
概要
世界に衝撃を与えたChatGPT。先日、そのAPIが公開されました。自分の観測範囲内でも、日々新しいアイデアとともに様々な機能が実装されています。 その自然なやり取りだけにとどまらず、情報の整理や概要説明など本当に色々なことができるので驚きですね。
今回はそんなChatGPT APIを利用してAIと音声で会話する方法について書いていきたいと思います。
ちなみにこれを利用してVR上で会話してみたのが以下の動画です。(今回はVRの話はしません。VR化は普通のVR開発と変わらないので) VR上で会話してみると没入感が半端ないです。PCVRが実行できる環境がある方はぜひVR化して会話してみてください。
今回はこの動画のようなことを実現するための方法についてまとめています。大きく以下の手順で解説していきます。
- ChatGPT APIへのリクエスト
- APIへ投げるリクエストを音声認識から得る
- レスポンスを音声合成APIに投げて音声化する
おもしろアイデア
解説に入っていく前に、自分が見かけたいくつかのおもしろアイデアを紹介します。
どれもとても面白いですよね。そしてChatGPTの可能性を感じさせてくれるものばかりです。
開発環境
まずはざっくり開発環境から。今回は以下の環境で開発しています。
- Windows 10
- Unity 2022.1.0f1
今回の実装はWindowsのPCVR前提となります。
Androidも音声認識エンジンがあるのでそれを利用することもできますが、今回はそちらは解説しません。Androidの音声認識部分をプラグイン化して利用する方法については自分の個人ブログに記事があるのでぜひそちらを参照してみてください。
これを利用して実際に動かしているのが以下の動画です。
上の動画は音声合成対応にはなっていないバージョンですが、今回解説するのはGCPのText to Speechを利用するためAndroidでも問題なく動作します。
ChatGPT環境のセットアップ
ではまずはじめに、ChatGPTのAPIを利用する部分から見ていきましょう。
OpenAIにSign up
まずはSign upしてアカウントを取得します。以下のURLにアクセスし、右上のSign upボタンを押して登録します。

API Keyの取得
Sign upができたら右上のメニューから「View API Keys」を選択してAPI Keyの取得を行います。
最初はキーがないので「Create new secret key」ボタンを押して新しくキーを作成します。作成したらそれをコピーしておきます。

ChatGPT APIへリクエストを投げてレスポンスを受け取る
次にChatGPT APIへリクエストを投げてレスポンスを受け取る処理を見ていきましょう。
curlを用いて動作確認
まずは curl を使って結果が得られるか確認してみます。
仕様については以下です。
サンプルコードを引用すると以下です。 <YOUR_API_KEY> のところに前述したAPI Keyを貼り付けます。
curl https://api.openai.com/v1/chat/completions \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer <YOUR_API_KEY>' \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Hello!"}]
}'
上記リクエストが成功すると以下のようなレスポンスが返ってきます。
{
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "\n\nHello there, how may I assist you today?",
},
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21
}
}
もしエラーが表示されたらそのエラー内容に従って解消してください。ここがクリアできればUnityからも普通にAPIを叩くことができます。
UnityからChatGPTのAPIを叩く
次に、UnityからAPIを叩く方法について見ていきます。
今回の実装は、ねぎぽよしさんの以下の記事を参考にさせていただきました。ありがとうございます。
APIの仕様を把握する
ChatGPTのWebサービスを利用したことがある人であれば、コンテキストを理解して会話してくれることを知っていると思います。
(例えば「その」役割はなに? みたいな代名詞を使っても会話が成り立つ、みたいな)
これを実現するにはAPIに過去の会話の内容をすべて(あるいは一部を)含める必要があります。APIの場合はその前までのコンテキストがリクエストごとに消失してしまうのでそのための対処ということでしょう。
APIのリクエストフォーマットを見ると以下のように示されています。(Pythonでの例です)
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
import openai
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
見てもらうと分かる通り、Request Bodyのパラメータとして messages と複数形になっていて配列を渡しているのが分かります。これが「会話の履歴」ということですね。
ドキュメントにもこう記載があります。
Including the conversation history helps when user instructions refer to prior messages. In the example above, the user’s final question of “Where was it played?” only makes sense in the context of the prior messages about the World Series of 2020. Because the models have no memory of past requests, all relevant information must be supplied via the conversation. If a conversation cannot fit within the model’s token limit, it will need to be shortened in some way.
