【2日目】色んなEDAを試してみる【2021アドベントカレンダー】

2021年1人アドベントカレンダー(機械学習)、2日目の記事になります。
テーマは EDA になります。
EDA は探索的データ分析 (Explanatory Data Analysis)のことです。
(自分は全然出来てないのですが...)機械学習は基本データの特徴を捉えて模倣する技術、ととらえると、そもそもデータがどんな特徴を持っているのか、どんな分布になっているのかが重要です。
生データを眺めていても全体感がわかりませんし、巨大なデータを眺めようものなら時間がいくらあっても足りません。
ここは便利なライブラリを活用したいところです。
Colab のコードはこちら ![]()
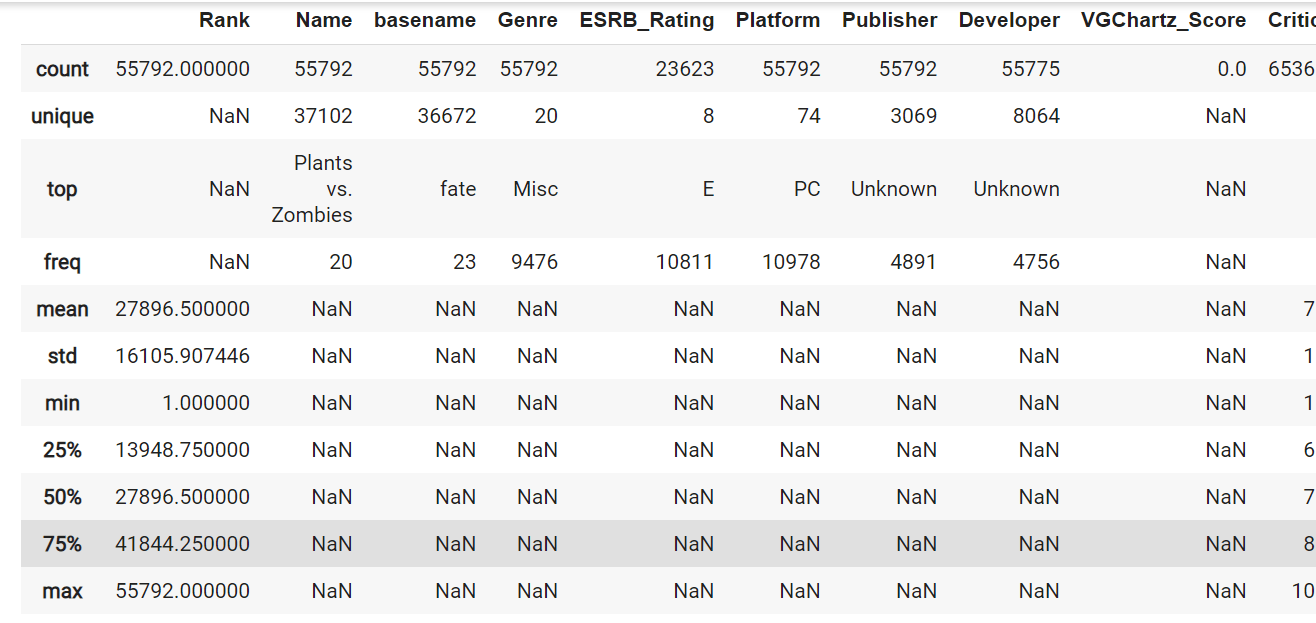
describe
Pandas であれば、describe() を使うことで数値データであれば平均値や最大値、最小値、四分位範囲を確認することができます。
四分位範囲とは、データのちらばり具合を求めるもので、第1四分位数から第3四分位数までの範囲(データの中央50%部分の範囲)のことを指します。
引数に include="all" を指定すればカテゴリーデータであってもユニーク数や最頻値を確認することができます。
df.describe(include='all')
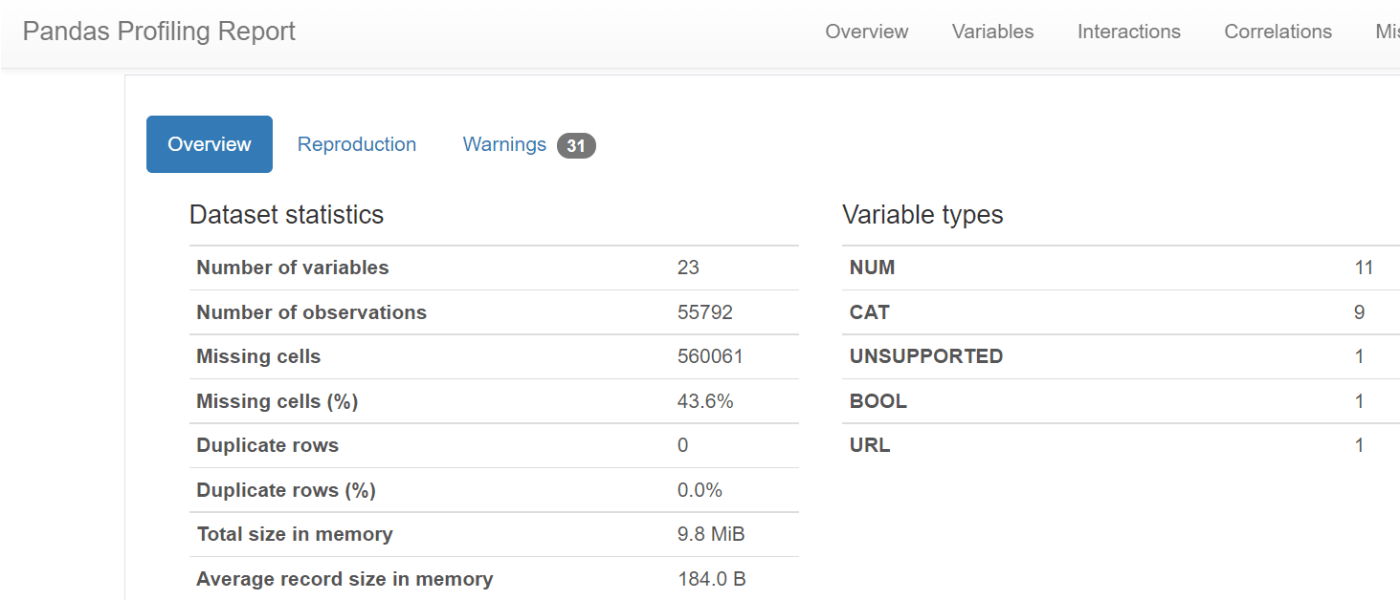
