StabilityAIのJapanese StableLM Alpha 7BをGoogle Colabフリープランで試す




概要
Stable DiffusionなどでおなじみのStabilityAIが、8/10に公開したブログにて新しいLLMであるJapanese StableLM Alphaを発表しました。
ブログから引用すると以下のように説明されています。
Stability AI Japan は70億パラメータの日本語向け汎用言語モデル「Japanese StableLM Base Alpha 7B」及び、指示応答言語モデル「Japanese StableLM Instruct Alpha 7B」を一般公開しました(略して「JSLM」)。これらのモデル はベンチマークスイート「lm-evaluation-harness」による複数の日本語タスクを用いた性能評価において、一般公開されている日本語向けモデルで最高の性能を発揮しています。
重要な点として、日本語向けに学習されているモデルという点です。なので、日本語を扱う私たちにとってもとても使いやすいモデルとなっていることが期待できます。
ということで、今回はこれを試してみたのでその紹介記事です。
実際に実行した様子は以下になります。
ただ、普通に利用するとGoogle Colabの無料プランではメモリが足らずに動かせなかったのですが、StabilityAIの中の人が、フリープランでも動くColabを公開してくれています。今回はこれを利用して推論するところを紹介します。
ちなみに結論を先に書いてしまうと、8bit量子化モデルを用いることでフリープランでも実行可能になっています。
ツイートは以下です。
Google Colabを実行する
では実際に実行してみましょう。ステップはそんなに多くありません。
実行の準備
まずはツイートにあるリンクを開きます。
開いたら、まずはランタイムがGPUになっていることを確認します。
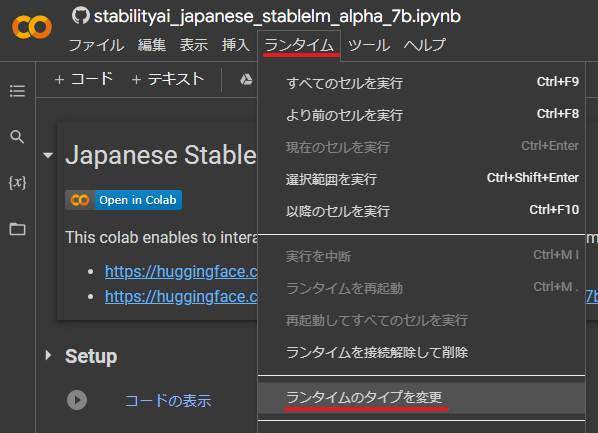
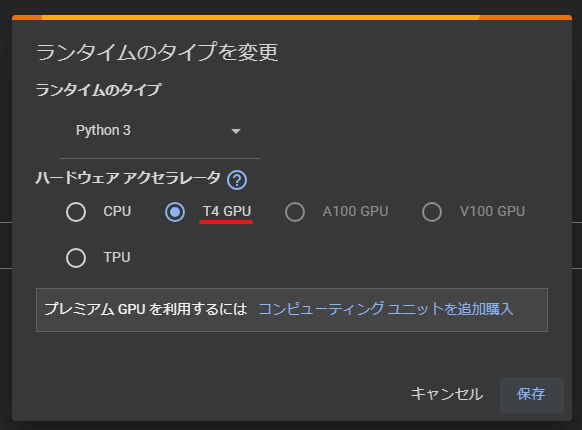
T4 GPU になっていなかったら変更して保存してください。
トークンの準備
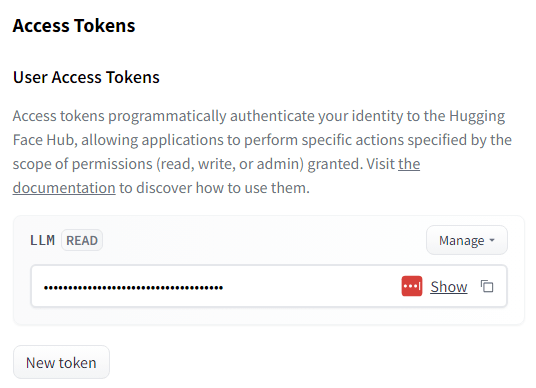
モデルのダウンロードにHuggingFaceを利用するため、事前にアカウントを作成しトークンを発行しておきます。
トークンは以下のページから発行できます。
アカウントを作成し、上記ページから New token を発行すると以下のように表示されるのでこれをコピーしておきます。
モデルのアクセス権の取得
今回のデモを実行する上で、HaggingFaceのモデルへのアクセス権を取得する必要があります。
モデルページにアクセスして、事前にアクセス権を得ておいてください。
