Mastra Workflowでマルチエージェントの処理状況をストリーミングする実装例【Next.js】
Claude CodeやCodex等で日々開発者が実感しているように、多くのAIエージェントが複数のAgentが協調して動くMulti Agentアーキテクチャへ進化しています。
単一Agentでは限界だった複雑なタスクを、専門化されたAgentが連携することで解決する時代が来ています。
しかし、TypeScriptベースのAIエージェントフレームワークでは、Multi Agent実装のためのWorkflow機能は提供されているものの、
UXに直結するStreaming周りの実装ノウハウが公開されていないのが実情です。
本記事では、MastraのWorkflowを使ったMulti Agent実装において、各Agentの処理状況をリアルタイムにStreamingする方法を解説します。
公式ドキュメントでは対応できなかったAgent内部のTool呼び出しまで含めた、完全なStreaming実装を実現しました。
前提技術
- Next.js v14以降
- Mastra v0.20以降
- Workflow を利用
- Vercel AI SDK v5を利用
対象読者
以下のいずれかに該当する方におすすめです
- AIエージェントの開発をしている
- Multi AgentシステムでChatGPT並のUXを実現したい
- toCサービスなど、応答速度が重要なサービスにLLMを組み込んでいる
- ReadableStreamやWriteableStreamに苦手意識がある
背景:Multi Agent時代の到来
なぜ単一Agentでは限界なのか
2025年6月頃に、AIエージェントの処理途中および最終出力をStreaming配信、UIでリッチに表示する事例(以下、先行事例)を公開しました。
当該記事は単一Agentによる出力を画面上でStreamingしながら表示する事例でした。
特に弊社のようなtoCサービスにおいては、顧客の獲得及び離脱の責任をプロダクトそのものが有することから、AI AgentがStreamingによってリッチかつ高速な応答性を有することは必須です。
しかし先行事例は単一Agentを前提とするがゆえに、単一Agentが抱える構造的な課題を有しています。
- 複数のミッションを持たせると、Instructionが肥大化し、破綻する傾向にある
- 改修改善において、Instructionが単一であるがために、影響範囲が予測しづらい
多少の拡張であれば以下記事に公開したようにドメイン駆動設計の考え方を応用することで単一Agentであっても拡張性を持たせることが可能ですが、もともとのミッション自体が複数種類のJob実行を伴うようになっていくと、そもそも単一Agentであるがゆえの性能限界に直面します。
