🦙
llama.cppを使って、EvoLLM-JP-v1-10Bを自分で量子化した手順
はじめに
SakanaAIから進化的モデルマージという手法を用いたAIモデルが複数公開されています。LLMモデルとしても7Bのモデルと、10Bのモデルが公開されています。
これをllama.cppを用いて実行するために8bitに量子化を試みました。
今回の環境
- Windows 11 Pro + WSL2(Ubuntu 22.04LTS)
- CUDA ... V12.3
- GPU ... RTX 4060 Ti 16GB
7Bモデルの量子化
llama.cppに含まれる convert.py を用いて、次のようにgguf形式に変換することができました。
$ python convert.py ../EvoLLM-JP-v1-7B
さらに8bitに量子化します。
$ ./quantize ../EvoLLM-JP-v1-7B/ggml-model-f16.gguf ../EvoLLM-JP-v1-7B/EvoLLM-JP-v1-7B-q8_0.gguf q8_0
これをllama.cppを使って実行すると、応答を得ることができました。
$ ./main-cuda -m '../EvoLLM-JP-v1-7B-q8_0.gguf' -p "### 指示: あなたは役立つアシスタントです。 ### 入力:富士山の高さは? ### 応答:" -n 256 --n-gpu-layers 50
(途中省略)
### 指示: あなたは役立つアシスタントです。 ### 入力:富士山の高さは? ### 応答:富士山の高さは3,776メートルです。 [end of text]
10Bモデルの量子化
gguf化のエラー
同様に10Bモデルをgguf形式に変換しようとすると、エラーが出て失敗してしまいます。
$ python convert.py ../EvoLLM-JP-v1-10B
→ ERROR
assert end - begin == math.prod(shape) * numpy_dtype.itemsize
どうやらデータのサイズが理論値と違うと言われているようです。
ヒント
