
概要
Unityが発表したAIツール群。その中にあるSeintsは、Barracudaをリプレイスすることを目標に作られているもののようです。現在はまだβプログラムで、全員が利用できるわけではありませんが、運良く参加できたので早速試してみました。
が、今回の内容はほぼBarracudaでも同じような内容になります。ONNXモデルを利用したフローを自分が理解したかったのでちょっとやってみた、という内容の記事ですw
今回は利用方法というより、全体の構造を把握、理解することを目的としています。Barracudaでもそうでしたが、SentisでもONNX(Open Neural Network Exchange)を利用してAIを構築します。
そこでONNXを自作し、それをSentis上で扱うまでを解説しながら使い方や使うイメージを掴んでもらえればと思います。
PyTorchでモデルを作成する
ONNXの作成の前に、まずはPyTorchを利用してモデルを作成します。今回はDeep LearningのHello Worldと言われる「MNIST(Mixed National Institute of Standard and Technology database)」を利用して手書き文字の認識を行うモデルを作成します。
MNISTとは
Wikipediaから引用すると以下のように説明されています。
MNISTデータベース(英: MNIST database, Modified National Institute of Standards and Technology databaseの略)は、さまざまな画像処理システムの学習に広く使用される手書き数字画像の大規模なデータベース。米国商務省配下の研究所が構築したこのデータベースは、機械学習分野での学習や評価に広く用いられている。

今回のモデル作成は以下の記事を参考にさせていただきました。
ONNXモデルを作成するPyTorchのコードをGitHubにアップしてあります。
実際に動作するコードをGoogle Colab上にもアップしているので、環境がない方はそちらから実行してみてください。
セットアップ
まずはデータセット(MNIST)を取得しましょう。必要なモジュールは以下です。
import torch
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
以下のようにして、訓練用データとテスト用データを取得します。
# Settings
num_batch = 100
transform = transforms.Compose([
transforms.ToTensor()
])
# Preparing training and test data
# Train data
train_data = MNIST(
'./datasets/mnist',
train=True,
download=True,
transform=transform,
)
train_loader = DataLoader(
train_data,
batch_size=num_batch,
shuffle=True,
)
# Test data
test_data = MNIST(
'./datasets/mnist',
train=False,
download=False,
transform=transform,
)
test_loader = DataLoader(
test_data,
batch_size=num_batch,
shuffle=True,
)
データセットとは
データセットとは推論を行うためのデータとラベル(正解データ)がセットになったデータの塊のことです。コードでは訓練用とテスト用で分けるため train=True / False で分けています。
データローダ( DataLoader )はコンストラクタに指定した batch_size 分ずつデータを取り出し、以下のように for ループで回した際に、指定したバッチサイズが 1 ループとして扱われます。
for inputs, labels in train_dataloader:
# ...
ちなみに参考にした記事によるとデータを取り出す際に、
このデータを取り出す際に、データを拡大、縮小、移動などを行い、見かけ上のデータ数を増やす水増しと言われる処理や、データを並び替えて値を0~1の値に収まるように変換し、テンソルと呼ばれるデータ形式に変更します。
とのこと。
イメージ図も引用すると以下のようになります。
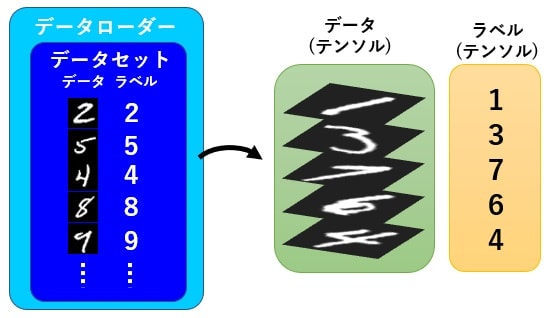
ニューラルネットワークの作成
データが準備できたので、Deep Learningの主題であるネットワークを構築します。といっても今回は2層のシンプルなネットワークです。
class Net(nn.Module):
def __init__(self, input_size, output_size):
super().__init__()
self.l1 = nn.Linear(input_size, 100) # From a input layer to a hidden layer.
self.l2 = nn.Linear(100, output_size) # From a hidden layer to a output layer.
