RubyVM を PHP (他言語)で実装する
あいさつ
こんにちは!めもりー(@m3m0r7)です。
先日 PHP カンファレンス 2023 が開催され「RubyVM を PHP で実装する」という内容でトークさせていただきました。
そもそも VM(Virtual Machine) とはなにか?という話から実際に PHP で RubyVM を作って Hello World を出力するまでの道のりを解説しています。
尺が 25 分だったということもあり,一部省いた解説や,Appendix に持っていった内容もあります。
そこで,本記事ではより深掘りして RubyVM を PHP で実装する方法を解説します。
記述しているコードは PHP ですが,もちろん PHP 以外に Perl であったり Python であったり,そして Ruby であったりでの実装も可能です。
RubyVM のまえの拙作に JVM を PHP で実装したものがあります。興味があれば,そちらも見てみてください。
(※この資料に表示されている会社から私は既に退職しています)
TL;DR
- RubyVM の作り方を登壇したスライドより,もう少し詳しく書いているよ
- 完成形のイメージは https://gist.github.com/m3m0r7/226e20c8115caf4a9d43b291861f978b だよ
- PHP で本気で書いたやつは https://github.com/m3m0r7/rubyvm-on-php だよ
- みんなも自作 RubyVM 作ってみよう!
VM を実装するというのはどういうことか
VM を作る際にLexer(字句解析器), Parser(構文解析器), AST(抽象構文木) といったワードが頻出します。
どこまで作るかによりますが,VM を作るというのはあくまで「中間言語以後のランタイムを実装する」に留めています。
どういうことかというと,書かれているプログラムというのは概ね以下の図のようなプロセスを経て実行されています。
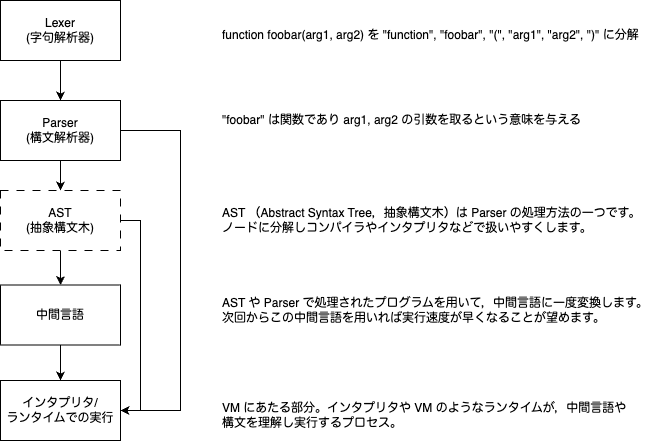
上記の図から,VM を作るというのは「インタプリタ/ランタイムでの実行」を実装するということになります。
つまり 元々あるプログラムを解釈する というのは含まれていないと考えてもらって問題ありません。
この前提から,RubyVM を実装するというのは中間言語を実行するランタイムを作るということになります。
Ruby にはこの中間言語を表す仕組みがあり,それを YARV (Yet Another Ruby Vm) といいます。ちなみに,YARV 向けにコンパイルされたバイナリを YARB (Yet Another Ruby Binary) というっぽい(?)です。
Lexer (字句解析器)と Parser (構文解析器),そして AST (抽象構文木)
さて,Lexer と Parser は実装しないと書きました。VM は実行する前の姿がどうなっていようが関係ないのです。これは JVM (Java Virtual Machine) に通ずるところがありますね。
どういうことかというと,Java を筆頭に Scala や Kotlin などがいわゆる JVM 言語に該当します。
JVM の実行環境そのものは,コンパイル前の言語が Scala や Kotlin であろうが動きます。
Lexer と Parser を実装するというのは,VM を作ることと関心事が異なるということが,これで理解できたかと思います。
そして,頻繁によく耳にする AST ですが,これは Parser の表現方法の一つです。PHP に限って言えば,AST で有名ドコロなライブラリは nikic/PHP-Parser です。
過去に私が登壇した「PHP で AST 解析をして Java のオペコードを生成する」で AST についてちらっと解説しています。
(※この資料に表示されている会社から私は既に退職しています)
RubyVM はどうやって作るのか
JVM には The Java Virtual Machine Specification というオンラインドキュメントが存在します。
JVM 言語を作る場合は,このオンラインドキュメントに則り先程解説したプロセスで JVM 言語の中間言語である class ファイルに変換させていきます。
では RubyVM はどうでしょうか。RubyVM はコミュニティ主体ということもあり,オンラインドキュメントも企業主体の Java と比較してしまうと,どうしても見劣りしてしまいます。
なので,私が盛り上げるぞ!!!という気持ちでこの記事を書いていたり登壇をしていたりします。Ruby 歴は 3 ヶ月目ですが(笑)
ドキュメントがないので,C 言語のコードを読むしかありません。そして読んだ結果を誰かが紡いでいくしかありません。
ということで,私が C 言語のコードを読んで理解したものを書いて行きます。
RubyVM のバイナリ構造
