




はじめに
ご覧いただきありがとうございます。阿河です。
今後データ分析系のサービスを使いたいと思っていますが、SQLを書かなければならない場面があります。
そのためGW期間にSQLを速習しました!
今回はSQL/データベース強化月間 第一弾として「Amazon AthenaでSQLを書いてみた」をやってみたいと思います!
対象者
- AWSを運用中
- データ分析系のサービスはあまり触っていない
- 業務の中でSQLが必要なときはコピペで済ましている
- ProgateやUdemyなど、他の教材でざっとSQLの操作を学んでいるほうが望ましいです
4番の「クエリを実行」のセクションでは、ケーススタディの中でSQLを「考えて書く」練習ができます。
概要
(★)がついているところは、手を動かして頂く項目です。
- 今回のハンズオン構成
- S3にデータをアップロード(★)
- Amazon Athenaの準備 (★)
- クエリを実行(★)
事前準備
- AWSアカウント作成
- AdministratorAccessを付与したIAMユーザーの作成
1.今回のハンズオン構成/使用データ
【構成】
- Amazon Athena
- S3
- ファイルアップロード用のバケットを作成
- クエリ結果保存用のバケットを作成
今回ハンズオン用に、自作でCSVファイルを作成しました。
S3にCSVファイルをアップロードして、Amazon Athenaから分析できるように準備していきます。
【使用データ】
ダウンロードして、お使いください。
【ハンズオンの流れ】
公式ドキュメントによると、Amazon Athenaを使用するまでの手順は以下の通りです。
- Amazon Athenaからのクエリ結果を保存するS3バケットを作成
- Amazon Athenaでデータベースを作成
- テーブルの作成
- クエリを実行
2.S3にデータをアップロード
まずS3側で準備を行います。
-
ファイルアップロード用にS3バケットを作成
(AWSマネジメントコンソール上の操作) S3⇒バケット⇒バケットを作成 -
ファイルアップロード用S3バケット配下に、/Salesおよび/Actionフォルダをそれぞれ作成