Multi Agentアーキテクチャへの進化
世間のフレームワークは複数Agentを比較的容易に実装できるような方向へ進んでいます。
TypeScriptベースでも、MastraやVoltAgentがMulti Agent対応を進めています:
- Mastra
- VoltAgent
平たく言えば、Workflowは複数Agentを連携させつつ、連携のロジックはハードコーディングによって担保する手法で、一方でAgent NetworkやSub Agentsは連携そのものも担当するAgentが存在する手法です。
Mastra Workflowを用いて制御を行うケースもMulti Agentと呼称していいか良く分かっていないのですが、本記事ではWorkflowによる実装でもMulti Agentと呼称する点ご了承ください。
しかし、Streaming実装のノウハウは不足
Workflow機能は提供されていても、複数のAgentが連携しながらリアルタイムに処理状況をStreamingする実装については、公式ドキュメントでも詳しく扱われていません。
特に、Agent内部でのTool呼び出しといった詳細な処理状況までStreamingするとなると、フレームワークの内部実装を理解し、独自の実装を加える必要があります。
本記事で得られること
- Mastra Workflowで
fullStreamを使った完全なStreaming実装 - Agent内部のTool呼び出しまでリアルタイムに表示する方法
- Route HandlerからフロントエンドまでのEnd-to-End実装例
- 公式ドキュメントに記載のない実装ノウハウ
なお、本記事ではWorkflowによる実装を解説します。Agent Networkや
Sub Agentsによる実装は別の機会に扱います。
動作例
では、実際にMastra WorkflowがStreamingしつつUIをリッチに表示している様子を示します。
※以下、動画を載せていますが大きいファイルのため表示されなかったらちょっと待ってください
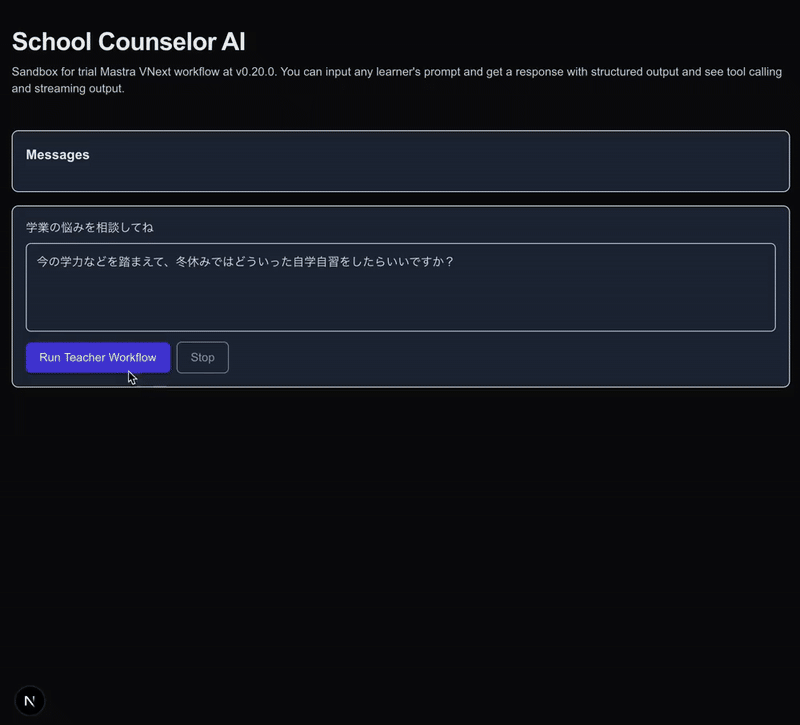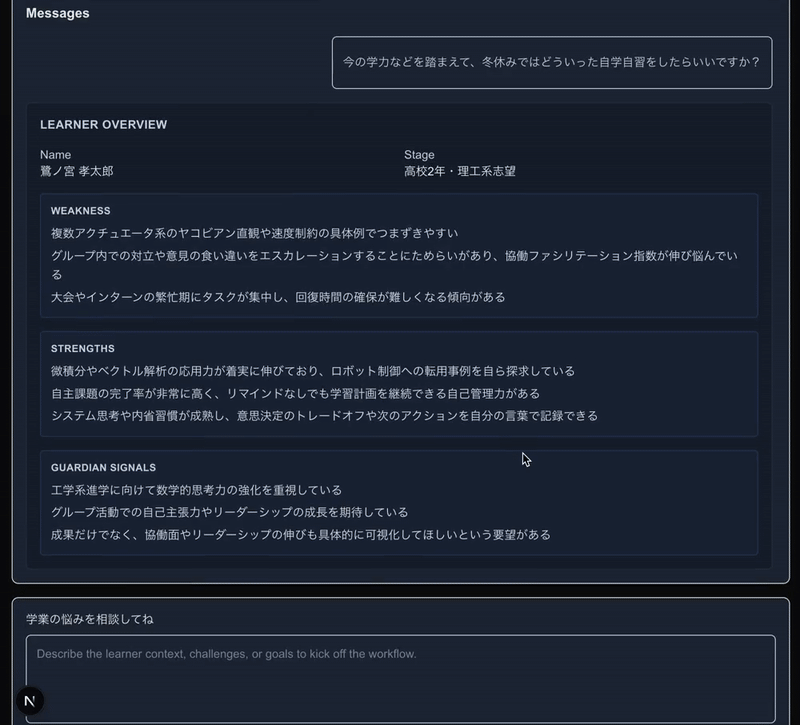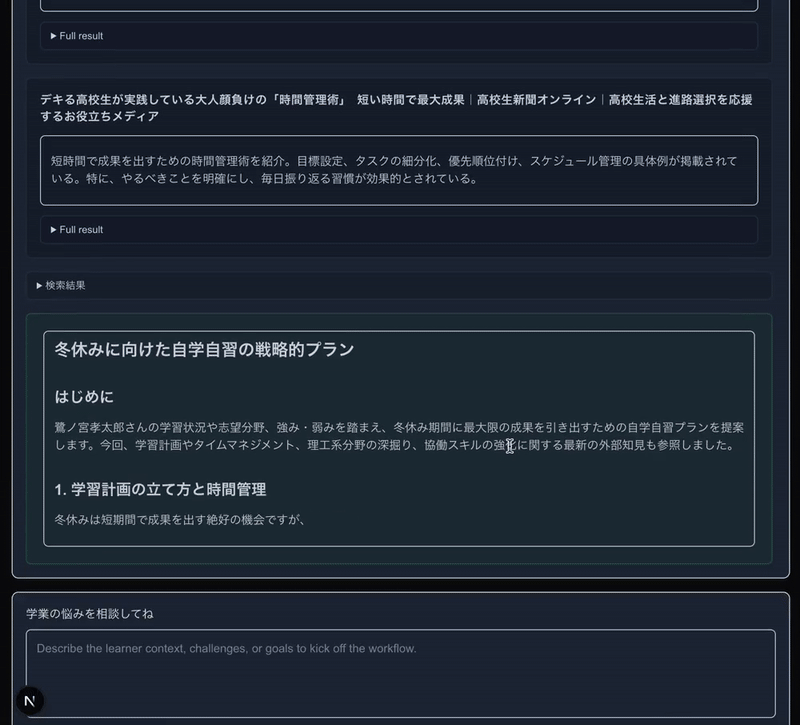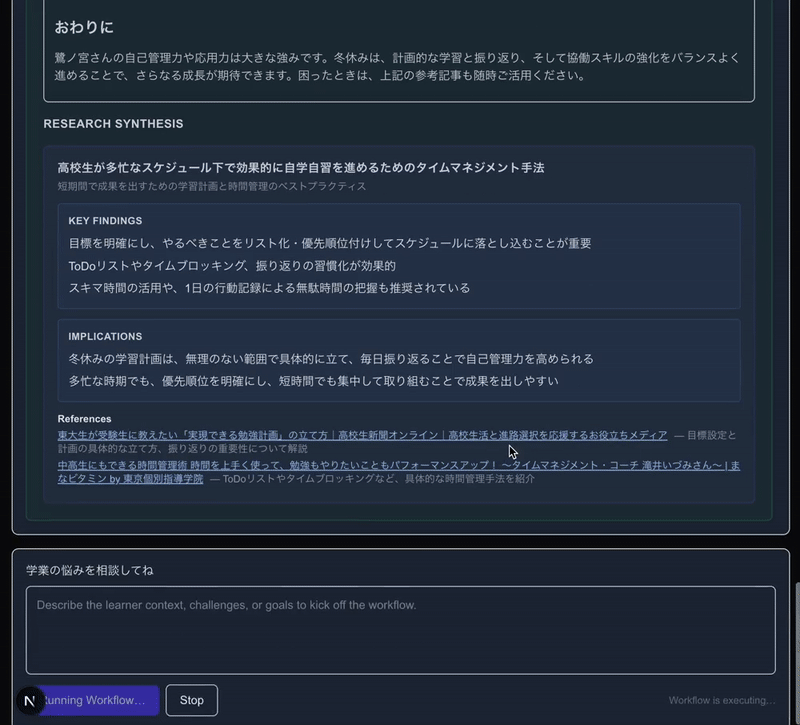
このサンプルは、とりあえず私がEdtechサービスの住人であることから、「スクールカウンセラーAgent」として作っています。大半のPromptなどをAI生成に頼っているので、肝心の挙動の精度は適当です。
注目すべきは、道中で呼び出されている、生徒さんの状況を把握して言語化するAgentと、Web検索するAgentと、最終的に出力するAgentがすべて進捗をStreaming UIでリッチに配信しつつ、さらにWeb検索Agentにおいては、道中のWeb検索Toolの呼び出し中、呼び出し完了までもがリアルタイムに監視できていることです。