def forward(self, x):
x = self.l1(x)
x = torch.sigmoid(x)
x = self.l2(x)
return F.log_softmax(x, dim=1)
forwardメソッド
forward メソッドはやや特殊な扱いになっています。継承元の nn.Module を見てみると以下のように __call__ が定義されており、その実装内で self.forward を呼んでいます。こうして間接的に呼ばれるようになっているわけですね。
__call__ : Callable[..., Any] = _call_impl
def _call_impl(self, *args, **kwargs):
forward_call = (self._slow_forward if torch._C._get_tracing_state() else self.forward)
ネットワークの概要
参考にした記事から引用すると以下のように説明されています。
今回は入力に画像データ全画素数(28 x 28)の784個入力で、全結合(出力100個)→ シグモイド → 全結合(出力10個)→ ログソフトマックスというとてもシンプルな物にしました。
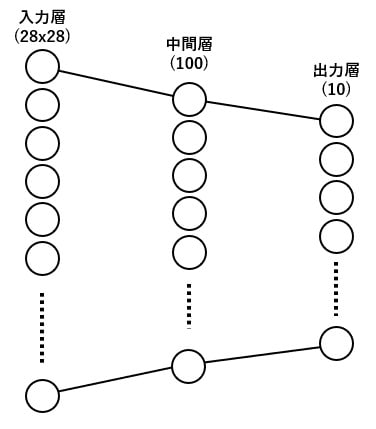
コードを見てみると nn.Linear(input_size, 100) となっていて、入力から 100 要素に変換しているのが分かります。そして続く nn.Linear(100, output_size) で最後の 10 要素に絞っています。( input_size と output_size はコンストラクタで指定され、今回はそれぞれ 28 * 28 = 784, 10 の値が設定されています)
forward メソッドを見てみると各層の処理が行われているのが分かります。 l1 と l2 を繋いでいるのが torch.sigmoid(x) で、シグモイド関数を利用しているのが分かりますね。
def forward(self, x):
x = self.l1(x)
x = torch.sigmoid(x)
x = self.l2(x)
return F.log_softmax(x, dim=1)
最後に F.log_softmax(x, dim=1) のログ・ソフトマックス関数で確率に変換したものを出力としています。
損失関数
損失関数はニューラルネットワークの出した結果と正解との誤差を比較するための関数です。この関数の誤差を最小化するのがイコール学習です。
今回は「交差エントロピー誤差関数( nn.CrossEntropyLoss )」を使用しています。
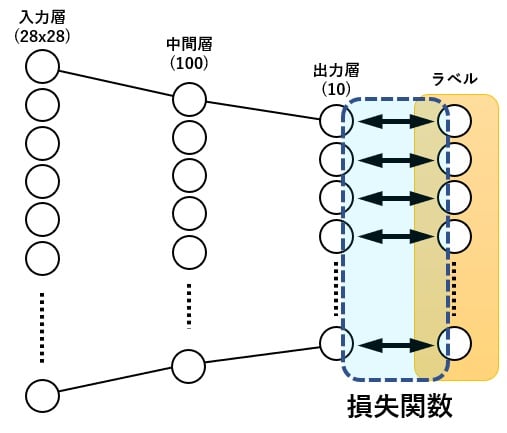
訓練(トレーニング)
道具がそろったのでこれを元に学習させていきます。
今回は 100 バッチサイズを1回のループとして、 10 エポック学習しています。
# Traning
model.train() # Change mode to training
for epoch in range(num_epochs):
loss_sum = 0
for inputs, labels in train_loader:
# Send data to GPU if it can do
inputs = inputs.to(device)
labels = labels.to(device)
# Initialize optimizer
optimizer.zero_grad()
# Perform the neural network.
inputs = inputs.view(-1, image_size)
outputs = model(inputs)
# Calculate loss
loss = loss_func(outputs, labels)
loss_sum += loss
# Calculate gradiation
loss.backward()
# Update its weights
optimizer.step()
# Show the progress
print(f'Epoch: {epoch+1}/{num_epochs}, Loss: {loss_sum.item() / len(train_loader)}')
# Save its weights
torch.save(model.state_dict(), 'model_weights.pth')
これを実行すると以下のように学習が進んでいく様子が確認できます。
Epoch: 1/10, Loss: 0.6625218200683594
Epoch: 2/10, Loss: 0.26709622701009117
Epoch: 3/10, Loss: 0.21106074015299478
Epoch: 4/10, Loss: 0.1781070073445638
Epoch: 5/10, Loss: 0.15328439076741537
Epoch: 6/10, Loss: 0.13522972106933595
Epoch: 7/10, Loss: 0.11996323903401693
Epoch: 8/10, Loss: 0.10726773579915365
Epoch: 9/10, Loss: 0.09663106918334961
Epoch: 10/10, Loss: 0.08731952667236328
最初は 0.6 と誤差が大きかったのが、最後には 0.08 程度まで下がっているのが確認できます。
チェックポイントの保存
各ループの最後に、その時点の状態を保存しています。
# Save its weights
torch.save(model.state_dict(), 'model_weights.pth')
今回は毎回上書きしてしまっていますが、ループごとにファイル名を変えれば、エポックごとの状況を保存することも可能です。
さぁ、これでPyTorchを利用したモデルの作成ができました。次はこれをONNXフォーマットに変換します。
ONNXフォーマットへ変換
前段でPyTorchによるモデルの学習を行いました。最後に保存されたものをONNXに変換してそれをUnityに持っていきましょう。
ONNXはオープンソースなので、PyTorchでも簡単に変換することができます。
以下のコードを実行して、保存したモデルをONNXフォーマットに変換します。
import torch
import torch.nn as nn
import torch.nn.functional as F
image_size = 28 * 28
device = 'cuda' if torch.cuda.is_available() else 'cpu'
if device == 'cuda':
torch.set_default_tensor_type('torch.cuda.FloatTensor')
class Net(nn.Module):
def __init__(self, input_size, output_size):
super().__init__()
self.l1 = nn.Linear(input_size, 100) # From a input layer to a hidden layer.