(AWSマネジメントコンソール上の操作) S3⇒バケット⇒フォルダの作成
- ファイルアップロード用のS3バケットにcsvデータをアップロード
(AWSマネジメントコンソール上の操作) S3⇒バケット⇒※バケットを指定⇒オブジェクトタブ⇒/Sales⇒アップロード
「ファイルを追加」ボタンから、ローカルにおとしたSalesデータをアップロードしてください。
アップロードが完了したら、S3バケット/Sales配下に、Salesデータがあることを確認しましょう。
同じ手順で、/Action配下にActionデータをアップロードします。
- Athenaからクエリした結果を保存するS3バケットを作成
これでS3側の準備は完了です。
3.Amazon Athenaの準備
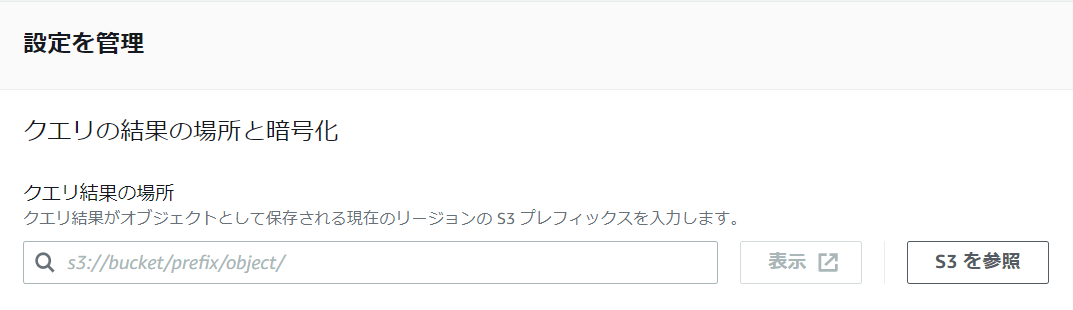
- クエリ保存先の設定
(AWSマネジメントコンソール上の操作) Amazon Athena⇒クエリエディタ⇒クエリを開始

設定タブ⇒管理にすすみ、クエリ結果の保存場所を指定します。
先程作成をしたS3バケット(クエリ結果保存用)を選択してください。
- データベースの作成
クエリエディタに、下記クエリを書いて実行する。
CREATE DATABASE mydatabase
mydatabaseという名前のデータベースを作成します。
データベースを作成したので、次はテーブルを作成します。
まずはSalesテーブルから作成してみましょう。
テーブル作成に必要な情報を確認するために、先程S3にアップロードしたSalesデータを確認してみましょう。
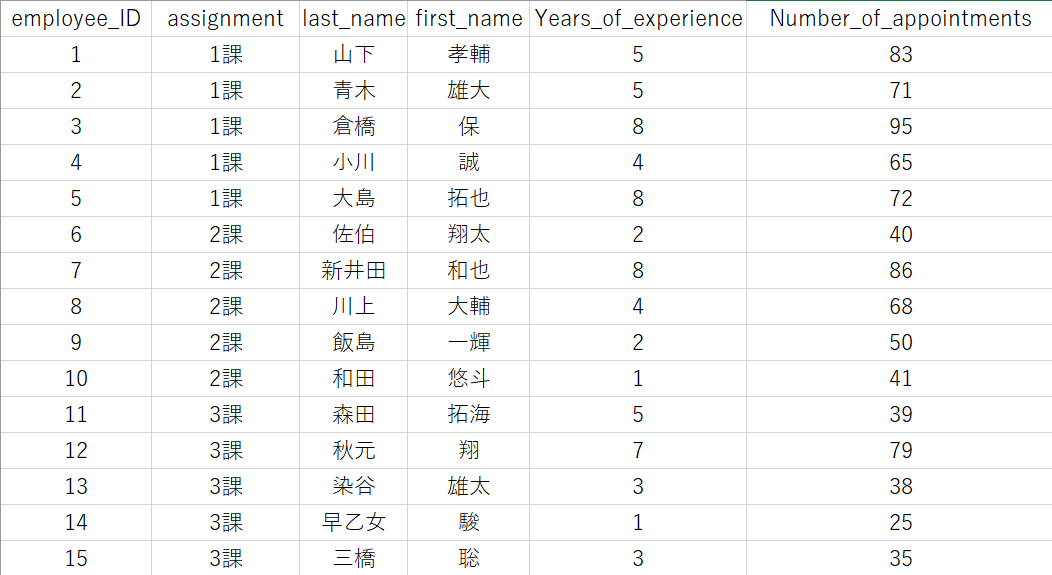
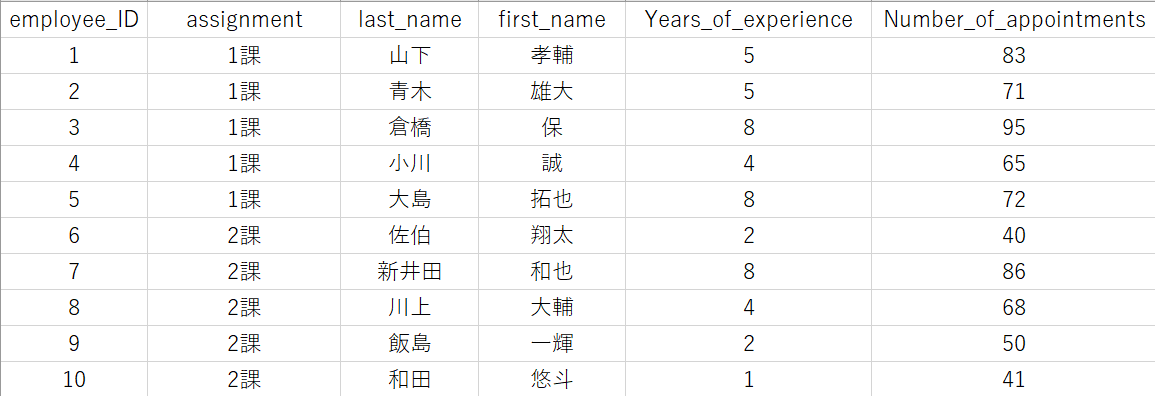
必要な列名は
「employee_ID(社員ID)」「assignment(配属)」「last_name(苗字)」「first_name(名前)」「Years_of_experience(入社年数)」「Number_of_appointments(月のアポイント件数)」
の6つです。
今回のカラムで使用するデータ型は、INT型とSTRING型です。
CREATE EXTERNAL TABLE IF NOT EXISTS mydatabase.sales (
