

はじめに
ご覧いただきありがとうございます。阿河です。
S3バケット内にCSVファイルをアップロードした際に、自動でAmazon Aurora内のテーブルにデータを反映させる検証を行いました。
前半(本記事)はS3自動通知/SQS/重複処理を避けるためのLambdaとDynamoDB連携など、後半(次回記事)はLambda~Aurora間の処理/Secrets Managerとの連携などを取り上げます。
対象者
- AWSを運用中の方
- 日々のデータ管理を楽にしたいと思っている方
概要
※本記事の対象
- S3にデータを用意する
- S3イベント通知およびSQSとの連携
- LambdaとDynamoDBの連携
- S3からのデータ読み込み部分の実装
※次回記事
- Auroraデータベース作成/テーブル作成
- Secrets Managerの設定
- Lambda関数(PostgreSQLへの書き込み)
- 検証
シナリオとしては
- 支店(branch_officeA,branch_officeB,branch_officeC)ごとに「どの担当者が、どの顧客に対して、どの商品を契約したか」を、日付別でCSVデータにまとめています。
- S3バケット内は「バケット名-支店名-月-日-csvファイル」の階層構造になっています。
- S3バケット内にcsvファイルをアップロードすると、Lambda関数がトリガーされ、Aurora PostgreSQLデータベースにデータをInsertします。
1. S3にデータを用意する
事前準備
下記をあらかじめセットしてください。
- VPC
- パブリックサブネット*2/インターネットゲートウェイ/NATゲートウェイ
- プライベートサブネット*2
- ルートテーブル(パブリック:インターネットゲートウェイへのルートおよびlocal/プライベート:NATゲートウェイへのルートおよびlocal)
S3バケット内にフォルダ構造を作る

S3バケットを新規作成して、支店ごとにフォルダを作成する。

さらに各支店フォルダ配下に「月/日付」のフォルダを作成。
今回はテストのため、12月フォルダを作成して、その配下に月初3日分のフォルダを切りました。
テストファイルを用意

上記のようなファイルを数パターン用意します。
[支店名-顧客ID-商品ID]
※支店名はbranchA,B,C、商品IDはproductA,B,Cのみ。
支店ごとに、その日に契約した商品をリストアップ⇒csvファイルにまとめて、S3の所定の場所にアップロードするイメージです。
2. S3イベント通知およびSQSとの連携
Amazon S3内にオブジェクトが作成されたときに、SQSキューにイベントを送信できます。
SQSキューの作成
- SQSで「キューを作成」を選択
- タイプ: 標準

- メッセージ保持期間: 3日
- 暗号化: 有効
- アクセスポリシー: ベーシック
その他は特にデフォルトのまま、キューを作成。
アクセスポリシーをより制限する。
{
"Version": "2012-10-17",
"Id": "Policy1670697232147",
"Statement": [
{
"Sid": "Stmt1670697121445",
"Effect": "Allow",
"Principal": "*",
"Action": "sqs:SendMessage",
"Resource": "xxxxxxxxxxxxxxxxx",
"Condition": {
"ArnLike": {
"aws:SourceArn": "xxxxxxxxxxxxxx"
}
}
}
]
}
※「xxxxxxxxxxxx」には、それぞれSQSキューとS3バケットのARNを入れる。
イベント通知の設定

S3バケットの設定画面で、イベント通知を作成。
- イベント名: 任意の名前
- イベントタイプ: PUT
- 送信先: SQSキュー
- SQSキュー: 先ほど作成したSQSキュー


イベント通知の設定ができました。
S3にcsvファイルをアップロード
作成したCSVファイルを、S3バケットの適したフォルダ配下にアップロードします。

branchAの12月1日のcsvファイル(コンマ区切り)を、「バケット/branch_officeA/12/1/」配下にアップロードします。
SQSキューの画面に移動します。
「メッセージを送受信」を確認。