YARV の生みの親の Sasada Koichi さんの以下の記事で設計思想がある程度読み取れます。
とはいえ大枠のバイナリの形式がどうなっているかについては,様々な記事があるので Ruby 3.2 をベースに以下にまとめてみました[1]。
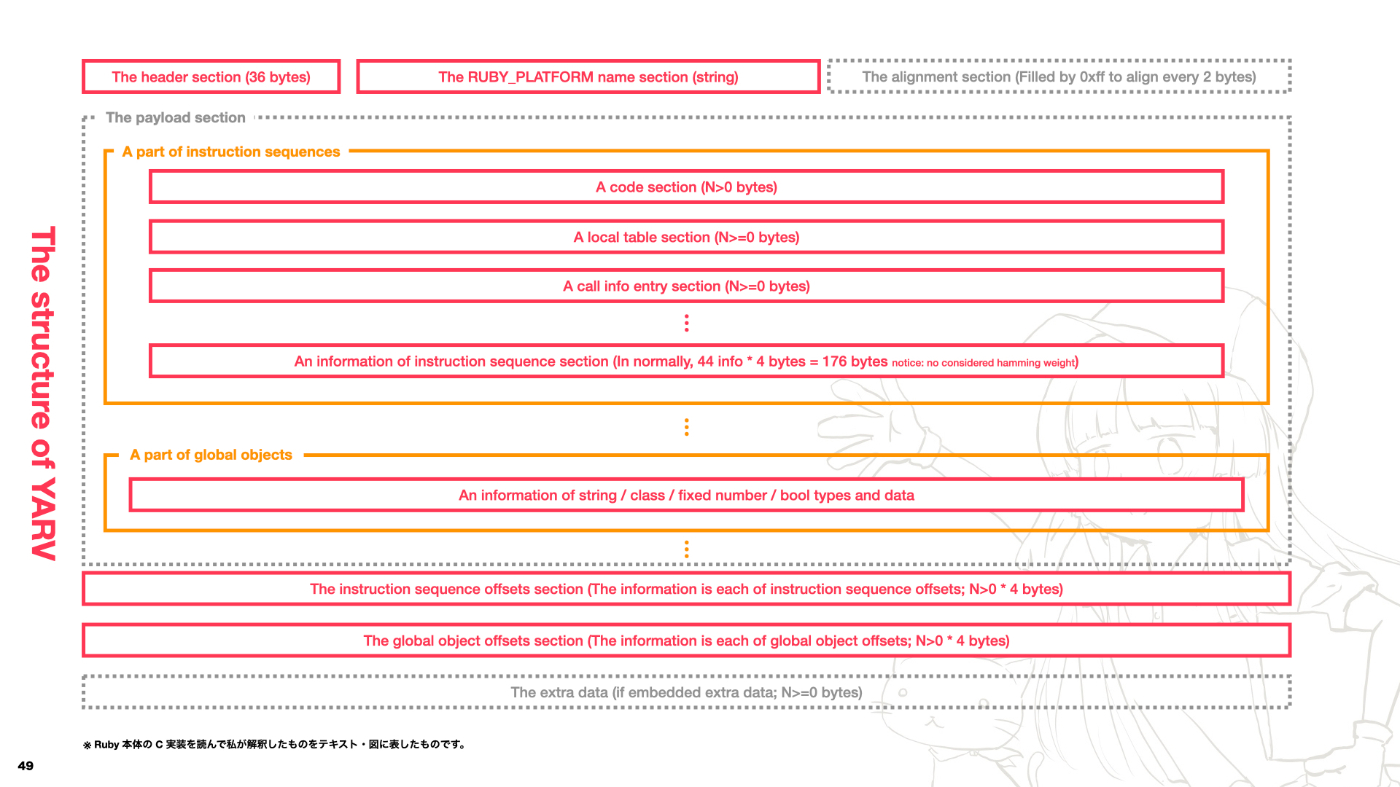
- ヘッダーセクション 左上からコンパイルされた Ruby のバージョン情報などが埋め込まれている
-
Ruby プラットフォームセクション コンパイルされた Ruby の環境などが埋め込まれています。例えば
arm64-darwin22(macOS) やx86_64-linux(Linux) です。\x00(文字列終端)まで読み込みます。 - アラインメントセクション 正直ちょっとあんまり(なぜ存在しているのか)詳しくわかってないんですが,2 バイトごとにバイナリを読み込めるように調整するためのセクションが用意されているようです(自信あまりなし)。
-
ペイロードセクション 命令シーケンス郡,グローバルオブジェクト郡が格納されているセクション。
- 命令シーケンス郡セクション Instruction Sequence (命令シーケンス),つまり中間言語に翻訳された Ruby のコードと,それに付随するメタ情報が格納されているセクションです。メタ情報には例外テーブルであったり,呼び出されるメソッドの引数情報などが格納されています。
-
グローバルオブジェクトセクション YARV でグローバルオブジェクトと呼んでいるのは使われているクラス情報,文字列,数字,シンボル(Ruby のシンタックスである
:symbolのこと)などの情報が埋め込まれています。JVM でいえば Constant Pool の役割を果たしていると認識するとわかりやすいかもしれません。
- 命令シーケンスのオフセットセクション 命令シーケンスがバイナリファイルの絶対位置から見て,どこから始まるのかオフセットの情報が格納されているセクションです。
- グローバルオブジェクトのオフセットセクション 上記同様に,グローバルオブジェクトがバイナリファイルの絶対位置から見て,どこから始まるのかオフセットの情報が格納されているセクションです。
- エクストラデータセクション バイナリファイルに埋め込まれているユーザーランドの文字列情報です。
概ね上記のような仕組みになっています。ヘッダーセクションに 命令シーケンスのオフセットセクション と グローバルオブジェクトのオフセットセクション,エクストラデータセクション のオフセット情報が記されています。ゆえに基本的には,このヘッダーセクションを読み込むところから,RubyVM の開発がスタートします。
読み込んだあとの流れも踏まえると大まかに以下のような流れになります。
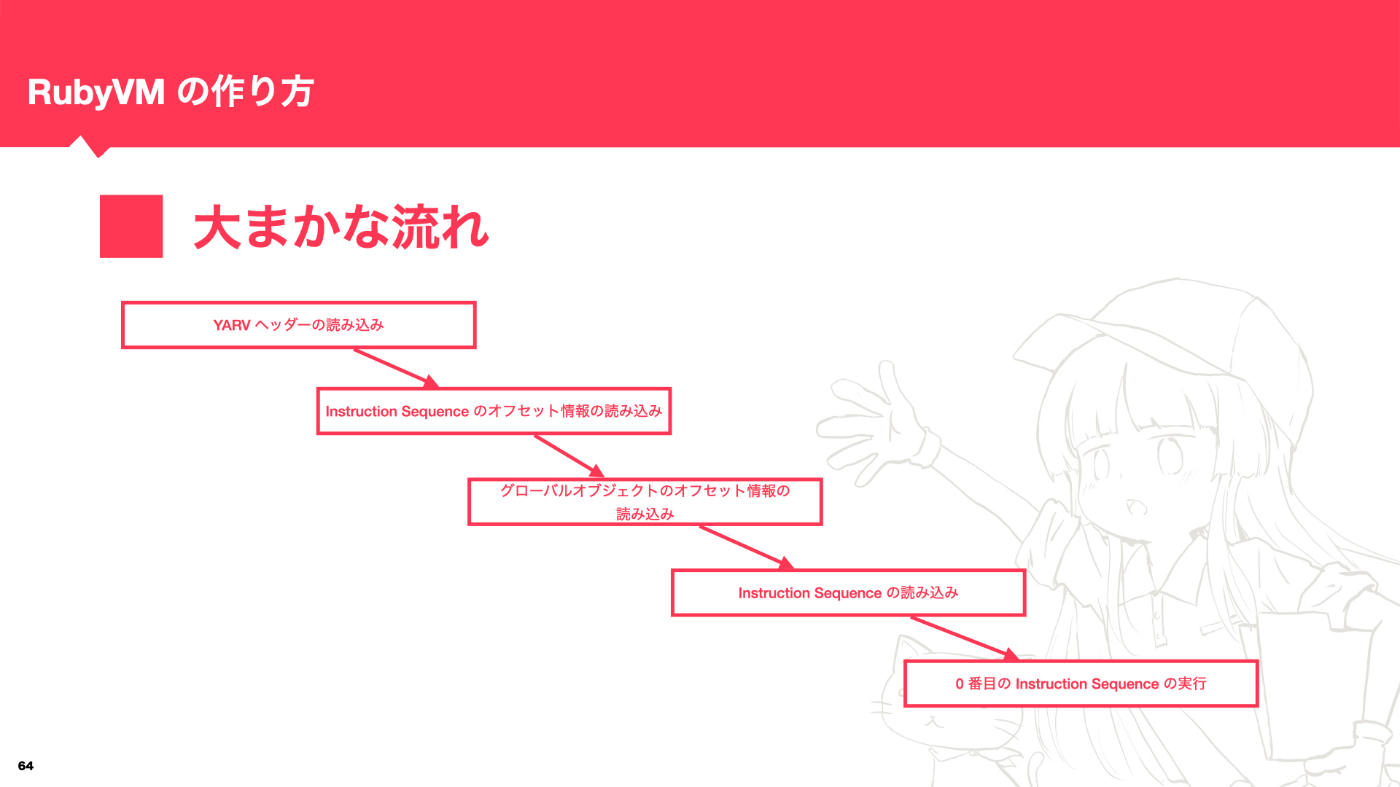
YARV の作り方
中間言語を実行させるのが VM だと先程解説しました。つまり,中間言語,つまり YARV に事前に変換させることが必要になります。
YARV を出力するためには RubyVM::InstructionSequence.compile を使用します。
以下のように Ruby のコマンドを実行し HelloWorld.yarv を作成します。
$ ruby -e "puts RubyVM::InstructionSequence.compile(\"puts 'HelloWorld\!\\n'\", \"HelloWorld.rb\").to_binary" > HelloWorld.yarv
そうすると現在のディレクトリに HelloWorld.yarv ができるので xxd コマンドでバイナリの様子を見てみます。
$ xxd HelloWorld.yarv
┌────────┬─────────────────────────┬─────────────────────────┬────────┬────────┐
│00000000│ 59 41 52 42 03 00 00 00 ┊ 02 00 00 00 e8 00 00 00 │YARB ┊ × │
│00000010│ 00 00 00 00 01 00 00 00 ┊ 05 00 00 00 94 00 00 00 │ ┊ × │
│00000020│ d4 00 00 00 61 72 6d 36 ┊ 34 2d 64 61 72 77 69 6e │× arm6┊4-darwin│
│00000030│ 32 32 00 25 2b 07 67 79 ┊ 03 01 03 03 03 01 03 01 │22 %+ gy┊ │
│00000040│ 01 03 00 ff ff ff ff ff ┊ ff ff ff 01 01 03 05 05 │ ×××××┊××× │
│00000050│ 09 29 03 01 01 01 0d 45 ┊ 0b 01 01 01 01 01 01 01 │ ) E┊ │