employee_ID int,
assignment string,
last_name string,
first_name string,
Years_of_experience int,
Number_of_appointments int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
)
LOCATION 's3://[※S3バケット名を入力]/Sales/'
TBLPROPERTIES (
'has_encrypted_data'='false'
)
無事テーブルは作成できたでしょうか。
ここで行ったことをザっと説明します。
CREATE EXTERNAL TABLE IF NOT EXISTS mydatabase.sales (
employee_ID int,
assignment string,
last_name string,
first_name string,
Years_of_experience int,
Number_of_appointments int
)
・・・
LOCATION 's3://[※S3バケット名を入力]/Sales'
外部テーブルを作成します。
データを照会する機能を保持しながら、そのデータを外部に持ちます。
カッコ内で、項目名と型を指定します。
「employee_ID」「assignment」「last_name」「first_name」「Years_of_experience」「Number_of_appointments」が項目にあたります。
Locationで、CSVをアップロードしたS3バケットのディレクトリを指定します。
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
)
こちらは公式ドキュメントを引用させていただきます。
SerDeは、Athena で使用されているデータカタログにデータの処理方法を指示するカスタムライブラリです。
SerDe タイプは、Athenaで CREATE TABLEステートメントのROW FORMAT部分にSerDeタイプを明示的にリストすることによって指定します。