特にここに記載があるように、
the user’s final question of “Where was it played?” only makes sense in the context of the prior messages about the World Series of 2020.
「どこで行われた試合?」というだけの質問に対しても適切に回答しているのは、その前の会話で「Who won the world series in 2020?」というのがあるゆえの回答というわけですね。
また興味深いのが、role に system と書くとそれは設定として扱われるという点です。これによりある程度ボットの性格や役割、返答のニュアンスなどを伝えることができます。
C#でリクエストを構築する
上記の仕様を踏まえた上で、実際に今回の実装で利用したコードを見ていきましょう。
以下はボットの方向性を決めるためのメッセージです。 role が system になっていますね。これによって、「これは質問ではなく、システムへの入力である」ということを明示することができます。
今回はUnityちゃんにしゃべってもらおうと思ったので、Unityちゃんぽく、女の子が話すように指示しています。
_mesasgeList.Add(new ChatGPTMessage
{
role = "system",
content = "Unityチャンっぽく、女の子が話すように振る舞ってください。(言葉には出さずに)",
});
初期化のタイミングで指示内容をメッセージに含めています。 role が system になっているので事前インプットになるわけですね。
感情も教えてもらう
実は今回の実装で少しだけ工夫している点があります。その工夫とは、返されたテキストの内容に応じて表情を変える、というものです。
具体的にどう実装しているかというと、以下のように事前情報をインプットしています。
_mesasgeList.Add(new ChatGPTMessage
{
role = "system",
content = "返答内容の感情を示す内容を、「喜・怒・哀・楽」の4文字から1文字だけ選択して文章の一番最後に次の例のように追加してください。例:<<嬉>>",
});
具体的には、返された内容の感情度合いを「喜怒哀楽」の4つの漢字からひとつを選択してもらうようにしています。加えて、プログラム側で判別しやすいようにフォーマットも指定しています。
例えば返信内容が「嬉しい」内容だった場合は、返信内容の末尾に <<嬉>> というパラメータが付与されて返ってくるわけです。そしてこれを受け取った際に感情データとして利用しつつ、このパラメータを削除して返信内容としています。
ちなみに前述したように、APIに投げる内容はすべて配列にして渡す必要があるため _messageList は List<T> 型の変数で、ここに上記システムメッセージを含めた会話履歴を蓄積していってAPIに投げるわけです。
APIにリクエストを投げる
では実際にリクエストを投げる部分の抜粋を見てみます。
public async UniTask<ChatGPTResponse> Talk(string message)
{
// 考え中を示す吹き出しを表示
_thinkingBalloon.SetActive(true);
// APIに投げるテキストを追加
_mesasgeList.Add(new ChatGPTMessage
{
role = "user",
content = message,
});
// リクエストオブジェクトを生成
// messagesには前述の通り、会話履歴を保持したListを指定する
var options = new ChatGPTRequest()
{
model = "gpt-3.5-turbo",
messages = _mesasgeList,
};
// JSON化
var jsonOptions = JsonUtility.ToJson(options);
using var request = new UnityWebRequest(s_apiUrl, "POST")
{
uploadHandler = new UploadHandlerRaw(Encoding.UTF8.GetBytes(jsonOptions)),
downloadHandler = new DownloadHandlerBuffer(),
};
// APIに必要なヘッダ設定
var headers = new Dictionary<string, string>
{
{ "Authorization", "Bearer " + _apiKey },
{ "Content-type", "application/json" },