│00000060│ 01 3b 01 03 05 05 03 07 ┊ 03 01 05 03 3b 13 09 0b │ ; ┊ ; │
│00000070│ 01 0b 00 ff ff ff ff ff ┊ ff ff ff 01 00 ff ff ff │ ×××××┊××× ×××│
│00000080│ ff ff ff ff ff 0b 03 01 ┊ 01 01 01 01 01 03 05 01 │××××× ┊ │
│00000090│ 01 00 00 00 55 00 00 00 ┊ f1 09 00 00 45 03 1b 48 │ U ┊× E H│
│000000a0│ 65 6c 6c 6f 57 6f 72 6c ┊ 64 2e 72 62 45 05 15 3c │elloWorl┊d.rbE <│
│000000b0│ 63 6f 6d 70 69 6c 65 64 ┊ 3e 00 00 00 45 03 19 48 │compiled┊> E H│
│000000c0│ 65 6c 6c 6f 57 6f 72 6c ┊ 64 21 0a 00 14 05 09 70 │elloWorl┊d! p│
│000000d0│ 75 74 73 00 98 00 00 00 ┊ 9c 00 00 00 ac 00 00 00 │uts × ┊× × │
│000000e0│ bc 00 00 00 cc 00 00 00 ┊ 0a │× × ┊ │
└────────┴─────────────────────────┴─────────────────────────┴────────┴────────┘
RubyVM の実装とはとどのつまり HelloWorld.yarv ファイルを読み込んでいくことになります。
ヘッダーセクション
ヘッダーセクションは Ruby 3.2 時点では 36 バイトの構成からなるものです。上から順に
-
マジックバイト (
YARB) -
Ruby のメジャーバージョン (
3) -
Ruby のマイナーバージョン (
2) - size バイナリファイルの文字列長
- extra size エクストラデータセクションの文字列長
- iseq size 命令シーケンスの数が入っています
- global object list size グローバルオブジェクトの数が入っています
- iseq list offset 命令シーケンスのオフセットセクション のオフセット情報が入っています
- global object list offset グローバルオブジェクトのオフセットセクション のオフセット情報が入っています
ここで エクストラデータセクション はどうなるのか?と思った方もいらっしゃるかもしれません。 size が エクストラデータセクション のオフセットとイコールです。
JVM (Java Virtual Machine) Spec (Specification) の形式で表すと以下のようになります。
HeaderSection {
c4 magic
u4 major_version
u4 minor_version
u4 size
u4 extra_size
u4 iseq_list_size
u4 global_object_list_size
u4 iseq_list_offset
u4 global_object_list_offset
}
c4 は char が 4 byte 分, u4 は unsigned int が 4 byte 文,以後出てくる str は文字列, sv は small value (後述) です。
以降は JVM Spec で表して解説します。
PHP でバイナリを読むには
さて,これらを PHP で読み取るにはどうしたらいいでしょうか。PHP には実はバイナリを読むのに便利な関数があります。fread と fseek と unpack です。
C 言語と違って int[3] と指定したら,その数だけ数字型で読み込んでくれるわけではないので,PHP では unpack が欠かせません。まぁなくてもやろうと思えばできますが。
そして fread で任意のバイト数を読み込み,指定されたオフセットへ移動させるためには fseek を用います。
実際に読み込んで見る
ヘッダーセクションを読み込むためには PHP で以下のコードを書きます。
unpack の V は unsigned int を指しています。詳しくは PHP の pack の説明を見てみてください。
// HelloWorld.yarv を読み込みモードで開く
$handle = fopen(__DIR__ . '/HelloWorld.yarv', 'r');
// c4 magic
$magic = fread($handle, 4);
// u4 major_version
$majorVersion = unpack('V', fread($handle, 4))[1];
// u4 minor_version