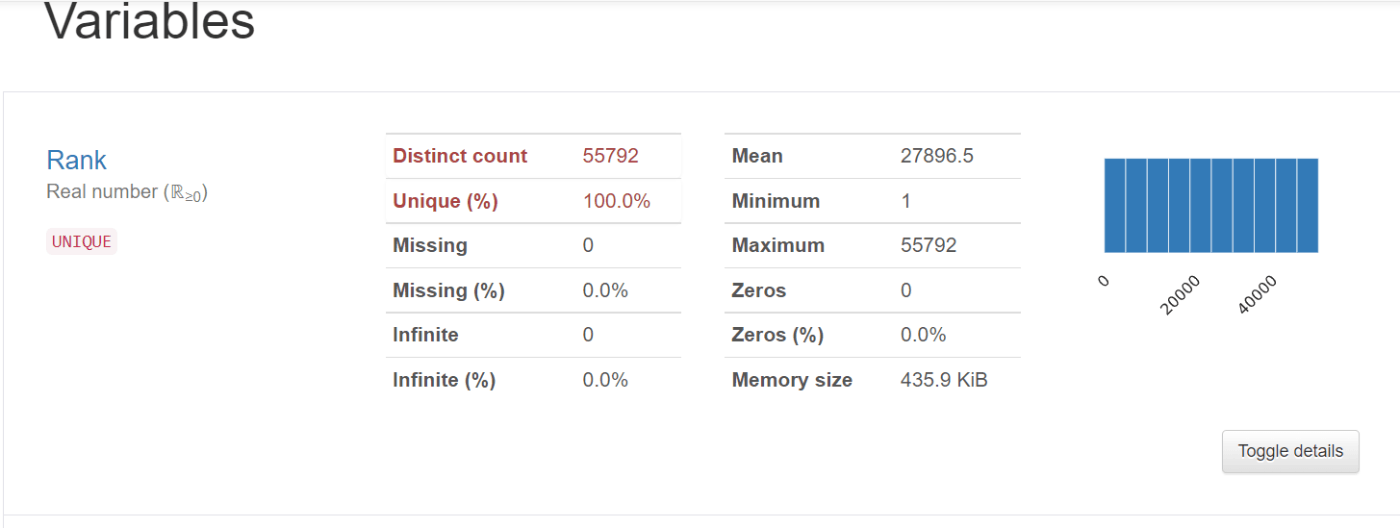
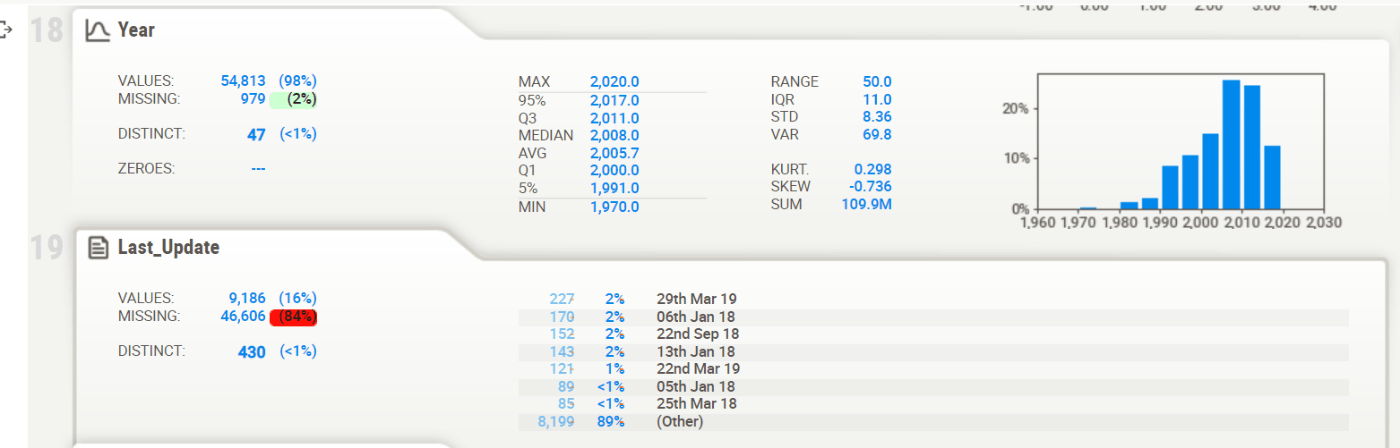
Pandas-Profile
Pandas-Profile を使うと、describe() よりも高度なEDAを簡単に表示することができます。
from pandas_profiling import ProfileReport
profile = ProfileReport(df, title="Pandas Profiling Report")
profile.to_notebook_iframe()
Sweetviz
Sweetviz も Pandas-Profile と同様、EDAを簡単に表示することができます。
import sweetviz as sv
from IPython.display import HTML
my_report = sv.analyze(df)
my_report.show_html()
HTML("/content/SWEETVIZ_REPORT.html")
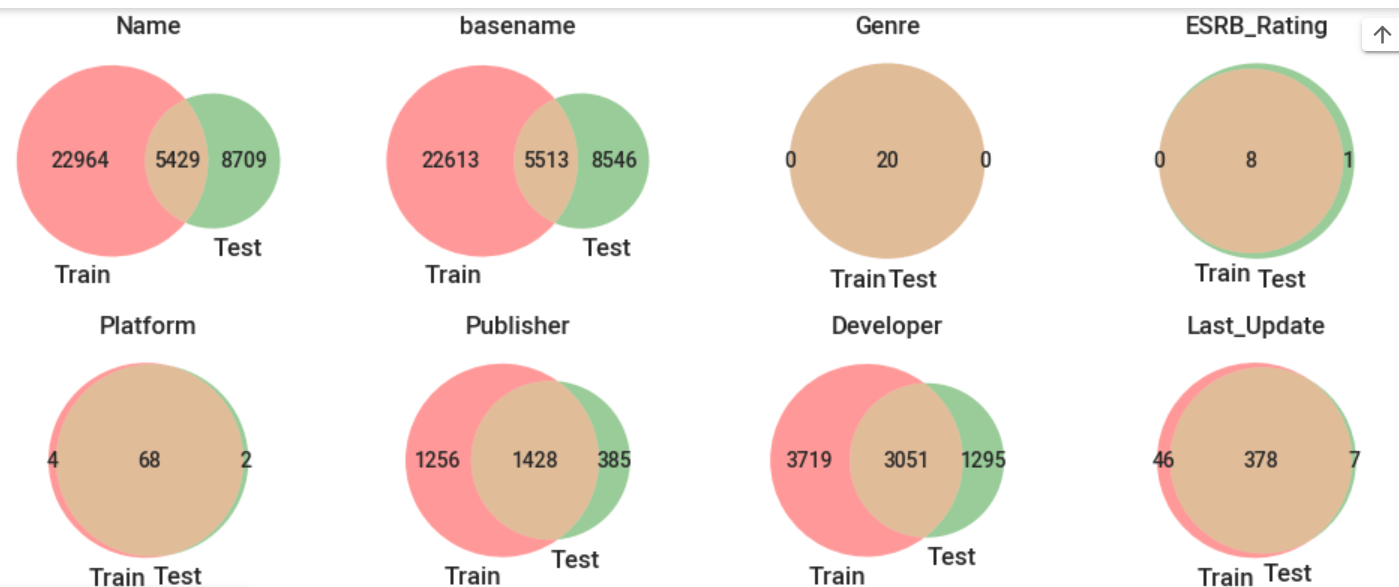
ベン図でカテゴリデータの分布を確認
分割した学習データとテストデータの内容が全く違う場合、いくら学習してもいい予測はできないかもしれないので確認してみましょう。
from matplotlib_venn import venn2