「メッセージをポーリング」を選択。
{"Records":[{"eventVersion":"2.1","eventSource":"aws:s3","awsRegion":"ap-northeast-1","eventTime":"2022-12-10T19:06:11.525Z","eventName":"ObjectCreated:Put","userIdentity":{"principalId":"AWS:xxxxxxxxxxxxxxxxxx"},"requestParameters":{"sourceIPAddress":"xxxxxxxxxxxxxxx"},"responseElements":{"x-amz-request-id":"xxxxxxxxxxxxxx","x-amz-id-2":"xxxxxxxxxxxxxxxxxxxxxxxxxxxxx"},"s3":{"s3SchemaVersion":"1.0","configurationId":"branch-event","bucket":{"name":"xxxxxxxxxxxxx","ownerIdentity":{"principalId":"xxxxxxxxxxxxxxxxxx},"arn":"arn:aws:s3:::xxxxxxxxxxxxx"},"object":{"key":"branch_officeA/12/1/branchA_20221201.csv","size":283,"eTag":"xxxxxxxxxxxxx","sequencer":"xxxxxxxxxxxxxxx"}}}]}
メッセージが取得できています。
ただし重複してメッセージを受け取ってしまっています。FIFOキューで重複削除を行おうとしましたが、S3イベント通知側の設定でFIFOキューを連携させることはできませんでした。
Lambdaの処理が重複して行われることを避けたいので、DynamoDBで重複処理を管理します。
3. LambdaとDynamoDBの連携
Lambda関数の作成
- 関数名: 任意の名前
- ランタイム: Python3.8
- IAMロール(AWSLambdaVPCAccessExecutionRole/AWSLambdaSQSQueueExecutionRole/その他S3,RDS,CloudWatch Logそれぞれの権限を要件に応じた強さで付与してください)
- VPCの有効化
- VPC
- サブネット: プライベートサブネットを指定
- セキュリティグループ: デフォルト
IAMロールの権限は要件に応じて絞ってください。
後程VPC内部でLambda~Aurora間のやり取りを行うので、LambdaをVPC内部に紐づけます。
import json
def lambda_handler(event, context):
a = event['Records'][0]['s3']['object']['key']
csv = a.split('/')
print(csv[3])
先程SQSキュー側で受け取ったイベントメッセージを、Lambdaのテストイベントに貼り、オブジェクトキーを出力してみます。
branchA_20221201.csv
問題なく出力されました。
DynamoDB作成
テーブルの作成を行います。
- テーブル名: 任意の名前
- パーティションキー: file_name 文字列
- デフォルト設定
Lambdaコードの修正
import boto3
s3 = boto3.client('s3')
dynamo = boto3.resource('dynamodb')
dynamo_table = dynamo.Table('postgre-dynamo')
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
filename = event['Records'][0]['s3']['object']['key'].split('/')
try:
add_item = {
'file_name': filename[3],
'status': 'exist'
}
response = dynamo_table.put_item(
Item=add_item,
ConditionExpression='attribute_not_exists(file_name)'
)
except Exception:
print('already exist')
Lambdaでテストを実行します。

DynamoDBの指定のテーブルに項目が追加されました。
もう一度Lambdaを実行します。
already exist
既にDynamoDB側にファイルデータ情報の登録があるので、PUTは行われませんでした。
これでLambdaの重複処理を割けます。
4. S3からのデータ読み込み部分の実装
Pandasの取り込み
- Lambdaコードの中でPandasライブラリを利用したいので、Lambda関数の「レイヤー設定」で、ライブラリを取り込みます。
上記GitHubからPandasのARNを探します。
cf. Python3.8⇒ap-northeast-1のcsv⇒ダウンロードしたCSVから、Pandasを探して、ARNをコピーします。

- Lambda関数のコードタブページの下部にある「レイヤー」で、「レイヤーの追加」を選択
- レイヤーを追加。PandasがLambdaコードで利用できるようになります。