$minorVersion = unpack('V', fread($handle, 4))[1];
// u4 size
$size = unpack('V', fread($handle, 4))[1];
// u4 extra_size
$extraSize = unpack('V', fread($handle, 4))[1];
// u4 iseq_list_size
$iSeqListSize = unpack('V', fread($handle, 4))[1];
// u4 global_object_list_size
$globalObjectListSize = unpack('V', fread($handle, 4))[1];
// u4 iseq_list_offset
$iSeqListOffset = unpack('V', fread($handle, 4))[1];
// u4 global_object_list_offset
$globalObjectListOffset = unpack('V', fread($handle, 4))[1];
// 出力してみる
var_dump(
$magic, $majorVersion, $minorVersion,
$size, $extraSize, $iSeqListSize,
$globalObjectListSize, $iSeqListOffset, $globalObjectListOffset,
);
上記の書かれたコードを test.php として保存しておきましょう。
出力結果は以下のようになります。
$ php test.php
string(4) "YARB"
int(3)
int(2)
int(232)
int(0)
int(1)
int(5)
int(148)
int(212)
本来はこのヘッダーの値が正しいか検証をするような仕組みが本家の RubyVM には備わっているのですが,Hello World を出力するレベルならそこまで煩わしいことをしなくてもいいでしょう。
それよりも,プログラミングに対する感情である「動くことが楽しい」と感じることいがとても大事です。
Ruby プラットフォームセクション
資料中では省略していましたが,せっかくの記事なのでプラットフォームセクションを取ってみます。
PlatformSection {
str platform_name
}
さて,ほとんどの人は知っているかもしれませんが,文字列には文字列終端という概念があります。何かしらの文字で文字列が終わりであるということを表します。それは "\x00" つまり NULL バイトです。
Ruby プラットフォームセクションについても例外ではありません。つまり NULL バイトまで読み込めばいいのです。
以下のように PHP で読み込みます。
// 文字列を格納するための変数
$rubyPlatformName = '';
// NULL バイトまでかつ,ファイル終端ではない間繰り返す
while (($char = fread($handle, 1)) !== "\x00" && !feof($handle)) {
$rubyPlatformName .= $char;
}
// 出力してみる
var_dump($rubyPlatformName);
出力がうまくいくと,以下のようにコンパイルされた環境が出力できます。
string(14) "arm64-darwin22"
命令シーケンスオフセットセクション
書かれているバイナリの構造とは読み込む順番が前後していますね。理由はペイロードセクションは命令シーケンスオフセットセクションとグローバルオブジェクトオフセットセクションを読み取ってから出ないと,参照する事ができないためです。
そういうことなので,まずは命令シーケンスオフセットセクションから読み込んでいきます。
ISeqOffsets {
u4 offsets[]
}
オフセット情報は配列かつ u4 で格納されているため,以下のように取得します。
$iseqListOffsets = [];
// 先ほど取得したオフセット先に移動
fseek($handle, $iSeqListOffset, SEEK_SET);
// オフセットの数だけ取得
for ($i = 0; $i < $iSeqListSize; $i++) {
$iseqListOffsets[] = unpack('V', fread($handle, 4))[1];
}
グローバルオブジェクトオフセットセクション
グローバルオブジェクトオフセットセクションについても命令シーケンスオフセットセクションと同じ取得方法で得ることが可能です。
GlobalObjectOffsets {
u4 offsets[]
}
$globalObjectListOffsets = [];
// 先ほど取得したオフセット先に移動
fseek($handle, $globalObjectListOffset, SEEK_SET);