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size=0.3, random_state=42)
plt.figure(figsize=(10, 20))
for i, column in enumerate(df.select_dtypes(include=object).columns):
plt.subplot(10, 4, i+1)
set1 = set(train[column])
set2 = set(test[column])
plt.title(column)
venn2([set1, set2], ('Train', 'Test'))
plt.tight_layout()
plt.show()
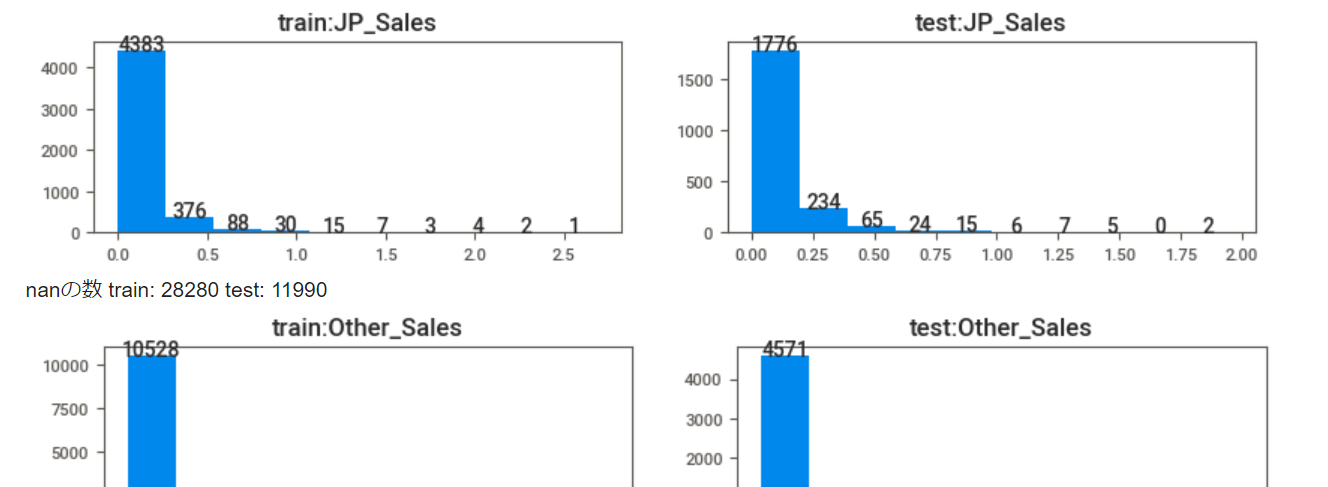
ヒストグラムで数値データの分布を比較
極端な外れ値がないか、数値の分布が予測しやすそうな形状をしているかはたまたカオスかどうか、ざっと確認してみます。
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size=0.3, random_state=42)
for i, column in enumerate(df.select_dtypes(include='number').columns):
print("nanの数 train:", train[column].isnull().sum(), "test:", test[column].isnull().sum())
plt.figure(figsize=(10, 40))
plt.subplot(20, 2, i*2+1)
plt.title("train:" + column)
n, bins, _ = plt.hist(train[column].dropna())
xs = (bins[:-1] + bins[1:])/2
ys = n.astype(int)
for x, y in zip(xs, ys):
plt.text(x, y, str(y), horizontalalignment="center")
plt.subplot(20, 2, i*2+2)
plt.title("test:" + column)
n, bins, _ = plt.hist(test[column].dropna())
xs = (bins[:-1] + bins[1:])/2
ys = n.astype(int)
for x, y in zip(xs, ys):
plt.text(x, y, str(y), horizontalalignment="center")
plt.show()
plt.tight_layout()
相関係数をヒートマップで確認
相関係数とは 2つのデータまたは確率変数の間にある線形な関係の強弱を測る指標になります。
単純に考えれば目的変数と相関のある特徴量を多く学習させれば、いい予測モデルができそうです。
(現実はそんなに甘くないですが...)