今回はCSVデータの処理で、かつデータに二重引用符(")で囲まれた値が含まれていないため、デフォルトのLazySimpleSerDeを使用します。
区切り文字を指定するには、WITH SERDEPROPERTIES を使用します。
※データ: CSV UTF-8(コンマ区切り)
TBLPROPERTIES (
'has_encrypted_data'='false'
)
TBLPROPERTIESのhas_encrypted_dataは、Locationで指定するデータの暗号化に関わる設定です。
ではテーブルの作成結果を確認してみましょう。
SELECT句でsalesテーブルからすべてのカラムのデータを取得します。
※表示するのは10行のみ。
SELECT *
FROM "mydatabase"."sales"
limit 10;
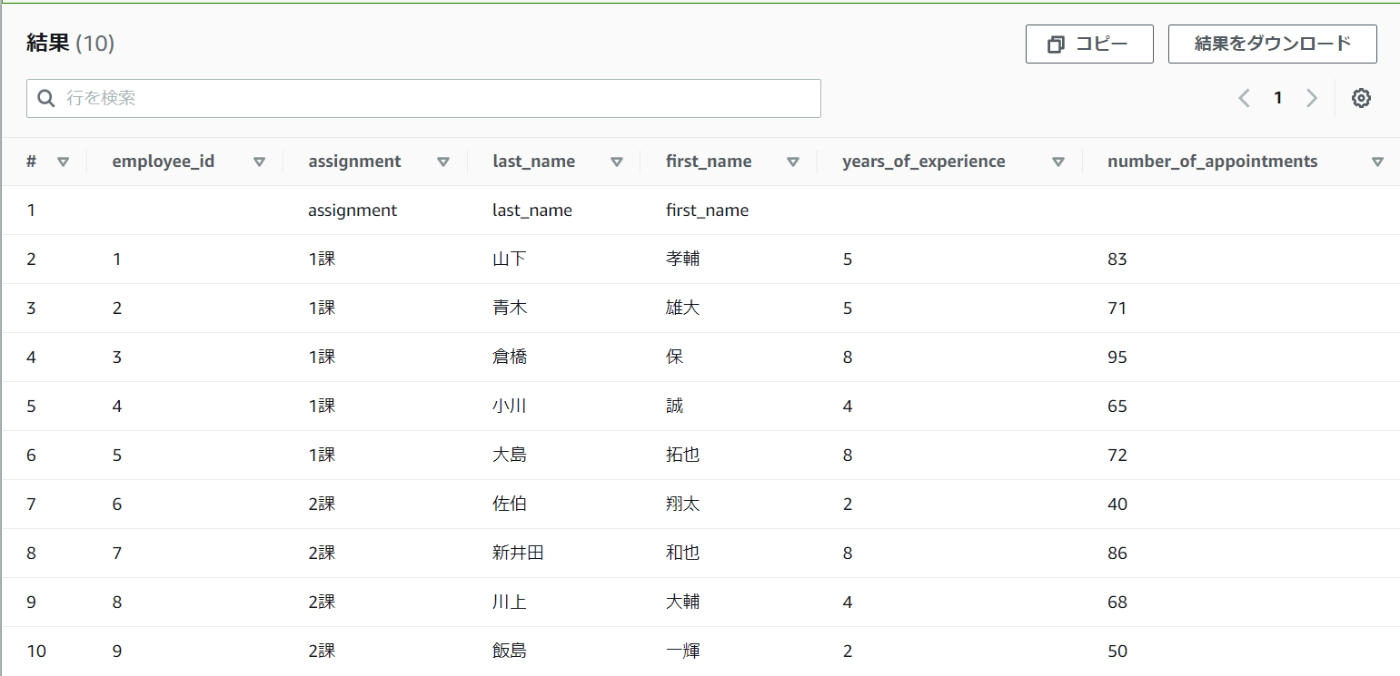
テーブルを確認すると、1行目に余分なものが入っています。
原因はSalesデータの一行目に列名が入っているからです。
改善が必要です。
CREATE EXTERNAL TABLE IF NOT EXISTS mydatabase.sales (
employee_ID int,
assignment string,
last_name string,
first_name string,
Years_of_experience int,
Number_of_appointments int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
)
LOCATION 's3://[※S3バケット名を入力]/Sales/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1'
)
skip.header.line.count テーブルプロパティの設定を追加することで、ヘッダーを無視できます。
再度SELECT句を実行してみましょう。
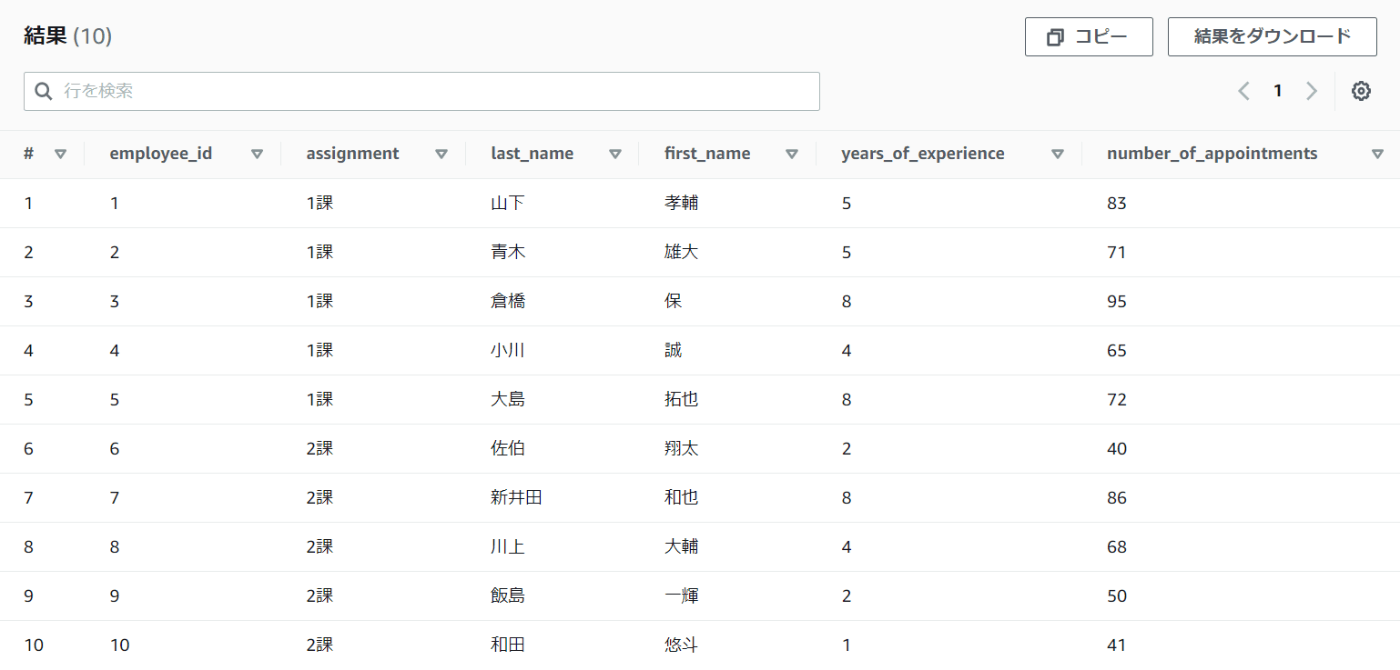
想定していた通りのテーブルが表示されました。
なお文字化けが発生する場合は、文字コードによるエラーの可能性があります。