{ "X-Slack-No-Retry", "1" }
};
foreach (var header in headers)
{
request.SetRequestHeader(header.Key, header.Value);
}
// APIに送信
await request.SendWebRequest();
// レスポンスが来たら、考え中アイコンを消す
_thinkingBalloon.SetActive(false);
if (request.result == UnityWebRequest.Result.ConnectionError ||
request.result == UnityWebRequest.Result.ProtocolError)
{
Debug.LogError(request.error);
throw new Exception();
}
// レスポンスオブジェクトを生成
string responseString = request.downloadHandler.text;
ChatGPTResponse response = JsonUtility.FromJson<ChatGPTResponse>(responseString);
Debug.Log($"CHatGPT: {response.choices[0].message.content}");
// 感情情報とテキスト情報を分離
EmotionData emotionData = EmotionData.Parse(response.choices[0].message.content);
_serif.text = emotionData.Message;
// 取得した返信を、音声合成APIに投げる
AudioClip clip = await _textToSpeech.Request(_serif.text);
// 取得した音声データを設定して再生する
_audioSource.clip = clip;
_audioSource.Play();
// 表情データに応じて表情を変える
_emotion.Change(emotionData.EmotionType);
// 履歴に最後のレスポンスを追加する
_mesasgeList.Add(response.choices[0].message);
return response;
}
特にむずかしいことはしていませんね。大雑把に処理を概観すると、
- 質問したいテキストをリストに追加
- JSON化してAPIに送信
- レスポンスを(次に備えて)追加
- 続けてレスポンス内容を音声合成APIに投げて再生
という流れです。
リクエストとレスポンス用の構造体
今回のリクエスト・レスポンスで利用している構造体のコードも載せておきます。
[Serializable]
public class ChatGPTMessage
{
public string role;
public string content;
}
[Serializable]
public class ChatGPTRequest
{
public string model;
public List<ChatGPTMessage> messages;
}
[Serializable]
public class ChatGPTResponse
{
public string id;
public string @object;
public int created;
public Choice[] choices;
public Usage usage;
[Serializable]
public class Choice
{
public int index;
public ChatGPTMessage message;
public string finish_reason;
}
[Serializable]
public class Usage
{
public int prompt_tokens;
public int completion_tokens;
public int total_tokens;
}
}
感情を把握する
前述の通り、レスポンスの内容の感情を漢字で表すようにしてもらっているので、そのデータを使って表情が変えられるようにします。
具体的には以下のようにしました。
private static readonly Dictionary<string, EmotionType> _mapping = new Dictionary<string, EmotionType>()
{
{ "喜", EmotionType.Happy },
{ "怒", EmotionType.Anger },
{ "哀", EmotionType.Sorrow },
{ "楽", EmotionType.Fun },
