「Next.jsで理解するSSRとクライアントルーティングの違い」という名目で社内にて簡単に勉強会を行いました。本記事は、その内容を適宜編集して公開するものです。
TL;DR
以下の要約を読んで、「なんだその話か」って思った方は引き返していただいて大丈夫です。逆に「えっそうなの・・・?」と思った方は、ぜひ読んでください!
- Next.jsアプリケーションにおいて、
/hogeと/fugaというページがあり、それぞれgetServerSideProps()が定義されているとします - 最初ブラウザで
/hogeを開いたとき、Next.jsアプリケーションはブラウザから/hogeへのGETリクエストを受け取り、getServerSideProps()を実行します - 次に
/hogeから/fugaへrouter.pushで遷移すると、Next.jsアプリケーションはブラウザから/fugaへのGETリクエストを受け取るわけではありません。ブラウザからは/fugaのgetServerSideProps()を実行し、結果を取得するためだけの特別なエンドポイントが呼び出されます - したがって、たとえばNext.jsをCDN(CloudFront)のバックエンドで動かしていて、
/fugaへのアクセス時のビヘイビア(振る舞い)をチューニングしたい場合、CDN上の/fugaへのビヘイビア設定だけを変えて良いのではなく、router.push時に呼び出されるエンドポイントへの設定も検討しましょう
なお、本記事はPages Router時代を前提として話します。というのも、App Routerの嬉しさを理解するために、大前提としてこういった通信パターンを腹落ちしておく必要があると考えているからです。
本記事の流れ
本記事と同様の主張をする記事は多いですが、フロントエンドの歴史やReactの内部挙動、App Router等の最新情報を掛け合わせていることから、読者に通信パターンを理解させるというIssueには特化していないように感じました。
そこで本記事では、「Next.jsアプリケーションのページを最初に読み込んだときと、router.push時にそれぞれどんな通信がされているの?」というお題を、できるだけ詳細or横道な話に踏み込まずに概念レベルで話していきます。
概念を理解したい方向けの記事にしたつもりなので、細かい技術面の解説をすっ飛ばしています。
仮歴史その1)SPAの誕生
SSRとクライアントルーティングの違いについて理解するには、「なぜSSRとクライアントルーティングが誕生したのか」を考えるとよいです。
そこで、本記事では「仮歴史」として、実際にそういう期間が存在したかはわからないけど、「世界で初めてSPAのような挙動がWeb業界に誕生した瞬間」に思いを馳せてみます。