TBLPROPERTIES内で、serialization.encodingの設定により解決することもありますが、CSVファイル自体をUTF-8で保存しておいたほうが無難だと思います。
では同じようにActionテーブルも作成してみましょう。
データはこちらです。
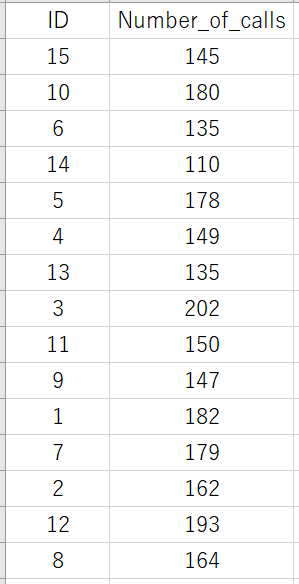
必要な列は「ID(職員ID)」「Number_of_calls(架電数)」です。
CREATE EXTERNAL TABLE IF NOT EXISTS mydatabase.Action (
ID int,
Number_of_calls int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
)
LOCATION 's3://[※S3バケット名を入力]/Action/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1'
)
テーブルを作成します。
結果はいかがでしょうか。
SELECTを実行してみましょう。

2つのテーブルを作成できました。

クエリを実行する環境が整いました。
4.クエリを実行
ケーススタディの中で様々なクエリを実行してみましょう。
① それぞれのチームごとに「所属人員数」「経験年数の平均」を取得する
SELECT COUNT(assignment) AS Number, AVG(years_of_experience) AS Avg_exprience
FROM mydatabase.sales
GROUP BY assignment
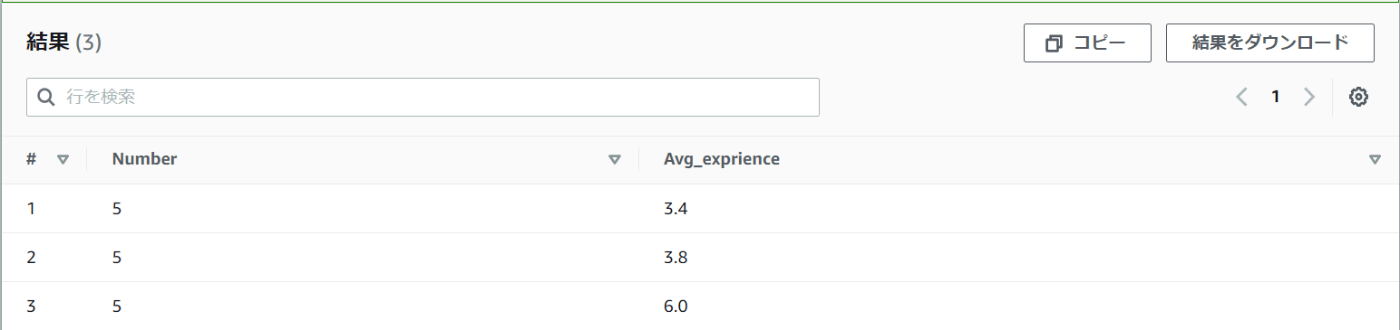
どのチームも人員は5人ですが、メンバーの社歴の平均をとると、1つのチームだけ数値が高いようです。
今のままではどのチームが数値が高いのか判別できません。
並べ替えが必要です。
SELECT COUNT(assignment) AS Number, AVG(years_of_experience) AS Avg_exprience
FROM mydatabase.sales
GROUP BY assignment