};
public static EmotionData Parse(string text)
{
MatchCollection matches = Regex.Matches(text, s_pattern);
string message = text;
foreach (Match match in matches)
{
message = message.Replace(match.Value, "");
}
EmotionType emotionType = EmotionType.Unknown;
if (matches.Count != 0)
{
string emotionTypeString = matches[0].Groups[1].Value;
if (_mapping.ContainsKey(emotionTypeString))
{
emotionType = _mapping[emotionTypeString];
}
}
return new(message, emotionType);
}
正規表現を用いて「喜怒哀楽」の漢字を抜き出し、さらにMaaping用の Dictionary から、対応する Enum の値を取り出して設定しています。あとはこれを利用して表情の変化に適用してやればいいわけです。
音声認識
次は音声認識について見ていきましょう。今回は nityEngine.Windows.Speech を利用しました。
そこまで長くないのでまずは全文を掲載します。
using System;
using UnityEngine;
using UnityEngine.Windows.Speech;
public class WindowsSpeechRecognizer : MonoBehaviour, ISpeechRecognizer
{
private DictationRecognizer _dictationRecognizer;
private void Start()
{
_dictationRecognizer = new DictationRecognizer();
_dictationRecognizer.DictationResult += (text, confidence) =>
{
Debug.LogFormat("Dictation result: {0}", text);
StopRecognizer();
OnResulted?.Invoke(new SpeechRecognizerResult(text));
};
_dictationRecognizer.DictationHypothesis += (text) =>
{
Debug.LogFormat("Dictation hypothesis: {0}", text);
};
_dictationRecognizer.DictationComplete += (completionCause) =>
{
if (completionCause != DictationCompletionCause.Complete)
{
Debug.LogErrorFormat("Dictation completed unsuccessfully: {0}.", completionCause);
}
StopRecognizer();
OnResulted?.Invoke(default);
};
_dictationRecognizer.DictationError += (error, hresult) => { Debug.LogErrorFormat("Dictation error: {0}; HResult = {1}.", error, hresult); };
foreach (var device in Microphone.devices)
{
Debug.Log($"Device Name: {device}");
}
}
#region ### ------------------------------ ISpeechRecognizer interface ------------------------------ ###
public event Action<SpeechRecognizerResult> OnResulted;
public bool IsRecognizing { get; private set; }
public void StartRecognizer()
{
Debug.Log("Start recognizing.");
IsRecognizing = true;
_dictationRecognizer.Start();
}
public void StopRecognizer()
{
