FORCIAのサマーインターンで検索DBを高速化してきた in 2024
はじめに
8月5日~9日にフォルシア株式会社のサマーインターンシップ 検索DB高速化コースに参加しました!
インターンの流れなどはこちらに記載されているので、本記事ではインターンで行った課題について深ぼって行きたいと思います!
行った課題
- 課題1:元々の環境と分散環境でのパフォーマンス検証
- 課題2:スケールアウトさせることでのパフォーマンス検証
- 課題3:スケールインさせるためのユーザー定義関数作成
前提
本インターンの課題では旅行検索サービスを題材として行いました。
宿泊プラン・日付・一部屋あたりの人数などが掛け合わされた大量で複雑なデータを扱います。

このように大量で複雑なデータをシステム構成のみで、どのようにパフォーマンスを上げていくのかを行っていきました。
使用技術
- k6
- PostgreSQL
- Citus
元々の環境
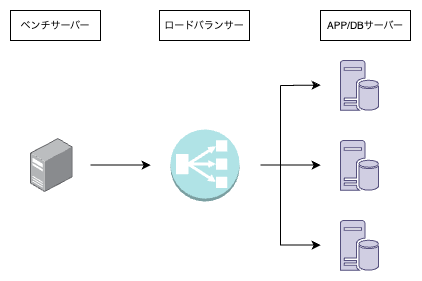
元々の環境はこのようになっており、ベンチサーバーが負荷を生成してリクエストを送信します。その後、ロードバランサーがリクエストを3つのAPP/DBサーバーに振り分け、各APP/DBサーバーがそれぞれリクエスト内容に基づいてクエリを実行し、結果を返す仕組みです。
ベンチマークのシナリオについて
今回のベンチマークでは、以下のようなシナリオを実行しました。
| シナリオ名 | 検索範囲 | データ取得量 | 同時リクエスト回数 |
|---|---|---|---|
| case1 | 限られたエリア(市区町村) | 最初の方だけ取得 | 1回 |
| case2 | 限られたエリア(市区町村) | 全て取得 | 1回 |
| case3 | 広いエリア(首都圏なども含む) | 最初の方だけ取得 | 1回 |
| case4 | 広いエリア(首都圏なども含む) | 全て取得 | 1回 |
| case5 | 限られたエリア(市区町村) | 最初の方だけ取得 | 5回 |
| case6 | 限られたエリア(市区町村) | 全て取得 | 5回 |
| case7 | 広いエリア(首都圏なども含む) | 最初の方だけ取得 | 5回 |
| case8 | 広いエリア(首都圏なども含む) | 全て取得 | 5回 |
元々の環境でベンチマークを行ってみる
元々の環境と後述する環境でのパフォーマンスを比較したいので、ひとまずベンチマークを行ってみます。
| シナリオ名 | count | successRate | avg | min | med | max | p(90) | p(95) |
|---|---|---|---|---|---|---|---|---|
| case1 | 73 | 1.00 | 233.233 | 37.632 | 169.456 | 820.840 | 519.830 | 581.604 |
| case2 | 74 | 1.00 | 138.400 | 28.500 | 98.456 | 711.656 | 321.451 | 413.916 |
| case3 | 2 | 1.00 | 7842.572 | 7729.113 | 7842.572 | 7956.031 | 7933.339 | 7944.685 |
| case4 | 3 | 1.00 | 4151.050 | 1901.628 | 4576.002 | 5975.521 | 5695.617 | 5835.569 |
| case5 | 211 | 1.00 | 239.898 | 31.680 | 155.707 | 1008.847 | 513.636 | 607.297 |
| case6 | 338 | 1.00 | 149.180 | 27.151 | 122.467 | 548.784 | 298.325 | 363.479 |
| case7 | 10 | 1.00 | 6422.999 | 1479.082 | 6890.328 | 14097.433 | 9211.746 | 11654.590 |
| case8 | 8 | 1.00 | 8356.307 | 4919.891 | 8031.453 | 11931.588 | 10935.188 | 12250.540 |
課題1:元々の環境と分散環境でのパフォーマンス検証
分散環境を作るにあたって、Citusを用いました。
Citusとは?