ORDER BY assignment
ORDER BYを使って、1課/2課/3課を昇順に並べました。
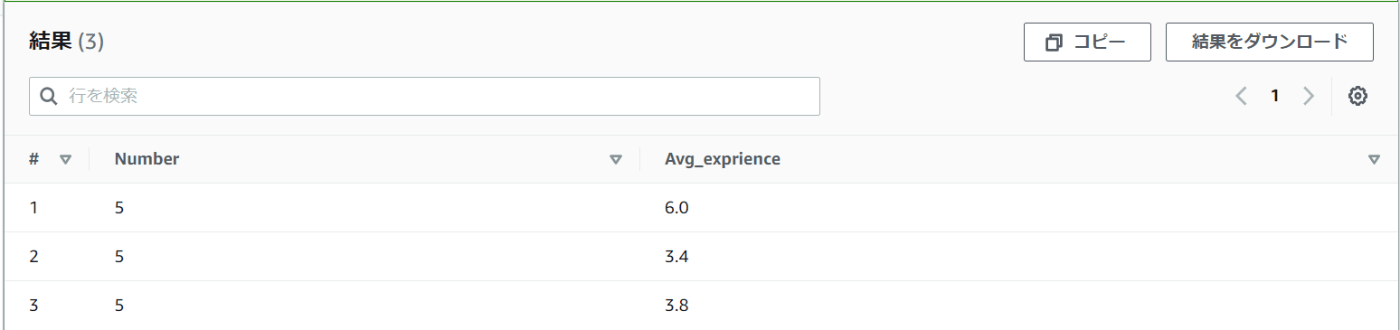
結果は1課はベテランメンバーが揃っていて、2課/3課は若手メンバーも多く在籍しているような結果になりました。
②それぞれの課ごとに「アポイントの合計」「アポイントの平均」「チームのアポイント取得ノルマが320件(1人80件)だった場合、どれくらい足りないか」を取得する
number_of_appointmentsは、月のアポイント数の合計値を指しています。
チームごとの、月間アポイント合計数を求めてみましょう。
SELECT SUM(number_of_appointments) AS Sum_appoint,
AVG(number_of_appointments) AS Avg_exprience,
(320 - SUM(Number_of_appointments)) AS Loss
FROM mydatabase.sales
GROUP BY assignment
ORDER BY assignment
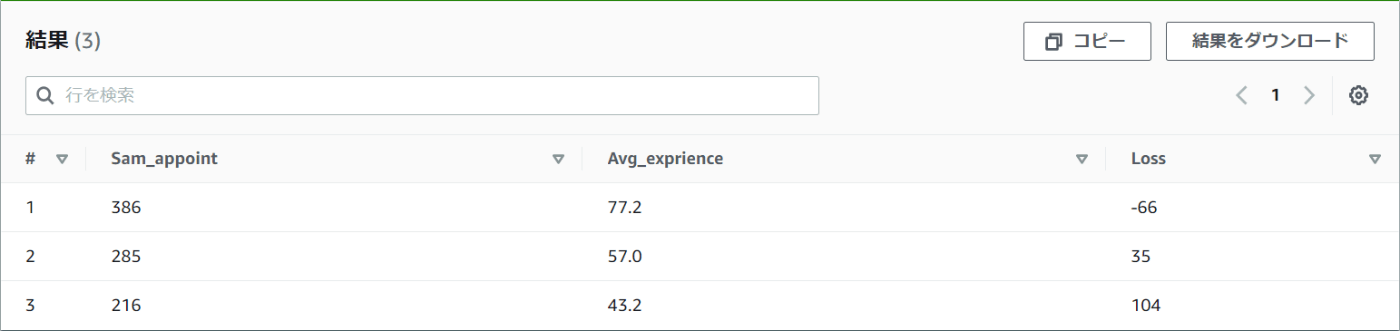
ベテランが多いからなのか1課のアポイント取得数は多いですね。
一方で2課と3課はメンバーの平均社歴はあまり変わらないようですが、チームの成績に差があります。
ちなみに1課はノルマを達成しているため、Lossの数値がマイナスになってしまいました。
これではわかりづらいので、少し変更を加えます。
③それぞれの課ごとに「アポイントの合計」「アポイントの平均」「チームのアポイント取得ノルマが320件(1人80件)だった場合、どれくらい差があるか」「ノルマ達成の是非」を取得する
SELECT SUM(number_of_appointments) AS Sam_appoint,
AVG(number_of_appointments) AS Avg_exprience,
ABS(320 - SUM(Number_of_appointments)) AS Difference,
IF((320 - SUM(Number_of_appointments) < 0),True,false) AS Result