Debug.Log("Stop recognizing.");
IsRecognizing = false;
_dictationRecognizer.Stop();
}
#endregion ### ------------------------------ ISpeechRecognizer interface ------------------------------ ###
}
ISpeechRecognizer と、インターフェース化しているのは、Android版の場合は別実装になるためです。
音声認識エンジンのセットアップ
Unity標準の機能を利用するため、実装は非常にシンプルです。エラーハンドリングなど細かな点はありますが、セットアップしている大事な部分は以下のところです。
_dictationRecognizer = new DictationRecognizer();
_dictationRecognizer.DictationResult += (text, confidence) =>
{
Debug.LogFormat("Dictation result: {0}", text);
StopRecognizer();
OnResulted?.Invoke(new SpeechRecognizerResult(text));
};
DictationRecognizer のインスタンスを生成し、そのコールバックを受け取れるように設定しているだけですね。音声認識して結果が得られるとこのコールバックが呼ばれます。
認識開始
今回はインターフェース化しているため、外部から StartRecognizer() メソッドが呼ばれると音声認識開始です。
public void StartRecognizer()
{
Debug.Log("Start recognizing.");
IsRecognizing = true;
_dictationRecognizer.Start();
}
_dictationRecognizer.Start() を実行するだけです。
音声認識部分はとてもシンプルですね。得られた結果はただのテキストなので、前述のChatGPTのAPIへそれをそのまま送れば音声認識したことへの返答を得ることができます。
最後に、得られた結果を音声合成してしゃべってもらいましょう。
音声認識に失敗する場合
場合によってはWindowsの設定で音声認識が無効化されていることがあります。その場合は「設定アプリ」から以下の設定を確認してください。
スタートメニューから起動します。
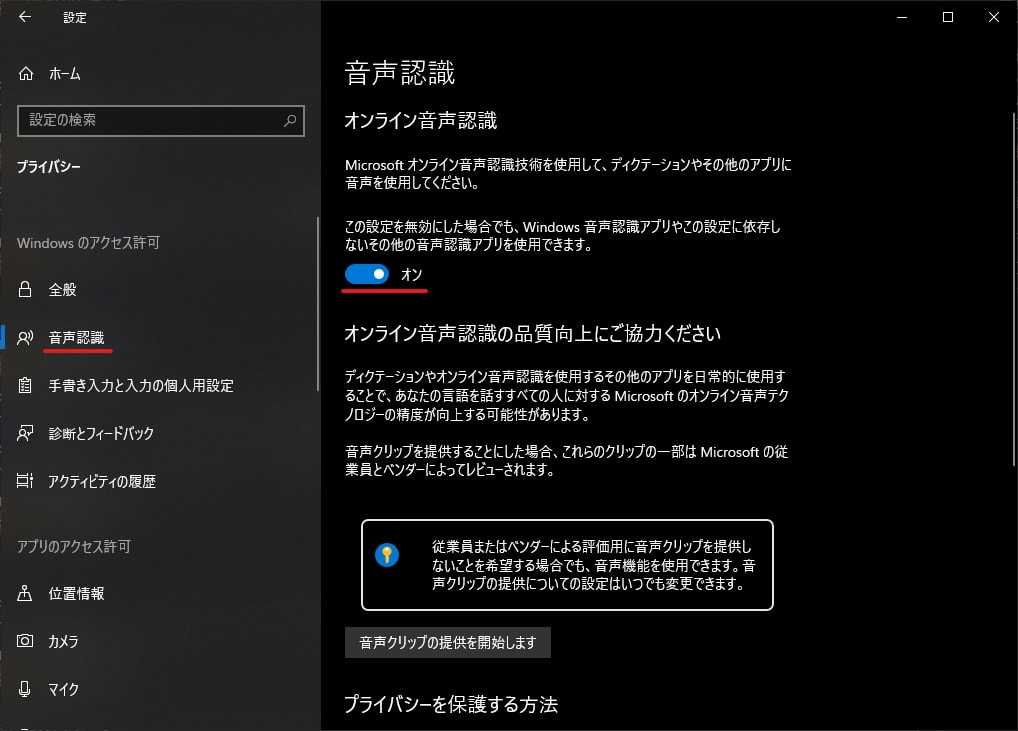
プライバシー設定に項目があります。
音声合成
今回の音声合成はGoogle CloudのText to Speechを利用しました。
Text to Speechを有効化する
初めて利用する場合は該当のAPIを有効化する必要があります。コンソールへ移動し、ライブラリへ移動します。
そして「Text to Speech」を検索します。
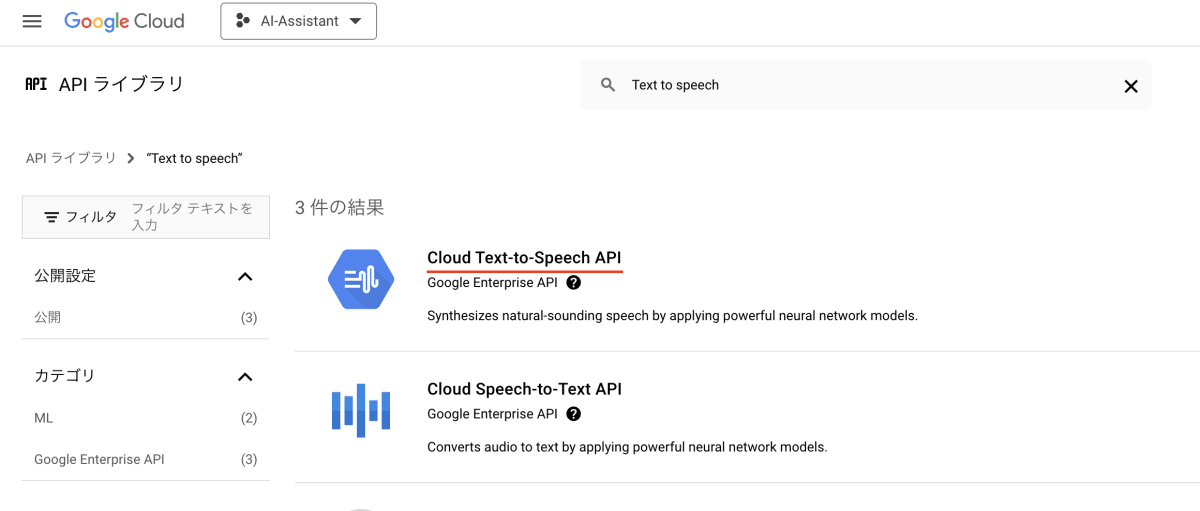
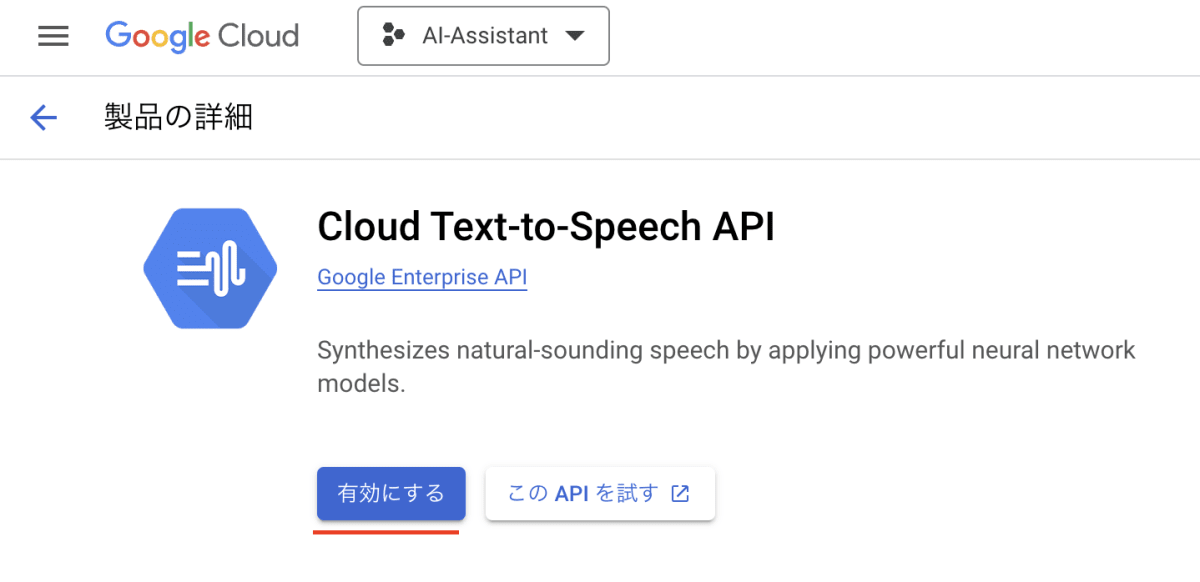
対象APIを有効化します。
API Keyを発行する
コンソールから、認証情報ページを開き「認証情報を作成 > APIキー」を選択してAPI Keyを作成します。
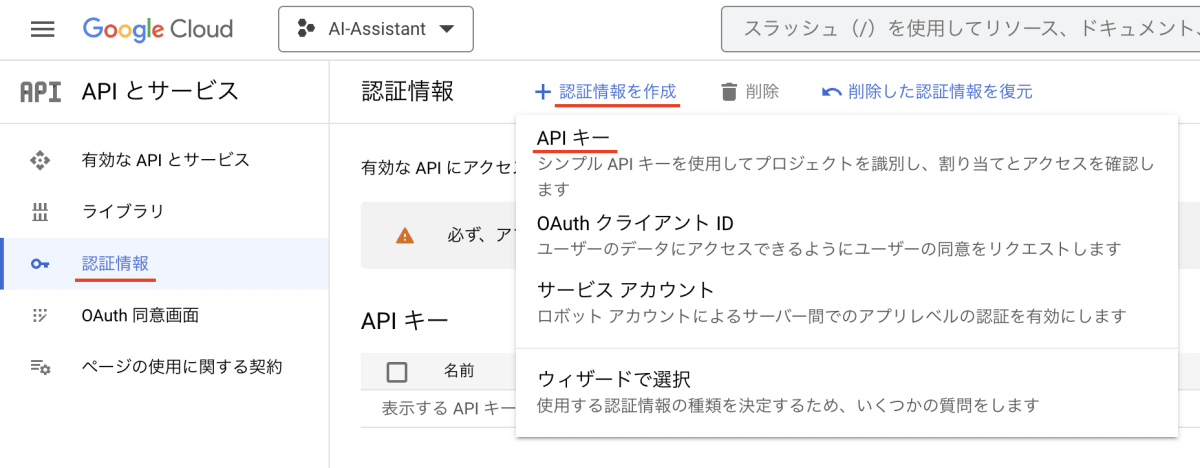
しばらくするとキーが発行されるのでそれをコピーしておきます。
Text to Speechへリクエストを送る
GoogleのText to Speechは音声データをbase64エンコードした文字列として返してくるため、少しだけ工夫が必要です。まずはリクエストを送るところから見てみましょう。
public async UniTask<AudioClip> Request(string serif)
{
Root root = new Root
{
input = new Input
{
text = serif,
},
voice = new Voice
{
languageCode = "ja-JP",
name = "ja-JP-Neural2-B",
ssmlGender = "FEMALE",
},
audioConfig = new AudioConfig
{
audioEncoding = "MP3",
}
};
string json = JsonUtility.ToJson(root);
using var request = new UnityWebRequest($"{s_apiUrl}?key={_apiKey}", "POST")
{