(検索ツール呼び出しといった形で白枠で表示されている部分です)
これだけを見ると、先行事例で共有しているものと何ら変わらないように見えると思いますが、それが目的です。先行事例と変わらないStreaming表示でありながら、裏側はMulti Agentになっていることがポイントです。
実装解説
本記事のコードは以下のRepositoryに上げているので、コード見たほうが速い方はそっちを見ちゃってください。
Web検索もOpenAIのものを使っているので、OPENAI_API_KEYさえあれば動きます。
Workflowの実装
こちらがWorkflowの実装です。Workflowを知らない方向けに簡単に解説すると、実態としては大げさな仕組みではなくて、メソッドチェーンで処理の順番を規定できてある程度型安全にもできるよっていう仕組みで、その気になれば自前でハードコーディングしても大差ないものではあります(過渡期っぽさはある)。
export const counselorWorkflow = createWorkflow({
id: "counselor-workflow",
inputSchema: z.object({
message: z.string(),
}),
outputSchema: CounselorWorkflowResponseSchema,
})
.then(gatherLearnerUnderstandingStep)
.then(performDeepResearchStep)
.then(synthesizeAdvisorPlanStep)
.commit();
Stepの実装
各Stepの実装は以下の通り。要するにStep内でAgentを呼び出すことで、Workflow全体でMulti Agentなシステムを実現しています。
const gatherLearnerUnderstandingStep = createStep({
id: "gather-learner-understanding",
inputSchema: z.object({
message: z.string(),
}),
outputSchema: z.object({
inquiry: z.string(),
understanding: LearnerUnderstandingSchema,
}),
execute: async ({ inputData, mastra }) => {
const agent = mastra.getAgent("userUnderstandingAgent");
const stream = await agent.stream(
[