この時代では、まずWebページを開くと、真っ白な画面が開いて、ローディング表示が行われ、ページ内部のデータが取得し終わると、その内容が表示されます。
今でもSaaSとか管理画面系の画面はこの通信パターンになっていることも多いですね。
ReactだとSWRを使って取得しているパターンがこれに近いです(SWR自体は最近のソリューションだけど、通信パターンで見ると最初期からあるといえる)。
また、違う画面に遷移したときは、画面自体を再読込みするのではなくて、History APIでURLを見た目上書き換えながら、別途遷移先の画面のデータを取得することで、普通に画面全体を再読込みするよりはサクサク遷移することができます。
この時代の通信パターン(だけ)をまとめると以下のとおりです。
- ページAを開く
- サーバー)空っぽHTMLを返す
- ブラウザ)データフェッチ→表示
- その後、ページBを開く
- サーバー)ナシ
- ブラウザ)History書き換え→データフェッチ→表示
- データフェッチ処理を実装する場所
- ブラウザのみ
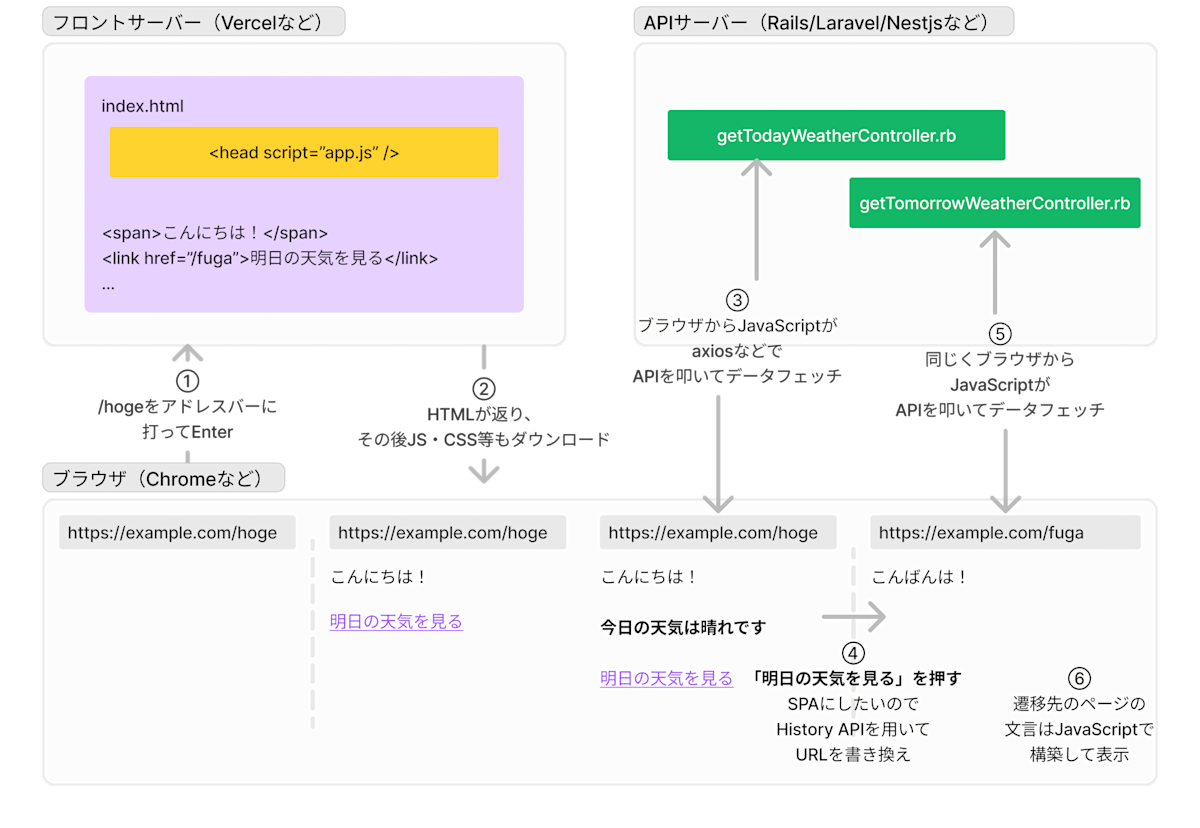
若干余談ですが、この時代だとフロントエンドサーバーはただのファイルサーバー(S3など)でも良いのが嬉しいですね。
※厳密には⑥の直後に「明日の天気」が表示されるイメージですが、図をコンパクトにしたいので割愛しました
※重ねて注釈ですが、めちゃめちゃ技術詳細を省いてます。本記事の目的はSPAやNext.jsを自作することではないので。興味ある方はこの図に足りないところを徹底的に言語化してみると勉強になるかもしれません。
仮歴史その2)原始的SSRの誕生
前回の歴史を経た人たちの感想は、「ページ遷移がサクサクなのはいいけど、初回表示したときに一瞬データが無い状態で画面が開くのが嫌」「Googleのクローラーが情報読み取るのが遅延する(JavaScript実行時までタイムラグが生じる)」といったものでした。
令和のエンジニアはSSRを実現するとしたらNext.jsを使うと思いますが、一旦、Next.jsが無い世界線でどうやってSSR実現するか?考えてみましょう。
SSRを実現するということは、前節の図で言うところの②の時点で、すでにデータが埋まっている状態にしてくれ!ということです。
まず、サーバーにリクエストが到達した時点でデータフェッチして、HTML内にデータの埋め込みをやるべきです。次に、データがすでに埋まったHTMLがブラウザにダウンロードされたあとに、onClickイベントの設定など、ブラウザでしかできない処理を実行します。