FROM mydatabase.sales
GROUP BY assignment
ORDER BY assignment
まずABS関数を使い、ノルマとの差を絶対値で求めます。
そしてIF関数でノルマを超えたか超えてないか判定することで、「チームとして目標を達成したのか、ノルマに対してどれほど開きがあるのか」が一目で分かります。
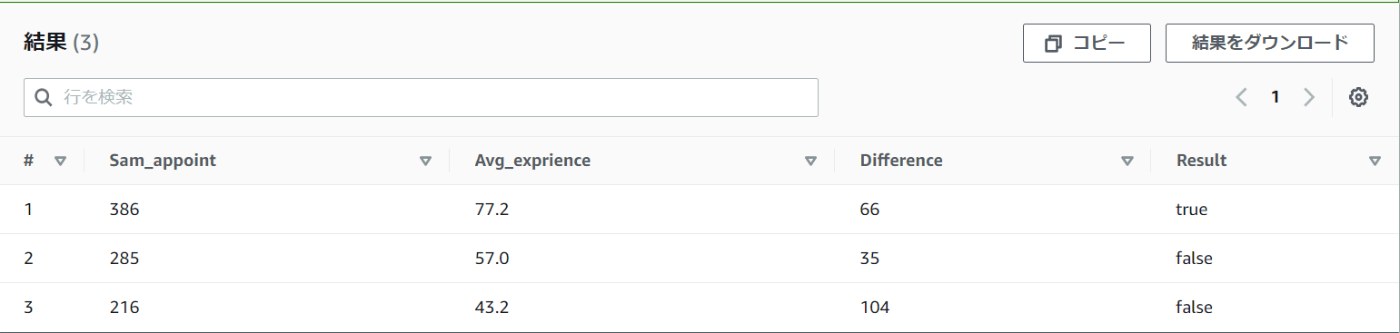
なぜ3チームにこれほどの差が生まれたのでしょうか。
④課ごとに「架電件数」「架電件数の平均」を調べる
チームごとに、一日の架電件数の開きはあるのでしょうか。
Actionテーブルを使います。
とある日の架電件数を職員ごとにまとめたデータです。
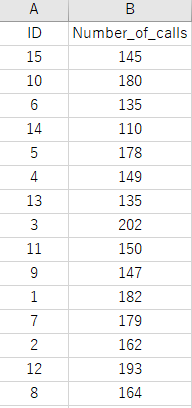
ActionテーブルのIDは、Salesテーブルのemployee_IDに対応しています。
よって2つのテーブルを結合すれば、各職員ごとの架電数が分かります。
しかしActionテーブルのIDは順番がバラバラのため、情報の整理が必要です。
SELECT assignment,
SUM(number_of_calls) AS Num_call,
Avg(number_of_calls) AS Avg_call
FROM mydatabase.sales
JOIN mydatabase.Action
ON employee_id = id
GROUP BY assignment
ORDER BY assignment;
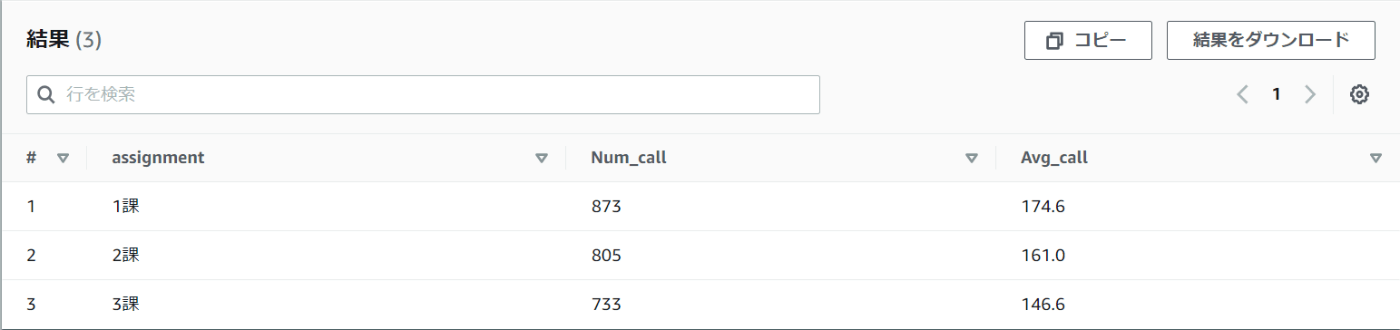
確認すると、1課と3課で一日140件ほどの架電件数の開きがあります。
また3課は平均架電件数が少ない印象を受けます。
架電件数が全ての原因とはいえないですが、少なくとも仕事の効率性という意味で何か問題があるかもしれません。
⑤成績下位5人と上位5人の「フルネーム」「配属」「社歴」「月間アポイント数」「架電件数」を取得する
成績上位と成績下位のデータをピックアップしましょう。
まずは下位5人です。
SELECT CONCAT(last_name,first_name),