// オフセットの数だけ取得
for ($i = 0; $i < $globalObjectListSize; $i++) {
$globalObjectListOffsets[] = unpack('V', fread($handle, 4))[1];
}
ペイロードセクション
オフセットの情報を得られたら,ペイロードセクションを読み込んでいきます。
ibf_load_small_value の実装
以後はバイナリ文字列を効率的に扱うために small_value というものを実装する必要があります。
C 言語側の実装は以下のようになっています。[2]
static VALUE
ibf_load_small_value(const struct ibf_load *load, ibf_offset_t *offset)
{
if (sizeof(VALUE) > 8 || CHAR_BIT != 8) {
union { char s[sizeof(VALUE)]; VALUE v; } x;
memcpy(x.s, load->current_buffer->buff + *offset, sizeof(VALUE));
*offset += sizeof(VALUE);
return x.v;
}
enum { max_byte_length = sizeof(VALUE) + 1 };
const unsigned char *buffer = (const unsigned char *)load->current_buffer->buff;
const unsigned char c = buffer[*offset];
ibf_offset_t n =
c & 1 ? 1 :
c == 0 ? 9 : ntz_int32(c) + 1;
VALUE x = (VALUE)c >> n;
if (*offset + n > load->current_buffer->size) {
rb_raise(rb_eRuntimeError, "invalid byte sequence");
}
ibf_offset_t i;
for (i = 1; i < n; i++) {
x <<= 8;
x |= (VALUE)buffer[*offset + i];
}
*offset += n;
return x;
}
ntz_int32 は rb_popcount32 であり,以下のようなコードになっています[3],
static inline unsigned int
rb_popcount32(uint32_t x)
{
#if defined(_MSC_VER) && defined(__AVX__)
/* Note: CPUs since Nehalem and Barcelona have had this instruction so SSE
* 4.2 should suffice, but it seems there is no such thing like __SSE_4_2__
* predefined macro in MSVC. They do have __AVX__ so use it instead. */
return (unsigned int)__popcnt(x);
#elif __has_builtin(__builtin_popcount)
STATIC_ASSERT(sizeof_int, sizeof(int) * CHAR_BIT >= 32);
return (unsigned int)__builtin_popcount(x);
#else
x = (x & 0x55555555) + (x >> 1 & 0x55555555);
x = (x & 0x33333333) + (x >> 2 & 0x33333333);
x = (x & 0x0f0f0f0f) + (x >> 4 & 0x0f0f0f0f);
x = (x & 0x001f001f) + (x >> 8 & 0x001f001f);
x = (x & 0x0000003f) + (x >>16 & 0x0000003f);
return (unsigned int)x;
#endif
}
ぱっと見何をしているかわからないと思います。ibf_load_small_value がやっていることはハミング重みを用いて立っているビット数分,整数として読み進めるための関数です。
ハミング重みが何かというと例えば以下のような 8 ビットのものがあったとします。
1010 0101
このとき 4 つのビットが立っているので,ハミング重みは 4 となります。
で,先頭の 1 バイトをこのビットのフラグを立たせるようにしてそれプラス指定されたバイト数分読み込ませるというのが,この ibf_load_small_value の仕組みです。
<-バイト-> <--読み込むバイト分-->
1000 0100 1101 1010 1010 1010 ....
