クリーンアーキテクチャについて考える 後半
概要
前回クリーンアーキテクチャついて考えたので、実現するための構成を考える。
注意事項
今回、完璧なクリーンアーキテクチャの実現は目指しません。
理由としては、今回はワンオペに近い運営を想定しています。
(個人で作るもののために考えているのでご理解ください)
そのためチーム運営を考慮せずに、簡易的な実現を目指します。
構成検討

引用元:Clean Architecture 達人に学ぶソフトウェアの構造と設計
クリーンアーキテクチャで有名な構成図といえばこちらなはず。
今回APIのみの利用なので少し置き換えて考える必要があるが、この図を純粋に実装するのが大変なのでその点を課題点として挙げていく
データのやりとり
クリーンアーキテクチャでは、依存性の逆転の実現に目を向けがちではあるが、
レイヤー間のデータのやりとりもむずあkしい問題ではある。
先ほどの構成図を見ても
ControllerからInput DataとInput Boundaryと2種類でており、
UseCaseを介してParsenterに変えるのもOutput BoudaryとOubput Dataとなっており、
依然性が密にならないように個別に定義しなければいけない。
当然、Controllerの数があればその分宣言する必要もあるので実はかなりの労力になりやすい。
この点に関しては、クリーンアーキテクチャを採用するには覚悟する点でもあるのである程度必要だが、
採用にあたってはシンプルに採用する方針。
Entitiesの立ち位置
Entitiesとは何なのか?
実は、クリーンアーキテクチャではビジネスルールをカプセル化することも認められているし、データ構造の集合であることも認められている。
しかし、円の中心にいるために外の変更があったときに影響がないことも補償される必要がある。
具体的なことで考えるとユーザー情報を例にして考える。
ユーザー情報として
- ユーザーID
- ログインID
- パスワード
- 生年月日
を持ってるとする。
DBもこの構成のTableがあるものとしたときに
ユーザー情報にメールアドレス情報を追加することを考える
ユーザー情報に追加されないと他の処理で利用するときに使えないし、当然DBにもデータそして保管されている必要がある。
では、DBのユーザー情報Tableに登録日時の情報を追加するときはどうなるのか?
内部であつかうユーザー情報に必要かといわれるとそうではないでしょう。
データの種類的にもデータ管理面で必要なカラムであって、処理面では必要ない情報でしょう。
と内部で処理するのに必要な構造をもつものをEntitiesとして扱うことにする。
そのため、DBのTable構成とは別に扱うことにする。
これはTable構成の変更が直接ビジネスルールに影響を与えないことでワンオペによる作業ミスの予防策として採用した。
この辺りは、サービスにとってDBのデータと処理側での扱いの関係性で考えたほうがいい。
処理とDBのデータ関係が重要になるような分析系のシステムなら近くにしたほうが運用しやすくなるケースはあると思うし、複雑な分析時には別途Entitiesを用意するといったルールを採用してもいいと思う。
課題点を考慮して今回考える構成
作成してみた構成はこちら
今回APIでのみの利用なのでViewはなくしている。
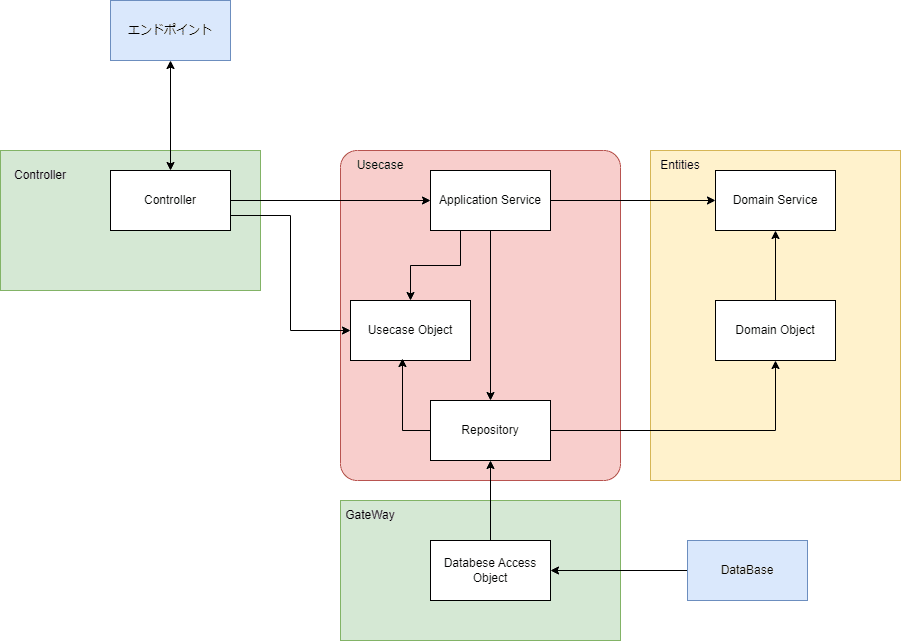
- レイヤー間のデータに関してはInputとOutputをまとめたUsercase Objectとして扱うこととした。
- 大量の構造体を用意せずにやり取り用の構造体を設けるようにしてできるようにした。
- Repositoryにもつながることを想定しており、共通にしてやり取りが行いやすくした。
- EntitiesはDomain ServiceとObjectを用意し、内部での処理に適した変換などもこちらに含める形にした。
- 問題点としは、変換処理は外のレイヤーの影響を受けやすいので依存性の逆転が崩れている要素でもあるので自覚して扱う必要がある。
- Table側の影響が直接内部処理に影響を与えないためにDatabase Access Objectを宣言し、DBの変更を直接受けない構成にした。
フォルダ構成
今回は以下のようなフォルダ構成で考えている。
app/
├── consts
├── controllers/
│ └── ci
├── entities
├── infra/
│ ├── database
│ ├── di
│ ├── logger
│ └── server
├── repositories/
│ └── ri
└── usecases/
└── ui
要点を整理すると
- controllers、repositories、usecasesは依存性の逆転のためInterfaceを記載する箇所をもうける。
- 1ファイルですべて宣言することも可能だが、Interfaceの特性を考えて別ファイルで宣言することにした。
- 命名はいろいろ考えてたが、usecase interfaceとして略してuiと扱うようにした。
- Interfaceは変更は具象側と比較すると少ないと思われるので1階層奥にしている。
- infra層に関して
- 一番外側の要因に対する設定を設ける場所にしている。
- databaseは今回ORMであるsqlboilerを使う要諦なので出力先としても採用している。
- constsフォルダ
- 定数の置き場として採用しているが、Entitiesにセットにしたほうが実用的な様子もあるのでここは様子見ではあります。
最後に
クリーンアーキテクチャについて軽く触れつつ、今回作るサービスのための構成に採用してみました。
最初に注意事項として書いていますが、厳密には正しいクリーンアーキテクチャではありません。
どちらかというとテストコードの書きやすさを考慮したものになっています。
しかし、完全に準拠したクリーンアーキテクチャの実装はできないという声もあるので
どの部分を許容するのか、採用しないのかをちゃんと考慮して選択する必要があるのだと感じました。
Discussion