uploadHandler = new UploadHandlerRaw(Encoding.UTF8.GetBytes(json)),
downloadHandler = new DownloadHandlerBuffer(),
};
request.SetRequestHeader("Content-Type", "application/json; charset=utf-8");
await request.SendWebRequest();
if (request.result == UnityWebRequest.Result.ConnectionError ||
request.result == UnityWebRequest.Result.ProtocolError)
{
Debug.LogError(request.error);
throw new Exception();
}
string responseString = request.downloadHandler.text;
GoogleTextToSpeechResponse response = JsonUtility.FromJson<GoogleTextToSpeechResponse>(responseString);
return await GetMedia(response.audioContent);
}
冒頭で行っているのはリクエストのための設定です。特に大事なのは「言語と音声タイプの設定」です。以下の部分ですね。
Root root = new Root
{
input = new Input
{
text = serif,
},
voice = new Voice
{
languageCode = "ja-JP",
name = "ja-JP-Neural2-B",
ssmlGender = "FEMALE",
},
audioConfig = new AudioConfig
{
audioEncoding = "MP3",
}
};
サポートされている言語と音声タイプは以下に一覧されています。
ここでは日本語( ja-JP )を指定し、音声タイプを ja-JP-Neural2-B の FEMALE として女性音声でしゃべってもらっています。また取得する音声ファイル・タイプを MP3 に指定しています。
音声タイプはいくつかあり、さらに種類によって金額が異なるため注意してください。今回利用したのは一番流暢に話してくれるタイプで、一番金額が高いものを選んでいます。音声タイプの一覧にはサンプル音声もあるのでそれを聴き比べて選ぶといいでしょう。
音声データを取り出す
前述したように、音声データはbase64エンコードされた文字列で渡されます。そのため少しだけ工夫する必要があります。それをしているのが以下の処理です。
private async UniTask<AudioClip> GetMedia(string base64Message)
{
byte[] audioBytes = Convert.FromBase64String(base64Message);
string tempPath = $"{Application.persistentDataPath}/tmpMP3Base64.mp3";
await File.WriteAllBytesAsync(tempPath, audioBytes);
using UnityWebRequest request = UnityWebRequestMultimedia.GetAudioClip($"file://{tempPath}", AudioType.MPEG);
await request.SendWebRequest();
if (request.result.Equals(UnityWebRequest.Result.ConnectionError))
{
Debug.LogError(request.error);
return null;
}
AudioClip clip = DownloadHandlerAudioClip.GetContent(request);
File.Delete(tempPath);
return clip;
}
まず、 Convert.FromBase64String(base64Message) によってbase64エンコードされた文字列をバイト配列に変換します。そしてそれをいったん mp3 ファイルとして保存します。
Unityには mp3 ファイルを AudioClip として読み込むための機能があるため、これを利用して取得した音声データを AudioClip として取得します。
using UnityWebRequest request = UnityWebRequestMultimedia.GetAudioClip($"file://{tempPath}", AudioType.MPEG);
