YouTube のチャンネルの更新通知を受け取って Lambda を実行する
YouTube のチャンネルの通知を受け取る方法として、 YouTube Data API のドキュメントでは Google PubSubHubbub Hub を使った方法が紹介されています。
Google PubSubHubbub Hub を利用するメリットは、 YouTube Data API を叩かないので Quota を消費しないことや、必要なときだけイベントが通知されること、などがあります。
今回は API Gateway を用いて Google PubSubHubbub Hub からの通知を受け取り、 Lambda を実行する仕組みを Serverless Framework を用いて構成しました。
完成したコードはこちら
この記事では YouTube のチャンネルの通知を受け取る方法として Google PubSubHubbub Hub を使った実装を解説しつつ、仕様書をもとに安全に利用するための注意点なども解説していきます。
背景
これまでの課題
YouTube のチャンネルの通知を受け取る方法として、YouTube Data API の Search: list から ChannelId にもとづく動画一覧を定期的に取得する方法を考えましたが、これは Quota を非常に消費するので現実的ではありませんでした。
別の方法として RSS から取得するやり方があります。
https://www.youtube.com/feeds/videos.xml?channel_id={channelId}
を定期的に取得することで、チャンネルの通知を受け取ることができます。
しかし、高頻度でリクエストを投げると 429 が返ってくるらしく、多くのチャンネルの通知を受け取るには限界があるようです(参考コメント)。
そして、紹介して頂いた方法が Google PubSubHubbub Hub を使って、 RSS の更新を Push 通知で受け取る方法です。
PubSubHubbub とは
PubSubHubbub は、現在 WebSub と呼ばれるプロトコルの名称です。
少しややこしいですが、この記事ではプロトコルのことを WebSub と呼び、 WebSub においてハブの役割を提供している Google PubSubHubbub Hub の事を PubSubHubbub と呼んでいます。
また、厳密に言うと、 Google PubSubHubbub Hub は Pubsubhubbub の仕様書である Pubsubhubbub 0.4 specification に準拠しているので、 WebSub の仕様書である WebSub W3C Recommendation に準拠していない場合があります。
基本的には違いはないのですが、違いがある箇所は一応細かい説明を書いています。
WebSub の簡単な説明
一般的な RSS の取得は PULL 型と呼ばれる方式で行っており、購読者(Subscribers)が出版者(Publishers)のコンテンツを定期的に取りに行きます。
それに対して PUSH 型は、出版者(Publishers)から購読者(Subscribers)へコンテンツを届ける方式です。
WebSub では、その PUSH 型の中間にハブ(Hubs)を挟むことで、出版者から購読者へコンテンツを届けることを可能にしています。

PUSH 型はコンテンツが更新された時、つまり、必要なときだけ情報が送信されます。しかし、これを実現するには出版者が全ての購読者を知っていて、全てに送信する必要があります。購読者が大勢いる場合は実現が困難になります。
対して WebSub では、中間にハブを挟むことにより、出版者はハブに送信するだけで大丈夫になっています。また、ハブから購読者に送信するので、出版者が購読者をそれぞれ知っている必要がなくなりました。
そんな WebSub を使っていきますが、今回はそれぞれ以下のような関係になっています。
- 出版者(Publisher) -> YouTube
- 購読者(Subscriber) -> このアプリケーション
- ハブ(Hub) -> Google PubSubHubbub Hub
なお、 WebSub の仕組みに関しては、気象庁防災情報の取得についてわかりやすい図で紹介されているこちらの記事が参考になります。
構成
今回はこのような構成で実装していきます。
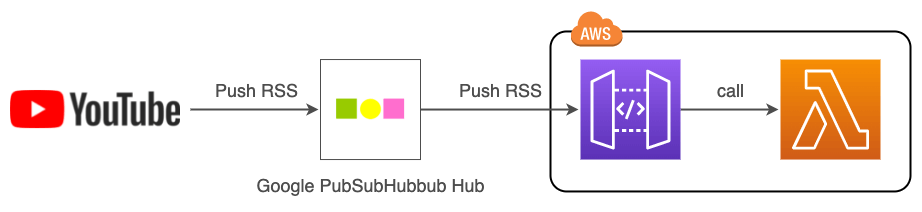
YouTube からの RSS の配信を Google Pubsubhubbub Hub が受け取り、更にそれを API Gateway に送るようにします
API Gateway へ来た POST リクエストをトリガーに Lambda を実行します。
AWS 側はシンプルな API Gateway + Lambda の構成なので、 Serverless Framework を使って構築します。
実装の概要
WebSub では Hub から Subscriber へ購読確認を行い、確認できた後に Publisher が配信したコンテンツを POST されるようになります。
