノードに対して、小型のUIコンポーネントのようなものを定義することを可能にします。このビューでは、ノードのDOMをレンダリングし、ノードの更新方法を定義し、イベントに反応するカスタムコードを記述できます。
let view = new EditorView({
state,
nodeViews: {
image(node) { return new ImageView(node) }
}
})
class ImageView {
constructor(node) {
// エディタはここで指定したDOM表現を利用します
this.dom = document.createElement("img")
this.dom.src = node.attrs.src
this.dom.addEventListener("click", e => {
console.log("You clicked me!")
e.preventDefault()
})
}
stopEvent() { return true }
}
この例で定義されている画像ノード用のビューオブジェクトは、画像用の独自のDOMノードを作成し、イベントハンドラを追加し、 stopEvent メソッドでProseMirrorがそのDOMノードから来るイベントを無視することを宣言しています。
ノードとのインタラクションが、ドキュメント内の実際のノードに何らかの影響を与えたくなることがよくあるでしょう。しかしノードを変更するトランザクションを作成するには、まずそのノードがどこにあるのかを知る必要があります。そのために、ノードビューはドキュメント内の現在のポジションを問い合わせるために使用できるゲッター関数を渡せます。この例を修正して、ノードをクリックすると画像のaltテキストを入力するようにクエリするようにしてみましょう。
let view = new EditorView({
state,
nodeViews: {
image(node, view, getPos) { return new ImageView(node, view, getPos) }
}
})
class ImageView {
constructor(node, view, getPos) {
this.dom = document.createElement("img")
this.dom.src = node.attrs.src
this.dom.alt = node.attrs.alt
this.dom.addEventListener("click", e => {
e.preventDefault()
let alt = prompt("New alt text:", "")
if (alt) view.dispatch(view.state.tr.setNodeMarkup(getPos(), null, {
src: node.attrs.src,
alt
}))
})
}
stopEvent() { return true }
}
setNodeMarkupは、指定されたポジションのノードタイプまたは属性のセットを変更するために使用できるメソッドです。この例では、 getPos を使用して画像の現在のポジションを見つけ、新しいaltテキストを含む新しい属性オブジェクトを与えています。
ノードが更新されると、デフォルトの動作は、その外側のDOM構造をそのままにしてその子を新しい子のセットと比較し、必要に応じてそれらを更新または置換します。この動作はオーバーライドできるので、例えばコンテンツに基づいて段落のクラスを変更するようなことが可能になります:
let view = new EditorView({
state,
nodeViews: {
paragraph(node) { return new ParagraphView(node) }
}
})
class ParagraphView {
constructor(node) {
this.dom = this.contentDOM = document.createElement("p")
if (node.content.size == 0) this.dom.classList.add("empty")
}
update(node) {
if (node.type.name != "paragraph") return false
if (node.content.size > 0) this.dom.classList.remove("empty")
else this.dom.classList.add("empty")
return true
}
}
画像は(訳註:テキストなどの)コンテンツを持たないので、先ほどの例ではそのレンダリング方法について心配する必要はありませんでした。しかし段落にはコンテンツがあります。ProseMirrorライブラリにコンテンツを管理させることもできますし、完全に自身での管理もできます。contentDOMプロパティを指定すると、ライブラリはノードのコンテンツをその中にレンダリングし、コンテンツの更新を処理します。そうしない場合コンテンツはエディタにとってブラックボックスとなり、どのように表示しユーザーに操作させるかはすべてあなた次第になります。
この場合段落コンテンツは通常の編集可能なテキストのように動作させたいので、コンテンツは外部ノードに直接レンダリングする必要があり、 contentDOM プロパティは dom プロパティと一致するように定義されています。
マジックは updateメソッドで起こります。まず、このメソッドはノードビューを更新して新しいノードを表示するかどうかを決定する役割を果たします。この新しいノードはエディタの更新アルゴリズムがここに描画しようとするものである可能性があるので、このノードビューが処理できるノードかどうかを確認する必要があります。
この例の更新メソッドは、まず新しいノードが段落であるかどうかをチェックし、そうでない場合は離脱します。次に、新しいノードの内容に応じて empty クラスが存在するかどうかを確認し、更新が成功したことを示すtrueを返します(この時点でノードのコンテンツが更新されます)。