{
role: "user",
content: `Summarize the learner based on available tools. Parent or advisor inquiry: "${inputData.message}"`,
},
],
{ output: LearnerUnderstandingSchema },
);
// 中略
return {
inquiry: inputData.message,
understanding,
};
},
});
WorkflowにおけるStreamingの課題
実はMastraの公式ドキュメントにも、Workflow Streamingの解説ページはあります。
少なくとも執筆時点では、
このページの要点は以下のとおりです。
- Workflow.Run.stream()関数で、Streamingができるよ
- 各Stepの引数にあるwriterというオブジェクトを通して、各Step内で起きていることをStreamにPipeすることができるよ
- 実際どのようにストリーミングするかをきめ細かく制御できるよ
つまるところ、低レベルAPIを公開しているので、細かいStreamingの内容の制御が可能です、と言っているのであって、前節で示したような具体的なUIまで見据えたStreamingについては明言されていないのが実情です。
実際、本ドキュメントのとおりに実装すると、
【Workflow→Stepから呼び出しているAgentの出力はStreamingできる】
のですが、
【Workflow→Step→Agentから呼び出しているToolの入出力はStreamingできない】
のです。
つまり、処理時間の長いAgentが含まれている場合はそのAgentが道中でどのようにツールを呼んでいるかが不可視になり、ユーザー体験を劣化させます。
たとえばWeb検索エージェントはDeep Researchのように深くサーチする挙動が求められることも多く、そのためAgent全体の処理時間は長いがツール呼び出しは多く行われていることがありえます。そのとき、Agentの最終出力までユーザーが待たされるのと、道中で検索クエリ等が表示されるのでは、UXが段違いです。
本記事ではここから、Workflow内部のAgentが呼び出すToolに至るまでをUI上に反映させるStreamingの実装例を解説していきます。
fullStreamの利用
公式ドキュメントではStreaming実現法としてtextStream.pipeToという関数が紹介されています。
import { createStep } from "@mastra/core/workflows";
import { z } from "zod";
export const testStep = createStep({
// ...