また、サーバーをそもそも建てないといけないので、別リポジトリとかでbackend-for-frontendみたいなリポジトリを作って、そこにサーバー処理用のフレームワーク(Expressなど)をセットアップしないといけません。
次に、ページ遷移するときがポイントです。SPAっぽくサクサク遷移させたいから、もう一度サーバーで同じ処理をさせては、MPAと全く同じ挙動になってしまいます。たとえば、
- ページAを開く
- サーバー)データフェッチ→HTMLへの埋め込み
- ブラウザ)HTMLを表示するだけ
- ページBを開く
- サーバー)データフェッチ→HTMLへの埋め込み
- ブラウザ)HTMLを表示するだけ
これだと完全にLaravelやRailsでのView表示と変わりませんね。
そこで開発者は以下の対策を考えます。
【AからBに遷移したとき】
- ページAを開く
- サーバー)データフェッチ→HTMLへの埋め込み
- ブラウザ)HTMLを表示するだけ
- ページBを開く
- ブラウザ)History書き換え→データフェッチ→表示
【BからAに遷移したとき】
-
ページBを開く
- サーバー)データフェッチ→HTMLへの埋め込み
- ブラウザ)HTMLを表示するだけ
-
ページAを開く
- ブラウザ)History書き換え→データフェッチ→表示
-
※データフェッチ処理を実装する場所
- ブラウザとサーバーの両方
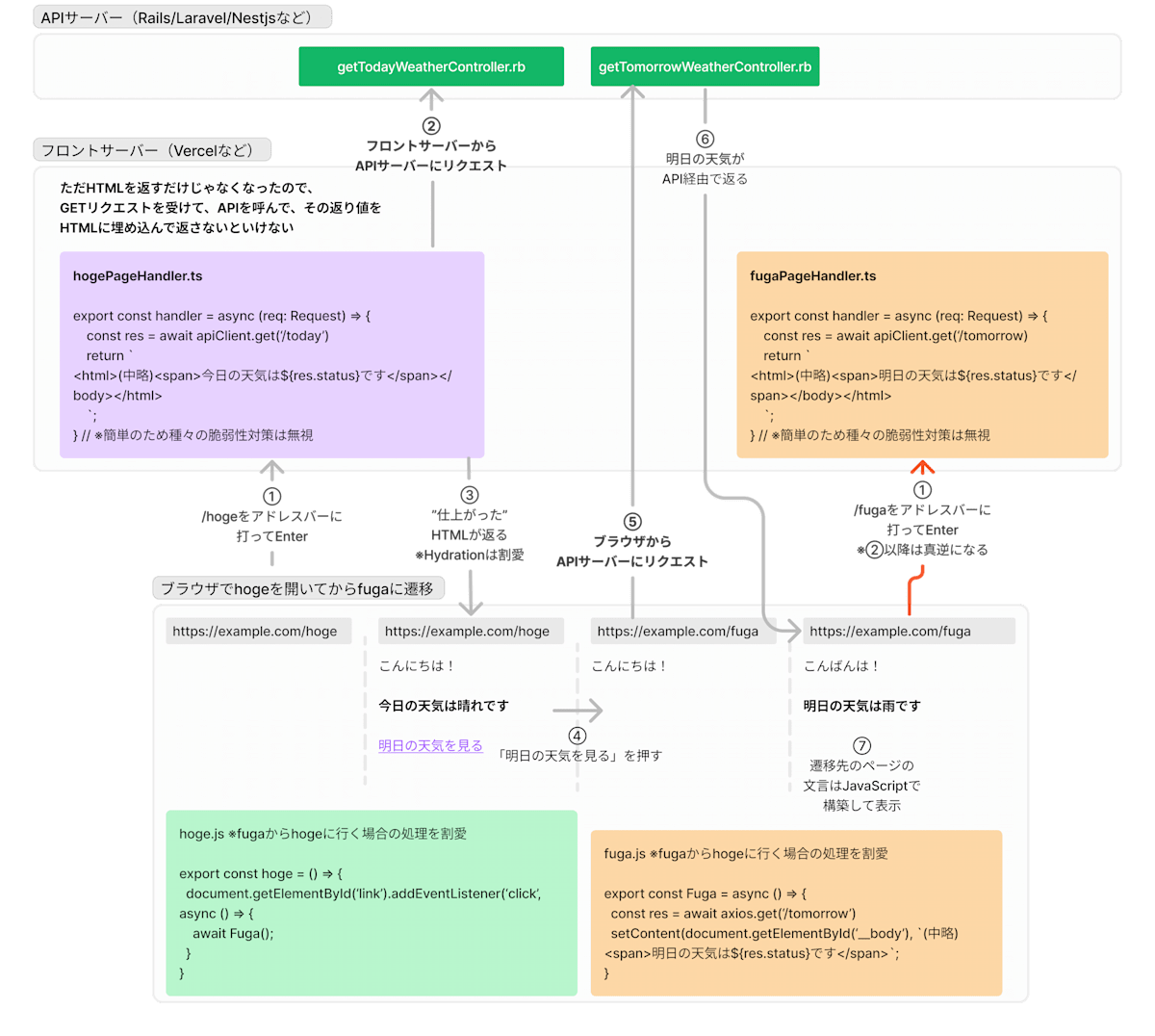
ページAからBに行っても、BからAに行っても、遷移先のページでブラウザからデータフェッチを実行します。
これで要件自体は満たせるのですが、「サーバーとブラウザに全く同じ通信処理が分断する」という問題が起きます。
最初にアクセスしたときはフロントサーバーで動くが、ページ間遷移のときはSPAっぽくしたいのでブラウザ上からフェッチするしHTMLの組み換えもするということになるので、よくよく図を見ていただければと思いますが、同じような処理がどっちにも分散しちゃっています。
Next.jsを使わないという前提で考えると、このときサーバーはNode.js(Express)とかで立ち上げていて、ExpressのControllerからバックエンドのAPIをaxiosとかで叩いて、結果返ってきたJSONをHTML内に適宜埋め込んで、Returnする必要があります。これは完全にLaravelとかRailsと同じです。
問題はフロントエンドで、フロントエンドでページ遷移をユーザーが行ったとき、フロントエンドでもバックエンドのControllerで実行しているのと同じAPIを叩かないといけません。それに、HTML構造もそのまま同じものを書き写さないといけません。