Commands
ProseMirrorの専門用語では、「コマンド」はユーザーが何らかのキーの組み合わせを押したり、メニューを操作することによって実行できる編集アクションを実装する関数です。
実用的な理由から、コマンドは少し複雑なインターフェースを持っています。単純に言えば、エディタステートとディスパッチ関数(EditorView.dispatchまたはトランザクションを受け取る他の関数)を受け取り、bool値を返す関数です。以下は非常に簡単な例です。
function deleteSelection(state, dispatch) {
if (state.selection.empty) return false
dispatch(state.tr.deleteSelection())
return true
}
コマンドが適用できないときはfalseを返して何もしません。適用可能な場合はトランザクションをディスパッチしてtrueを返さなければなりません。これはたとえばキーにバインドされたコマンドが適用されたときに、キーイベントのさらなる処理を停止するためにkeymapプラグインで使用されます。
コマンドを実際に実行することなく与えられたステートに対してコマンドが適用可能かどうかを問い合わせることができるように、 dispatch引数は非必須です。コマンドは、適用可能であるもののdispatch引数が与えられていないときには何もせずに単にtrueを返すべきです。つまりこの例のコマンドは実際には次のようになるはずです。
function deleteSelection(state, dispatch) {
if (state.selection.empty) return false
if (dispatch) dispatch(state.tr.deleteSelection())
return true
}
選択範囲を削除できるかどうかを調べるには deleteSelection(view.state, null) を呼び、実際にコマンドを実行するには deleteSelection(view.state, view.dispatch) のような処理をします。これは、メニューバーでどのメニュー項目をグレーアウトさせるかを決定するために使うことができます。
この形式ではコマンドは実際のエディタビューにアクセスできません。ほとんどのコマンドはそれを必要とせず、この方法でビューが利用できない設定に適用してテストができます。しかしいくつかのコマンドはDOMと相互作用する必要があります。与えられたポジションがテキストブロックの終わりであるかどうかを問い合わせる必要があったり、ビューに対して相対的に配置されたダイアログを開きたい場合などです。この目的のために、コマンドを呼び出すほとんどのプラグインは第3引数として全体のビューを渡します。
function blinkView(_state, dispatch, view) {
if (dispatch) {
view.dom.style.background = "yellow"
setTimeout(() => view.dom.style.background = "", 1000)
}
return true
}
この(かなり無駄な)例は、コマンドはトランザクションをディスパッチする必要がないことを示しています。それらはその副作用のために呼ばれます。
prosemirror-commands モジュールは、deleteSelection コマンドの変種のような単純なものからjoinBackward のようなやや複雑なものまで、多くの編集コマンドを提供します。またスキーマに依存しない多くのコマンドを、通常使用されるキーにバインドする基本的なキーマップも付属しています。
通常は1つのキーにバインドされている動作も可能な限り異なるコマンドに落とし込むのが良いです。ユーティリティ関数chainCommandsは複数のコマンドを組み合わせるために使用され、そのどれか1つがtrueを返すまで次々に試されます。
たとえば基本キーマップでは、backspaceをdeleteSelection(選択範囲が空でないときに実行)、joinBackward(カーソルがテキストブロックの先頭にあるとき)、およびselectNodeBackward(スキーマが通常の結合動作を禁止している場合に、選択範囲の前のノードを選択)にコマンドチェーンで結合しています。これらのどれにも当てはまらない場合、ブラウザは自身のbackspace処理を実行できます。これは、テキストブロック内のbackspaceに適切なものです(ネイティブのスペルチェックなどが混乱しないようにするため)。
たとえば、toggleMarkはマークの種類とオプションで属性を受け取り、現在の選択部分のマークをトグルするコマンド関数を返します。
他のモジュールでもコマンド関数をエクスポートするものがあります。たとえばhistoryモジュールのundoとredoなど。エディタをカスタマイズしたり、ユーザーが独自のドキュメントノードと対話できるようにするために、独自のカスタムコマンドを書きたい場合もあるでしょう。
Collaborative editing
リアルタイム共同編集は、複数の人が同じドキュメントを同時に編集できます。編集者が行った変更は直ちにローカルドキュメントに適用され、その後ピアに送信され、ピアはこれらの変更を自動的にマージします(手動で競合を解決する必要はありません)。
このガイドでは、ProseMirrorの共同編集機能がどのように配線しているかについて説明します。
Algorithm
ProseMirrorの共同編集システムは、変更を適用する順番を決定する中央機関を採用しています。2人の編集者が同時に変更した場合、2人ともこの中央機関に変更内容を報告することになります。中央機関はどちらかの変更を受け入れ、その変更をすべてのエディタに知らせます。もう一方の変更は受け入れられず、そのエディタはサーバーから新しい変更を受け取ると、ローカルの変更をもう一方のエディタからの変更の上にリベースして、再度投稿する必要があります。
The Authority
中央機関の役割は、実はかなり単純です。それは...