self.l2 = nn.Linear(100, output_size) # From a hidden layer to a output layer.
def forward(self, x):
x = self.l1(x)
x = torch.sigmoid(x)
x = self.l2(x)
return F.log_softmax(x, dim=1)
# Create a neural network.
model = Net(image_size, 10).to(device)
checkpoint = torch.load('model_weights.pth')
model.load_state_dict(checkpoint)
torch.onnx.export(
model=model,
args=torch.randn(1, 784),
f='model.onnx',
export_params=True,
input_names=['input'],
output_names=['output'],
)
これを実行すると ONNX ファイルが生成されます。
ONNXファイルの確認

ONNXファイルの中身を確認するのにNETRONというアプリが利用できます。これはオープンソースなので無料で使えます。
実際に、作成したONNXモデルをNETRONで確認すると以下のようになります。
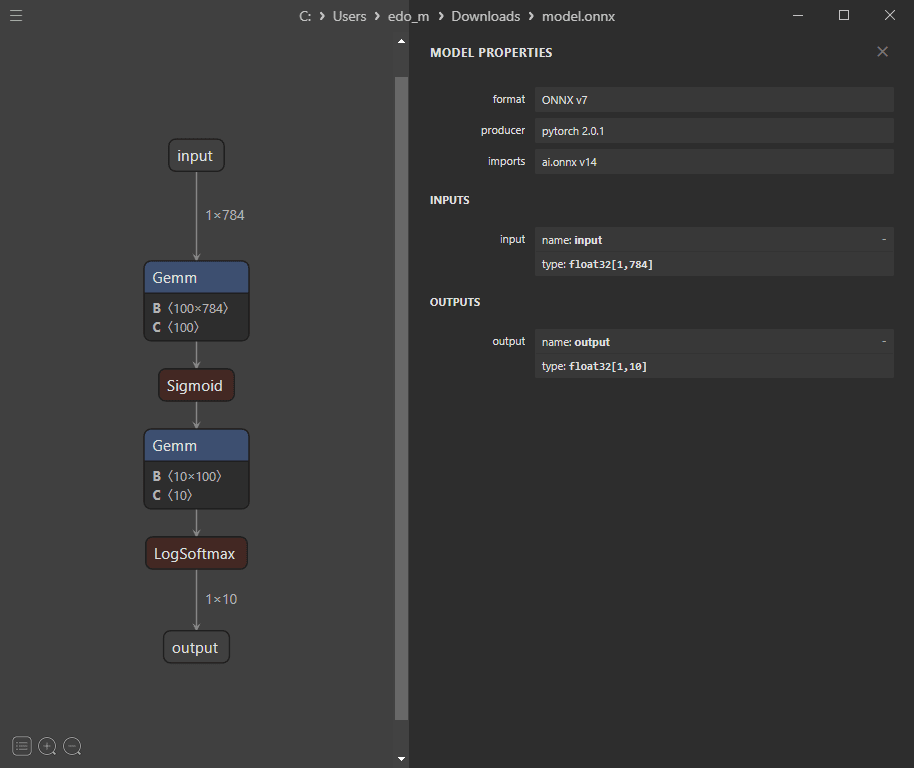
inputが 1 x 784 で、outputが 1 x 10 になっているのが確認できますね。
これでONNXモデルが準備できました。次はこれをUnityに持っていき、 Unity.Sentis で扱う方法を確認します。
Unity Sentisで利用する
まずはUnity Sentisの仕組みを概観しましょう。
なお、今回実装したものはGitHubにアップしてあります。(ただし、βプログラムを利用しているので許可されていない人は利用できません)
Sentisのワークフローを知る
-
Unity.Sentisnamespaceを利用 - ニューラルネットワークのモデルをロード(前段で作成したONNXモデル)
- モデルに入力するデータを準備(今回は画像)
- 推論エンジン(
IWorker)を作成する - 入力を用いてモデルを実行し、推論する
- 結果を得る
内容はシンプルですね。実際のコードでも見ていきましょう。
Unityでの実装
モデルのロード
モデルをロードします。モデルの元となるデータ( ModelAsset )は、ドキュメントでは以下のように Resourcees.Load を利用していますが、 SerializeField を利用して設定してもOKです。
ModelAsset modelAsset = Resources.Load("model-file-in-assets-folder") as ModelAsset;
Model runtimeMoodel = ModelLoader.Load(modelAsset);
入力の準備
入力は 28 x 28 の画像になります。
Resources.Load や SerializeField などを用いて画像を読み込みます。
Texture2D inputTexture = Resources.Load("image-file") as Texture2D;
TensorFloat inputTensor = TextureConverter.ToTensor(inputTexture);
画像そのままでは扱えないので TextureConverter.ToTensor メソッドでテクスチャデータをテンソルに変換します。
推論エンジンを作成
ファクトリメソッドが用意されているのでそれを用いて生成します。生成の際、どういう形で利用するかを指定します。今回は BackendType.GPUCompute を選択しました。
IWorker worker = WorkerFactory.CreateWorkder(BackendType.GPUCompute, runtimeModel);
推論を実行
推論は worker.Execute に入力を渡して実行するだけです。
worker.Execute(inputTensor);
結果を得る
結果を得るには worker.PeekOutput を利用します。
TensorFloat outputTensor = worker.PeekOutput() as TensorFloat;
float[] results = outputTensor.ToReadOnlyArray();
今回は 1 x 10 のサイズのテンソルが出力となり、0~9の数字のどの数字が一番確率が高そうかを示した確率の値が格納されます。
一番大きい値のインデックスが結論です。
コード全文
