🌳
決定木の定義と仕組み
決定木とは?
決定木 (Decision Tree) は分類 (classification) や回帰 (regression) に使われる機械学習アルゴリズムです。
知っておきたい単語
-
ルートノード (Root Node)
決定木の一番上にあるスタート地点となるノード -
内部ノード (Internal Node)
ルートノード以外で、特徴量に基づいてデータを分割するノード -
リーフノード (Leaf Node)
決定木の終端ノードで、ここで最終的な予測(クラスラベルまたは数値)が行われる -
特徴量 (Feature or Attribute)
予測や分類に重要な情報を持っている変数 -
枝 (Branch)
ノード間をつなぐ線で、データの流れを表す -
分割 (Split)
データを特徴量に基づいて複数の部分に分けるプロセス -
不純度 (Impurity)
ノード内のデータがどれだけ混在しているかを表す指標-
ジニ不純度 (Gini Impurity)
各ノードにおけるデータの不純度を測る指標; 値が小さいほどデータが純粋に分類されていることを示す -
エントロピー (Entropy)
情報理論に基づく不純度の指標で、情報ゲインを計算する際に使われることがある -
平均二乗誤差 (Mean Square Error)
予測値と実際の値の差の二乗を平均したもの; 回帰モデルの予測精度を評価するためによく使われる
-
ジニ不純度 (Gini Impurity)
-
情報ゲイン (Information Gain)
特徴量によってデータがどれだけうまく分割されるかを評価する指標
決定木の基本的な仕組み
-
ルートノードからスタート
全てのデータをルートノードに集め、最も重要な特徴量を選び分割を始めます。 -
特徴量の選択と条件による分割
最も重要な特徴量をデータの不純度をベースに選び、分割を始めます。 -
分割を繰り返す
ルートノードでの分割が終わると、各サブグループで再び特徴量を選んでデータを分割します。この過程は、データが純粋になるか、または指定された条件(木の最大深さや最小サンプル数など)に達するまで繰り返されます。 -
リーフノードに到達する
すべてのデータが最終的にリーフノードに到達します。リーフノードでは、そのノードに属するデータがほぼ同じクラスに分類されていることが理想です。
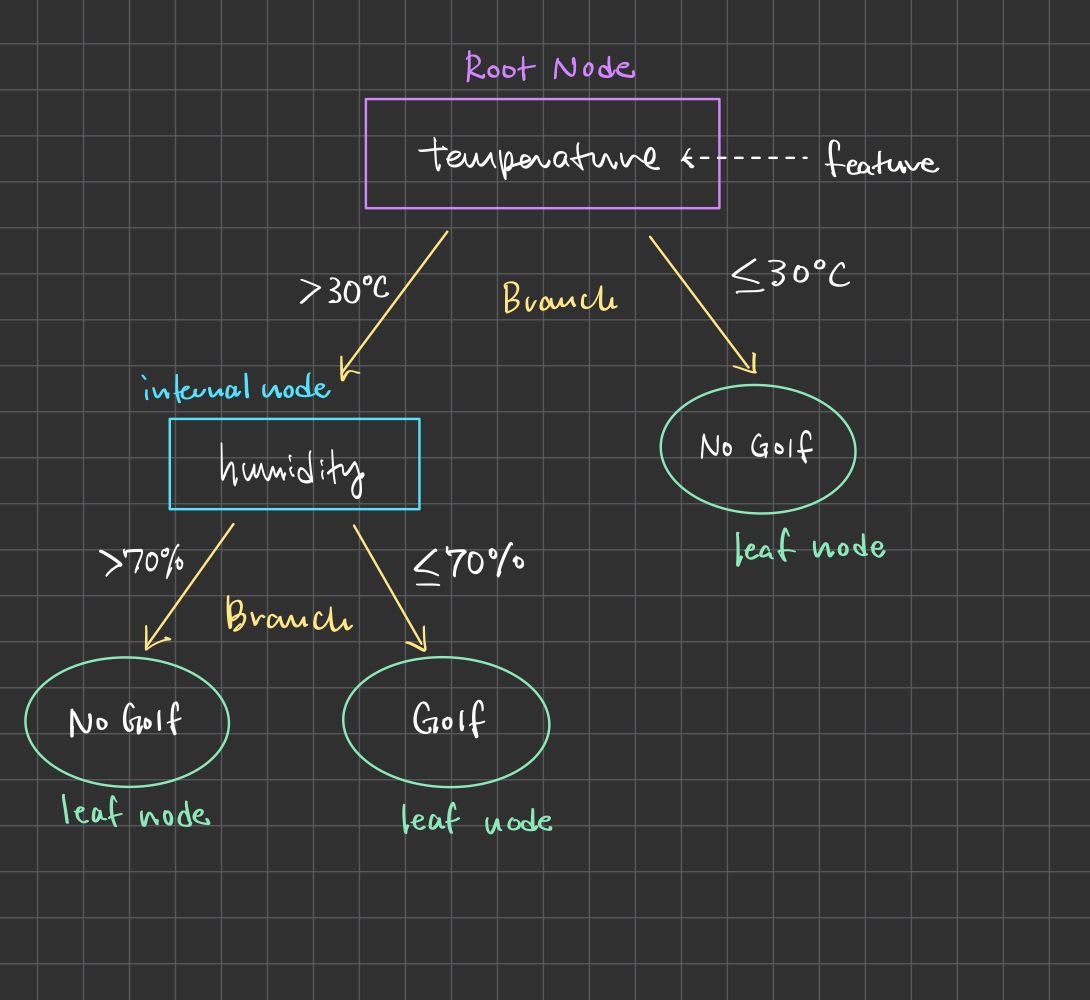
決定木の例
ゴルフに行くか行かないかを決定木を使って予測してみよう!
サンプルデータ
| 気温 (°C) | 湿度 (%) | ゴルフをするか |
|---|---|---|
| 32 | 80 | いいえ |
| 28 | 65 | いいえ |
| 35 | 60 | はい |
| 29 | 75 | いいえ |
| 33 | 72 | はい |
| 30 | 55 | はい |
決定木の動き
- ルートノードで「気温が30度以上か?」という条件をチェック
- 気温が30度以上の場合、次に「湿度が70%以上か?」を確認
- これらの条件によって、ゴルフをするかどうかが決まる
Discussion