【8日目】クロスバリデーションをやってみる【2021アドベントカレンダー】

2021年1人アドベントカレンダー(機械学習)、8日目の記事になります。
テーマは クロスバリデーション になります。
ざっくりとした理解ですが、特にデータが少ない場合、汎化性能(未知のテストデータに対する識別能力)を保つために学習データとテストデータの分け方を工夫する手法かなと思います。
Wikipedia では、
- 統計学において標本データを分割し、その一部をまず解析して、残る部分でその解析のテストを行い、解析自身の妥当性の検証・確認に当てる手法
- データの解析(および導出された推定・統計的予測)がどれだけ本当に母集団に対処できるかを良い近似で検証・確認するための手法
とあります。
本ブログでは cross_validate、KFold、GroupKFold、TimeSeriesSplit を扱っています。
Colab のコードはこちら ![]()
cross_validate
ライブラリの cross_validate を使うとシンプルにクロスバリデーションのコードを組むことができます。
下記コードでは cv に数値を入れているので KFold でクロスバリデーションされますが、他のクロスバリデーションのインスタンスを設定することも可能です。
from sklearn.model_selection import cross_validate
# 学習、推論
params = {
'boosting_type': 'gbdt', # GBDTを指定
'objective': 'regression', # 回帰を指定
'learning_rate': 0.1, # 学習率
'seed': SEED # シード値
}
model = lgb.LGBMRegressor(
**params, # ハイパーパラメータをセット
)
cv_results = cross_validate(
estimator = model,
X = X_train_ce,
y = y_train,
scoring="neg_root_mean_squared_error",
return_train_score=True,
return_estimator=True,
cv=5
)
print(cv_results["test_score"]*-1)
print(cv_results["test_score"].mean()*-1)
出力:
[0.13769191 0.194626 0.14601733 0.12854627 0.34482036]
0.19034037555062389
KFold
KFold とは、訓練データセットを k 個のサブセットに分割して、そのうち k - 1 個のサブセットで学習し、残りの 1 個のサブセットで検証するという作業をすべての組み合わせに対して行う検証方法。
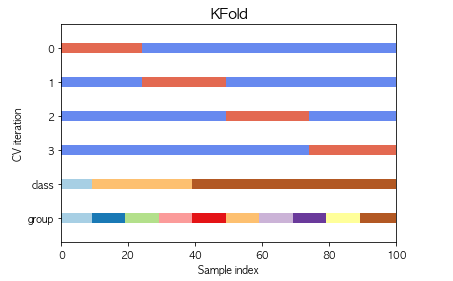
from sklearn.model_selection import KFold
kf = KFold(n_splits=5)
y_train = y_train.reset_index(drop=True)
params = {
'task': 'train', # タスクを訓練に設定
'boosting_type': 'gbdt', # GBDTを指定
'objective': 'regression', # 回帰を指定
'metric': {'rmse'}, # 回帰の損失(誤差)
'learning_rate': 0.1, # 学習率
'seed': SEED # シード値
}
cv_result_kf = []
for fold , (train_index, test_index) in enumerate(kf.split(X_train_ce)):
X_train_kf, X_test_kf = X_train_ce.iloc[train_index], X_train_ce.iloc[test_index]
y_train_kf, y_test_kf = y_train.iloc[train_index], y_train.iloc[test_index]
# 学習、推論
lgb_train = lgb.Dataset(X_train_kf, y_train_kf)
lgb_test = lgb.Dataset(X_test_kf, y_test_kf, reference=lgb_train)
lgb_results = {} # 学習の履歴を入れる入物
model = lgb.train(
params=params, # ハイパーパラメータをセット
train_set=lgb_train, # 訓練データを訓練用にセット
valid_sets=[lgb_train, lgb_test], # 訓練データとテストデータをセット
valid_names=['Train', 'Test'], # データセットの名前をそれぞれ設定
num_boost_round=100, # 計算回数
early_stopping_rounds=50, # アーリーストッピング設定
evals_result=lgb_results,
verbose_eval=-1, # ログを最後の1つだけ表示
)
# 損失推移を表示
loss_train = lgb_results['Train']['rmse']
