OpenAI APIとLangChainを用いた記事の翻訳・要約メディアのつくり方
はじめに
この記事では、3日間でテック記事のAI要約・翻訳メディアをつくる個人開発で利用した
- OpenAI API
- LangChain
の具体的な実装と利用コストについて触れていきます。
OpenAI APIとLangChainとは...
OpenAI API
OpenAI APIは、OpenAIという人工知能の研究・開発・普及を目的とした団体が提供するAPIです。このAPI は、自然言語とコードの理解または生成を必要とするタスクに利用することができます。
LangChain
OpenAIが提供するGPT-3のような大規模言語モデル(Large Language Model: LLM)を利用してサービスの開発をしたいときに、「あるとうれしい機能」が集まったライブラリです。
この記事の目的
- OpenAI API を使った記事の要約とFunction Callingの紹介
- LangChain による長文の翻訳や要約方法の紹介
- ぜんぜん安い!利用コストの紹介
全体のシステム構成
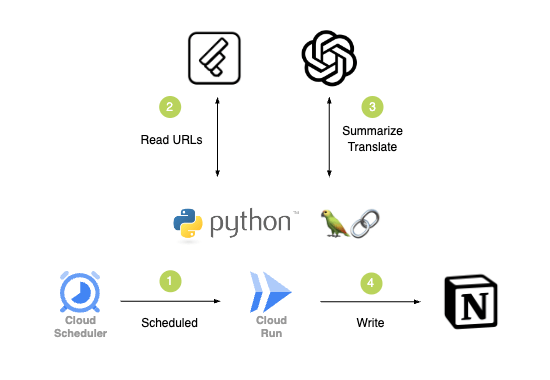
❶ 定期実行
Cloud Scheduler から一定間隔で Cloud RunにデプロイしたAPIにリクエストを行います。
❷ データソースの取得
- Python
- Feedly API
Feedly から翻訳・要約記事のデータソースとなるURLを取得します。
❸ 翻訳・要約記事の生成
- Python
- LangChain
- OpenAI API
URL先のページ内容を要約・翻訳し、メディア用の記事データを生成します。
ここではGPTのトークン制限の対応や生成結果のJSON化などを行います。
今回はこちらについての具体的な実装について触れていきます。
❹ 生成した記事の保存とUI
- Python
- Notion API
- Notion Database
記事データを入稿します。
翻訳・要約記事の生成方法
まずは完成系のコード
URL先のページ内容を要約・翻訳し、メディア用の記事データをJSONとして生成するコードです。
import json
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
import openai
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import SeleniumURLLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains.summarize import load_summarize_chain
from langchain.docstore.document import Document
openai_api_key = "OPENAI_API_KEY"
openai.api_key = openai_api_key
llm = ChatOpenAI(model_name="gpt-3.5-turbo-16k",
temperature=0,
openai_api_key=openai_api_key)
app = FastAPI()
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
class Query(BaseModel):
url: str
@app.post("/generate/article")
def generate_article_test(query: Query):
try:
content = load_content(query.url)
summarized = summarize(content)
serialized = serialize(summarized)
return serialized
except Exception as e:
raise HTTPException(
status_code=400, detail=f"Failed to generate: {e}")
def load_content(url) -> str:
urls = [url]
try:
loader = SeleniumURLLoader(urls=urls)
data = loader.load()
first_or_none = next(iter(data), None)
if first_or_none and first_or_none.page_content:
return first_or_none.page_content
else:
raise ValueError
except Exception as e:
raise e
def summarize(content: str) -> str:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=3600,
chunk_overlap=100,
)
texts = text_splitter.split_text(content)
docs = [Document(page_content=t) for t in texts]
chain = load_summarize_chain(llm, chain_type='map_reduce')
summarized: str = chain.run(docs)
# Summarize by AI
prompt_summary = f"""
下記の文章から「タイトル」「新機能や改善点」「タグ」を抽出し、日本語で出力してください。