- PostgreSQLの拡張として実装
- 分散データベースに変換してくれる
- データとクエリを複数のノードに分散させることで、データ処理を並列化し、大きいデータセットに対しても高速に結果を返してくれる
本課題ではv12.1を使用しました。
Citusを用いた分散環境

Coordinator Node
Coordinator Nodeはベンチサーバーからリクエストを受け付け、分散環境を管理します。適切なWorker Nodeにクエリを振り分け、各Worker Nodeから結果を統合して最終的な結果を返します。また、メタデータ(どのシャードがどのWorker Nodeに配置されているかなど)を管理します。
なお、Coordinator Node自体も1つのインスタンスとして動作するため、元々の環境と比較するとクエリを処理するサーバーが1つ減少します。
Worker Node
各Worker Nodeにはシャーディング(テーブルを分割して負荷を分散するようにデータを分ける手法)が適用されたデータが保存されています。それぞれのWorker Nodeは独立してクエリを処理しています。
Coordinator Nodeからの指示に基づき、複数のWorker Nodeが並行してクエリを処理します。
Citusを使うことで何が嬉しいのか
元々の環境では、3つのAPP/DBサーバーが独立して動作しているため、クエリが1つのサーバ一に割り当てられると、そのサーバーのリソースしか利用できません。そのため、一度にリソースを多く消費する重いクエリが来た場合、全体の1/3のリソースしか使用できず、処理が遅くなることがあります。
一方、Citusを使った分散環境では、Coordinator Nodeがクエリを複数のWorker Nodeに分散し、並行して処理することで、重いクエリが来た場合に単一のサーバで処理するよりも高速化が期待できます。
分散環境でベンチマークを行ってみる
分散環境下で行ったベンチマークは以下の通りになります。
| シナリオ名 | count | succesRate | avg | min | med | max | p(90) | p(95) |
|---|---|---|---|---|---|---|---|---|
| case1 | 73 | 1.00 | 137.223 | 48.931 | 109.047 | 685.100 | 250.746 | 282.632 |
| case2 | 112 | 1.00 | 89.703 | 48.038 | 81.084 | 165.639 | 135.229 | 140.871 |
| case3 | 9 | 1.00 | 1601.581 | 639.445 | 1103.005 | 5202.227 | 2701.503 | 3951.865 |
| case4 | 16 | 1.00 | 945.448 | 589.890 | 703.670 | 3540.263 | 1320.989 | 2236.232 |
| case5 | 103 | 1.00 | 497.312 | 137.804 | 505.610 | 669.175 | 603.952 | 634.369 |
| case6 | 110 | 1.00 | 467.025 | 104.209 | 472.827 | 633.553 | 563.616 | 580.617 |
| case7 | 27 | 1.00 | 3301.907 | 547.864 | 3299.182 | 3414.573 | 3387.421 | 3395.263 |
| case8 | 26 | 1.00 | 3133.153 | 606.398 | 3409.975 | 3541.333 | 3498.212 | 3529.510 |
元々の環境との比較
簡略化のため、シナリオ名・count・medに注目してみてみます。
| シナリオ名 | count(元々) | count(分散) | med(元々) | med(分散) |
|---|---|---|---|---|
| case1 | 73 | 73 | 169.456 | 109.047 |
| case2 | 74 | 112 | 98.456 | 81.084 |
| case3 | 2 | 9 | 7842.572 | 1103.005 |
| case4 | 3 | 16 | 4576.002 | 703.670 |
| case5 | 211 | 103 | 155.707 | 505.610 |
| case6 | 338 | 110 | 122.467 | 472.827 |
| case7 | 10 | 27 | 6890.328 | 3299.182 |
| case8 | 8 | 26 | 8031.453 | 3409.975 |
パフォーマンスが向上したケース
case5と6を除いて、分散環境の方がパフォーマンス向上しています。特にcase3とcase4では大幅な改善が見られました。
元々の環境では1つのリクエストに対して利用できるインスタンスが3つあるうちの1つだけであったため、資源の使い方が非効率でした。一方、分散環境では複数のWorker Nodeが並行してクエリを処理できるため、リクエストに対する処理時間が大幅に短縮されています。
元々の環境の方が良かったケース
case5と6では、元々の環境の方が良い結果となりました。
これは検索範囲が「限られたエリア」であるため、クエリの負荷が比較的軽いこと、元々の環境では、5つのリクエストを3つのインスタンスで効率的に処理できている。分散環境ではCoordinator Nodeがクエリを分散する際のオーバーヘッドが発生しており、この差がパフォーマンスに影響を与えています。
結果から