- 現在のドキュメントのバージョンを追跡する。
- 編集者からの変更を受け入れ、適用可能な場合は変更リストに追加する。
- 編集者があるバージョン以降の変更点を受け取る方法を提供する。
エディタと同じJavaScript環境で動作する些細な中央機関を実装してみましょう。
class Authority {
constructor(doc) {
this.doc = doc
this.steps = []
this.stepClientIDs = []
this.onNewSteps = []
}
receiveSteps(version, steps, clientID) {
if (version != this.steps.length) return
// 新しいステップを適用し、積み重ねる
steps.forEach(step => {
this.doc = step.apply(this.doc).doc
this.steps.push(step)
this.stepClientIDs.push(clientID)
})
// シグナルをリッスンする
this.onNewSteps.forEach(function(f) { f() })
}
stepsSince(version) {
return {
steps: this.steps.slice(version),
clientIDs: this.stepClientIDs.slice(version)
}
}
}
エディタが自分の変更を中央機関に提出しようとするとき、そのエディタは受信した最後のバージョン番号と、追加した新しい変更、そしてクライアントID(これはどの変更が自分から来たかを後で認識するための方法です)を渡して、その上で受信ステップを呼び出すことができます。
ステップが受け入れられると、中央機関は新しいステップが利用可能であることを通知するので、クライアントはそれに気づき、そして自分のステップを与えます。実際の実装では、最適化として receiveSteps がステータスを返し、送信されたステップを直ちに確認もできます。しかしここで使われているメカニズムは信頼性の低い接続での同期を保証するために必要なものなので、常にこれを基本ケースとして使用すべきです。
この中央機関の実装は、無限に増加するステップの配列を保持し、その長さは現在のバージョンを表します。
The collab Module
collabモジュールは、ローカルの変更を追跡し、リモートの変更を受信し、何かが中央機関に送信されなければならないときにそれを示すことを引き受けるプラグインを返すcollab関数をエクスポートします。
import {EditorState} from "prosemirror-state"
import {EditorView} from "prosemirror-view"
import {schema} from "prosemirror-schema-basic"
import collab from "prosemirror-collab"
function collabEditor(authority, place) {
let view = new EditorView(place, {
state: EditorState.create({
doc: authority.doc,
plugins: [collab.collab({version: authority.steps.length})]
}),
dispatchTransaction(transaction) {
let newState = view.state.apply(transaction)
view.updateState(newState)
let sendable = collab.sendableSteps(newState)
if (sendable)
authority.receiveSteps(sendable.version, sendable.steps,
sendable.clientID)
}
})
authority.onNewSteps.push(function() {
let newData = authority.stepsSince(collab.getVersion(view.state))
view.dispatch(
collab.receiveTransaction(view.state, newData.steps, newData.clientIDs))
})
return view
}
collabEditor 関数は、collabプラグインが読み込まれたエディタビューを作成します。ステートが更新されるたびに、中央機関に送信するものがあるかどうかをチェックし、それを送ります。
また、新しいステップが利用可能になったときに中央機関が呼び出すべき関数を登録し、それらのステップを反映するためにローカルのエディタステートを更新するトランザクションを作成します。
ステップのセットが中央機関によって拒否された場合、それらは、おそらくすぐに中央機関から新しいステップを受け取るまで、未確認のままとなります。その後、 onNewSteps コールバックはディスパッチを呼び出し、その dispatchTransaction 関数を呼び出すので、コードは再び変更を送信しようとします。
これがすべてです。もちろん、非同期データチャンネル(collabデモのロングポーリングやWeb Socketsなど)では、もう少し複雑な通信と同期のコードが必要になります。そしておそらく、メモリ消費量が際限なく増加しないように、中央機関がある時点でステップを捨て始めるようにしたくなるでしょう。しかし一般的なアプローチはこの小さな例で十分に説明できます。
Discussion