外部インターフェイスとしてのデータベースの拡張性と後方互換性
これは SmartHR Advent Calendar 2023 シリーズ1の11日目の記事です。
はじめに
この記事ではサービスが外にデータベースのテーブルを公開インターフェイスとして提供する場合について、一般的な REST の Web API と比較しながらどのようにインターフェイス自体と内部の実装との成長を実現するかをまとめています。
前提として一つのデータベースを複数のサービスから依存される状態は「共有データベース」と呼ばれてマイクロサービスの文脈で避けられています。サービス間の依存関係の増加、スキーマ変更の影響範囲も広く、サービスの自律性を失うことにつながることが避けられる理由として挙げられます。
しかし、データの統合において共有データベースを限定的に利用することは、メリットやリスクを慎重に評すればサービス間でデータの統合を行う有効なアプローチの一つになると考えます。
データベースを公開インターフェイスとして利用してもらう上で、そのインターフェイス自体と内部の実装との成長において無視できないものに後方互換性があります。
あるサービスが外に提供する API は、そのインターフェイスの後方互換性を保つことが基本的に求められます。
インターフェイスに頻繁に互換性のない変更が加わるなら、そこに依存したクライアントは常に即時対応を迫られてしまうでしょう。その一方で、インターフェイスの互換性担保が枷となって内部の実装が変更できないとなるとサービス自体の成長に影響が出てしまいます。
可能な限り互換性を保ち、時にはバージョニングによる分岐や破壊的な変更を加えてインターフェイス自体と内部の実装との成長が求められます。
では、データベースのテーブルをインターフェイスとした場合にこの成長をどのように実現できるでしょうか?
初期のインターフェイス
誰もが自由に記事を書くようなブログサービスを題材に考えていきましょう。
このブログサービスにはたくさんのユーザーが登録して活発に記事を書いており、そのデータ自体の価値を他のサービスから活かしてもらおうとしています。
記事を表す Post というモデルがあり、記事を特定するユニークな id と記事名 title のフィールドを持つとします。
Web API
Web API で記事一覧を返すとして /posts のエンドポイントで以下のようなレスポンスが返るとします。
[
// post
{
"id": 1, // number
"title": "Title" // string
}
]
この Post はデータベースのテーブル posts にフィールドと同じカラム名で永続化されていることにします。
CREATE TABLE posts (
id SERIAL PRIMARY KEY,
title VARCHAR(255)
);
(この記事ではデータベースに PostgreSQL 15.5 を利用して検証しています。)
ではこのテーブル posts を外部向けインターフェイスとして捉えた場合どうなるでしょう。
テーブル
クライアントとなる他のサービスは、データベースに接続し、次のようにクエリを発行します。
SELECT id, title from posts;
これで posts のデータをクライアントが取得できます。
REST API のクライアントに対して /posts パスと id, title を公開しているのと同じように、クライアントに対してデータベースの posts テーブルとそこに含まれる id, title を公開しています。
さて、ここを出発点として、変更を加えていきたいと思います。
内部実装の変更(テーブル名の変更)
ここで、クライアントに対して posts の id, title として提供した後に、
社内事情により内部的なデータベースのテーブル名とモデル名を tweets および Tweet に変更する必要が出てきたとします。
ALTER TABLE posts
RENAME TO tweets;
Web API
Web API としては /posts エンドポイントそのままとします。
既存のインターフェイスを保つため、処理としては tweets テーブルのレコードを Tweet モデルにマッピングした上で、その中身をレスポンスとして返せば問題ないでしょう。
テーブル
一方で、テーブルを外部向けインターフェイスとしていた場合はテーブル名の変更はエンドポイントの削除のようなものなので、クライアントから急にアクセスできなくなってしまいます。
既存のインターフェイスを保つため、ビューによって posts のままアクセスできるようにしましょう。
CREATE VIEW posts AS
SELECT
id,
title
FROM tweets;
これでクライアントは今までと同じように posts としてデータを利用可能になっています。
クライアントと Web API(/posts)、ビュー(posts)、テーブル(tweets)、モデル(Tweet) の関係をイメージしやすいように一度図にまとめます。
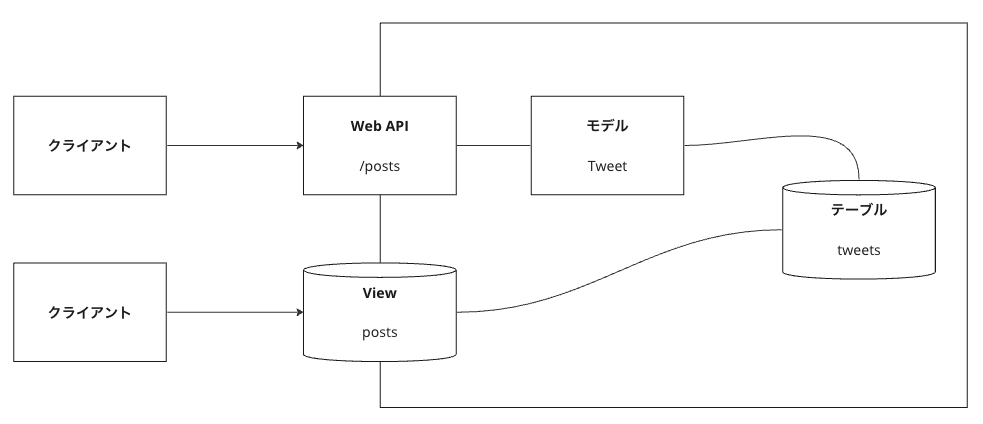
インターフェイスと内部実装の変更(テーブルへのカラム追加)
次に tweets テーブルに人気度(popularity)と優先度(internal_priority) カラムを追加する場合について考えます。
ALTER TABLE tweets
ADD COLUMN popularity INTEGER,
ADD COLUMN internal_priority INTEGER;
そして popularity は公開して良い値であるのに対し、internal_priority に関してはサービス内部でのみ利用する値とします。
Web API