比較を行う前は、分散環境の方がすべてのケースでパフォーマンスが向上すると考えていました。しかし、実際の結果を見ると、必ずしもすべてのケースで分散環境が優れているわけではないことが分かりました。この結果から、分散環境の活用は、クエリの性質やシステムの特性に応じて適材適所で検討する必要があると感じました。
課題2:スケールアウトさせることでのパフォーマンス検証
インスタンスを増やせば増やすほどパフォーマンスが向上しますが、現実的にはコストが増加するため、この考え方だけでは十分ではありません。そこで以下の2点に注目し、スケールアウトによるパフォーマンスの検証を行いました。
- インスタンスを1つ追加することで、コストに見合った効果が得られるか
- 理想としては、インスタンスを増やすことでパフォーマンスが比例して向上してほしい。
- インスタンスの適正な数はどれくらいか
1台目追加
1台目を追加した結果、ケースによってはパフォーマンスが比例して向上していることが確認できました。
| シナリオ名 | count | successRate | avg | min | med | max | p(90) | p(95) |
|---|---|---|---|---|---|---|---|---|
| case1 | 155 | 1.00 | 64.743 | 31.45 | 60.295 | 108.525 | 98.538 | 102.442 |
| case2 | 159 | 1.00 | 63.194 | 33.094 | 57.484 | 118.991 | 95.885 | 102.358 |
| case3 | 21 | 1.00 | 702.445 | 452.194 | 667.213 | 1436.789 | 1012.999 | 1367.126 |
| case4 | 21 | 1.00 | 720.352 | 419.052 | 552.465 | 1432.412 | 1019.169 | 1409.789 |
| case5 | 153 | 1.00 | 311.272 | 116.803 | 321.527 | 448.563 | 366.163 | 395.249 |
| case6 | 160 | 1.00 | 317.833 | 121.799 | 321.944 | 390.574 | 367.164 | 395.891 |
| case7 | 27 | 1.00 | 2935.063 | 411.385 | 3113.924 | 4356.967 | 3999.91 | 4295.557 |
| case8 | 22 | 1.00 | 3450.522 | 537.083 | 3470.946 | 4768.17 | 4295.557 | 4304.864 |
2台目追加
2台目を追加した場合、パフォーマンスは向上しましたが、比例して向上しているとは言えない結果となりました。
| シナリオ名 | count | successRate | avg | min | med | max | p(90) | p(95) |
|---|---|---|---|---|---|---|---|---|
| case1 | 194 | 1.00 | 51.416 | 22.601 | 45.718 | 212.127 | 85.287 | 92.558 |
| case2 | 217 | 1.00 | 45.966 | 22.494 | 44.647 | 195.143 | 94.513 | 97.436 |
| case3 | 27 | 1.00 | 572.415 | 315.524 | 461.377 | 1088.542 | 760.129 | 802.495 |
| case4 | 25 | 1.00 | 625.625 | 315.392 | 465.258 | 1866.631 | 1096.654 | 1183.378 |
| case5 | 206 | 1.00 | 244.542 | 116.18 | 229.95 | 438.121 | 302.98 | 325.881 |
| case6 | 207 | 1.00 | 244.819 | 65.853 | 244.095 | 365.622 | 293.951 | 304.574 |
| case7 | 30 | 1.00 | 2702.104 | 357.36 | 2204.899 | 3510.768 | 2942.854 | 3340.504 |
| case8 | 28 | 1.00 | 2808.941 | 359.067 | 3129.231 | 3926.025 | 3621.524 | 3729.0 |
3台目追加
3台目を追加しても、パフォーマンスは向上しましたが、比例するほどの向上は見られませんでした。
| シナリオ名 | count | successRate | avg | min | med | max | p(90) | p(95) |
|---|---|---|---|---|---|---|---|---|
| case1 | 275 | 1.00 | 36.258 | 15.896 | 33.256 | 75.835 | 60.137 | 63.966 |
| case2 | 281 | 1.00 | 35.478 | 16.095 | 32.998 | 76.131 | 55.494 | 61.233 |
| case3 | 27 | 1.00 | 557.926 | 253.393 | 649.635 | 968.707 | 922.237 | 963.703 |
| case4 | 30 | 1.00 | 529.641 | 253.365 | 402.094 | 884.203 | 911.115 | 925.761 |