購読確認では Hub が Subscriber の Callback URL に対して、 GET リクエストを送信します
クエリパラメータで hub.challenge が送信され、その値をそのまま返却します(参考)。
Hub から Subscriber へ POST される時は、共通の鍵( hub.secret )で HMAC を用いて、中身が改竄されていないことを確認します。
問題がなければ body を読み込み、 XML をパースし、必要な情報を取り出します。
取り出した情報を使うことで YouTube のチャンネルの更新通知をトリガーにした様々な処理を実行することが出来ますが、今回はその基盤部分の作りの解説のため、ログに出力するだけとなっております。
GET リクエスト(購読確認)
購読確認用の GET API を作成します。
serverless.yml に GET の HTTP API を作成します。
パスは Callback URL として推測困難なものにしたいので、callback-[32bytesのランダムな文字列]となっています(後述)。
functions:
challenge:
handler: handler.get_handler
events:
- httpApi:
# /callback-[a random URL-safe text string(32bytes)]
path: /callback-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
method: get
handler.get_handler はテスタブルにするために実態を challenge 関数に分けています。
@dataclass(frozen=True)
class RequestChalenge:
challenge: str
@dataclass(frozen=True)
class Response:
statusCode: int
body: str
def challenge(req: RequestChalenge) -> Response:
"""
challengeのロジック部分
"""
return Response(statusCode=200, body=req.challenge)
def get_handler(event, context):
params: dict = event.get("queryStringParameters", {})
req = RequestChalenge(challenge=params.get("hub.challenge", ""))
res = challenge(req)
return asdict(res)
リクエストで送られてきた hub.challenge をそのまま返します。
購読確認はこれだけで完了です。
POST リクエスト(更新情報の通知)
購読確認が完了したら、そのエンドポイントへ POST リクエストが送られてくるようになります。
GET API と同様に serverless.yml に POST の HTTP API を作成します。
functions:
...
notify:
handler: handler.post_handler
events:
- httpApi:
# /callback-[a random URL-safe text string(32bytes)]
path: /callback-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
method: post
# YouTube から送られてくる HMAC の16進数の signatures を取り出すための正規表現
X_HUB_SIGNATURE = re.compile(r"sha1=([0-9a-f]{40})")
@dataclass(frozen=True)
class RequestNotify:
x_hub_signature: str
body: str
@dataclass(frozen=True)
class Response:
statusCode: int
body: str
def notify(req: RequestNotify) -> Response:
"""
notifyのロジック部分
"""
if not (m := X_HUB_SIGNATURE.match(req.x_hub_signature)):
logger.info('verification failed: X_HUB_SIGNATURE is not match.')
logger.info(req)
return Response(200, "success") # チャレンジに失敗しても 2xx success response を返す
if not validate_hmac(m.groups()[0], req.body, HMAC_SECRET):
logger.info('verification failed: hmac is not match.')