Webで検索しても対策が見つからず途方に暮れていましたが、X(twitter)上でヒントを見つけました。どうもありがとうございます!
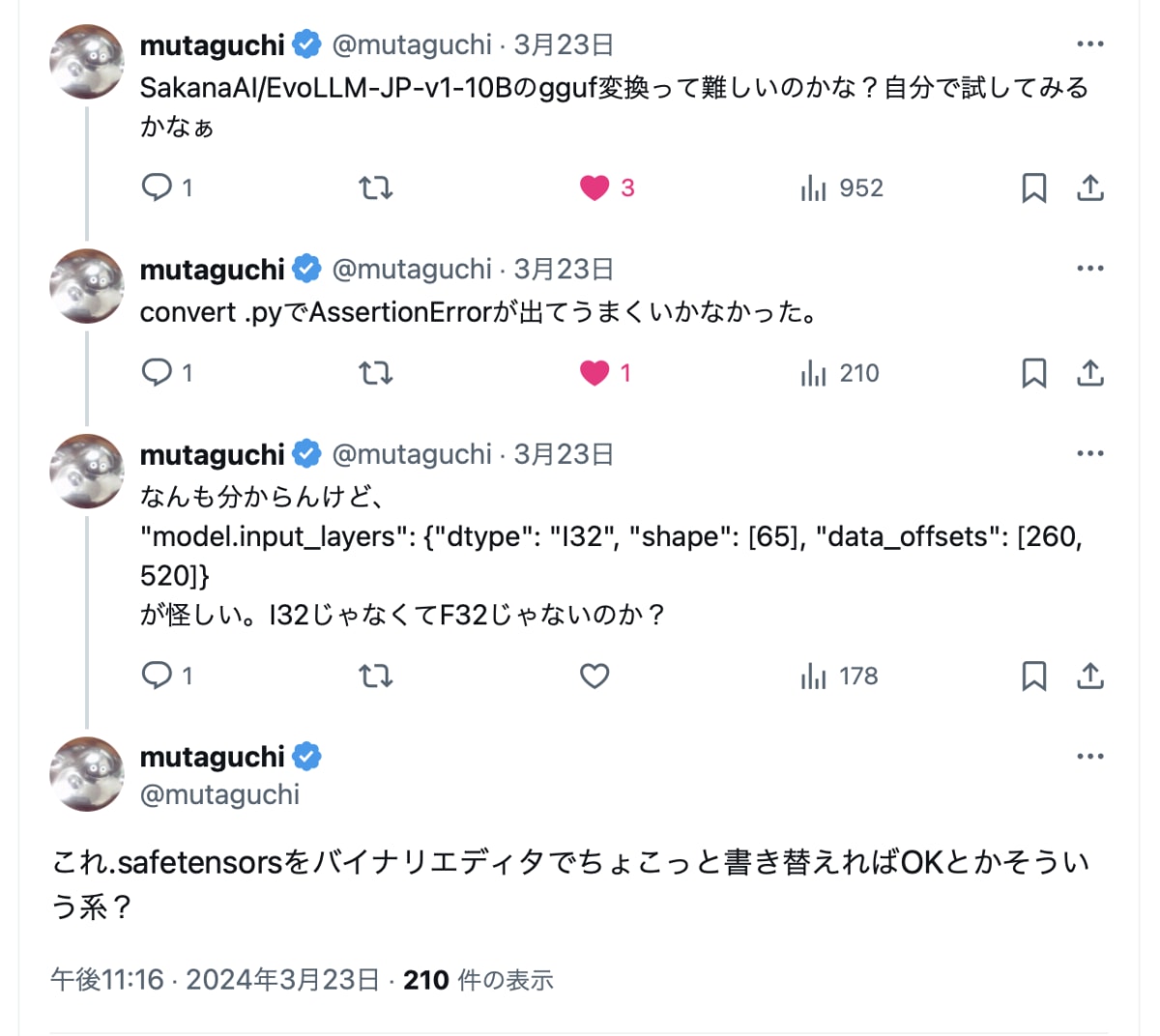
どうやらヘッダー情報に誤りがあり、バイナリエディタで書き換えてあげれば良さそうです。
バイナリの編集
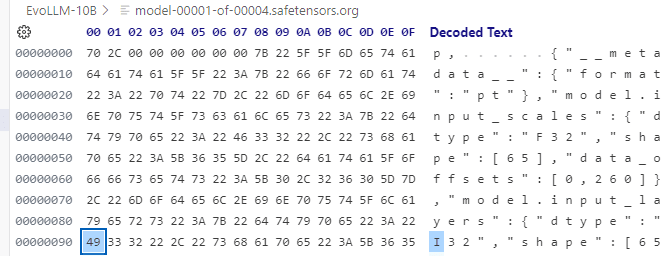
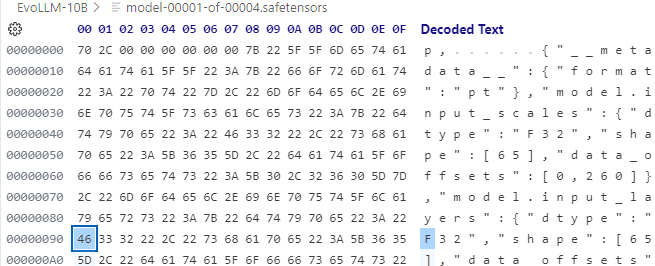
VS Code に Hex Editorという機能拡張を入れ、EvoLLM-JP-v1-10B/model-00001-of-00004.safetensors というファイルのヘッダー部分を次のように変更しました。(I32 → F32)
変更前
変更後
gguf 変換
改めてconvert.py を用いてgguf形式に変換します。そのままだと不明なモデルとのエラーが出るので、「--skip-unknown」オプションを指定することで変換できました。
$ python convert.py --skip-unknown ../EvoLLM-JP-v1-10B
さらに8bitに量子化します。
$ ./quantize ../EvoLLM-JP-v1-10B/ggml-model-f16.gguf ../EvoLLM-JP-v1-7B/EvoLLM-JP-v1-10B-q8_0.gguf q8_0
llama.cppの実行
$ ./main-cuda -m '../EvoLLM-JP-v1-10B-q8_0.gguf' -p "### 指示: あなたは役立つアシスタントです。 ### 入力:富士山の高さは? ### 応答:" -n 256 --n-gpu-layers 50
(途中省略)
### 指示: あなたは役立つアシスタントです。 ### 入力:富士山の高さは? ### 応答:富士山の高さは3776メートルで す。 [end of text]
無事動かすことができました。
終わりに
無事にEvoLLMの10Bモデルを量子化して動かすことができました。まさかLLM時代になってもバイナリエディタのお世話になるとは、ちょっとビックリです。
Discussion