| case5 | 275 | 1.00 | 184.129 | 37.695 | 181.422 | 293.087 | 235.906 | 253.012 |
| case6 | 273 | 1.00 | 185.122 | 46.066 | 186.756 | 293.703 | 244.059 | 257.234 |
| case7 | 36 | 1.00 | 2297.775 | 609.292 | 2297.295 | 3208.406 | 3043.638 | 3155.244 |
| case8 | 35 | 1.00 | 2368.167 | 287.43 | 2391.931 | 3540.14 | 3112.754 | 3263.512 |
全体を比較してみて
- インスタンスを1つ追加することで、コストに見合った効果が得られるか
- 1台目の追加では、ケースによってはパフォーマンスが比例して向上していることが確認でき、追加する価値があると感じました。
- 2台目以降はパフォーマンスが向上するものの、比例するほどではありませんでした。
- インスタンスの適正な数
- 今回のケースでは、1台追加することが最もバランスが良い選択だと判断しました。
課題3:スケールインさせるためのユーザー定義関数作成
分散環境において、1つのWorker Nodeを切り離す必要がある場合、シャーディングされているデータが存在するため、簡単に切り離すことはできません。そのため、以下のような処理が必要になります。
- シャーディングされているデータを別のWorker Nodeに移動する
- 対象のWorker Nodeを切り離す
- 残ったWorker Node間でデータを均等に振り分ける
ここで課題となるのが、Citusにはこれらの処理を自動で行う機能が備わっていないことです。そのため、自分でユーザー定義関数を実装する必要があります。
実装したもの
ということで、先程の処理を実装したものが以下になります。
CREATE OR REPLACE FUNCTION move_shards_between_nodes(
source_node_name TEXT,
target_node_name TEXT
) RETURNS VOID AS $$
DECLARE
source_node_port INT;
target_node_port INT;
shard_record RECORD;
BEGIN
SELECT nodeport INTO source_node_port FROM pg_dist_node WHERE nodename = source_node_name;
SELECT nodeport INTO target_node_port FROM pg_dist_node WHERE nodename = target_node_name;
IF source_node_port IS NULL THEN
RAISE EXCEPTION 'Source node "%" not found', source_node_name;
END IF;
IF target_node_port IS NULL THEN
RAISE EXCEPTION 'Target node "%" not found', target_node_name;
END IF;
FOR shard_record IN
SELECT shardid
FROM pg_dist_shard_placement
WHERE nodename = source_node_name
LOOP
IF EXISTS (
SELECT 1
FROM pg_dist_shard_placement
WHERE shardid = shard_record.shardid
AND nodename = target_node_name
) THEN
RAISE NOTICE 'Shard "%" already present on node "%"', shard_record.shardid, target_node_name;
CONTINUE;
END IF;
PERFORM citus_move_shard_placement(
shard_record.shardid,
source_node_name,
source_node_port,
target_node_name,
target_node_port,
'block_writes'
);
END LOOP;
PERFORM citus_remove_node(source_node_name, source_node_port);
RAISE NOTICE 'Source node "%" removed from the cluster.', source_node_name;
PERFORM citus_rebalance_start();
RAISE NOTICE 'Rebalance of table shards initiated.';
END;
$$ LANGUAGE plpgsql;
以下の処理部分を見ていきます。
- シャーディングされているデータを別のWorker Nodeに移動する
- 対象のWorker Nodeを切り離す
- 残ったWorker Node間でデータを均等に振り分ける
1. シャーディングされているデータを別のWorker Nodeに移動する
FOR shard_record IN
SELECT shardid
FROM pg_dist_shard_placement
WHERE nodename = source_node_name
LOOP
IF EXISTS (
SELECT 1
FROM pg_dist_shard_placement