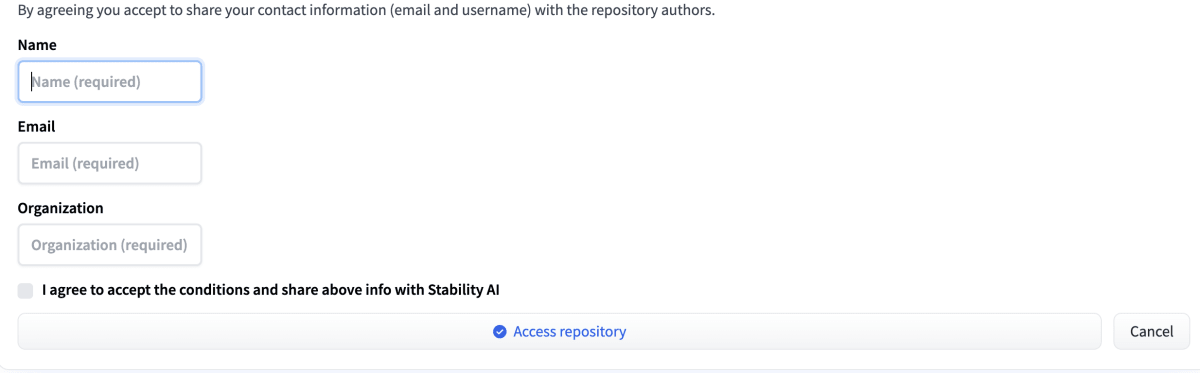
アクセス権をリクエストするフォーム
セットアップ
準備が終わったら実際に実行していきましょう。
まずは上2つの「Setup」と「Login HuggingFace」を実行します。
左側の(▶)を上から順番にクリックして実行します。
下のセルを実行するとHaggingFaceのトークンの入力を求められるので、先ほどコピーしておいたトークンを貼り付けます。
ちょっと分かりづらいが、 Token: の横がInput Fieldになっている
Token: の横がInput Fieldになっているのでクリックすると入力することができるようになります。そこにトークンを入力してEnterキーを押すとValidationされ、問題がなければ次の質問( Add token as git credential? )が表示されます。

これは n を入力します。(同様に、質問の横がInput Fieldになっています)
その後、ログイン成功のメッセージが出ればセットアップ完了です。
モデルの読み込み
続いて Load model のセルを実行します。
項目はデフォルトのままでOKです。
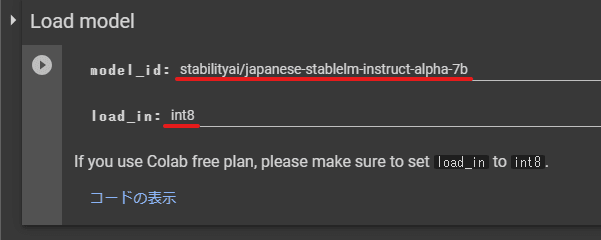
実行してしばらくするとモデルのダウンロードと読み込みが終わります。終了したら最後のセルを実行します。
実行する
最後のセルを実行します。少しすると以下のようなWebインターフェースが現れます。
表示されたら好きにメッセージを入力してみてください。
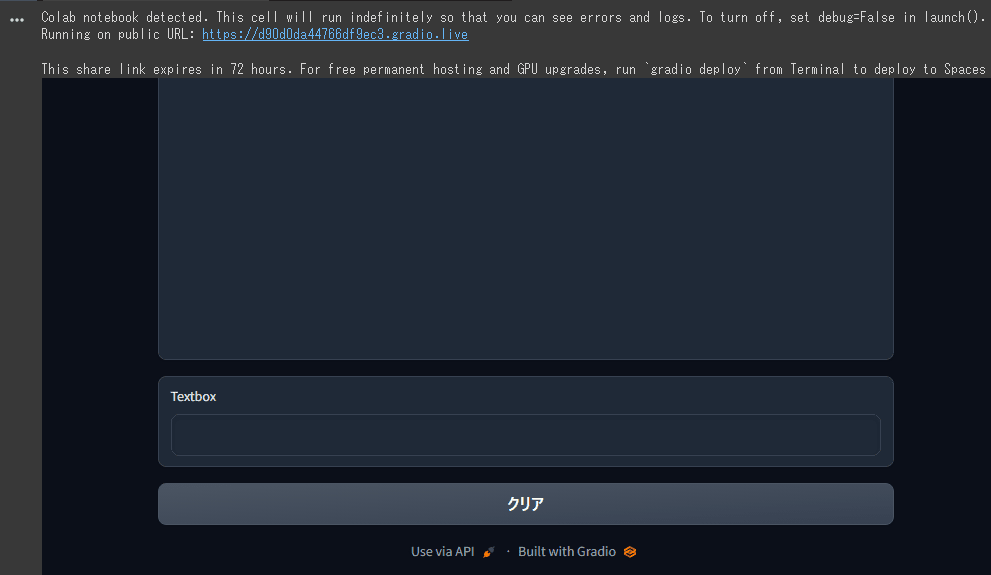
冒頭で紹介した、自分が実際に試した動画を再掲します。
しっかりと受け答えができているのが分かりますね。
コードを読んでみる
テックブログなので少しだけコードを読んでみましょう。
といっても、だいぶ短いコードでこれを実現しています。モデルの読み込みなどはHaggingFaceを利用しているのでとても簡単です。ありがたいですね。
モデルの読み込みコード
まずはモデルの読み込み部分です。
# @title Load model
import torch
from transformers import LlamaTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"device: {device}")
model_id = "stabilityai/japanese-stablelm-instruct-alpha-7b" # @param ["stabilityai/japanese-stablelm-base-alpha-7b", "stabilityai/japanese-stablelm-instruct-alpha-7b"]
load_in = "int8" # @param ["fp32", "fp16", "int8"]