loss_test = lgb_results['Test']['rmse']
fig = plt.figure()
plt.xlabel('Iteration')
plt.ylabel('logloss')
plt.title(f"fold:{fold}")
plt.plot(loss_train, label='train loss')
plt.plot(loss_test, label='test loss')
plt.legend()
plt.show()
# 推論
y_pred = model.predict(X_test_kf)
# 評価
rmse = mean_squared_error(y_test_kf, y_pred, squared=False)
cv_result_kf.append(rmse)
print("RMSE:", cv_result_kf)
print("RMSE:", np.mean(cv_result_kf))
RMSE: [0.16398461099992923, 0.21202615379568318, 0.22711279960179856, 0.19929656830878598, 0.19227936502624798]
RMSE: 0.198939899546489
GroupKFold
GroupKFold は、同じグループがテストセットとトレーニングセットの両方に現れないようにする手法。
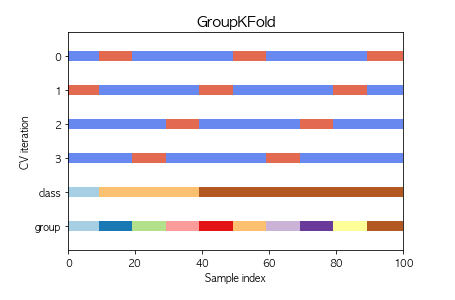
from sklearn.model_selection import GroupKFold
下記コードでは groups = X_train_ce["Genre"] で、ジャンルをGroupにしています。
y_train = y_train.reset_index(drop=True)
gkf = GroupKFold(n_splits=5)
groups = X_train_ce["Genre"]
params = {
'task': 'train', # タスクを訓練に設定
'boosting_type': 'gbdt', # GBDTを指定
'objective': 'regression', # 回帰を指定
'metric': {'rmse'}, # 回帰の損失(誤差)
'learning_rate': 0.1, # 学習率
'seed': SEED # シード値
}
cv_result_gkf = []
for fold, (train_index, test_index) in enumerate(gkf.split(X_train_ce, y_train, groups)):
X_train_gkf, X_test_gkf = X_train_ce.iloc[train_index], X_train_ce.iloc[test_index]
y_train_gkf, y_test_gkf = y_train.iloc[train_index], y_train.iloc[test_index]
# 学習、推論
lgb_train = lgb.Dataset(X_train_gkf, y_train_gkf)
lgb_test = lgb.Dataset(X_test_gkf, y_test_gkf, reference=lgb_train)
lgb_results = {} # 学習の履歴を入れる入物
model = lgb.train(
params=params, # ハイパーパラメータをセット
train_set=lgb_train, # 訓練データを訓練用にセット
valid_sets=[lgb_train, lgb_test], # 訓練データとテストデータをセット
valid_names=['Train', 'Test'], # データセットの名前をそれぞれ設定
num_boost_round=100, # 計算回数
early_stopping_rounds=50, # アーリーストッピング設定
evals_result=lgb_results,
verbose_eval=-1, # ログを最後の1つだけ表示
)
# 損失推移を表示
loss_train = lgb_results['Train']['rmse']
loss_test = lgb_results['Test']['rmse']
fig = plt.figure()
plt.title(f"fold:{fold}")
plt.xlabel('Iteration')
plt.ylabel('logloss')
plt.plot(loss_train, label='train loss')
plt.plot(loss_test, label='test loss')
plt.legend()
plt.show()
# 推論
y_pred = model.predict(X_test_gkf)
# 評価
rmse = mean_squared_error(y_test_gkf, y_pred, squared=False)
cv_result_gkf.append(rmse)
print("RMSE:", cv_result_gkf)
print("RMSE:", np.mean(cv_result_gkf))
TimeSeriesSplit