必然的に二重管理になってしまいますね。デザイン変更の依頼とかを受けるたびに、サーバー側のリポジトリのControllerから返すHTMLと、フロント側のページ遷移時にデータをフェッチして埋め込むHTMLそれぞれ対応しないといけません。別にできなくはないと思うのですが、ひたすら面倒ですね。
あまりにもつらすぎるので、この時代の開発者たちは悲痛な叫びを上げます。
「初回レンダリング時はSSR、ページ遷移時はClient Routingしたいんだけど、通信処理とHTML組み立て処理は1つのコードでまかないたい〜!!」
余談:SSRとクライアントルーティングの併用の何が辛いのか
一応前節では「SSRとページ遷移時でそれぞれ通信処理とHTML組み立て処理を書くのは面倒すぎる」という書き方で済ませたのですが、個人的にもっと辛い理由があります。
それは、「やりたい目的と、実装しなければいけない内容が乖離していること」です。要件定義としては「ページを移動したい」なのですが、実装内容が「API叩いて〜〜HTML組みたてて〜〜」というふうにややこしくなっているのが辛いところです。せめて、「ページ遷移する」という関数があって、そこに遷移したいページパスを渡したら適切なAPIを叩いてHTMLを作ってくれたらいいのですが・・・
仮歴史その3)Next.js襲来
このIssueをそもそも解いているのがNext.jsです、というふうに捉えてほしいのがこの勉強会の骨子です。
Next.js(だけじゃなくてNuxt.jsとかも一緒です)が提唱したことは、「肝心なところをフレームワークが巻き取れば、フロントエンドとサーバーサイドで二重で書いていた部分を共通実装にできるよ!」ということです。
先程の図の中から、サーバーサイドの実装とフロントエンドの実装を抜粋しました。


初回ロード時のSSRも、ページ遷移時のrouter.push時も、抽象化したら「データフェッチ」と「HTMLの組み立て」に大別できることが言えると思います(くどいですが、実際もっとやることあるけど超割愛してます)。
ということは「データフェッチ」と「HTMLの組み立て」だけを開発者に実装してもらって、それらのコードがサーバーサイドで呼ばれたときとフロントエンドで呼ばれたときの必要な処理の差はフレームワークが巻き取ればよいのではないでしょうか?
<それぞれの特徴>
- サーバーサイドで呼ばれたとき:HTML全体を返さないといけない
- フロントエンドで呼ばれたとき:生成するHTMLは更新分だけでいいが、History APIを用いたURLの書き換えと、遷移後のページに必要なJavaScriptを
<head>に加えて追加で読み込ませるなども必要
さて、勘の鋭い方はお気づきかと思いますが、「データフェッチ」と「HTMLの組み立て」は、まさにNext.jsのPages Routerにおいて、/pages/hoge/index.tsxに定義する内容と合致するのです。