----------
{summarized}
"""
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k",
messages=[
{"role": "system", "content": prompt_summary},
]
)
summary = response.choices[0].message.content
# Description by AI
prompt_description = f"""
下記の文章から「解説」「ITサービスや導入例の提案」「重要度」を抽出し、日本語で出力してください。
----------
{summarized}
"""
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k",
messages=[
{"role": "system", "content": prompt_description},
]
)
description = response.choices[0].message.content
answer = "{}\n{}".format(summary, description)
return answer
def serialize(content: str) -> any:
prompt = f"""
下記の内容から、メディアの入稿データ用にフォーマットをしてください。
----------
{content}
"""
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k",
messages=[
{"role": "system", "content": prompt},
],
functions=[
{"name": "set_definition", "parameters": schema}
],
function_call={"name": "set_definition"},
)
answer = response.choices[0].message.function_call.arguments
dict = json.loads(answer)
return dict
# 例
schema = {
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"properties": {
"title": {
"type": "string"
},
"categories": {
"type": "array",
"items": {
"type": "string"
}
},
"key_points": {
"type": "array",
"items": {
"type": "string"
}
},
"suggestions": {
"type": "array",
"items": {
"type": "string"
}
}
},
"required": [
"title",
"categories",
"key_points",
"suggestions",
]
}
下記のコマンドをターミナル等から実行すると、FastAPIを起動できます。
uvicorn main:app --reload
url に任意のURLをリプレイスし、CURLコマンドでAPIを実行できます。
curl --location 'http://127.0.0.1:8000/generate/article' \
--header 'Content-Type: application/json' \
--data '{
"url": "https://blog.hogehoge/fugafuga/" # 要約・翻訳元記事のURL
}'
結果がJSONで出力されることが確認できます。
urlにhttps://cloud.google.com/blog/products/identity-security/how-sensitive-data-protection-can-help-secure-generative-ai-workloads/?hl=enを指定した時の例です。
{
"title": "グーグルのセンシティブデータ保護機能についての紹介",
"categories": [
"センシティブデータ保護",
"個人情報保護",
"プライバシー規制",
"プロンプトインジェクション攻撃",
"Vertex AI",
"ファウンデーションモデルのカスタマイズ"
],
"key_points": [
"センシティブデータ保護機能を使用することで、組織は個人情報や機密情報を保護できる。",
"様々なデータ変換メソッドとプライバシー規制への準拠も提供されている。",
"プロンプトインジェクション攻撃への保護の必要性と、ファウンデーションモデルのカスタマイズにはVertex AIが利用できることも言及されている。"
],
"suggestions": [
"Google Sensitive Data Protectionは、個人情報や機密情報の保護を支援するサービスです。",
"組織はこのサービスを利用して、機密情報を検出・変換し、文脈を保ったまま保護することができます。",
"さまざまなデータ変換手法とプライバシー規制の遵守を提供しており、プロンプトインジェクション攻撃に対する保護の必要性も考慮されています。",
"また、ファウンデーションモデルのカスタマイズにはVertex AIが利用できるとされています。"
]
}
URLからHTMLデータの取得
LangChainにはいくつかのDocument Loaderクラスが存在します。
- UnstructuredURLLoader