例えば unsigned int 分読み込むとしたら,先頭の 1 バイトと 4 バイトなので,合計 5 バイト分消費します。
これを PHP で実装すると以下のようになります。
function readSmallValue(): int
{
global $handle;
$offset = ftell($handle);
// ハミング重み
$ntzInt32 = function (int $x): int {
$x = ~$x & ($x - 1);
$x = ($x & 0x55555555) + ($x >> 1 & 0x55555555);
$x = ($x & 0x33333333) + ($x >> 2 & 0x33333333);
$x = ($x & 0x0F0F0F0F) + ($x >> 4 & 0x0F0F0F0F);
$x = ($x & 0x001F001F) + ($x >> 8 & 0x001F001F);
$x = ($x & 0x0000003F) + ($x >> 16 & 0x0000003F);
return $x;
};
$c = unpack('C', fread($handle, 1))[1];
$n = ($c & 1)
? 1
: (0 == $c ? 9 : $ntzInt32($c) + 1);
$x = $c >> $n;
if (0x7F === $x) {
$x = 1;
}
for ($i = 1; $i < $n; ++$i) {
$x <<= 8;
$x |= unpack('C', fread($handle, 1))[1];
}
fseek(
$handle,
$offset + $n,
SEEK_SET,
);
return $x;
}
グローバルオブジェクトを読み込むための loadObject
取得したグローバルオブジェクトを読み込むための loadObject を実装します。
C 言語側では ibf_load_object で実装されています[4]。Hello World の出力であれば,すべて実装する必要はないので,必要な部分だけかいつまんで実装します。
PHP で実装する場合は以下のようになります。
function loadObject(int $offset)
{
global $handle;
$current = ftell($handle);
fseek($handle, $offset, SEEK_SET);
$byte = ord(fread($handle, 1));
// ビットに読み込むべき種類が格納されています。
$type = ($byte >> 0) & 0x1f;
$ret = null;
// 5 は文字列を読む処理。20 はシンボルを読む処理だが,今回は文字列を読み込むのと同等で問題ない
// https://github.com/ruby/ruby/blob/ruby_3_2/compile.c#L12919 を参照するとわかる。
if ($type === 5 || $type === 20) {
// NOTE: エンコーディング手法の情報。今回は使わない。
$encIndex = readSmallValue();
// 文字列長の取得
$len = readSmallValue();
$ret = fread($handle, $len);
} else {
throw new RuntimeException("未実装です ({$type})");
}
fseek($handle, $current, SEEK_SET);
return $ret;
}
これでペイロードセクションのグローバルオブジェクトセクションが読み込めるようになりました。
さて,これで下準備は完了です。
命令シーケンスセクション
本命の実装です。命令シーケンスセクションを読み込んでいきましょう。資料では Appendix になっていた CallInfoEntry もついでに読み込んでいきます。
C 言語側では,読み込むパラメーターの数が多くて[5]カオスな事になっていますが…w
IseqSection {
sv type
sv iseq_size
sv bytecode_offset
sv bytecode_size
sv param_flags
sv param_size
sv param_lead_num
sv param_opt_num
sv param_rest_start
sv param_post_start
sv param_post_num
sv param_block_start
sv param_opt_table_offset
sv param_keyword_offset
sv location_pathobj_index
sv location_base_label_index
sv location_label_index
sv location_first_lineno
sv location_node_id
sv location_code_location_beg_pos_lineno
sv location_code_location_beg_pos_column
sv location_code_location_end_pos_lineno
sv location_code_location_end_pos_column
sv insns_info_body_offset
sv insns_info_positions_offset
sv insns_info_size
sv local_table_offset
sv catch_table_size
sv catch_table_offset
sv parent_iseq_index
sv local_iseq_index
sv mandatory_only_iseq_index
sv ci_entries_offset
sv outer_variables_offset
sv variable_flip_count
sv local_table_size
sv ivc_size
sv icvarc_size
sv ise_size
sv ic_size
sv ci_size
sv stack_max
sv catch_except_p
sv builtin_inline_p
}
Hello World の出力であれば,一部のパラメーター以外は不要です。具体的に使用するのは bytecode_offset, bytecode_size, ci_entries_offset ciSize だけです。
PHP で読み込んでいくと以下のようになります。
// iseqListOffsets の 0 番目には,はじめに実行するメインコンテキストの iseq の情報が格納されています。
// そのため 0 番目のオフセットを参照します。
fseek($handle, $iseqListOffsets[0], SEEK_SET);
$type = readSmallValue();
$iseqSize = readSmallValue();