export const getServerSideProps = () => {...}
export default function Page(props: InferGetServerSidePropsType<typeof getServerSideProps>) => {...}
たとえばNext.jsが/hogeへのリクエストを「フロントエンドサーバー」で受け取ってからpages/hoge/index.tsxを呼び出すまでにどんな処理があるかはブラックボックスですが、ここまで読み進めた方であれば以下のような処理をNext.jsが実行してそうだなと推論できるのではないでしょうか。
export const index = async (req: Request) => {
const path = req.path // "/hoge"みたいな文字列が入る
const targetModule = await import(`pages${path}/index.tsx`) // 実際はビルド時にRouter相当のファイルを静的生成していると思うけどこういう感じで対応するindex.tsxを引っ張ってくるイメージ
const gSSP = targetModule.getServerSideProps
const Component = targetModule // default Exportなので
const SharedLayout = getSharedLayoutComponent() // _app.tsxといった共通部分のコードを引っ張ってくるはず
return renderReactDOM(SharedLayout, Component(await gSSP({req}))); // イメージです。要は共通レイアウトにページComponentにgSSP()を実行した結果を渡して、最後Renderした文字列をHTTP Responseにして返しているイメージ
}
くどいですが実際にNext.jsがやっている処理はもっと複雑だし、今書いていても_app.tsxなどの共通化をどうやっているのか?とか、react-domにRenderさせた結果をHTTP Responseに包み込む処理ってどうやっているんだろとか疑問が無限に湧き出てくるし、最近だとhonoとかは軽量なFWでJSX対応しているから今度コード読んでみようかな〜とか思うのですが、ここでは「pages/hoge/index.tsxに決められたExportルールに沿ってファイルを置いておくことで、Next.jsが実行してくれている」ということに気がつけばOKです。
