⛄
【23日目】類似度を計算してみる【2021アドベントカレンダー】

2021年1人アドベントカレンダー(機械学習)、23日目の記事になります。
テーマは 類似度の計算 になります。
前回に続き、回帰による予測 からは脱線して、データセットからできることを試してみます。
Colab のコードはこちら ![]()
サンプルデータの抽出
データセットから2行ほどサンプルデータを抽出します。
a_b = df_tf.sample(
n = 2,
random_state=SEED
)
a = a_b.iloc[0:1]
b = a_b.iloc[1:]
display(a)
display(b)

コサイン類似度
コサイン類似度とは、2つのベクトルがなす角のコサイン値のこと。
詳しくは下記サイトを参照。
cosine_similarity(a, b)[0][0]
出力:
0.46408305161820873
ジャッカード係数
ジャッカード係数は2つの集合に含まれている要素のうち、共通要素が占める割合である。
詳しくは以下サイト参照。
jaccard(a, b)
出力:
0.8571428571428571
a と b の位置関係を、次元削減後の分布の中で見てみると、以下のようになりました。
sparse = 5
model = TSNE(
n_components=2,
perplexity=5,
random_state=SEED
)
feature_all = model.fit_transform(df_tf)
plt.scatter(feature_all[:, 0], feature_all[:, 1], alpha=0.8, color="blue")
plt.scatter(feature_all[a.index[0], 0], feature_all[a.index[0], 1], alpha=0.8, color="white") # a
plt.text(feature_all[a.index[0], 0]+sparse, feature_all[a.index[0], 1]+sparse, "a", color="white")
plt.scatter(feature_all[b.index[0], 0], feature_all[b.index[0], 1], alpha=0.8, color="white") # b
plt.text(feature_all[b.index[0], 0] + sparse, feature_all[b.index[0] + sparse, 1], "b", color="white")

雑なレコメンド
類似度を使った、雑なレコメンドをやってみます。
51個サンプルデータを抽出し、1つのデータに対し、残りの50個のデータの類似度を計算し、一番類似度が高いデータを抽出してみます。
group = df_tf.sample(
n = 51,
random_state=SEED
)
target = group.iloc[0:1]
group = group.iloc[1:]
コサイン類似度 による抽出は以下のとおり。
best_similarity_score = 0
num_of_best_best_similarity = ""
for i in tqdm(range(len(group))):
one_of_group = group.iloc[i:i+1]
score = cosine_similarity(target, one_of_group)[0][0]
if best_similarity_score < score:
best_similarity_score = score
num_of_best_best_similarity = i
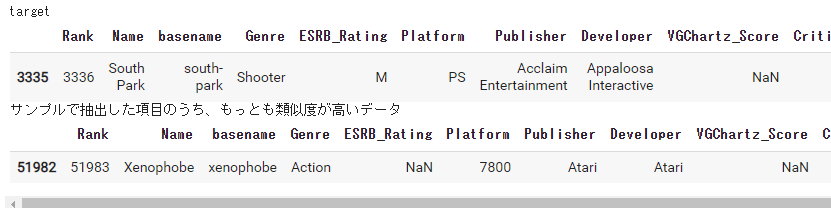
print(best_similarity_score)
print("target")
display(df.iloc[target.index])
print("サンプルで抽出した項目のうち、もっとも類似度が高いデータ")
display(df.iloc[group.iloc[num_of_best_best_similarity:num_of_best_best_similarity+1].index])
出力:
0.9994433230982763
ジャッカード係数による抽出は以下のとおり。
best_similarity_score = 0
num_of_best_best_similarity = ""
for i in tqdm(range(len(group))):
one_of_group = group.iloc[i:i+1]
score = jaccard(target, one_of_group)
if best_similarity_score < score:
best_similarity_score = score
num_of_best_best_similarity = i
print(best_similarity_score)
print("target")
display(df.iloc[target.index])
print("サンプルで抽出した項目のうち、もっとも類似度が高いデータ")
display(df.iloc[group.iloc[num_of_best_best_similarity:num_of_best_best_similarity+1].index])
出力:
0.9047619047619048

23日目は以上になります、最後までお読みいただきありがとうございました。
Discussion