📈
【3日目】LightGBMでシンプルな回帰をやる【2021アドベントカレンダー】

2021年1人アドベントカレンダー(機械学習)、3日目の記事になります。
テーマは lightGBM によるシンプルな回帰 になります。
lightGBM の便利さは以下記事をご参照ください。
扱うデータがゲームの販売本数なので回帰を扱います。
Colab のコードはこちら ![]()
SEED = 42
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
df.dropna(subset=["Global_Sales"]).drop(["Global_Sales", "NA_Sales", "PAL_Sales", "JP_Sales", "Other_Sales"], axis=1).select_dtypes(include="number"),
df.dropna(subset=["Global_Sales"])["Global_Sales"],
test_size=0.3,
shuffle=True,
random_state=SEED
)
LGBMRegressor
scikit-learn のようにシンプルに モデルのインスタンスの宣言、fit、predict で扱えるのが LGBMRegressor です。
import lightgbm as lgb
学習
model = lgb.LGBMRegressor(
random_state = SEED,
)
model.fit(
X_train,
y_train,
eval_set=[(X_test, y_test), (X_train, y_train)],
verbose=-1 # 学習ログを省略
)
# 学習履歴の表示
lgb.plot_metric(model)

推論(以降同じ)
model.predict(X_test)
lightGBM
データセットの定義等の設定が必要になりますが、より詳細な定義が可能なのがこちらです。
# データセットを登録
lgb_train = lgb.Dataset(X_train, y_train)
lgb_test = lgb.Dataset(X_test, y_test, reference=lgb_train)
パラメーター
params = {
'task': 'train', # タスクを訓練に設定
'boosting_type': 'gbdt', # GBDTを指定
'objective': 'regression', # 回帰を指定
'metric': 'rmse', # 回帰の評価関数
'learning_rate': 0.1, # 学習率
}
学習
lgb_results = {} # 学習の履歴を入れる入物
model = lgb.train(
params=params, # ハイパーパラメータをセット
train_set=lgb_train, # 訓練データを訓練用にセット
valid_sets=[lgb_train, lgb_test], # 訓練データとテストデータをセット
valid_names=['Train', 'Test'], # データセットの名前をそれぞれ設定
num_boost_round=100, # 計算回数
early_stopping_rounds=50, # アーリーストッピング設定
evals_result=lgb_results, # 学習の履歴を保存
verbose_eval=-1 # ログを最後の1つだけ表示
)
学習履歴の表示
evals_result に辞書型データを設定することで、学習履歴(メトリクスによる評価結果の推移)を確認することができます。
loss_train = lgb_results['Train']['rmse']
loss_test = lgb_results['Test']['rmse']
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.set_xlabel('Iteration')
ax1.set_ylabel('logloss')
ax1.plot(loss_train, label='train loss')
ax1.plot(loss_test, label='test loss')
plt.legend()
plt.show()
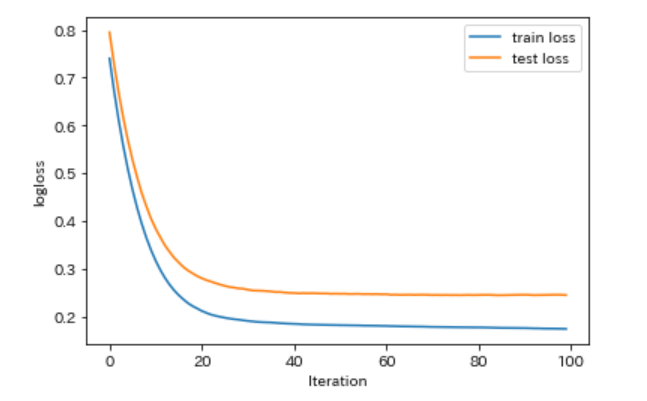
オリジナルの評価関数(カスタムメトリクス)
引数を設定することで基本的な評価関数(rmse, auc等)を設定することは可能ですが、独自の評価関数を設定することも可能です。
その場合は、パラメーターで "None" (文字列。予約語の None ではない点に注意。) を設定しましょう。
params = {
'task': 'train', # タスクを訓練に設定
'boosting_type': 'gbdt', # GBDTを指定
'objective': 'regression', # 回帰を指定
'metric': "None", # 回帰の評価関数に None を指定
'learning_rate': 0.1, # 学習率
}
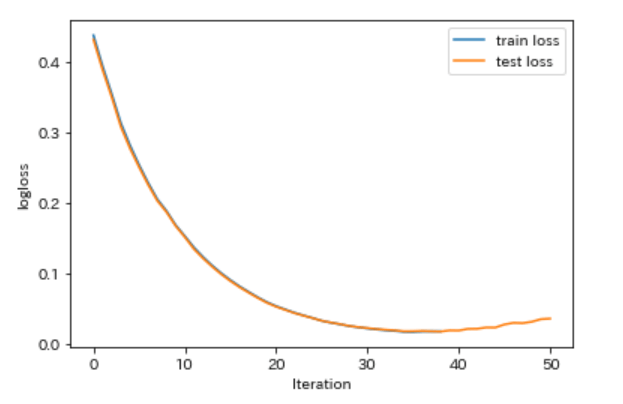
オリジナルの評価関数の作成
なんでもいいのですが、今回は RMSPE を扱ってみます。
返り値の3番目の bool 値は、この評価関数は数値が大きい方が精度がよい(True)のか、小さい方が精度がよい(False)のか、という設定になります。
is_higher_betterbool
Is eval result higher better, e.g. AUC is is_higher_better.
RMSPE は誤差であり小さい方が精度がよくなりますので、False とします。
def custom_metrics(y_pred, data):
y_true = data.get_label() # lgb.Dataset() から 目的変数を取得
score = np.mean( np.sqrt( (y_true - y_pred) / y_true) ** 2 ) # 評価結果を算定。平均処理を行う
return 'custom_metrics', score, False
lgb_results = {} # 学習の履歴を入れる入物
model = lgb.train(
params=params, # ハイパーパラメータをセット
train_set=lgb_train, # 訓練データを訓練用にセット
valid_sets=[lgb_train, lgb_test], # 訓練データとテストデータをセット
valid_names=['Train', 'Test'], # データセットの名前をそれぞれ設定
num_boost_round=100, # 計算回数
early_stopping_rounds=50, # アーリーストッピング設定
evals_result=lgb_results, # 学習の履歴を保存
verbose_eval=-1, # ログを最後の1つだけ表示
feval=custom_metrics,
)
3日目は以上になります、最後までお読みいただきありがとうございました。
Discussion