次に、router.pushのときに何が起きているのかも考えてみましょう(今更ですが、<Link />のときもほとんど同じと思ってよいです。また、prefetchの挙動については一旦考慮外にします)。
router.pushって遷移先のパスを受け取るので、サーバーサイドと同様、対応するPage Componentのパスを特定できるし、そこに含まれるgetServerSidePropsやDefault Exportされているコンポーネントを知ることができるはずです。
ここで解答をお伝えしてしまうと、router.pushによる遷移時には以下のようなGETリクエストが飛んでいます。
GET https://example.com/_next/data/G-F0jfVmIi21uKja6yfdb/articles/XXXXYYYYZZZZ.json?articleId=XXXXYYYYZZZZ
これは、あるページから/articles/{articleId}というページに、articleId=XXXXYYYYZZZZとしてrouter.pushで遷移するときのリクエストです。
ここまで本記事を読んでいる方はほぼ全員、Pages RouterのNext.jsアプリケーションが目の前にあることかと思いますので、どこかからどこかへページ遷移してみて、DevToolsのNetworkタブでXHRに絞って飛んでいるGETリクエストを見てみてください。https://example.com/_next/dataから始まるリクエストがあるはずです。
実際のアプリケーションを見てみよう
業務で開発しているアプリケーションはいつApp Routerに移行するかわからないし、CDNでキャッシュ等も進めているので、以下の個人開発サービスを例にして説明します。
自分リリースノートを公開できるサービスです。プロトタイプなので誰も投稿できません。2021年以来開発してないので今後も多分改善する気がないです(誰か誘ってください(?))。また、2021年の開発物なので絶対にPages Routerですが、当時の世相的にもISRでビルドしている説が濃厚なので、厳密にSSRの動きを見たい方は本節のやり方をお手元のアプリケーションで真似してください。
さて、Networkタブを開いたままトップページを開いてみると、以下のように表示されるはずです。
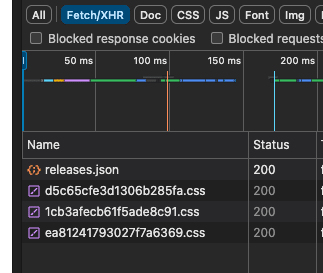
prefetchが動いているっぽいので実行タイミングが速いですが、このreleases.jsonはリリースノート一覧画面(https://my-release-notes.meijin.dev/releases )のgetServerSidePropsを実行して結果を返しています。
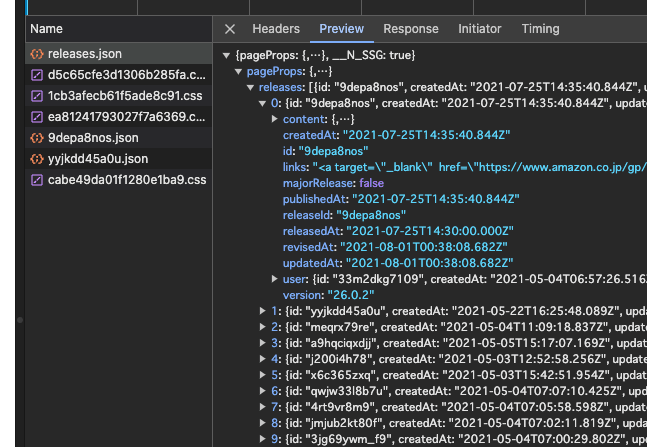