$bytecodeOffset = readSmallValue();
$bytecodeSize = readSmallValue();
// $bytecodeSize の真下に追加
$paramFlags = readSmallValue(); // 使用しない
$paramSize = readSmallValue(); // 使用しない
$paramLeadNum = readSmallValue(); // 使用しない
$paramOptNum = readSmallValue(); // 使用しない
$paramRestStart = readSmallValue(); // 使用しない
$paramPostStart = readSmallValue(); // 使用しない
$paramPostNum = readSmallValue(); // 使用しない
$paramBlockStart = readSmallValue(); // 使用しない
$paramOptTableOffset = readSmallValue(); // 使用しない
$paramKeywordOffset = readSmallValue(); // 使用しない
$locationPathObjIndex = readSmallValue(); // 使用しない
$locationBaseLabelIndex = readSmallValue(); // 使用しない
$locationLabelIndex = readSmallValue(); // 使用しない
$locationFirstLineNo = readSmallValue(); // 使用しない
$locationNodeId = readSmallValue(); // 使用しない
$locationCodeLocationBegPosLineNo = readSmallValue(); // 使用しない
$locationCodeLocationBegPosColumn = readSmallValue(); // 使用しない
$locationCodeLocationEndPosLineNo = readSmallValue(); // 使用しない
$locationCodeLocationEndPosColumn = readSmallValue(); // 使用しない
$insnsInfoBodyOffset = readSmallValue(); // 使用しない
$insnsInfoPositionsOffset = readSmallValue(); // 使用しない
$insnsInfoSize = readSmallValue(); // 使用しない
$localTableOffset = readSmallValue(); // 使用しない
$catchTableSize = readSmallValue(); // 使用しない
$catchTableOffset = readSmallValue(); // 使用しない
$parentISeqIndex = readSmallValue(); // 使用しない
$localISeqIndex = readSmallValue(); // 使用しない
$mandatoryOnlyIseqIndex = readSmallValue(); // 使用しない
$ciEntriesOffset = readSmallValue();
$outerVariablesOffset = readSmallValue(); // 使用しない
$variableFlipCount = readSmallValue(); // 使用しない
$localTableSize = readSmallValue(); // 使用しない
$ivcSize = readSmallValue(); // 使用しない
$icvArcSize = readSmallValue(); // 使用しない
$iseSize = readSmallValue(); // 使用しない
$icSize = readSmallValue(); // 使用しない
$ciSize = readSmallValue();
// 以降のパラメータは使わないので省略
次に CallInfoEntry を読み込んでいきます。CallInfoEntry は,メソッド呼び出しの際の引数の情報や,キーワード引数を有する場合はその情報,呼び出すメソッド名などの情報が格納されています。あとはメソッドのアクセス修飾子あたりです。
PHP では以下のように読み取ります。
// call info entries の読み込み
// $ciEntriesOffset の位置は iseqListOffset からみて相対位置になるので,マイナスしています。
fseek($handle, $iseqListOffsets[0] - $ciEntriesOffset, SEEK_SET);
$callInfoEntries = [];
for ($i = 0; $i < $ciSize; $i++) {
// メソッド名
$methodName = loadObject($globalObjectListOffsets[readSmallValue()]);
// メソッドの種別(今回は使わない)
$flag = readSmallValue();
// 引数の数
$argCount = readSmallValue();
$callInfoEntries[] = [$methodName, $argCount];
}
// 出力してみる
var_dump($callInfoEntries);
実際に出力すると以下のようになります。
array(1) {
[0]=>
array(2) {
[0]=>
string(4) "puts"
[1]=>
int(1)
}
}
それっぽくなってきましたね。
バイトコードの読み込み
バイトコードを読み込む前に,opcode と,実行するニーモニックを紐づけします。
opcode とはオペレーションコードを指し,ニーモニックはその番号にヒューマンリーダブルな意味を加えたものだと認識すると良いです。RubyVM のオペレーションコードとニーモニックの具体的な紐づけは cruby_bindings.inc.rs を読むとわかります。
Hello World の出力においては,すべてを実装する必要はないので,以下の opcode とニーモニックの実装を行います。
| opcode | mnemonic (ニーモニック) | 概要 |
|---|---|---|
| 18 | putself | 実行中のコンテキストをスタック上に積む |
| 21 | putstring | 文字列をスタック上に積む |
| 51 | opt_send_without_block | 指定されたメソッドを実行 |
| 60 | leave | 返り値を返してそのコンテキストを終了 |