logger.info(req)
return Response(200, "success") # チャレンジに失敗しても 2xx success response を返す
entry = parse(req.body)
try:
action(entry)
except Exception as e:
logger.error(e)
# 2xx success 以外で返すと配信が止まるという説もあるので、あえて 2xx success で返しても良さそう
return Response(500, "internal server error")
return Response(200, "success")
def action(entry: Entry):
"""
動画の通知が来たときに行う処理
"""
logger.info(entry)
def validate_hmac(hub_signature: str, msg: str, key: str) -> bool:
digits = hmac.new(key.encode(), msg.encode(), hashlib.sha1).hexdigest()
return hmac.compare_digest(hub_signature, digits)
def post_handler(event, context):
headers: dict = event.get("headers", {})
req = RequestNotify(x_hub_signature=headers.get("x-hub-signature", ""),
body=event.get("body", ""))
res = notify(req)
return asdict(res)
signatures の取得
まず、リクエストで送られてきたx-hub-signatureヘッダーがsha1=[0-9a-f]{40}であることを確認します。
WebSub W3C Recommendation では SHA-1 は危険だから使うなと書いてありますが、 Google Pubsubhubbub Hub では Pubsubhubbub 0.4 specification に準拠しているため SHA-1 が使われています。
As SHA-1 has been demonstrated to be compromised as of the date of this publication, a minimum of SHA-256 should be used.
https://www.w3.org/TR/websub/#distribution
The X-Hub-Signature header's value MUST be in the form sha1=signature where signature is a 40-byte, hexadecimal representation of a SHA1 signature [RFC3174].
https://pubsubhubbub.github.io/PubSubHubbub/pubsubhubbub-core-0.4.html#authednotify
実装上の正規表現ではsha1=([0-9a-f]{40})となっており、m.groups()[0]で signatures だけを取り出すようになっています。
signatures の検証
取り出した signatures は、リクエスト Body と共通の鍵( hub.secret )、 SHA-1 ハッシュアルゴリズムによって得られた signatures と比較します。
signatures の比較は、==ではなくタイミング分析を防ぐよう設計された関数を用います。
ここでは HMAC のことについて実装しているので、 hmac モジュールの hmac.compare_digest を使いました。
そして、これらの署名の確認に失敗した場合は 2xx success を返します。
# チャレンジに失敗しても 2xx success というコメントに驚くかもしれないですが、これは Pubsubhubbub 0.4 specification に準拠した実装です。
If the signature does not match, subscribers MUST still return a 2xx success response to acknowledge receipt, but locally ignore the message as invalid.
https://pubsubhubbub.github.io/PubSubHubbub/pubsubhubbub-core-0.4.html#authednotify
そもそも WebSub の仕組み的に POST リクエストのレスポンスは殆ど意味が無いです。
そして、 Subscriber は Hub だけから情報が送られてくる事を想定しているので、想定外のリクエストに対してわざわ「 signatures が間違っています」と教える必要はない(むしろそれはブルートフォース攻撃のヒントとなりうる)ために、このような仕様になっているのかと思われます。
ちなみに Pubsubhubbub 0.4 specification では MUST ですが、 WebSub W3C Recommendation では MAY となっています。
Subscribers MAY still acknowledge this request with a 2xx response code in order to be able to process the message asynchronously and/or prevent brute-force attempts of the signature.
https://www.w3.org/TR/websub/#signature-validation
実際、このテクニックを使ったところでブルートフォース攻撃を防げるものではないので、 WebSub W3C Recommendation では Callback URLs を推測困難なものにすることが推奨されています。
Second, subscribers SHOULD use unique unguessable capability URLs for the callbacks, as well as make them available via HTTPS.