TimeSeriesSplit は 時系列データ向けであり、未来のデータを学習して過去のデータを予測すること(リーク)が発生しないように交差検証を実施する手法。
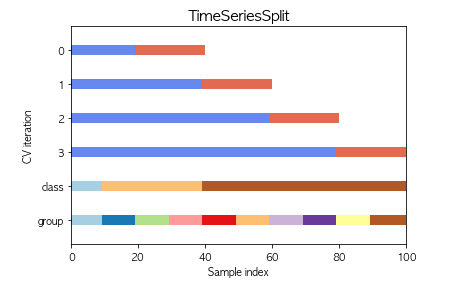
データの並びが時系列になっていることを前提にしているのがネックである。
from sklearn.model_selection import TimeSeriesSplit
# Yearで並び替え、ただしYearの欠損値は削除
X_train, X_test, y_train, y_test = train_test_split(
df.dropna(subset=["Year"], how='any', axis=0).sort_values("Year").dropna(subset=["Global_Sales"]).drop(["Global_Sales", "NA_Sales", "PAL_Sales", "JP_Sales", "Other_Sales"], axis=1),
df.dropna(subset=["Year"], how='any', axis=0).sort_values("Year").dropna(subset=["Global_Sales"])["Global_Sales"],
test_size=0.3,
shuffle=False,
random_state=SEED
)
カテゴリーエンコーディング、正規化の処理は割愛、詳細は Colab 参照
y_train = y_train.reset_index(drop=True)
tscv = TimeSeriesSplit()
params = {
'task': 'train', # タスクを訓練に設定
'boosting_type': 'gbdt', # GBDTを指定
'objective': 'regression', # 回帰を指定
'metric': {'rmse'}, # 回帰の損失(誤差)
'learning_rate': 0.1, # 学習率
'seed': SEED # シード値
}
cv_result_tscv = []
for fold, (train_index, test_index) in enumerate(tscv.split(X_train_ce)):
X_train_tscv, X_test_tscv = X_train_ce.iloc[train_index], X_train_ce.iloc[test_index]
y_train_tscv, y_test_tscv = y_train.iloc[train_index], y_train.iloc[test_index]
# 学習、推論
lgb_train = lgb.Dataset(X_train_tscv, y_train_tscv)
lgb_test = lgb.Dataset(X_test_tscv, y_test_tscv, reference=lgb_train)
lgb_results = {} # 学習の履歴を入れる入物
model = lgb.train(
params=params, # ハイパーパラメータをセット
train_set=lgb_train, # 訓練データを訓練用にセット
valid_sets=[lgb_train, lgb_test], # 訓練データとテストデータをセット
valid_names=['Train', 'Test'], # データセットの名前をそれぞれ設定
num_boost_round=100, # 計算回数
early_stopping_rounds=50, # アーリーストッピング設定
evals_result=lgb_results,
verbose_eval=-1, # ログを最後の1つだけ表示
)
# 損失推移を表示
loss_train = lgb_results['Train']['rmse']
loss_test = lgb_results['Test']['rmse']
fig = plt.figure()
plt.xlabel('Iteration')
plt.ylabel('logloss')
plt.title(f"fold:{fold}")
plt.plot(loss_train, label='train loss')
plt.plot(loss_test, label='test loss')
plt.legend()
plt.show()
# 推論
y_pred = model.predict(X_test_tscv)
# 評価
rmse = mean_squared_error(y_test_tscv, y_pred, squared=False)
cv_result_tscv.append(rmse)
print("RMSE:", cv_result_tscv)
print("RMSE:", np.mean(cv_result_tscv))
RMSE: [0.31756989358571397, 0.09208190098818901, 0.08884351917329887, 0.10281805025349675, 0.35985409955823405]
RMSE: 0.19223349271178652
8日目は以上になります、最後までお読みいただきありがとうございました。
Discussion