execute: async ({ inputData, mastra, writer }) => {
const { city } = inputData;
const testAgent = mastra?.getAgent("testAgent");
const stream = await testAgent?.stream(`What is the weather in ${city}$?`);
await stream!.textStream.pipeTo(writer!);
return {
value: await stream!.text,
};
},
});
これはWeb標準の関数であり、MastraがWorkflowの出力であるWriteableStreamをStepのExecute関数に渡すため、Agentの出力をパイプすることが可能です。
しかしtextStreamはAgentの最終出力をプレーンテキストでStreamingする機能のみを提供するため、Toolの呼び出しには対応できません。
そこでMastraの実装を調査したところ、fullStreamという、より包括的な機能を持つAPIが存在することが判明しました。
正確には、textStreamはfullStreamから特定のChunkTypeのみをフィルタリングした結果をpipeToで提供している実装です。
したがって、textStreamをfullStreamに置き換えることで、最終出力だけでなく処理途中のツール呼び出しまで含めてStreamingの対象とすることができます。
await stream.fullStream.pipeTo(writer);
ただし、この変更には対処すべき課題が2つ存在します。次節以降でこれらの課題と解消方法について解説していきます。
多様なChunkTypeへの対応を自前で実装する
fullStreamを使用する際の課題は、そのメリットの裏返しとして存在します。すなわち、Agent処理中のあらゆるイベントがStreamingされるため、適切なフィルタリングを行わなければフロントエンドが大量の表示で溢れてしまいます。
これらのイベントの型定義は、以下のファイルに集約されています。
例えば、ツール呼び出しのための引数文字列の生成途中であっても、イベントとして配信される仕様となっています。
そこで本サンプルリポジトリでは、Chunkをフィルタリングし適切な形式に変換してフロントエンドへ返す処理を、Route Handlerに実装しました。
if (chunk.type === "workflow-step-output") {
const payloadOutput = chunk.payload.output as ChunkType;
const payload = chunk.payload;
const stepName: string =
typeof payload === "object" &&
payload !== null &&
"stepName" in payload &&
typeof payload.stepName === "string"
? payload.stepName
: typeof payload === "object" &&
payload !== null &&
"id" in payload &&
typeof payload.id === "string"
? payload.id
: "";
// ツール呼び出し。ここは実ツール名に依存するが、複数ツールの表示にフロントエンドが対応する必要があるときは
// ツール名を直接sendしてしまっても構わない(ツール名の型ガードを実装する形でもいいかもしれない)
if (
payloadOutput.type === "tool-call" &&
payloadOutput.payload.toolName?.includes("webSearch")
) {
send({
event: "tool-call",
text: JSON.stringify(payloadOutput.payload?.args),
toolName: "web-search",
processId: payloadOutput.payload.toolCallId,
});
} else if (
(payloadOutput.type === "tool-result" ||
payloadOutput.type === "tool-error") &&
payloadOutput.payload.toolName?.includes("webSearch")
) {
// ツール呼び出し終了のイベント送信
send({
event: "tool-call-finished",
text: JSON.stringify(payloadOutput.payload.args),
toolName: "web-search",
processId: payloadOutput.payload.toolCallId,
});
} else if (payloadOutput.type === "text-delta") {
// 1文字ずつのイベント送信。Stepの出力が送られる(厳密には、Agentの出力をPipetoしているので、Stepそのものの出力ではなく、Step内で呼び出しているAgentの出力であることに注意。そのためStep内で複数のAgentを呼び出しすべてをStreamingしたい場合は、RunIDの内部仕様次第ではあるがもうひと工夫必要になるはず。Agent名を何らかの方法でIdentifyに用いるなど)
send({
event: "workflow-step-output-chunk",