以上の動きから、getServerSideProps関数は必ずしもページリロード時だけではなく、他ページから遷移する際(prefetchによって前もって実行されることもありますが)に、/_next/data/...経由で呼び出されることもあるということがわかります。
Next.jsの通信の動きを図解してみる
以上の話から、あくまで通信パターンに特化して図解してみました。相変わらず細かい内部挙動には踏み込まずに概念だけ書いてます。
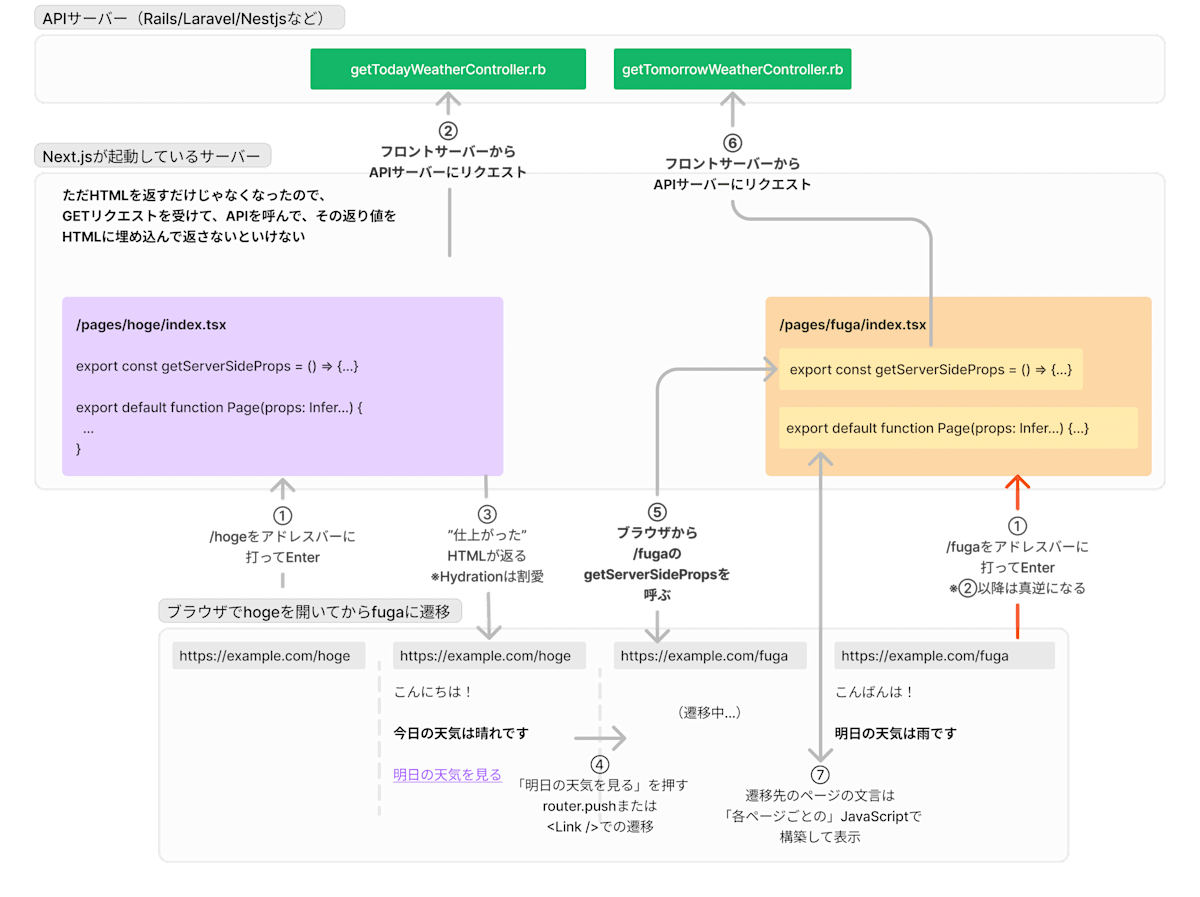
図を読み解く際のポイントは以下のとおりです。
- "原始的SSR"の時代と違って、ソースコードは単一のファイルに定義するだけでよくなっている
- その代わり、データ取得関数
getServerSidePropsもexportする必要がある。exportされたデータ取得関数は/_next/data/XXX...というパスを通して単体で呼び出すことができる - ⑤と⑦を見ていただくとわかるが、
router.pushによるページ遷移時には、getServerSidePropsを通して得たデータを、ページごとにビルドしたJavaScriptファイルで構築したページに表示している
特に3つ目の挙動については、DevToolsのNetworkタブで、XHRとJavaScriptのダウンロードを見てみると実感できるはずです。prefetchしている場合は遷移前のページを開いた時点でダウンロードが始まりますが、遅くともLinkのクリック時にはXHRによるデータフェッチと、遷移先ページに対応するJavaScriptのダウンロードが始まっているはずです。
開発者は「ページ遷移したいな〜」と思ってLinkを置いたりrouter.pushするだけですが、Next.jsは想像以上に複雑なことをやってくれていると分かったと思います(複雑なことを簡単そうに見せるのがFWの仕事なので、素晴らしいと思います)。
【余談】prefetchについて
散々触れているprefetchというのは、LinkがViewport内に入ったときなどにあらかじめ遷移先に必要なリソースのダウンロードをしておくことで、遷移を爆速にする工夫です。
超余談ですが、Lighthouseスコアのチューニングをしていると、prefetchの影響で無駄にJSサイズが大きいと見なされたりするので、prefetchを意図的に一部OFFにするみたいな、(あまり良くないかもしれない)工夫をやったことがあります。昔聞いた話ですが dev.to はリンクのホバー時にprefetchするらしくて、そのやりかたは賢いな〜と思いますね。
まとめ
結局これを知って何が嬉しいの?