S3ファイルの読み込み
Pandasを使って、S3に格納したcsvファイルの読み込みを行います。
import boto3
import pandas as pd
s3 = boto3.client('s3')
dynamo = boto3.resource('dynamodb')
dynamo_table = dynamo.Table('postgre-dynamo')
def file_read(bucket, filename):
obj = s3.get_object(Bucket=bucket, Key=filename)
df = pd.read_csv(obj['Body'], header=None)
df_len = len(df)
title_list = []
year_list = []
product_list = []
print(df_len)
for i in range(df_len):
title_list.append(df.iloc[i, 0])
year_list.append(df.iloc[i, 1])
product_list.append(df.iloc[i, 2])
print(title_list)
print(year_list)
print(product_list)
def lambda_handler(event, context):
bucket = event['Records'][0]['s3']['bucket']['name']
filename = event['Records'][0]['s3']['object']['key']
try:
add_item = {
'file_name': filename.split('/')[3],
'status': 'exist'
}
response = dynamo_table.put_item(
Item=add_item,
ConditionExpression='attribute_not_exists(file_name)'
)
file_read(bucket, filename)
except Exception:
print('already exist')
Lambdaコードの変更を保存したら、テスト実行します。
['branch_A', 'branch_A', 'branch_A', 'branch_A', 'branch_A', 'branch_A', 'branch_A', 'branch_A', 'branch_A', 'branch_A']
[11325678, 11432525, 11437543, 11432525, 11432525, 11432435, 11029255, 12872525, 11483625, 11298525]
['productB', 'productA', 'productA', 'productC', 'productA', 'productC', 'productB', 'productC', 'productB', 'productB']

S3にあるCSVファイルから読み取りが可能になりました。
SQS ~ Lambda間の連携
Lambda関数の設定画面で、トリガー設定を行います。

S3自動通知~ SQS ~ Lambda処理の確認

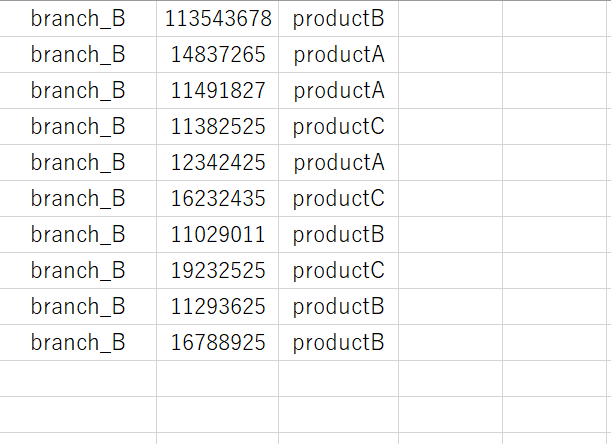
改めて、S3バケット内の所定位置にcsvファイルをアップロードします。

CloudWatch Logsを見ると、Lambdaが発火しています。
[ERROR] KeyError: 's3'
Traceback (most recent call last):
File "/var/task/lambda_function.py", line 33, in lambda_handler
bucket = event['Records'][0]['s3']['bucket']['name']
イベントの読み取り方に問題があるようです。
Lambdaのテストイベントに「sqs-receive-message」のテンプレートがあるので、見てみます。
{
"Records": [
{
"messageId": "19dd0b57-b21e-4ac1-bd88-01bbb068cb78",
"receiptHandle": "MessageReceiptHandle",
"body": "Hello from SQS!",
"attributes": {
"ApproximateReceiveCount": "1",
"SentTimestamp": "1523232000000",
"SenderId": "123456789012",
"ApproximateFirstReceiveTimestamp": "1523232000001"
},
"messageAttributes": {},
"md5OfBody": "{{{md5_of_body}}}",
"eventSource": "aws:sqs",
"eventSourceARN": "arn:aws:sqs:us-east-1:123456789012:MyQueue",
"awsRegion": "us-east-1"
}
]
}
イベント構造が異なるようです。
試しにコードを変更してデバッグしてみます。
import boto3
import pandas as pd
def lambda_handler(event, context):
print(event['Records'])
結論としてはbodyの部分に内容が入っていました。
'body': '{"Records":[{"eventVersion":"2.1","eventSource":"aws:s3","awsRegion":"ap-northeast-1","eventTime":"2022-12-11T10:10:26.925Z","eventName":"ObjectCreated:Put",
・・・・(略)・・・・
コードを修正します。
import boto3
import json
import pandas as pd
s3 = boto3.client('s3')
dynamo = boto3.resource('dynamodb')
dynamo_table = dynamo.Table('postgre-dynamo')
def file_read(bucket, filename):
obj = s3.get_object(Bucket=bucket, Key=filename)
df = pd.read_csv(obj['Body'], header=None)
df_len = len(df)
title_list = []
year_list = []
product_list = []
print(df_len)
for i in range(df_len):
title_list.append(df.iloc[i, 0])
year_list.append(df.iloc[i, 1])
product_list.append(df.iloc[i, 2])
print(title_list)
print(year_list)
print(product_list)
def lambda_handler(event, context):
sqs_event = event['Records'][0]['body']
ev = json.loads(sqs_event)
bucket = ev['Records'][0]['s3']['bucket']['name']
filename = ev['Records'][0]['s3']['object']['key']
try:
add_item = {
'file_name': filename.split('/')[3],
'status': 'exist'
}
response = dynamo_table.put_item(
Item=add_item,
ConditionExpression='attribute_not_exists(file_name)'
)
file_read(bucket, filename)
except Exception:
print('already exist')
イベント構造に従って、データを読み取ります。
※途中でjson.loads()が必要です。