/posts では popularity だけをフィールドとして公開し、 internal_priority フィールドを露出しないようにプレゼンテーションレイヤーで制御します。
テーブル
posts ビューの方でも同じように popularity を公開し、 internal_priority を非公開に保つために、ビューを再作成します。
この時、internal_priority を ビュー作成時の query として含めないことで必要最小限のインターフェイス(カラム)に絞って公開できます。
CREATE OR REPLACE VIEW posts AS
SELECT
id,
title,
popularity
FROM tweets;
実テーブルを公開するのではないビューであることで、元のテーブルに対しての可視性の制御が可能になっています。
内部実装の変更(カラム名の変更)
次に title カラムが name カラムへと名前の変更が必要になったとします。
ALTER TABLE tweets
RENAME COLUMN title TO name;
Web API
/posts では tweets.name として取得した値をプレゼンテーションレイヤーで title として返すことで後方互換性を保てます。
テーブル
一方で、posts ビューの場合はどうなるでしょうか。
テーブルを外部向けインターフェイスとしているため、カラム名の変更はフィールドの変更と同様でクライアントを壊す破壊的な変更になります。
しかし、ビューを利用している場合は内部的に後方互換を保つように自動的に name AS title としてくれます。便利ですね。
つまり、以下のようなビューへと自動で置き換わります。
-- 実際には実行不要
CREATE OR REPLACE VIEW posts AS
SELECT
id,
name AS title,
popularity,
FROM tweets;
これでクライアントは posts の title という抽象に依存し、その実態は name になる状況を作れ、インターフェイスを保っています。
インターフェイスと内部実装の変更(カラムの削除)
次に popularity カラムが削除されることになったとします。
Web API
/posts が popularity をフィールドとして返しているため、フィールドの自体の削除を行います。これは非互換な変更となります。
エンドポイントの処理から popularity の参照がなくなれば、カラムを削除できるようになります。
テーブル
posts から popularity カラムを削除することになるため、 Web API と同様に非互換な変更になります。
まず、インターフェイスとして popularity を利用させないように、次の通りビューを再作成したいところです。
CREATE OR REPLACE VIEW posts AS
SELECT
id,
name AS title
FROM tweets;
しかしこの処理は予想外に失敗します。
ERROR: cannot drop columns from view
これは PostgreSQL のドキュメントにもしっかりと記載されています。
CREATE OR REPLACE VIEWも同様の働きをしますが、 このコマンドでは、同じ名前のビューが既に存在している場合、そのビューを置き換えます。 新しい問い合わせは、既存のビュー問い合わせが生成する列と同じ列(つまり、同じ順序の同じデータ型の同じ列名)を生成しなければなりません。 しかし、そのリストの最後に列を追加しても構いません。 出力列を生成する計算をまったく異なるものにしても構いません。
https://www.postgresql.jp/document/15/html/sql-createview.html
既存のビューと同じ順序の同じデータ型の同じカラム名を保たないと CREATE OR REPLACE VIEW を利用できません。
さて、ではどうするかですがトランザクションの中で DROP VIEW と CREATE VIEW を実行するのが正攻法です。
BEGIN;
DROP VIEW posts;
CREATE VIEW posts AS
SELECT
id,
name AS title
FROM tweets;
COMMIT;
ビューの再作成によって、クライアントからは popularity にアクセスできなくなりました。
ここで popularity への参照がなくなったため、カラムを削除できます。
ちなみに CREATE OR REPLACE VIEW を利用して順序の変更を行なった場合は、名前の変更として扱われてエラーになります。
ERROR: cannot change name of view column "A" to "B"
また、データ型を変更した場合は次のエラーになります。
ERROR: cannot change data type of view column "title" from character varying(255) to boolean
ところで、カラム名の変更の際にはビュー側は自動でその変更に追随してくれました。
先に実テーブルのカラムである tweets.popularity を変更した場合はどうなるのかやってみましょう。
ALTER TABLE tweets
DROP COLUMN popularity;
ERROR: cannot drop column popularity of table tweets because other objects depend on it
DETAIL: view posts depends on column popularity of table tweets
HINT: Use DROP ... CASCADE to drop the dependent objects too.
