AHC047参加記【164位】
問題
ざっくりとした解法
- 各テストケースについて、スコアが大きい順に3つの文字列を採用とする
- 文字列の中での遷移をカウントして記憶する。但し、単純な回数ではなくスコアで傾斜をつける。
- それをそのまま確率行列に採用して、合計が100になるように正規化する。
- 提出
https://atcoder.jp/contests/ahc047/submissions/65957456
164位 3960028 perf1884
ビジュアライザ
Seed=0 26190

Seed=11 49033
解説
ぱっと問題読んだときの感想は「うわーだるそう」だった。
とりあえず、validな提出のために全部の確率が均等になるような解を作って出してみる。
Score = 2529

赤い文字列もあるけど、短くてスコアの低いものしか採用されていない。そのため全体スコアもかなり低い。
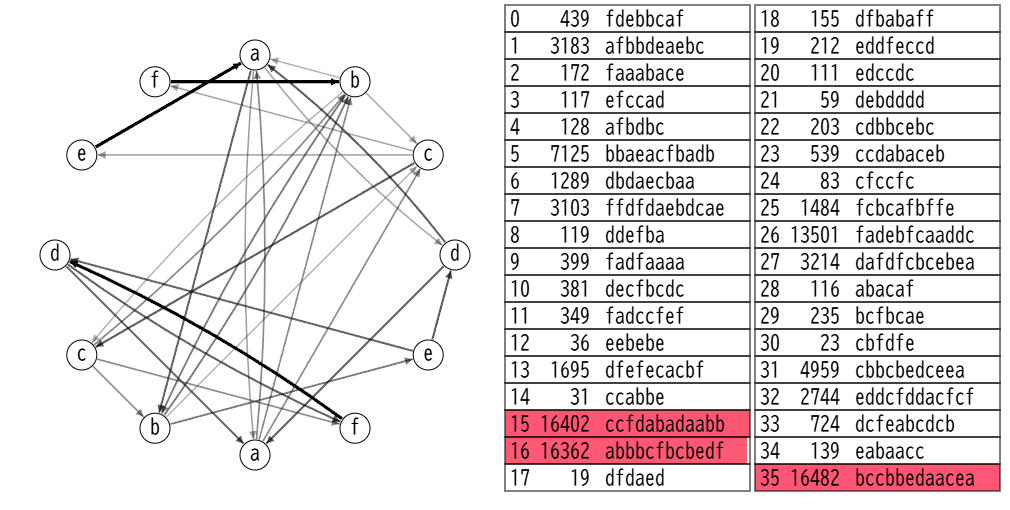
次に、最もスコアの高い文字列が100%生成される解を出してみる。制約の中で、M=12でSは6<=Si<=12なので、ぐるっと回る矢印のみがあるような行列と、その状態を設定すれば可能。
Score = 15639