- SeleniumURLLoader
- PlaywrightURLLoader
後者ふたつは、JavaScriptでレンダリングが必要なページもロードすることができます。
今回はSeleniumURLLoader を利用しました。
from langchain.document_loaders import SeleniumURLLoader
def load_content(url) -> str:
urls = [url]
try:
loader = SeleniumURLLoader(urls=urls)
data = loader.load()
first_or_none = next(iter(data), None) # ① 解説に記載
if first_or_none and first_or_none.page_content:
return first_or_none.page_content
else:
raise ValueError
except Exception as e:
raise e
解説
①:first_or_none = next(iter(data), None)
Loaderに対してURLは複数渡すことができ、戻り値を受け取るdataも複数(List[Document]型)になります。そのため、ここでは、List[Document]型であるdataの値をiter()でイテレータに変換したあとnext()で取り出しています。値がない場合は初期値のNoneを与えています。
要約と翻訳
URLから取得したデータを要約するために、OpenAIに渡します。
ただ要約と翻訳をさせるだけなら、下記のようにOpenAIライブラリのみで完結します。
import openai
openai.api_key = "OPENAI_API_KEY"
model_name = "gpt-3.5-turbo"
def summarize(content: str) -> str:
prompt_summary = f"""
下記のWebページ内のコンテンツを要約し日本語で出力してください。
----------
{content}
"""
response = openai.ChatCompletion.create(
model=model_name,
messages=[
{"role": "system", "content": prompt_summary},
]
)
summary = response.choices[0].message.content
return summary
要約・翻訳元の文章が短いケースは、これでも十分です。
ですが、テック系ブログの中にはリリースノートなど、とりわけ文章量が多い記事があります。
それらをOpenAIで処理する際に問題になるのが、トークン制限です。
OpenAI APIは、テキストの長さに関する「トークン」の上限が設定されており、この上限を超えるとエラーが発生します。
トークン制限(長い文章)の対応
すぐに取り入れられそうな対応方法は、下記でした。
- 言語モデルの変更
- 長い文章を分割(チャンク)して要約する
- プロンプトの指示を分ける
言語モデルの変更
最大トークン数は、OpenAI のモデルごとに異なります。
-
gpt-4MAX 8,192 tokens -
gpt-4-32kMAX 32,768 tokens -
gpt-3.5-turboMAX 4,097 tokens -
gpt-3.5-turbo-16kMAX 16,385 tokens
最大トークン数と料金との兼ね合いから、今回はgpt-3.5-turboとgpt-3.5-turbo-16kを併用し、長い文章を処理する際は後者を指定していました。
モデルごとの使用料金表はこちらに記載があります。
しかし、モデルの変更だけではリリースノート系の長文には太刀打ちできませんでした。
長い文章を分割(チャンク)して要約
LangChain には、文章をチャンクするためのいくつかのText splitterがあります。
今回は、公式でデフォルト推奨されているRecursiveCharacterTextSplitterを用いています。
下記のコードでは、長文であるcontentを
-
TextSplitterを用いて一定サイズごとにチャンク(分割) -
load_summarize_chainにより、チャンクをそれぞれ要約 - 要約した各チャンクをひとつにまとめて再要約して出力
という処理を行っています。
from langchain.chat_models import ChatOpenAI
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains.summarize import load_summarize_chain
from langchain.docstore.document import Document
llm = ChatOpenAI(model_name="gpt-3.5-turbo",
temperature=0,
openai_api_key="OPENAI_API_KEY")
def summarize(content: str) -> str:
# ① 解説に記載
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=3600,
chunk_overlap=100,
)
texts = text_splitter.split_text(content)
docs = [Document(page_content=t) for t in texts]
chain = load_summarize_chain(llm, chain_type='map_reduce')
