Numeraiでランク学習してみた
はじめに
この記事はNumerai Advent Calendar 2021の15日目の記事です。
私がNumeraiのモデル構築に四苦八苦している中、機械学習コンペのプラットフォームSignateでSignalsに似た課題設定のコンペ「J-Quants」が開催されました。
具体的には特定の銘柄の変動率の「順位」を予想するタスクでした。Signalsと非常に良く似ていますよね。
さらに、上位入賞者によるプレゼンテーションが行われた上にコードまで公開されました。
1位の方のプレゼンテーションの中で、学習には「ランク学習」なるものを用いた、とあり、ランク学習を全く知らなかった私としては、これでNumeraiでも強いモデルが作れるのではと藁にもすがる思いでやってみました。lightGBMにちょうどランク学習に対応したLGBMRankerがあって助かりました。
ランク学習とは
こちらの記事が非常にわかりやすかったです。
簡単に言うと、ランク学習ではtargetの値を推論できるように学習するのではなく、その名の通りtargetの順位を推論できるように学習します。
例えば、「googleで検索ワードに対して記事をどのように評価するか」や、下のサイトの例のように、「amazonのユーザーが商品をどのように評価するか」など、検索クエリに対して評価の順位付けを行うタスクによく用いられます。
順位付けとは、例えば、本来のラベルが「5, 4, 3, 2, 1」であるところを、「4, 4, 2, 1, 1」と予想したときに、ラベルの予想はズレていますが、順位は完全に予想できていることになります。
Numeraiではeraを検索クエリとして、各idで表される銘柄のtargetの順位付けを行うことになります。
注意点
データ作成時の注意点としては、一般的なテーブルデータに対するモデルでは1行が1件を表しており、他の行との関りはない(並び変えても問題ない)ですが、ランク学習をする際には検索クエリと順位付けを行う対象をリンクさせる必要があるので、何行ごとに別のクエリに変わっているかのリストを渡す必要があります。
def get_model_input(df):
"""
LGBMRankerに入力するデータを取得する
"""
df.reset_index(inplace=True)
# 検索クエリ
query_list = df['era'].value_counts()
# クエリリストをインデックスでソート
query_list = query_list.sort_index()