全文載せても多くないのでここに掲載しておきます。
using Unity.Sentis;
using UnityEngine;
using UnityEngine.Serialization;
public class SentisTest : MonoBehaviour
{
[SerializeField] private ModelAsset _modelAsset;
[FormerlySerializedAs("_Texture")] [SerializeField]
private Texture2D _texture;
private static readonly int s_width = 28;
private static readonly int s_height = 28;
private Model _runtimeModel;
private TensorFloat _inputTensor;
private IWorker _engine;
private void Start()
{
_runtimeModel = ModelLoader.Load(_modelAsset);
_engine = WorkerFactory.CreateWorker(BackendType.GPUCompute, _runtimeModel);
TensorFloat tensor = TextureConverter.ToTensor(_texture);
TensorShape shape = new TensorShape(1, 784);
_inputTensor = tensor.ShallowReshape(shape) as TensorFloat;
Execute();
}
private void Execute()
{
_engine.Execute(_inputTensor);
TensorFloat outputTensor = _engine.PeekOutput() as TensorFloat;
float[] results = outputTensor.ToReadOnlyArray();
int number = Inference(results);
Debug.Log($"Result: {number.ToString()}");
}
private int Inference(float[] results)
{
int number = -1;
float max = float.MinValue;
for (int i = 0; i < results.Length; i++)
{
if (results[i] > max)
{
max = results[i];
number = i;
}
}
return number;
}
private void OnDestroy()
{
_engine.Dispose();
}
}
実際に動かしてみた結果がこちらです。
適切に画像を認識していることが分かります。
最後に
Unity Sentisはこれ以外にも様々な用途にAIを用いることができます。特にありがたいのはランタイムで動き、Unityがサポートしているプラットフォームをカバーしていることです。
もちろん重いモデルではモバイルで動かすのはむずかしいケースもあるかもしれませんが、クラウドに頼らずにモデルを動かせるのはとても大きなアドバンテージだと思います。
また今後は、モデルが軽量化しモバイル上で動くことが当たり前になっていくことは想像に難くありません。そうしたときにもすぐに対応できるように、今からAIをアプリに組み込んでいくのはとても有意義であると思います。
今回の記事がAIを利用する際の参考になれば幸いです。
エンジニア絶賛募集中!
MESONではUnityエンジニアを絶賛募集中です! 空間コンピューティングのプロジェクトに関わってみたい! 開発したい! という方はぜひご応募ください!
MESONのメンバーページからご応募いただくか、TwitterのDMなどでご連絡ください。
書いた人

比留間 和也(あだな:えど)
カヤック時代にWEBエンジニアとしてリーダーを務め、その後VRに出会いコロプラに転職。 コロプラでは仮想現実チームにてXRコンテンツ開発に携わる。 DAYDREAM向けゲーム「NYORO THE SNAKE & SEVEN ISLANDS」をリリース。その後、ARに惹かれてMESONに入社。 MESONではARエンジニアとして活躍中。
またプライベートでもAR/VRの開発をしており、インディー部門でTGSに出展など公私関わらずAR/VRコンテンツ制作に精を出す。プライベートな時間でも開発しているように、新しいことを学ぶことが趣味で、最近は英語を学んでいる。
MESON Works
MESONの制作実績一覧もあります。ご興味ある方はぜひ見てみてください。

Discussion