assignment,
years_of_experience,
number_of_appointments,
number_of_calls
FROM mydatabase.sales
JOIN mydatabase.Action
ON employee_id = id
ORDER BY number_of_appointments
limit 5;
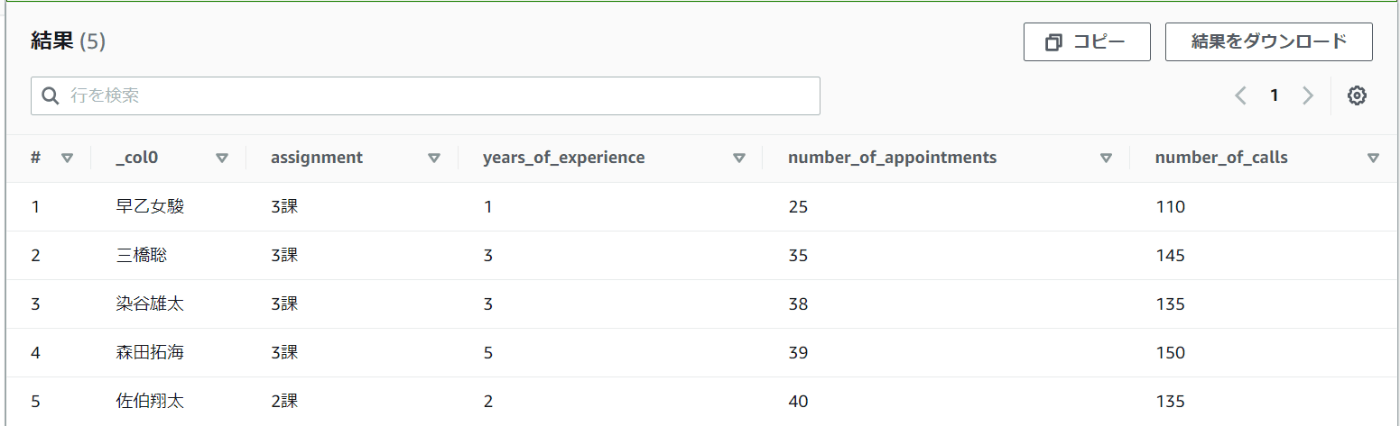
全体的に社歴が浅いのはありますが
・下位が3課に集中している
・架電件数が少ない
傾向にあります。
社歴平均では2課も同じようなものなので、3課のチーム内で改善が必要そうです。
次は上位5人を見てみましょう。
SELECT CONCAT(last_name,first_name),
assignment,
years_of_experience,
number_of_appointments,
number_of_calls
FROM mydatabase.sales
JOIN mydatabase.Action
ON employee_id = id
ORDER BY number_of_appointments desc
limit 5;
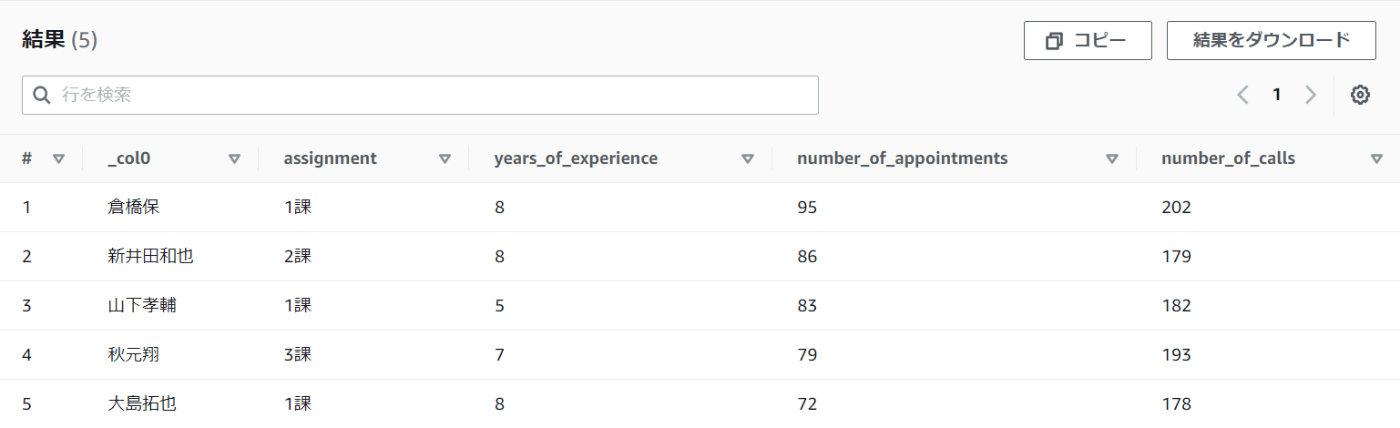
ORDER BYで降順にするだけでOKです。
ベテラン勢が多いですが、架電件数が安定して多いですね。
また3課のメンバーが一人入っていますが、この方が一人で三課の数字を引き上げているようです。
3課には改善の余地があるらしいと分かったところで、ハンズオンを終わらせていただきます。
さいごに
というわけでAmazon Athenaを使うと、分析環境が素早く手に入ります。
普段AWSのデータ分析系サービスを触らないという方は、SQLをざっと学んでから 試してみてはいかがでしょうか。
以上です。
本日もお疲れ様でした!!
MEGAZONEはAWS プレミアティア サービスパートナーとして多数のCompetencyを取得しており、大企業、ゲーム会社、スタートアップ、公共機関などさまざまな分野の5,000以上のお客様にAWSソリューションとサービスを提供しています。
Discussion