# @markdown If you use Colab free plan, please make sure to set `load_in` to `int8`.
model_kwargs = {"trust_remote_code": True, "device_map": "auto", "low_cpu_mem_usage": True}
if load_in == "fp16":
model_kwargs["variant"] = "fp16"
mddel_kwargs["torch_dtype"] = torch.float16
elif load_in == "int8":
model_kwargs["variant"] = "int8"
model_kwargs["load_in_8bit"] = True
tokenizer = LlamaTokenizer.from_pretrained("novelai/nerdstash-tokenizer-v1", additional_special_tokens=['▁▁'])
model = AutoModelForCausalLM.from_pretrained(model_id, **model_kwargs)
if load_in != "int8":
model.to(device)
model.eval()
ちなみに冒頭でインポートしている transformers がHuggingFaceが提供してくれているモジュールで、HuggingFaceのページで以下のように説明されています。
🤗 Transformers provides APIs and tools to easily download and train state-of-the-art pretrained models.
これによって簡単にモデルの読み込みや利用ができるというわけなんですね。
特に注目すべきところは model_id と load_in です。最初の model_id は今回試しているJapanese StableLMのモデルを指定しています。そして load_in で、これは読み込むモデルの精度を表しています。一番精度が高いのが fp32(単精度浮動小数点)で、次に fp16(半精度浮動小数点)、最後に int8(8bit量子化)となります。
最後の8bit量子化については浮動小数点を整数に丸めるため、誤差などが出てしまいますが、精度を犠牲にして省メモリで実行できるようにすることができます。
モデルの8bit整数の量子化(int8の意味)
こちらのサイトから引用すると以下のように説明されていました。
モデルの量子化
量子化とは、深層学習モデルを変換して、パラメータと計算をより低い精度で使用するプロセスです。従来、DNN のトレーニングと推論は、IEEE 単精度浮動小数点形式に依存しており、32 ビットを使用して浮動小数点モデルの重みとアクティベーションテンソルを表していました。詳細については、自動混合精度 (Automatic Mixed Precision, AMP) を参照してください。ほとんどの DNN は、データセンターやクラウドで、NVIDIA V100 や A100の GPU を使用してトレーニングを行っているため、この計算リソースはトレーニング時には許容できるかもしれません。しかし、デプロイ時には、これらのモデルは、エッジでの計算リソースと電力予算がはるかに小さいデバイス上で実行する必要があります。フル 32 ビット表現を使用して DNN 推論を実行することは、エッジの計算、メモリ、電力の制約を考えると、リアルタイム解析には実用的ではありません。
モデルの構造やパラメータの数を犠牲にせずに計算リソースを削減するために、より低い精度で推論を実行することができます。当初、量子化推論はテンソルと重みを 16 ビットの浮動小数点数 (FP16) で表現した半精度で実行されていました。これにより、約 1.2~1.5 倍の計算量の節約になりましたが、まだ利用できる計算リソースとメモリ帯域幅に改善できる余地が残っていました。この代わりに、モデルはさらに低い精度で量子化され、重みとテンソルは 8 ビットの整数表現に用います。これにより、モデルのメモリ容量は 4 倍小さくなり、スループットは約 2~4 倍速くなりました。
8 ビット量子化は、計算とメモリリソースを節約するために魅力的ですが、損失の大きいプロセスです。量子化の際には、小さな範囲の浮動小数点数を一定数の情報範囲に絞り込みます。その結果、情報が失われます。
もともと 32 ビット表現で解決できた微細な違いは、8 ビット表現では同じ範囲に量子化されてしまうために失われてしまいます。これは、分数を整数として表現するときに遭遇する丸め誤差のようなものです。より低い計算精度で推論を行う際に精度を維持するためには、このような情報の損失に起因する誤差を軽減するように努めることが重要です。