ロードが正常に終われば AudioClip として取り出せます。取り出したあとは作業用ファイルを削除してクリップを返します。
AudioClip clip = DownloadHandlerAudioClip.GetContent(request);
File.Delete(tempPath);
return clip;
これでGoogleのText to Speechで音声化したデータを利用することができます。
コード全文
参考までに、コード全文を載せておきます。
using System;
using System.IO;
using System.Text;
using Cysharp.Threading.Tasks;
using UnityEngine;
using UnityEngine.Networking;
public class TextToSpeech : MonoBehaviour
{
public struct GoogleTextToSpeechResponse
{
public string audioContent;
}
[Serializable]
public struct Input
{
public string text;
}
[Serializable]
public struct Voice
{
public string languageCode;
public string name;
public string ssmlGender;
}
[Serializable]
public struct AudioConfig
{
public string audioEncoding;
}
[Serializable]
public struct Root
{
public Input input;
public Voice voice;
public AudioConfig audioConfig;
}
[SerializeField] private AudioSource _audioSource;
[SerializeField] private string _apiKey = "<YOUR API KEY HERE>";
private static readonly string s_apiUrl = "https://texttospeech.googleapis.com/v1/text:synthesize";
public async UniTask<AudioClip> Request(string serif)
{
Root root = new Root
{
input = new Input
{
text = serif,
},
voice = new Voice
{
languageCode = "ja-JP",
name = "ja-JP-Neural2-B",
ssmlGender = "FEMALE",
},
audioConfig = new AudioConfig
{
audioEncoding = "MP3",
}
};
string json = JsonUtility.ToJson(root);
using var request = new UnityWebRequest($"{s_apiUrl}?key={_apiKey}", "POST")
{
uploadHandler = new UploadHandlerRaw(Encoding.UTF8.GetBytes(json)),
downloadHandler = new DownloadHandlerBuffer(),
};
request.SetRequestHeader("Content-Type", "application/json; charset=utf-8");
await request.SendWebRequest();
if (request.result == UnityWebRequest.Result.ConnectionError ||
request.result == UnityWebRequest.Result.ProtocolError)
{
Debug.LogError(request.error);
throw new Exception();
}
string responseString = request.downloadHandler.text;
GoogleTextToSpeechResponse response = JsonUtility.FromJson<GoogleTextToSpeechResponse>(responseString);
return await GetMedia(response.audioContent);
}