なんでこんな話をすることになったかというと、弊社ではNext.jsの前段にCloudFrontを置いていまして、ビヘイビアの設定を変えることでgetServerSideProps内で特定のHTTPヘッダーの値を取得しようとしたのですが、/hogeビヘイビアだけ設定したら、ページ遷移時にヘッダーの値が取得できなくて困惑→そうか、ページ遷移時は/_next/dataにリクエストが飛ぶんだった!となったので、社内向けに勉強会を開催した、といった流れでした。
CDN設定に限らず、アクセスログの解析をするときや、Lighthouseスコアの改善をするときなども、大前提こういった内部挙動を分かっておくほうが網羅的に選択肢が出せると思いますし、冒頭にも若干触れましたが、App Routerの何が凄いのか?とか、SWRって何で流行ったんだっけ?っていうのも、上記の話を理解していると、「getServerSidePropsでしかデータ取得しない」ことがデメリットになってきた&しかしメリットは享受したい、みたいな背景があるよね〜といったことがザックリ見えてくるので、技術トレンドを追うのも効率上がるんじゃないかなと思ってます。
この記事の活用の仕方
弊社では本記事のように、あえて詳細に触れずに通信パターンに特化して勉強会をすることで効果的な学習ができたと思います。
若干おこがましいことを書きますが、もしこの記事を読んでいる方が、ある企業のフロントエンドのジュニア〜ミドルレベルの方で、読んでなるほど!と思っていただいたのであれば、ぜひ所属企業のリードエンジニアの方に記事を見せて、同じように社内で勉強会を開催していただくのが良いかなと思います。
また、シニア以上の方には退屈な記事になったかと思いますが、もしこの説明が分かりやすそうだなと思って頂けましたら、同じ会社のジュニア〜ミドルの方に勉強会として展開するための資料としてご活用いただけますと幸いです。
私自身、改めてこうやって説明することで、自分の理解度が不足している箇所が見えてきて楽しかったです。他社の勉強会にお邪魔したり、自社と共同で勉強会することもあるので、一緒にNext.jsの仕組みを学ぼう!と思っていただいた方は XアカウントへのDM などにてお誘いいただければ喜んで加わります!

オンライン家庭教師マナリンクを運営するNoSchool社のテックブログです。 manalink.jp/ 実際に検証・開発した内容をベースに、ただのマニュアルや告知に留まらない具体的な知見を公開します! カジュアル面談はこちら! forms.gle/fGAk3vDqKv4Dg2MN7
Discussion
SSRとクライアントルーティングの通信パターンを「仮歴史」として丁寧に説明されている部分は、視覚的にも頭に残りやすくて素晴らしいと感じました。