# era, idをインデックス化
df = df.set_index(['era', 'id'])
# 特徴量と目的変数データをインデックスでソート
df.sort_index(inplace=True)
# 特徴量
df_x = df[features]
# 目的変数
df_y = df[TARGET_COL]
return df_x, df_y, query_list
また、モデル作成時の注意事項としては、
- label_gain = np.arange(max_labels):よくあるランク学習では検索結果の上位を推論するために使用したりなど、上位のラベルについて関心があるので、デフォルトでは上位のラベルに指数関数的に大きく重みがつけられています。紹介した望月さんのコードでは線形に設定していたので、このコードでも線形に設定しています。Numeraiのようなタスクでは上位に限らず上位から下位までまんべんなく予想することが求められるからなのかと考えています。
- lambdarank_truncation_level = max_labels:上と同じ理由でデフォルトでは上位30位までしか学習時に利用してくれないので、まんべんなく利用してくれるように変更しています。
があります。
model = lgb.LGBMRanker(
label_gain = np.arange(10),
lambdarank_truncation_level = max(query_list_train),
)
実際のコードがこちらです。
結果
rank学習(上)と単純なテーブルデータとして学習させた(下)モデルのdiagnosticsが以下です。
もちろん同じ特徴量(small)で学習させています。

LGBMRanker
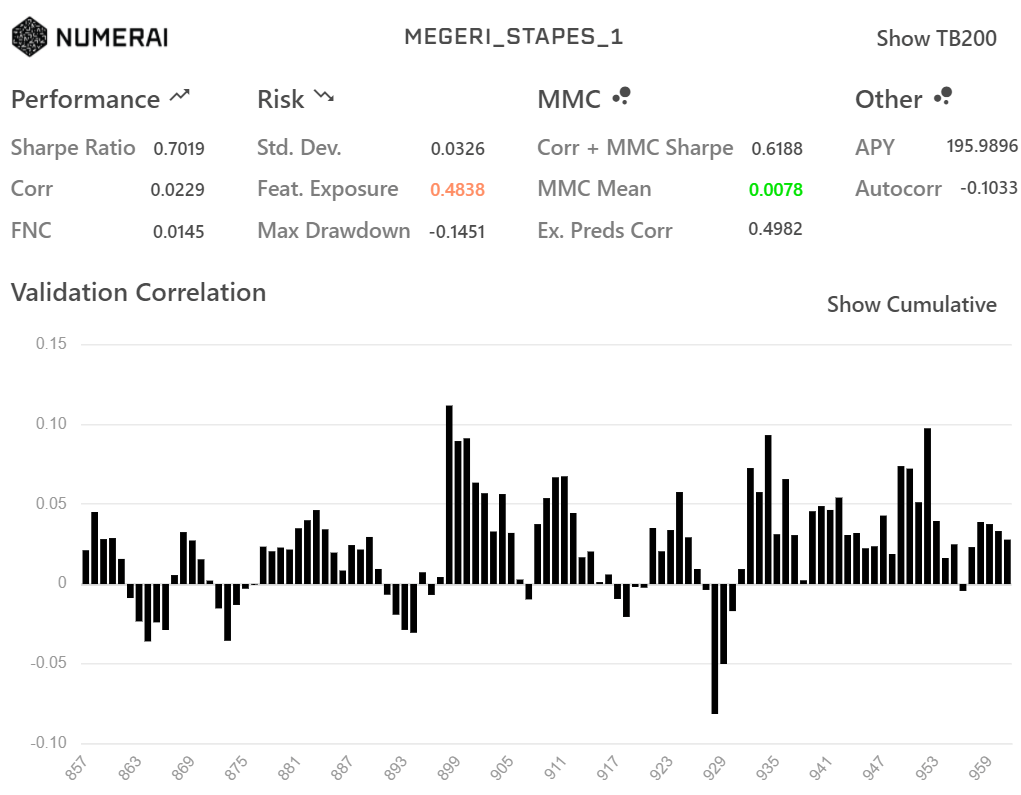
LGBMRegressor
各種指標の値もグラフの形もほとんど同じになりました。
上で挙げたlabel_gainを線形にしてlambdarank_truncation_levelを大きくするとほとんど同じ挙動をするのかもしれません。
この2つのパラメータをはじめとして色々いじってみるとsampleより強いモデルが作れるかもしれないのでぜひ試してみてください!
ちなみに、label_gainを指数関数的(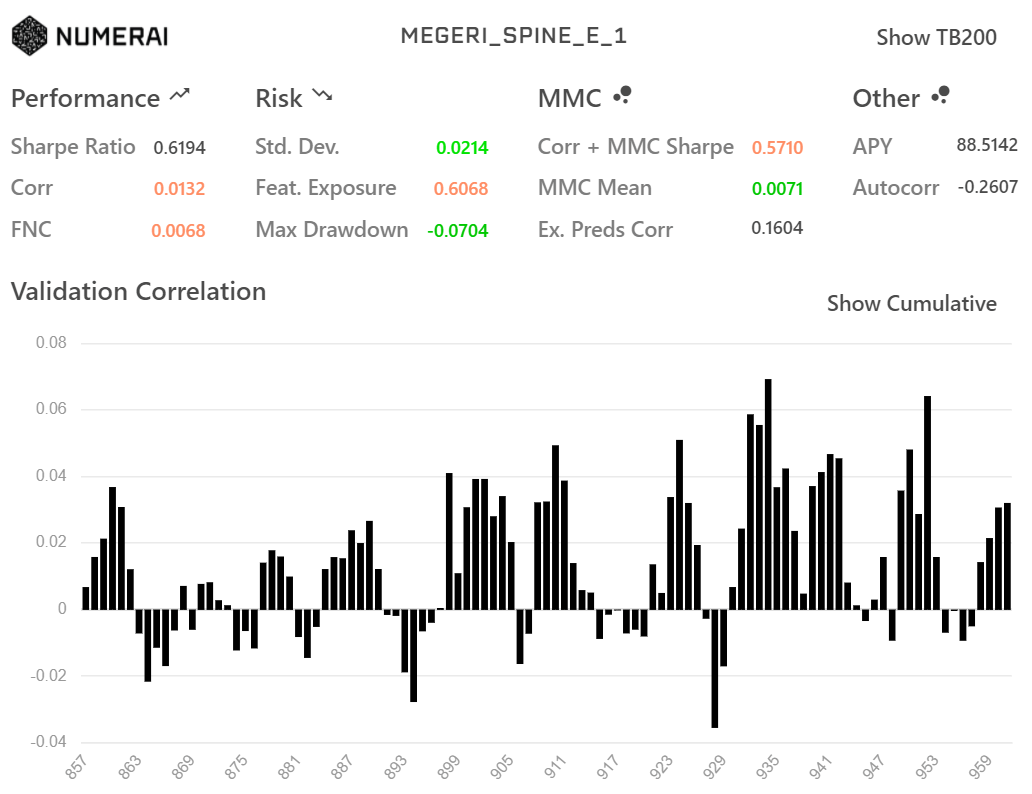
gainを指数関数的にしたもの
明らかに弱くなっているのでやはりgainは線形がよさそうです。
Discussion