これらの opcode などを詳しく実装するには codegen.rs などを眺めると良いです。
また putself 命令では,メインコンテキストをスタック上に積む必要があるので,puts メソッドを持った main クラスを実装しておきます。
$mnemonic = [
18 => 'putself',
21 => 'putstring',
51 => 'opt_send_without_block',
60 => 'leave',
];
class Main
{
public function puts($string): void
{
echo $string;
}
}
大枠の仕組みができました。次に,それぞれのニーモニックを実装していきます。
// バイトコード先に移動します。
fseek($handle, $iseqListOffsets[0] - $bytecodeOffset, SEEK_SET);
$stacks = [];
for ($codeIndex = 0, $ciIndex = 0; $codeIndex < $iseqSize; $codeIndex++) {
$code = readSmallValue();
switch ($mnemonic[$code] ?? null) {
case 'putself': // 18
// Main コンテキストをスタックにプッシュさせます。
$stacks[] = new Main();
break;
case 'putstring': // 21
// グローバルオブジェクトのオフセットの情報を取得します。
$pos = readSmallValue();
$objectPos = $globalObjectListOffsets[$pos];
// グローバルオブジェクトを取得します
$stacks[] = loadObject($objectPos);
break;
case 'opt_send_without_block': // 51
[$methodName, $argCount] = $callInfoEntries[$ciIndex++];
$arguments = [];
for ($k = 0; $k < $argCount; $k++) {
$arguments[] = array_pop($stacks);
}
$callee = array_pop($stacks);
// メソッドを呼び出し
$callee->{$methodName}(...$arguments);
break;
case 'leave': // 60
// NOTE: 今回の例では特に実装不要。返り値などが必要な場合に leave コマンドで操作する必要があります。
break;
}
}
ここで以下のように実行してみると HelloWorld! が出力されることがわかります。
$ php test.php
HelloWorld!
これで自作 RubyVM で HelloWorld! まで出力できましたね!
文字列を変えるぐらいだったら動作しますので,HelloWorld.yarv で出力させたい文字列を以下のように変えてみます。
$ ruby -e "puts RubyVM::InstructionSequence.compile(\"puts 'Neko Neko Nyan Nyan\\n'\", \"HelloWorld.rb\").to_binary" > HelloWorld.yarv
もう一度 php test.php と実行してみましょう。
$ php test.php
Neko Neko Nyan Nyan
文字列が変わって出力されるのがわかりました。正しく動いていそうですね。
コードまとめ
Gist にまとめています。また,本格的に PHP で実装するにはどうしたらいいかについては以下を御覧ください。
Gist は最小限必要な実装のみになってます。
- gist: https://gist.github.com/m3m0r7/226e20c8115caf4a9d43b291861f978b
- rubyvm-on-php: https://github.com/m3m0r7/rubyvm-on-php
個人的なプロジェクトとしては四則演算はじめ,クラスの実装,メソッドの実装,正規表現の実装,ブロックの実装などは終えており,FizzBuzz やフィボナッチ数列,クイックソートなどが動作するなど多岐に渡って実装してあります。
デバッグ方法について
HelloWorld 以降へ実装を進めるとどういうニーモニックが渡ってくるかわからない場合もあります。そういった場合は Ruby が提供している puts RubyVM::InstructionSequence.compile_file('ファイル名').disasm を使うと以下のようにどういった命令があるのか確認できます。Java で言うところの javap コマンドに似ています。
== disasm: #<ISeq:<main>@test.rb:1 (1,0)-(1,19)> (catch: false)
0000 putself ( 1)[Li]
0001 putstring "Hello World!"
0003 opt_send_without_block <calldata!mid:puts, argc:1, FCALL|ARGS_SIMPLE>
0005 leave
これをひたすらなぞって,正しい opcode になっているか,引数の数は大丈夫か,呼び出そうとしているメソッドは正しいか,など検証しながら進めていくことになろうかと思います。
次に向けて
HelloWorld の出力が完了したら,次は文字列ではなく整数を扱う,次に四則演算…,文字列結合…,条件分岐,ループ文,FizzBuzz … など段階を踏んで実装していくと良いでしょう。Ruby は四則演算は任意に上書きできるように設計されていますが,最初は,そこまで気にせずやると良いと思います。私も最初は上書きできることを知らないでそのまま実装して直近でリライトしています。
VM づくりを楽しいと思う人が増えていくと嬉しいなと思っています。それでは。
-
foobar セクション のように名付けしていますが,これは私がそう呼称しているだけであり,本家がどう呼称しているかはわかりかねます。正式な呼び方があったら教えてくれ!! ↩︎
-
https://github.com/ruby/ruby/blob/ruby_3_2/compile.c#L11312 ↩︎
-
https://github.com/ruby/ruby/blob/b28c1d2c5644c726bba60cd35ce9313da6e86a4f/parser_bits.h#L450 ↩︎
-
https://github.com/ruby/ruby/blob/ruby_3_2/compile.c#L12955 ↩︎
-
https://github.com/ruby/ruby/blob/ruby_3_2/compile.c#L12169-L12214 ↩︎
Discussion