問題なくログが出力されました。
合わせて別のデータもアップしてみます。
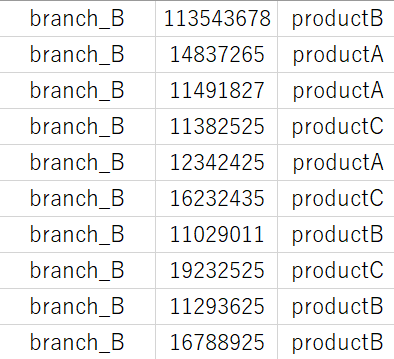

結果は以下の通りです。
['branch_B', 'branch_B', 'branch_B', 'branch_B', 'branch_B', 'branch_B', 'branch_B', 'branch_B', 'branch_B', 'branch_B']
[113543678, 14837265, 11491827, 11382525, 12342425, 16232435, 11029011, 19232525, 11293625, 16788925]
['productB', 'productA', 'productA', 'productC', 'productA', 'productC', 'productB', 'productC', 'productB', 'productB']
DynamoDB側にも情報が反映されています。
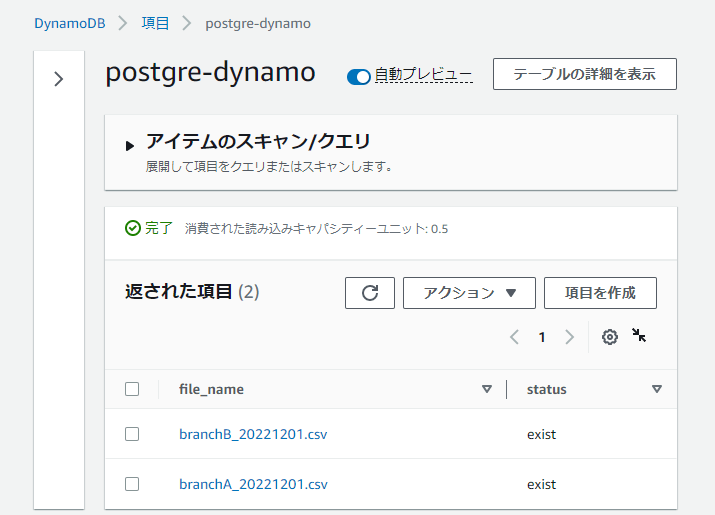
試しに先程S3バケットにアップロードしたデータを消して、アップし直しました。
already exist
重複処理が起こらないことも確認できました。
今回は以上です。
さいごに
今回は「S3にファイルアップロード⇒SQS⇒Lambdaの起動/DynamoDBとの連携」までを実装しました。
次回はS3にファイルアップロードを行うと、自動でAuroraデータベースに情報反映が行われるように設定していきます。
御覧いただき ありがとうございます!
MEGAZONEはAWS プレミアティア サービスパートナーとして多数のCompetencyを取得しており、大企業、ゲーム会社、スタートアップ、公共機関などさまざまな分野の5,000以上のお客様にAWSソリューションとサービスを提供しています。
Discussion