text: String(payloadOutput.payload.text) ?? "",
processId: String(chunk.payload.output.runId),
stepName,
});
} else {
// console.log("[WORKFLOW STREAM] NOT LISTED OUTPUT", payloadOutput);
}
執筆時点のMastraの仕様では、流れてくるStreamのChunkにおいて、"workflow-step-output"がchunk.typeになっているものが、Step内部でPipeしたStreamもマージされて流れてきています。
さらにその後、chunk.payload.output.typeを確認することで、どの種類のイベントかを特定できます。
これを理解していれば、後は実現したいUXに向けて自由に扱うことができます。本リポジトリでは、特定のツールの呼び出しのみを対象に、ツール呼び出し時とツール終了時にそれぞれStreamへ流すことで、フロントエンド側で呼び出しの開始と終了を検知できるようにし、適切なUIで表示できるようにしています。
preventClose: true
以下ドキュメントにある通り、pipeToメソッドのオプションで、ReadableStreamが閉じてもWriteableStreamを閉じないようにpreventCloseオプションをTrueにする必要があります。
ReadableStream: pipeTo() メソッド - Web API | MDN
await stream.fullStream.pipeTo(writer, {
preventClose: true,
preventAbort: true,
preventCancel: true,
});
これは重要なフラグで、仮に指定しなかった場合、複数のStepでそれぞれのAgentにPipetoした際、1つ目のAgentが実行終了した瞬間にWorkflow全体のWriteableStreamごとCloseしてしまいます。開発時は謎の挙動に困惑しましたが、MDNを確認することで解決しました。
残り2つのフラグも検証している範囲ではtrueにしておくほうが安定していましたが、falseでも問題ない可能性があります。
これらのオプションを適切に設定することで、ストリームの予期しない終了を防ぎ、安定したストリーミング処理を実現できます。
NDJSON
本リポジトリでは、Route Handlerからは1つのChunkをJSONとして、改行コードで区切られた状態でControllerへEnqueしています。このような改行コードで区切られた連続したJSONによるレスポンス形式をNDJSONと呼びます。
参考:NDJSON 101: HTTPエンドポイントでのストリーミング
const send = (event: StreamEvent) => {
controller.enqueue(encoder.encode(`${JSON.stringify(event)}\n`));
};
return new Response(stream, {
headers: {
"Content-Type": "application/x-ndjson; charset=utf-8",
"Cache-Control": "no-cache",
},
});
この形式を使用することで、フロントエンドはリアルタイムでデータを受け取り、処理することが可能になります。
フロントエンドでのStreamed Chunkのハンドリング
Route HandlerでReadableStreamに書き込むオブジェクトの型を定義し、それをExportしフロントエンドでも活用します。
export type StreamEvent =
| {
event: "workflow-step-output-chunk";
text: string;
stepName: string;
processId: string;
}
| {
event: "tool-call";
text: string;
processId: string;
toolName: "web-search";
}
| {
event: "tool-call-finished";
text: string;
processId: string;
toolName: "web-search";
}
| { event: "error"; message: string };
const parsed = JSON.parse(line) as StreamEvent;
switch (parsed.event) {
case "workflow-step-output-chunk":
if (parsed.text && parsed.processId) {
const newText = parsed.text;
const stepName = parsed.stepName;
// Try to parse partial JSON for real-time rendering
if (stepName && isValidWorkflowStepName(stepName)) {
textOutputEachTools[stepName] =
(textOutputEachTools[stepName] ?? "") + newText;
const parseResult = parsePartialJson(
textOutputEachTools[stepName] ?? "",
);
if (
parseResult.state === "successful-parse" ||
parseResult.state === "repaired-parse"
) {