WHERE shardid = shard_record.shardid
AND nodename = target_node_name
) THEN
RAISE NOTICE 'Shard "%" already present on node "%"', shard_record.shardid, target_node_name;
CONTINUE;
END IF;
PERFORM citus_move_shard_placement(
shard_record.shardid,
source_node_name,
source_node_port,
target_node_name,
target_node_port,
'block_writes'
);
END LOOP;
処理の流れ
-
pg_dist_shard_placementテーブルからsource_node_nameに対応するシャードを取得 - 各シャードに対して以下を行う
- シャードがすでにターゲットノードに存在している場合、通知を行い、次のループへ
- シャードがダーゲットノードに存在していない場合、
citus_move_shard_placementを実行してシャードを移動させる
※補足(block_writesについて)
citus_move_shard_placementに'block_writes'オプションを追加しないと以下のようなエラーが発生します。
'block_writes'オプションを追加することで、シャードの移動中にそのシャードへの書き込み操作が一時的にブロックされます。これにより、移動中に新しいデータが書き込まれることで起こる論理レプリケーションの競合を防ぐことができます。(WALログが新しい書き込みによって更新されることを防ぐ)
2. 対象のWorker Nodeを切り離す
PERFORM citus_remove_node(source_node_name, source_node_port);
RAISE NOTICE 'Source node "%" removed from the cluster.', source_node_name;
処理の流れ
-
citus_remove_nodeを実行してソースノードをCoordinator Nodeのメタデータから削除する - ノードの削除が完了したことを通知
3. 残ったWorker Node間でデータを均等に振り分ける
PERFORM citus_rebalance_start();
RAISE NOTICE 'Rebalance of table shards initiated.';
処理の流れ
-
citus_rebalance_startを実行して残ったWorker Node間でシャードを再分配する - シャードの再分配が開始されたことを通知
課題の他にやったこと
基本的なパフォーマンスチューニング
本課題では、システム構成の変更を通じてパフォーマンスを向上させることが目的でしたが、加えてクエリのチューニングにも取り組みました。以下は、チューニング作業の大まかな流れです。
- スロークエリをログに出力する設定を行う
- ベンチマークを実行し、スロークエリのログを確認して、どのクエリが遅いのかを特定する
- スロークエリに対して
EXPLAIN ANALYZEを実行し、実行計画を確認する - 実行計画を基にクエリをチューニングする
チューニング対象のクエリがかなり複雑で、理解するだけでも手間がかかり、どのように改善すべきかに戸惑いました。しかし、以下の記事がその解決の糸口を与えてくれました。(全てFORCIAの記事😎)
postgresql.confをいじる
こちらも本課題の目的とは直接関係ありませんが、チューニングを行いました。
shared_buffersやwork_memなどのパラメータをいじってみて、ベンチマークを行い、パフォーマンスへの影響を検証しました。
分散環境のシャード複製
現在の分散環境では、いずれかのインスタンスがダウンすると、それに引きずられて全てのインスタンスが停止してしまう問題があります。このような状況はシステムの可用性として望ましくありません。そのため、各Worker Nodeにシャードを複製することで、特定のインスタンスがダウンしてもシステムが稼働し続けられるようにする対策を試みました。
実施した流れ
- 各Worker Nodeに対して
SET citus.shard_replication_factor = 複製したい数を行う
新しいシャードの複製がされる準備 - Coordinator Nodeに対して
SELECT citus_rebalance_start()を行う
各シャードでデータが複製される
課題と変更方針
作業を進める中で判明したのは、citus.shard_replication_factorはすでにdeprecatedとなっており、Citusでは可用性の担保をシャード単位ではなくWorker Node全体の複製によって担保するようでした。
なので、Worker Nodeを複製する方針での処理を試みようと思ったんですが、残りの時間的に厳しそうだったので断念しました。(とても悔しい...😭)
おわりに
インターン期間中は、メンターの方や企画をしてくださった社員の皆さまなど、多くの方にお世話になりました。
私自身、インターンに参加する前はDBを高速化する手法について知見がなく、やり切れるか不安でしたが、メンターさんの手厚いサポートのおかげでここまでやり切ることができました。
この場を借りて、深く感謝申し上げます。5日間楽しい時間を提供していただき本当にありがとうございました!
おそらく来年度も開催されると思うので、このような技術に興味がある人は是非応募してみてください!(インターンでは数少ないRustを使うコースもあるよ)
Discussion