summarized: str = chain.run(docs)
# ...次項につづく
解説
①:RecursiveCharacterTextSplitter
chunk_size: チャンクの最大文字数
chunk_overlap: チャンク間の最大オーバーラップ文字数
今回はそれぞれ、チャンク後の要約に利用するgpt-3.5-turboモデルの最大トークン数4,097 tokensを考慮して設定しています。
プロンプトの指示を分ける
今回個人開発したサービスでは、要約・翻訳元の記事について
- タイトル
- 要点を箇条書き
- 関連しそうなキーワードタグ
- 非エンジニアにもわかるような補足
- 記事の内容が役立ちそうなITサービスや導入例の提案
- 記事の重要度(5つの指標を与えて算出)
- AIの感想(ネタ枠)
という項目もGPTにて生成していました。
こういったプロンプト内の指示に当たる文章自体も、トークンを消費する要因になります。
そのため、項目別にタスクを分けて処理し、出力結果を結合することにしました。
def summarize(content: str) -> str:
# ...前項のつづき
# 要約タスク 1
prompt_summary = f"""
下記の文章から「タイトル」「新機能や改善点」「タグ」を抽出し、日本語で出力してください。
----------
{summarized}
"""
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k",
messages=[
{"role": "system", "content": prompt_summary},
]
)
summary = response.choices[0].message.content
# 要約タスク 2
prompt_description = f"""
下記の文章から「解説」「ITサービスや導入例の提案」「重要度」を抽出し、日本語で出力してください。
----------
{summarized}
"""
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k",
messages=[
{"role": "system", "content": prompt_description},
]
)
description = response.choices[0].message.content
answer = "{}\n{}".format(summary, description) # ① 解説に記載
return answer
解説
①:answer = "{}\n{}\n{}".format(summary, description)
生成結果のsummary、descriptionの文字列を結合しています。
入稿データ用にJSONシリアライズ
最終的にすべての出力結果であるcontentをもとに、JSONシリアライズを行います。ここで用いるのがOpenAI APIのFunction Callingです。
下記のJSONスキーマは例ですが、開発に利用したスキーマは、ChatGPTにて生成しました。
def serialize(content: str) -> any:
prompt = f"""
下記の内容から、メディアの入稿データ用にフォーマットをしてください。
----------
{content}
"""
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k",
messages=[
{"role": "system", "content": prompt},
],
functions=[
{"name": "set_definition", "parameters": schema}
],
function_call={"name": "set_definition"},
)
answer = response.choices[0].message.function_call.arguments
dict = json.loads(answer)
return dict
# 例
schema = {
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"properties": {
"title": {
"type": "string"
},
"categories": {
"type": "array",
"items": {
"type": "string"
}
},
"key_points": {
"type": "array",
"items": {
"type": "string"
}
},
"suggestions": {
"type": "array",
"items": {
"type": "string"
}
}
},
"required": [
"title",
"categories",
"key_points",
"suggestions",
]
}
GPTの利用コスト
このサービスをリリースして約2週間になりますが、289記事の生成で、GPTの利用料金は12.33ドルでした。
また、最も費用が高かった日で0.8ドルで、40記事の要約と翻訳を行っていました。
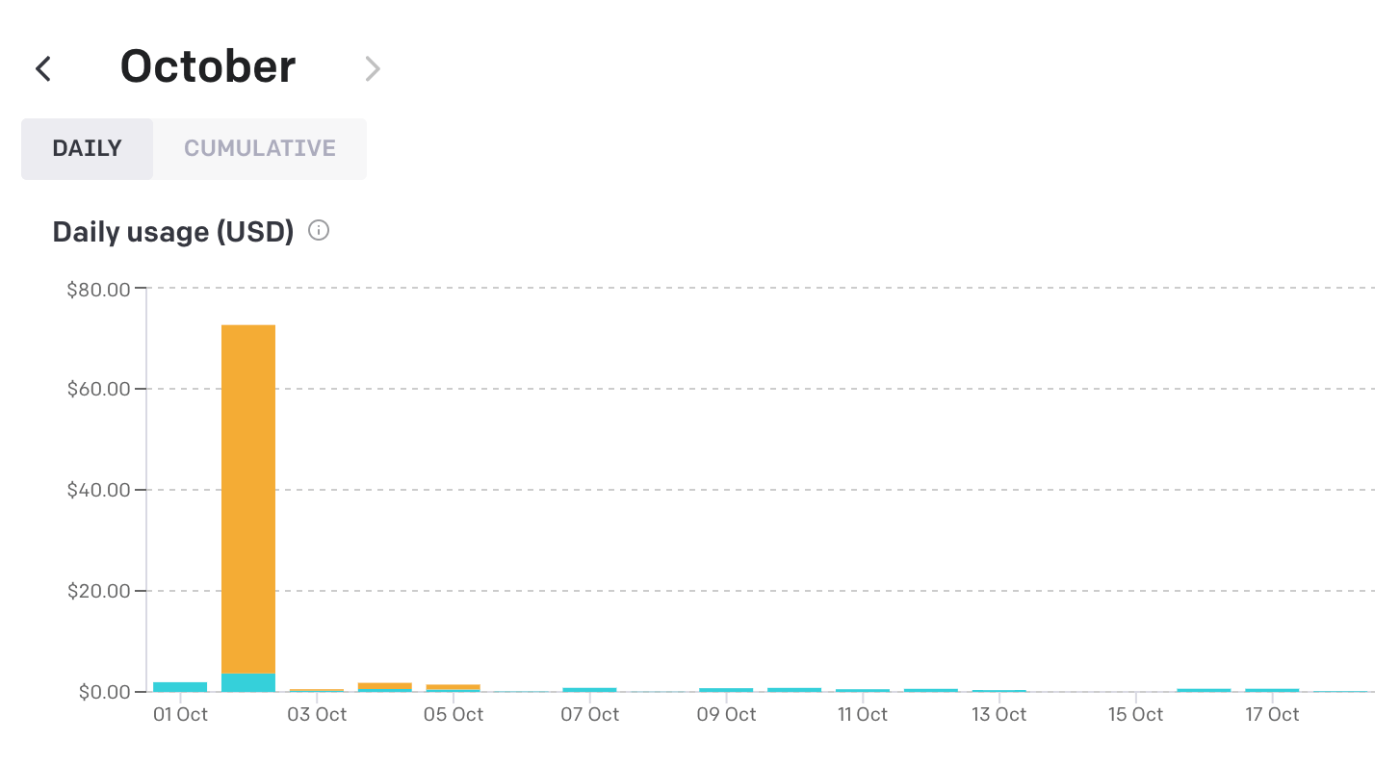
なお、10月2日にコストが跳ね上がっていますが、後述しました開発中のミスになります😿
10月5日時点で不具合修正を行って以降は、コストは安定して毎日1ドル以下です。
以上です🎉
ありがとうございました。
Discussion