const parsedValue = parseResult.value;
if (
typeof parsedValue === "object" &&
!Array.isArray(parsedValue) &&
parsedValue !== null
) {
addProcessOutput(
stepName,
parsed.processId,
parsedValue,
);
}
}
}
break;
case "tool-call":
if (parsed.text && parsed.processId) {
const parseResult = parsePartialJson(parsed.text);
if (
parseResult.state === "successful-parse" ||
parseResult.state === "repaired-parse"
) {
const parsedValue = parseResult.value;
if (
typeof parsedValue === "object" &&
!Array.isArray(parsedValue) &&
parsedValue !== null
) {
addProcessOutput(parsed.toolName, parsed.processId, {
...parsedValue,
isProcessing: true,
});
}
}
}
break;
// 終了イベントもキャッチすることでツール呼び出し中の状態管理を可能にする。IDを一致させて受け取ることでisProcessingフラグを正しく管理できる
case "tool-call-finished":
const parseResult = parsePartialJson(parsed.text);
if (
parseResult.state === "successful-parse" ||
parseResult.state === "repaired-parse"
) {
const parsedValue = parseResult.value;
if (
typeof parsedValue === "object" &&
!Array.isArray(parsedValue) &&
parsedValue !== null
) {
addProcessOutput(parsed.toolName, parsed.processId, {
...parsedValue,
isProcessing: false,
});
}
}
break;
default:
assertNever(parsed);
break;}
先行事例の開発時に得たノウハウを活かし、parsePartialJson関数を使ってNDJSONの各行の値をパースしてローカルステートへ格納しています。
※parsePartialJson関数について知りたい方は上記記事を読んでください
完璧な型安全性とは言えない部分もありますが、概ねRoute Handlerからフロントエンドのステートまでを型安全、かつランタイムでもある程度安全に扱えるようにしています(余裕があればZod Parseも入れると良いでしょう)。
本リポジトリでは、Chunkに含まれるIDを使ってフロントエンドで同じツールへのChunkをマージし、状態管理を可能にする実装を行っています。詳細は割愛しますので、より詳しく知りたい方はコードを参照してください。
実装手段まとめ
Mastraで直接的に対応していないStreaming実装を完成させるには、以下の実装を行う必要があります。
-
textStreamではなく、fullStreamを使用する - Stepの
writer引数で渡されるWriteableStreamへPipeする - 多様なChunkイベントの種類を把握し、要件を満たせる種別をどこかでフィルタリングし、整形する(本リポジトリではRoute Handler)
- フロントエンドで整形済みのChunkを最終的に画面表示するための粒度に再整形する(本リポジトリではTool CallとTool Finishを1つのカードの状態管理としてまとめる)
- Route Handlerでは
ReadableStreamをResponseに直接渡して返す低レベルAPIの実装を行う - フロントエンドでは
fetch関数とReadableStreamReader、TextDecoderを使ってRoute Handlerから返したNDJSONを扱う
これらの実装を一つずつ行うことで完遂できることがわかりました。
また、言い換えると、MastraのStreamingとVercel AI SDKは内部的に上記のような作業を行ったWrapperを提供してくれているといえます。
以下のようなコードを読むことで確認できます。
MastraはVercel AI SDK互換を謳っており、そのためのDocumentも公開しています。そのためMastraのAgentが吐き出す各種イベントを、最終的にVercel AI SDKがuseChat等を通してフロントエンドで扱うための変換層が必要となります。これらのコードを読むと、抽象的には本リポジトリで取り組んだことと近しい処理を行っていることがわかります。
本リポジトリの実装を通して、MastraなどのAIエージェントフレームワークがエージェントの内部挙動をStreamingするために独自形式を有していること、そしてVercel AI SDKといったフロントエンドツールチェインとの互換性担保のための変換層が必要であること、それらをブラックボックス化した変換関数などをフレームワークが実装していること、及びそれらが内部でどういった責務を果たしているかをより深く理解することができました。
Discussion