private async UniTask<AudioClip> GetMedia(string base64Message)
{
byte[] audioBytes = Convert.FromBase64String(base64Message);
string tempPath = $"{Application.persistentDataPath}/tmpMP3Base64.mp3";
await File.WriteAllBytesAsync(tempPath, audioBytes);
using UnityWebRequest request = UnityWebRequestMultimedia.GetAudioClip($"file://{tempPath}", AudioType.MPEG);
await request.SendWebRequest();
if (request.result.Equals(UnityWebRequest.Result.ConnectionError))
{
Debug.LogError(request.error);
return null;
}
AudioClip clip = DownloadHandlerAudioClip.GetContent(request);
File.Delete(tempPath);
return clip;
}
}
それぞれをまとめあげる
以上で個別の処理の説明は終わりです。あとはこれをまとめあげて、Unityちゃんが話すようにしてあげれば完成です。
最後にまとめあげている箇所のコードを掲載します。
string responseString = request.downloadHandler.text;
ChatGPTResponse response = JsonUtility.FromJson<ChatGPTResponse>(responseString);
Debug.Log($"CHatGPT: {response.choices[0].message.content}");
EmotionData emotionData = EmotionData.Parse(response.choices[0].message.content);
_serif.text = emotionData.Message;
AudioClip clip = await _textToSpeech.Request(_serif.text);
_audioSource.clip = clip;
_audioSource.Play();
_emotion.Change(emotionData.EmotionType);
_mesasgeList.Add(response.choices[0].message);
まず、ChatGPT APIから返ってきたJSONをパースしてレスポンスオブジェクトにします。そしてその内容から感情データ( EmotionData )に変換して、表情データとメッセージを取得します。
そして得られたメッセージをGoogleのText to Speech APIに投げます。
最後に、音声に変換されたものを AudioSource に設定して再生し、合わせて表情を変化させて完成です。
最後に
ChatGPT自体の自然さは知っていましたし、音声認識、音声合成自体はそれぞれ試したことがありました。しかし、これらを統合して、さらにVR化して目の前にいる状態で話をすると完全に新しい体験でした。
会話によってはたまに質問されることもあるので、本当に自然に会話している感じがして、SFの世界に足を踏み入れたような不思議な感じがしました。
VR環境がある人はぜひ、VR化して目の前のキャラと話しをしてみてください。
エンジニア絶賛募集中!
MESONではUnityエンジニアを絶賛募集中です! XRのプロジェクトに関わってみたい! 開発したい! という方はぜひご応募ください!
MESONのメンバーページからご応募いただくか、TwitterのDMなどでご連絡ください。
書いた人

比留間 和也(あだな:えど)
カヤック時代にWEBエンジニアとしてリーダーを務め、その後VRに出会いコロプラに転職。 コロプラでは仮想現実チームにてXRコンテンツ開発に携わる。 DAYDREAM向けゲーム「NYORO THE SNAKE & SEVEN ISLANDS」をリリース。その後、ARに惹かれてMESONに入社。 MESONではARエンジニアとして活躍中。
またプライベートでもAR/VRの開発をしており、インディー部門でTGSに出展など公私関わらずAR/VRコンテンツ制作に精を出す。プライベートな時間でも開発しているように、新しいことを学ぶことが趣味で、最近は英語を学んでいる。
MESON Works
MESONの制作実績一覧もあります。ご興味ある方はぜひ見てみてください。

Discussion