https://www.w3.org/TR/websub/#x8-3-distribution
正常なデータが届いた時の処理
検証が完了したら entry = parse(req.body) で Body をパースし、データを取り出します(パースは次項で解説します)。
取り出したデータをメインの処理 action(entry) を実行します。
action 関数はログを出力しているだけなので、もしこのコードを使って開発をしたい場合は、 action 関数を書き換える必要があります。
def action(entry: Entry):
"""
動画の通知が来たときに行う処理
"""
logger.info(entry) # 今はログを出力しているだけ
XML パース
YouTube からは Atom feed (+ YouTube XML Schemas)の通知が送られて来ます。
実際に送られてくる XML はこちらです。
<?xml version='1.0' encoding='UTF-8'?>
<feed xmlns:yt="http://www.youtube.com/xml/schemas/2015"
xmlns="http://www.w3.org/2005/Atom">
<link rel="hub" href="https://pubsubhubbub.appspot.com"/>
<link rel="self" href="https://www.youtube.com/xml/feeds/videos.xml?channel_id=CHANNEL_ID"/>
<title>YouTube video feed</title>
<updated>2015-04-01T19:05:24.552394234+00:00</updated>
<entry>
<id>yt:video:VIDEO_ID</id>
<yt:videoId>VIDEO_ID</yt:videoId>
<yt:channelId>CHANNEL_ID</yt:channelId>
<title>Video title</title>
<link rel="alternate" href="http://www.youtube.com/watch?v=VIDEO_ID"/>
<author>
<name>Channel title</name>
<uri>http://www.youtube.com/channel/CHANNEL_ID</uri>
</author>
<published>2015-03-06T21:40:57+00:00</published>
<updated>2015-03-09T19:05:24.552394234+00:00</updated>
</entry>
</feed>
この XML は2つの名前空間を使っており、 Atom をデフォルトの名前空間として、ytという YouTube 独自の名前空間を使っていることに注意します。
パースするコードは以下の通り。
from dateutil.parser import parse as dateutil_parse
from dateutil.tz import gettz as dateutil_gettz
import defusedxml.ElementTree as ET
# YouTubeから送られてくるXMLデータの名前空間情報
XML_NAMESPACE = {
'atom': 'http://www.w3.org/2005/Atom',
'yt': 'http://www.youtube.com/xml/schemas/2015',
}
@dataclass(frozen=True)
class Entry:
videoId: str
channelId: str
title: str
link: str
authorName: str
authorUri: str
published: datetime
updated: datetime
def parse(text: str) -> Entry:
root = ET.fromstring(text)
entry = root.find("atom:entry", XML_NAMESPACE)
author = entry.find("atom:author", XML_NAMESPACE)
return Entry(videoId=entry.find("yt:videoId", XML_NAMESPACE).text,
channelId=entry.find("yt:channelId", XML_NAMESPACE).text,
title=entry.find("atom:title", XML_NAMESPACE).text,
link=entry.find("atom:link", XML_NAMESPACE).get("href"),
authorName=author.find("atom:name", XML_NAMESPACE).text,
authorUri=author.find("atom:uri", XML_NAMESPACE).text,
published=dateutil_parse(entry.find("atom:published", XML_NAMESPACE).text).astimezone(dateutil_gettz('Asia/Tokyo')),
updated=dateutil_parse(entry.find("atom:updated", XML_NAMESPACE).text).astimezone(dateutil_gettz('Asia/Tokyo')))
XML パーサーモジュール
まず、 XML のパースに defusedxml というパッケージを使います。
Python では XML を扱うモジュールは多々ありますが、 xml パッケージにまとめられている XML モジュール群は、不正なデータや悪意を持って作成されたデータに対して安全ではないことが警告されています。
信頼出来ない XML をパースする場合は、 defusedxml の使用が推奨されています。
というか、 defusedxml を使うべきではない理由がなければ、 defusedxml を使うべきだと思います。
また、 Flatt Security 社のブログで AWS Lambda における脆弱性の XML External Entity (XXE) について を解説されており、一読されることをオススメします。
