Elastic Search の Java Client でほしい検索結果を得るためにとりあえず理解したこと
はじめに
この記事は株式会社LabBase テックカレンダー Advent Calendar 2022 18日目の記事です。
株式会社LabBase でエンジニアをしている渡辺創です。
最近、Elasticsearch を触り始めたのですが、クエリの構造を理解したら作りやすくなったのでそのことについて書こうと思います。
概要としては、Compound Queries と Leaf Queries の違いと Full Text Queries と Terms Level Queries の違いを理解したという感じです。
Compound Queries と Leaf Queries
Compound Queries は複数の種類の検索を組み合わせて行うためのクエリで、Leaf Queries はその中でどのような検索を行うか詳細指定するクエリです。Compound=化合物、Leaf=葉、という名前の持つイメージはわかりやすいと思います。
こちらのブログのイメージがわかりやすかったので、引用させていただきます。
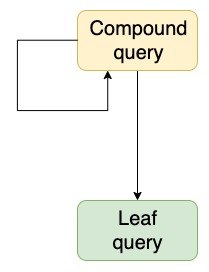
Compound Queries と Leaf Queries の説明はこちらにあります。
まとめると以下のような感じです。
Compound Queries
代表的な Compound Queries として、Bool Queries を取り上げます。
Bool Queries は他のクエリのブール値の組み合わせでドキュメントを検索するクエリです。Leaf Queries にもよりますが、フィールドが一致すればするほど内部スコアが高くなるイメージを持てば良いと思います。
Leaf Queries
bool queries の leaf queries としてはmust, filter, should, must not の4つがあります。
詳しくは公式ドキュメントにありますが、以下のような特徴です。
- must クエリ : AND として使います。スコアの計算に影響する。
- filter クエリ : AND として使います。スコアの計算に影響しない。
- should クエリ : OR として使います。
- must not クエリ : NOT して使います。
Full Text Queris と Term-Level Queries
Full Text Queries の公式ドキュメントが[こちら]
(https://www.elastic.co/guide/en/elasticsearch/reference/current/full-text-queries.html) 、Term-level Queries の公式ドキュメントがこちらになります。
Full Text Queries では分析されて検索されており、Term-level Queries では用語レベルの検索であり、正確な用語一致で検索されます。
このブログを参考にさせていただきました。
言語処理の有無が大きな違いのようです。
ほしい検索結果
弊社のLabBaseというサービスは学生の研究内容を検索して、マッチした学生をスカウトするというサービスのため、以下のようなユースケースが考えられます。
学生の研究内容が書かれたフィールドを複数の単語で全文検索し、学年でフィルタをかけ、閲覧済みの学生を除外する検索を実行したいという設定にします。
ほしい検索結果の分解
クエリを作成するために検索方法を分解します。
研究内容が書かれたフィールドを research(text),
学年のフィールドを year(long),
閲覧済み viewed(boolean),
と仮定して、分解していきます。
研究内容を複数の単語で全文検索 → research フィールドを対象とした、言語処理が必要なor検索
学年が一致する学生のみ検索 → year フィールドを対象とした、言語処理が不要なand検索
閲覧済みの学生を除外する → viewed フィールドを対象とした、言語処理が不要なnot検索
これら3つの種類のクエリを bool クエリで組み合わせることで、作りました。
実際のクエリ
今回は "機械学習"、"自然言語処理"という単語で、学年の値が4、viededがfalseの学生を検索します。
Kibana 上で実行する場合:
GET _search
{
"query": {
"bool": {
// 研究内容部分
"should": [
{
"match": {
"research": {
"query": "機械学習"
}
}
},
{
"match": {
"research": {
"query": "自然言語処理"
}
}
}
],
// 学年部分
"filter": [
{ "term": {"year": 4 }}
],
// 閲覧済み部分
"must_not": [
{
"term": {
"viewed": true
}
}
]
}
}
}
Java Client
// "機械学習"と"自然言語処理"でor検索するクエリ
private ArrayList<Query> makeShouldQuery() {
ArrayList<Query> shouldQueryList = new ArrayList<>();
List<String> wordList = new ArrayList();
wordList.add("機械学習");
wordList.add("自然言語処理");
wordList.stream().forEach(word ->
Query query = MatchQuery.of(m -> m
.field("research")
.query(word)
)._toQuery();
shouldQueryList.add(query);
});
return shouldQueryList;
}
// 学年でフィルタするクエリ
private ArrayList<Query> makeFilterQuery() {
ArrayList<Query> filterQueryList = new ArrayList<>();
Query yearFilterQuery = TermQuery.of(t-> t
.field("year")
.value(4L)
)._toQuery();
filterQueryList.add(yearFilterQuery);
return filterQueryList;
}
// 閲覧済みを除外するクエリ
private ArrayList<Query> makeMustNotQuery() {
ArrayList<Query> mustNotQueryList = new ArrayList<>();
Query viewedMustNotQuery = TermQuery.of(t-> t
.field("viewed")
.value(FieldValue.TRUE)
)._toQuery();
mustNotQueryList.add(viewedMustNotQuery);
return mustNotQueryList;
}
実際に検索する際には、elasticSearchClientのsearchメソッドで以下のように使うことができます。
clientの宣言方法やindexの定義の仕方は公式ドキュメントを参考にしてください。
response = esClient.search(s -> s
.index(index)
.query(q -> q.bool(b -> b
.should(makeShouldQuery())
.filter(makeFilterQuery())
.mustNot(makeMustNotQuery())
)
).size(10), ObjectNode.class);
終わりに
構造的に理解したことでだいぶ簡単にクエリを作れるようになりました。まだそんなに複雑なクエリはつくっていないので、もう少し触ってみて自由自在にクエリを作れるとよいなーという感じです。
Discussion