posts が popularity カラムに依存しているために削除できませんでした。
なお CASCADE パラメータを付与した場合、ビューごと消えてしまうため今回の用途には適しません。
インターフェイスの変更(物理データと異なる表現のフィールドの追加)
記事をアーカイブする機能のために archived_at カラムを追加したときのことを考えます。
ALTER TABLE tweets
ADD COLUMN archived_at TIMESTAMP;
Web API
/posts としてはアーカイブ済みかどうかの真偽値をクライアントに提供したいとします。この場合、今までと同じように archived_at に値がセットされている場合のみ true となる archived フィールドをプレゼンテーションレイヤーで追加することで実現できます。
テーブル
これを posts ビューで実現する際には以下のようにビューを再作成します。
CREATE OR REPLACE VIEW posts AS
SELECT
id,
name AS title,
archived_at IS NOT NULL AS archived
FROM tweets;
以下のように検索もシンプルに実現可能です。
SELECT * FROM posts where archived = true;
REST API での /posts?archived=true と似たような形ですね。
インターフェイスの変更(別のモデルから計算されるフィールドの追加)
ユーザーが有益だと思った投稿への賛辞、後で見返したい投稿の保存、知人の投稿に対しての社交として、その他様々な意味を持つ統合的な概念「いいね」の機能が追加されたとします。そして記事に対しての「いいね」の数を like_count として公開する場合のことを考えます。
テーブルとしては tweets.id と関連を持つ likes が実態だとします。
CREATE TABLE likes (
id SERIAL PRIMARY KEY,
tweet_id INTEGER NOT NULL,
FOREIGN KEY (tweet_id) REFERENCES tweets(id)
);
Web API
/posts では Tweet モデルの id を tweet_id として持つ likes の数を like_count としてフィールドを追加して実現します。
テーブル
今までと同じようにこれを posts ビューで再現するため、ビューを再作成します。
CREATE OR REPLACE VIEW posts AS
SELECT
t.id,
t.name AS title,
t.archived_at IS NOT NULL AS archived,
COALESCE(l.like_count, 0) AS like_count
FROM tweets t
LEFT JOIN (
SELECT
tweet_id,
COUNT(*) AS like_count
FROM likes
GROUP BY tweet_id
) l ON t.id = l.tweet_id;
もしビューではなく実テーブルをクライアントと共有していた場合、クライアントは like_count のために、クライアント側は知る必要のない likes テーブルの id カラムや likes.tweet_id が tweets.id を指すといったクエリのための知識を必要とし、またそこに依存することになります。
ビューによってクライアントに優しいインターフェイスを提供し、そこにビューを組み立てるクエリという実装が依存した形になっています。
まとめ
データベースのテーブルをインターフェイスとして外部提供した際の、インターフェイスと内部実装の成長を実現するいくつかの方法を挙げて整理しました。
物理データとモデルでの意味が一致しているものは特に大きな問題は無く利用できそうです。
また、ビューの再作成に考慮が必要な場合があるものの、ほぼ Web API と似た考え方で後方互換性を保った変更ができそうだと感じました。
とはいえ利用には考慮すべき事柄も多くあるように思えます。
archived_at を archived へと変換したように、物理データを意味づけする変換処理がシステム上でモデルとデータベースのビューとの2箇所に分散させた場合、どちらかの扱い方が変わった際に追随できていないければ思わぬ不整合を呼び込んでしまいそうです。この点に関しては、ビューから取得した値とモデルを経由した値とが一致するよう変換処理をテストすれば担保できそうです。
また、意図せずパフォーマンスの悪いクエリが発行されてしまうリスクもあるでしょう。
今回の例では読み込みのみでしたが、書き込みも許容する場合にはまた異なる考慮点が生まれそうです。
これらに加え、初めに書いたような共有データベースとしての課題もあります。
どこまでのリスクであれば許容できるのか、課題やその取り巻く環境に合わせて判断が必要ですね。
今回の話題は Sam Newman. 「モノリスからマイクロサービスへ」で紹介されているパターンの一つをインターフェイス内外の成長の観点で深ぼったものです。書籍内では共有データベースの使いどころや今回紹介したようなビューを使う話、そしてビューよりも柔軟だがコストのかかるアーキテクチャが紹介されています。興味を持った方は読んでみることをお勧めします。
技術選定における選択肢の一つとして道具箱の隅にしまっていただければ幸いです。
Discussion