XML 名前空間
更新された情報は<entry>に詰まっています。ここからデータを取り出すには XML 名前空間に注意する必要があります。
XML 名前空間については
<feed xmlns:yt="http://www.youtube.com/xml/schemas/2015" xmlns="http://www.w3.org/2005/Atom">
のところで定義しており、これはデフォルトの名前空間としてhttp://www.w3.org/2005/Atomという URI を使って、ytという名前空間としてhttp://www.youtube.com/xml/schemas/2015という URI を使っています。
これをプログラムに落とし込むと
XML_NAMESPACE = {
'atom': 'http://www.w3.org/2005/Atom',
'yt': 'http://www.youtube.com/xml/schemas/2015',
}
root = ET.fromstring(text)
entry = root.find("atom:entry", XML_NAMESPACE)
となります。
まずroot = ET.fromstring(text)で XML をパースしますが、この時entryというタグは省略されたデフォルトの名前空間が展開されて、{http://www.w3.org/2005/Atom}entryとなっています。
いちいち URI を指定するのは面倒なので、http://www.w3.org/2005/Atomに対してatomという名前で扱うようにXML_NAMESPACEという名前空間の定義をして、find関数の第2引数に指定します。
# もし、名前空間を引数に指定しないならば
entry = root.find("{http://www.w3.org/2005/Atom}entry")
# 第2引数に名前空間を指定する
entry = root.find("atom:entry", XML_NAMESPACE)
同様に yt の名前空間も定義しており、entry.find("yt:videoId", XML_NAMESPACE)で<yt:videoId>の値を取得することが出来ます。
時刻データの整形
XML のパースでデータを取り出せるようになりましたが、時刻データが String 型なので Datetime 型に変換したいです。
updatedの文字列は、一見すると ISO 8601 形式ですが、標準ライブラリの datetime モジュールのfromisoformatでは変換することが出来ません。
>>> datetime.datetime.fromisoformat('2022-01-28T12:40:58.132027669+00:00')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: Invalid isoformat string: '2022-01-28T12:40:58.132027669+00:00'
どうやら小数点以下の桁数が多いことが問題のようです。
様々な解決方法はあると思いますが、 dateutil モジュールのparse関数を用いると、特殊な前処理を実装せずに String 型から Datetime 型に変換可能です。
とはいえ、parseという名前は XML をパースする自作の関数名とバッティングするので、今回はdateutil_parseという名前をつけて使っています。
これで、ようやくプログラムの実装は完了です。
デプロイ
README.md に書いている通りですが、まずは.emv.exampleをコピーした.envファイルを作成し、 hub.secret を書き込みます。
PuSH_hmac_secret=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
そして、デプロイコマンドを実行すると、自動的に API Gateway と Lambda が作られます。
sls deploy
Google PubSubHubbub Hub の準備
実装が完了しデプロイしたら、 Google PubSubHubbub Hub に Subscriber として API を登録します。

セットする値はそれぞれ以下の通り。
- Callback URL
- 先程作った API のエンドポイント
- Topic URL
-
https://www.youtube.com/xml/feeds/videos.xml?channel_id={channelId}となる YouTube の URL 。{channelId}は YouTube channel ID であり、通知したいチャンネルの ID です。
-
- Verify type
-
asynchronousを選択 (Pubsubhubbub 0.4 specification では廃止されたものらしく、どちらを選んでも違いがないようです(参考))
-
- Mode
-
subscribeを選択
-
- Verify token
- 購読確認時に使う認証トークンですが、特に指定する必要はないです。
もともとは Pubsubhubbub 0.3 specification に OPTIONAL なパラメータとして用意されていましたが、 Pubsubhubbub 0.4 specification で廃止されました。
認証トークンという名前は、セキュリティ上で必要そうな感じが出ていますが、実際に hub.verify_token を用いることで防ぐことの出来るシナリオは、 hub.secret と signatures で検証することでも防ぐことが出来ます(参考)
- 購読確認時に使う認証トークンですが、特に指定する必要はないです。
- HMAC secret
- signatures を求めるために使う共通の鍵。最長 200 bytes 。(リクエストでは
hub.secretで送られる)
- signatures を求めるために使う共通の鍵。最長 200 bytes 。(リクエストでは
- Lease seconds
-
828000にしています。Hubs SHOULD enforce short lived hub.lease_seconds (10 days is a good default).