一気に高くなる。そのため、スコアが高いものを優先して採用することが結構大事という考え方になった。
とりあえずということで、スコアが高い文字列2つ3つくらいがまあまあな確率で生成されてくれれば結構なところまでスコアが伸びそうという見通しになったので、そういうのが生成できるような行列を考えてみる。
遷移が問題になるので、単純に遷移をカウントしてみることにする。
但し、予め状態はabcdefabcdef固定にして考える。
例として、Seed=0の一番スコアの高い8の文字列では、
d->cが1回、c->fが1回、f->aが1回、a->aが1回....
というように今の文字と次の文字を見てその回数をカウントする。ただし、同じ文字が2連続で出てきた場合には別の方の状態に振ってみる。
var previous = s[0] - 'a'
for (i in 0 until s.length - 1) {
var next = s[i + 1] - 'a'
if (previous == next) {
next += 6
}
A[previous][next]++
previous = next
}
これを、スコアの高い3つの文字列についてやって、行列の形にする。
あとは、提出できるように、横の合計が100になるように正規化する。余りは滑らかになるように均等に振ってみた。使われない文字列がある場合は適当な場所を100にするのを忘れないように。
Score = 27853
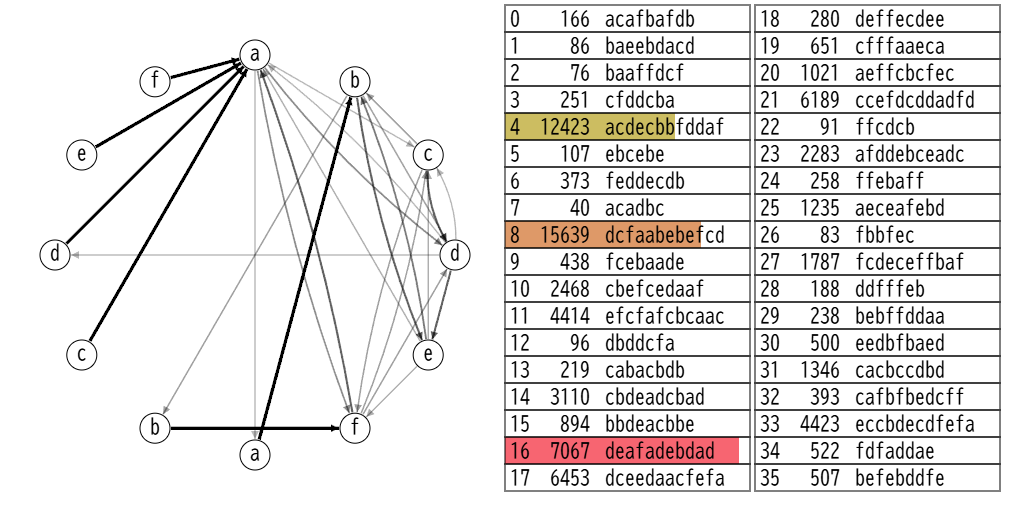
方針としては合っている感触があった。
ただ、このビジュアライザから見た感じ、もうすこし16の確率を下げてでも4と8の確率を上げたい気持ちになる。上の部分でAに単純に1を足して見る代わりに、スコアを足して見ることにした。また、2つある同じ文字の状態が均等に分けられるように順番に使われる処理を追加した。
val countAlphabet = BooleanArray(6) { false }
for (i in sorted.indices) {
val s = sorted[i].s
val p = sorted[i].p
var previous = s[0] - 'a'
for (i in 0 until s.length - 1) {
var next = s[i + 1] - 'a'
if (countAlphabet[next]) {
countAlphabet[next] = false
next += 6
} else {
countAlphabet[next] = true
}
A[previous][next] += p
previous = next
}
}
Score = 26190

seed=0でのスコアは下がってしまったが、Seed=11のように3つの文字列が均等にほぼ100%になるパターンがテストケースのなかに多くなり、全体スコアは上昇。これがほぼ最終提出と同じコードで、絶対スコア3960028、perf1800後半と自己最高の順位までいくことができた。
ここから、概算でもいいのでなにかしらのスコア計算関数ができれば山登りなり焼きなましなりビームサーチなりができたのかもしれないが、全く思いつかなかったためこんな感じのルールベースなのか貪欲なのかよくわからない解法で終わってしまったことが悔やまれる。
まとめ
兎にも角にも過去最高順位と過去最高perfが取れたことがとにかく嬉しかった。
ただ、まだできそうなことがあった上でのこれなので、もっと上に行けたんじゃないかという後悔もちょっと残る感じに。
少なくとも青perfを継続してはいきたい。
あとから思いついたアイデア
- スコアが大きい順に3つ選んだときに、その中にaが1つも入っていないとスコアが0になることにあとから気づいて青ざめた。ただ、35-36文字をランダムに生成したときにaが一つもないパターンはほぼないっぽいので助かった。(5/6)^36 ≒ 0.00141なので1000ケースに1つくらいの期待値。
- 上記と似たような感じになるが、aから状態が始まってしまうと確率的に勿体ない感じがすごいするので、最もスコアの高い文字列目の1文字目が状態0になるように帳尻を合わせて置いたほうがスコアは上がりそう
- 2つある同じ文字の状態が均等になる処理は、実際は更に次の文字を見て判断する形にしたほうが良さそう。例えば、[なにかの文字] -> a -> [なにかの文字]という場合に、aの次の文字がabcならこっちのa、defならこっちのaみたいな方が、本来は適切な感じがする。
- 文字列と文字列の間の遷移を全く気にしてなかったのでそこも考慮したほうがいいような気はする。採用する文字列を最初から結合して、そこから遷移のカウントをしてみるみたいなののほうが本来はいいかもしれない。
Discussion