🗂
QA集のEmbeddingsを考える

QA集をEmbeddingsする時、QだけをEmbeddingsするのか、キーワードなどの類似の言葉も含めるのか・・・
実際にどうベクトルが変わるのかを何件か確かめてみたのでメモ。
準備
対象のモデルはtext-embedding-ada-002です。
まずはサンプルをChatGPTさんに作ってもらいます。

いつもありがとうございます。
2個目のサンプルを使ってみます。
ChatGPTを使う場合、マークダウンちっくな書き方で見出しを書いてやると良いなんて言うのEmbeddingsではどうか試す。
テストアプリを作ってみました。
上の入力フォームと、下の入力フォームのベクトルのコサイン類似度を計算するものです。

色々試す
まずは見出しを消してみます。
結果、数値が上がりました。見出しがあると類似度が下がるようです。考えてみたらそれはそうなのかも。

ちなみに質問文そのままだと当然ですが高い数値になります。
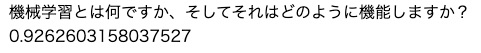
こんな感じでいくつかのパターンを入力してみます。

キーワードとして付与していた言葉についても確認します。

文章中にはない、近い言葉も確認してみます。
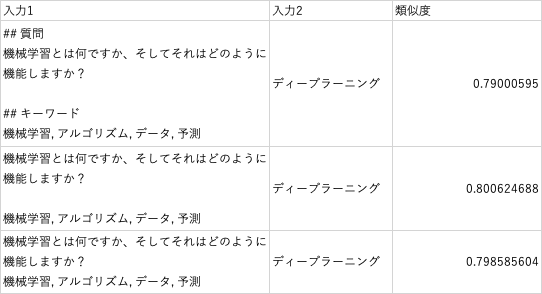
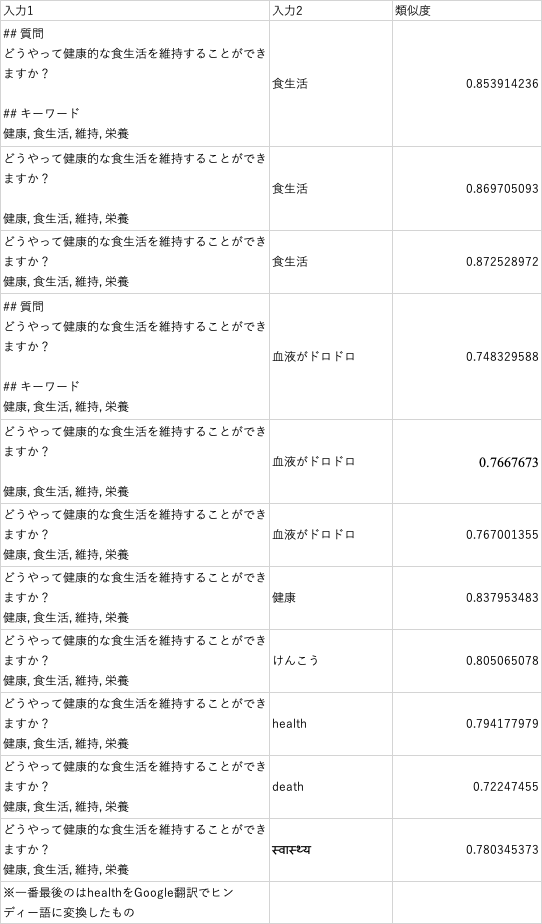
他の例文でも確認してみます。
今回の結果
- キーワードを付与すると、メインの質問の中にある言葉での類似度はちょっと下がる
- キーワードを付与すると、キーワードの類似度が上がる
- 質問とキーワードを見出しをつけて連結するより、単純に連結した方が類似度が上がる
- 違う言語でも近い言葉は類似度が上がる
単語を入力とするべきではないのかもしれませんが、実際QAシステムを使う場合って単語だけで検索することが多いと思うので単語メインで比較しました。
ただ、考えてみたら単語での検索って日本人の特性(というより日本語とGoogle検索の特性?)であって、これからは徐々に文章による検索が普通になるのかもしれませんね。
Discussion