と WebSub W3C Recommendation では書かれているので、
864000(=10days)にしたかったのですが、どうやら最大値が828000らしいのでこの値にしています(参考)
-
Do It!のボタンを押すと、真っ白な画面になりますが、このリクエストには 204 を返すようなので問題ないです。
また、ここでは購読確認の成否に関わらず 204 が返ってくるので、 Subscriber Diagnostics から購読確認が成功しているか確認する必要があります。

先程登録したものと同じ Callback URL, Topic URL, HMAC secret の値をセットし、Do It!のボタンを押します。
すると、 Subscription Details というページに遷移し、購読確認が成否を確認できます。
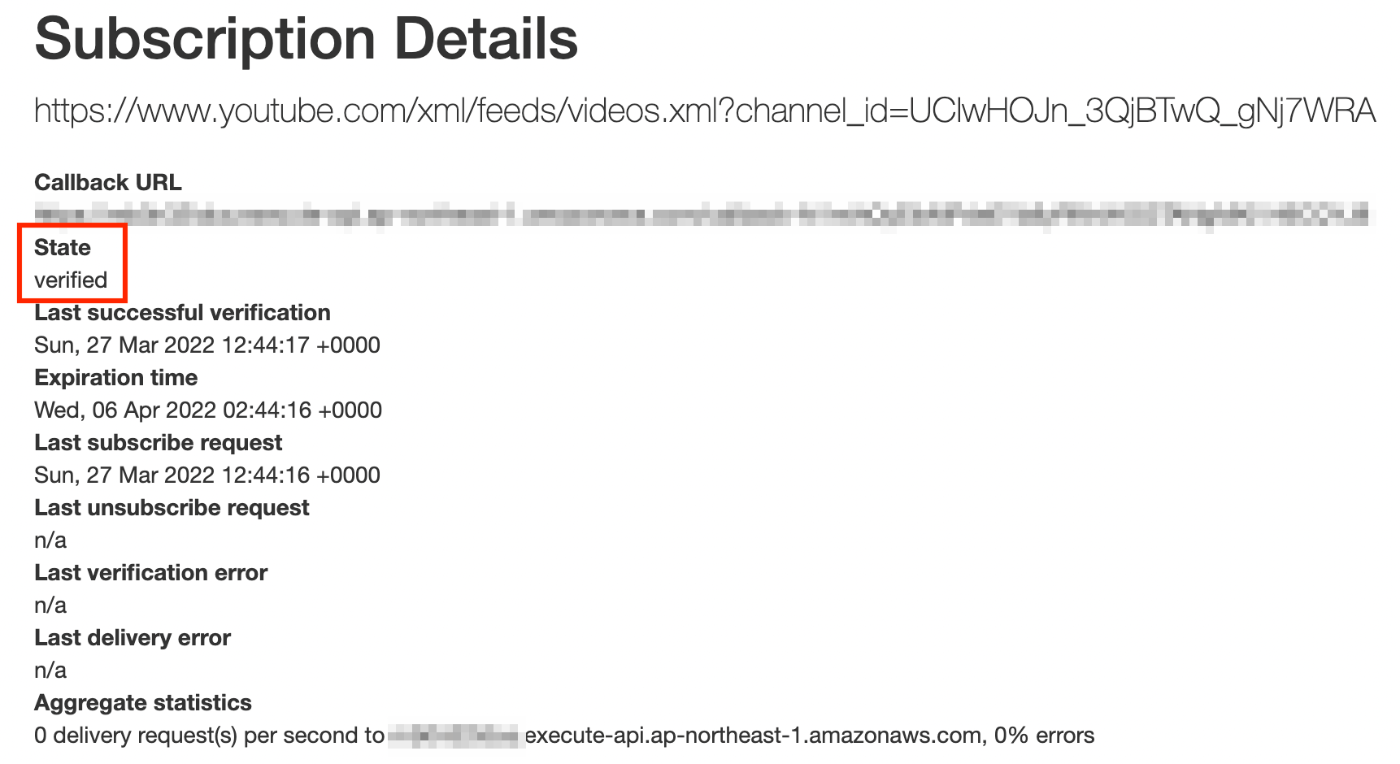
Stateがverifiedになっていると、購読確認が成功しています。
これで Google PubSubHubbub Hub の準備は完了です。
YouTube チャンネルの更新通知が Lambda に届くようになりました。
CloudWatch Log で動作確認
今回作成したプロジェクトをそのままデプロイすると、 Lambda applications に youtube-pubsubhubbub-lambda-dev というアプリケーションが新規で追加されているかと思います。