デモ実行コード
こちらが実際にデモを行っているコードです。
# @title **Do the Run!**
# @markdown You can try Japanese StableLM Alpha 7B in chat-like UI.
# @markdown <br>**Remark:** this is single-turn inference, i.e., previous contexts are ignored.
import gradio as gr
def build_prompt(user_query, inputs="", sep="\n\n### "):
sys_msg = "以下は、タスクを説明する指示と、文脈のある入力の組み合わせです。要求を適切に満たす応答を書きなさい。"
p = sys_msg
roles = ["指示", "応答"]
msgs = [": \n" + user_query, ": "]
if inputs:
roles.insert(1, "入力")
msgs.insert(1, ": \n" + inputs)
for role, msg in zip(roles, msgs):
p += sep + role + msg
return p
@torch.no_grad()
def base_inference_func(prompt, max_new_tokens=128, top_p=0.95, repetition_penalty=1.):
print(f"PROMPT:\n{prompt}")
input_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
output_ids = model.generate(
input_ids.to(model.device),
do_sample=True,
max_new_tokens=max_new_tokens,
top_p=top_p,
temperature=1,
repetition_penalty=repetition_penalty,
)
generated = tokenizer.decode(output_ids.tolist()[0][input_ids.size(1):], skip_special_tokens=True).strip()
print(f"generated: {generated}")
return generated
def inference_func(message, chat_history, additional_prompt, max_new_tokens=128, top_p=0.95, repetition_penalty=1.):
# Infer with prompt without any additional input
user_inputs = {
"user_query": message,
"inputs": additional_prompt,
}
prompt = build_prompt(**user_inputs)
generated = base_inference_func(prompt, max_new_tokens, top_p, repetition_penalty)
chat_history.append((message, generated))
return "", chat_history
with gr.Blocks() as demo:
with gr.Accordion("Configs", open=False):
if "instruct" in model_id:
additional_prompt = gr.Textbox(label="additional_prompt")
max_new_tokens = gr.Number(value=128, label="max_new_tokens", precision=0)
top_p = gr.Slider(0.0, 1.0, value=0.95, step=0.01, label="top_p")
repetition_penalty = gr.Slider(0.0, 5.0, value=1.1, step=0.1, label="repetition_penalty")
if "instruct" in model_id:
chatbot = gr.Chatbot()
msg = gr.Textbox()
clear = gr.Button("Clear")
msg.submit(inference_func, [msg, chatbot, additional_prompt, max_new_tokens, top_p, repetition_penalty], [msg, chatbot])
clear.click(lambda: None, None, chatbot, queue=False)
else:
with gr.Row():
with gr.Column():
prompt = gr.Textbox(label="prompt")
button = gr.Button(label="submit")
with gr.Column():
out = gr.Textbox(label="generated")
button.click(base_inference_func, [prompt, max_new_tokens, top_p, repetition_penalty], out)
if __name__ == "__main__":
demo.launch(debug=True, share=True, show_error=True)
最後のセルのコードがデモ用のコードですね。頭の部分で gradio をインポートしています。
gradioは、こうした機械学習のモデルをすばやく簡単に実行できるようにしてくれる、Webインターフェースのモジュールです。
サイトの説明を引用すると以下のように書かれていました。
Gradio is the fastest way to demo your machine learning model with a friendly web interface so that anyone can use it, anywhere!