そして、 CloudWatch の Log groups から POST リクエスト(更新情報の通知)のほうの lambda のログを取っている/aws/lambda/youtube-pubsubhubbub-lambda-dev-notifyを参照します。
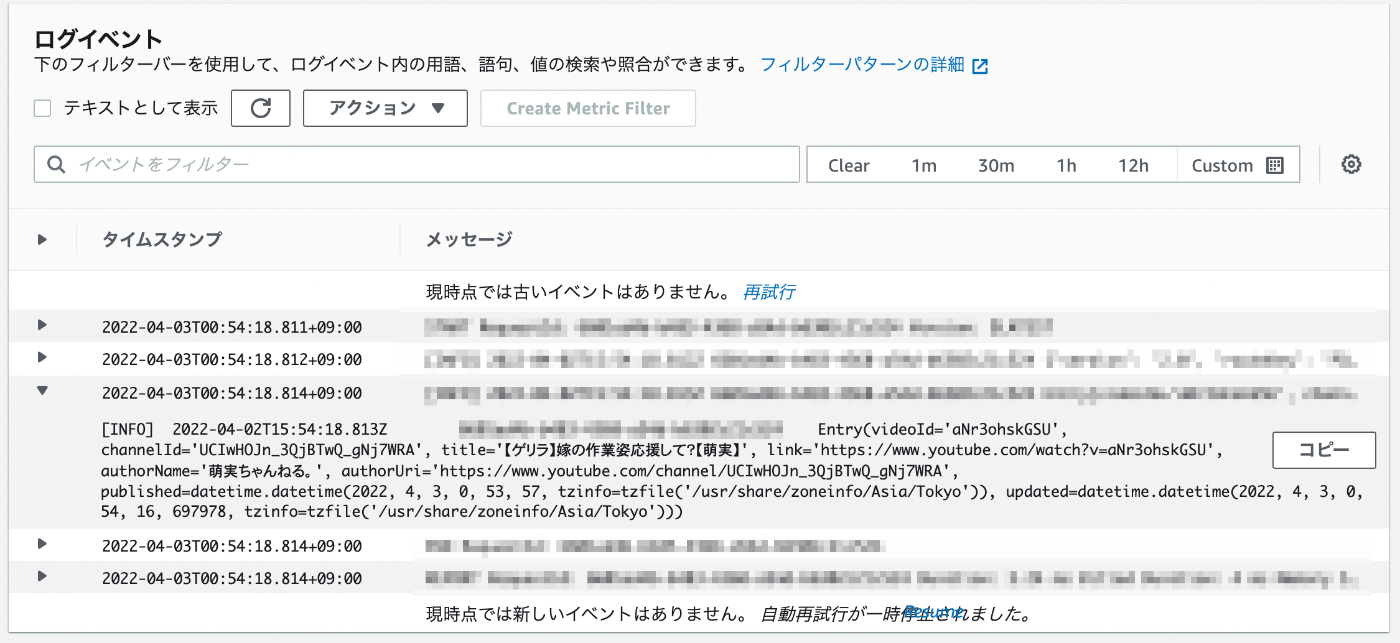
YouTube チャンネルの更新通知が正しくパースされ、Entryという dataclass が生成されている事が確認出来ました。
(偶然ですが、ゲリラ配信の通知を取得できました。こういったリアルタイム性も PubSubHubbub を使うメリットです。)
おわりに
長くなりましたが、最後まで読んでいただき、ありがとうございます。
WebSub や PubSubHubbub に関する技術的な記事は少なかったり、情報が古かったり、セキュリティ的に不安があったりしていました。(要出典)
ですが、 YouTube のチャンネルの更新通知を取得するには、これがより良い方法であると思いますし、ちゃんとした WebSub や PubSubHubbub に関する記事は必要だと感じました。
仕様書を読み解いて実装、解説をしているので、同様の目的( YouTube のチャンネルの更新通知を取得したい)の人や、 WebSub の Subscribers のアプリケーションを作りたい人の参考になれば幸いです。
ただし、この記事は2022年04月に書いたものなので、情報が古くなることにご留意ください。公式ドキュメントが正しいです。
あと、リポジトリへのスターやプルリクエストお待ちしています。
Discussion