自分も、Stable Diffusionを利用するときはAUTOMATIC1111のWebUIを利用して実行していますが、そこでもこれが使われています。とても便利です。
「実行する」のところで出てきたWebインターフェースがまさにこれで実行されているわけですね。
推論実行コード
下半分ほどはWebインターフェース構築のためのものです。上半分が推論を行う、デモのコードになります。
そのデモ用コードを見ていきましょう。
推論のエントリポイントはメッセージ送信時に実行される inference_func です。
def inference_func(message, chat_history, additional_prompt, max_new_tokens=128, top_p=0.95, repetition_penalty=1.):
# Infer with prompt without any additional input
user_inputs = {
"user_query": message,
"inputs": additional_prompt,
}
prompt = build_prompt(**user_inputs)
generated = base_inference_func(prompt, max_new_tokens, top_p, repetition_penalty)
chat_history.append((message, generated))
return "", chat_history
ユーザの入力を元にプロンプトを生成しているのが分かります。
プロンプト生成は以下のようになっています。
def build_prompt(user_query, inputs="", sep="\n\n### "):
sys_msg = "以下は、タスクを説明する指示と、文脈のある入力の組み合わせです。要求を適切に満たす応答を書きなさい。"
p = sys_msg
roles = ["指示", "応答"]
msgs = [": \n" + user_query, ": "]
if inputs:
roles.insert(1, "入力")
msgs.insert(1, ": \n" + inputs)
for role, msg in zip(roles, msgs):
p += sep + role + msg
return p
OpenAIのAPIを使ったことがある人であれば、その利用の雰囲気に似ていることが分かります。基本的には自然言語でメッセージを構築するので当たり前と言えば当たり前ですが。
プロンプトを生成したら、 base_inference_func で推論を実行しています。
def base_inference_func(prompt, max_new_tokens=128, top_p=0.95, repetition_penalty=1.):
print(f"PROMPT:\n{prompt}")
input_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
output_ids = model.generate(
input_ids.to(model.device),
do_sample=True,
max_new_tokens=max_new_tokens,
top_p=top_p,
temperature=1,
repetition_penalty=repetition_penalty,
)
generated = tokenizer.decode(output_ids.tolist()[0][input_ids.size(1):], skip_special_tokens=True).strip()
print(f"generated: {generated}")
return generated
実際にモデルを実行しているのは以下の部分ですね。
output_ids = model.generate(
input_ids.to(model.device),
do_sample=True,
max_new_tokens=max_new_tokens,
top_p=top_p,
temperature=1,
repetition_penalty=repetition_penalty,
)
とても少ないコードでモデルの読み込みから利用までできるのはとてもすばらしいですね。
LLMの精度はモデルに依存するので、読み込むモデルを変えることで様々に変化させられるのも面白い点です。
興味があればぜひ色々試してみてください。
利用時の注意点
StabilityAIが発表したLMには2種類のモデルがあります。
上のモデル(Japanese StableLM Base Alpha 7B)は商用利用も可能になっている一方、下のほう(Japanese StableLM Instruct Alpha 7B)は研究目的での利用に限定されている点に注意が必要です。
ブログから引用すると以下のように説明されています。
Japanese StableLM Base Alpha 7Bは商用利用可能なApache License 2.0での公開となります。Japanese StableLM Instruct Alpha 7Bは研究目的で作成されたモデルであり、研究目的での利用に限定した公開となります。詳細は Hugging Face Hub のページをご確認ください。
最後に
ChatGPTから始まり、いまやたくさんのLLMが巷にあふれています。今回のモデルもそうですが、ある程度スペックは必要ではあるものの、ローカルで動くものも少なくありません。
そして、いずれモバイル上で動くモデルが出てきて、それが当たり前になるのは自然な流れでしょう。(Apple GPTなんていう噂もあります。ローカルで動くかは分かりませんが)
モバイル上で動くことができるようになり、かつセキュリティなどが担保されていれば、SF映画にあるような、自分にパーソナライズされたLLMが登場するのも時間の問題でしょう。
これからの時代、プログラマであっても、いやむしろプログラマこそAIの力を借りてアプリケーションを作っていくのは必須だと考えています。
さらに言えば、AIそのものをアプリケーションに組み込むことも当たり前になるでしょう。
そうした未来に向けて、今から色々とAIに触れて知見をためていきたいですね。
エンジニア絶賛募集中!
MESONではUnityエンジニアを絶賛募集中です! 空間コンピューティングのプロジェクトに関わってみたい! 開発したい! という方はぜひご応募ください!
MESONのメンバーページからご応募いただくか、TwitterのDMなどでご連絡ください。
書いた人

比留間 和也(あだな:えど)
カヤック時代にWEBエンジニアとしてリーダーを務め、その後VRに出会いコロプラに転職。 コロプラでは仮想現実チームにてXRコンテンツ開発に携わる。 DAYDREAM向けゲーム「NYORO THE SNAKE & SEVEN ISLANDS」をリリース。その後、ARに惹かれてMESONに入社。 MESONではARエンジニアとして活躍中。
またプライベートでもAR/VRの開発をしており、インディー部門でTGSに出展など公私関わらずAR/VRコンテンツ制作に精を出す。プライベートな時間でも開発しているように、新しいことを学ぶことが趣味で、最近は英語を学んでいる。
MESON Works
MESONの制作実績一覧もあります。ご興味ある方はぜひ見てみてください。
Discussion