import matplotlib.pyplot as plt
import seaborn as sns
sns.heatmap(df.corr(), square=True, annot=True)

PairPlot
seaborn の pairplot() を使うと、各カラム同士の散布を簡単に表示することができます。
import matplotlib
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
plt.figure(figsize=(40, 40))
sns.pairplot(
df,
hue='Genre',
diag_kind = 'kde',
plot_kws = {'alpha': 0.6, 's': 80, 'edgecolor': 'k'},
markers='+',
height = 4
);
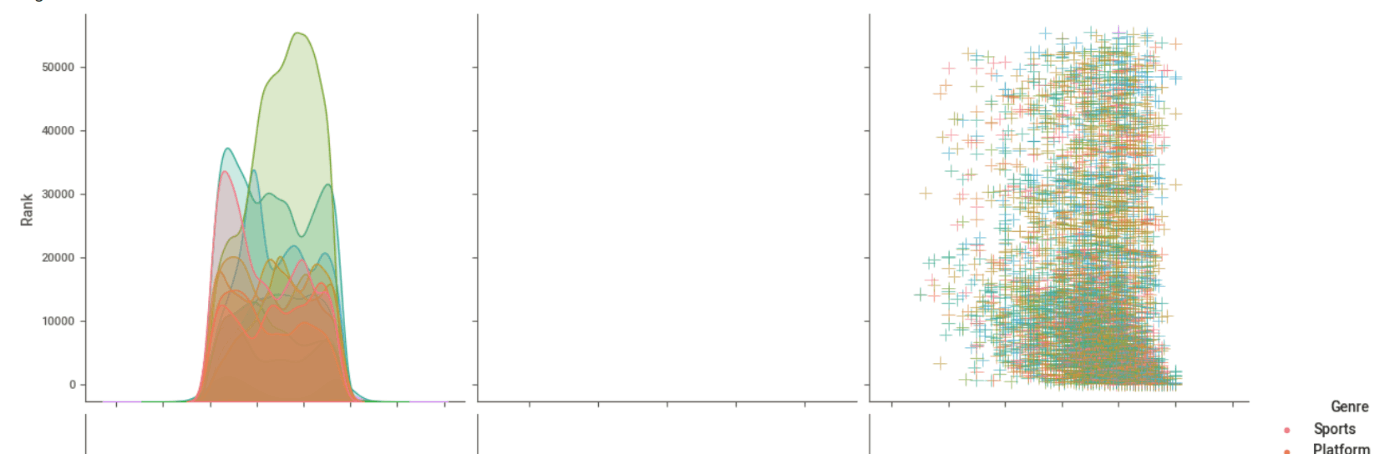
全データをPairPlotすると表が大きすぎるので、カラムも指定できる。
plt.figure(figsize=(40, 40))
sns.pairplot(
df,
hue='Genre',
diag_kind = 'kde',
plot_kws = {'alpha': 0.6, 's': 80, 'edgecolor': 'k'},
vars = ['Rank', 'VGChartz_Score', 'Critic_Score'],
markers='+',
height = 4
);
2日目は以上になります、最後までお読みいただきありがとうございました。
参考書籍
EDAメインではないですが、kaggleをテーマにEDAについても触れられてますし、2021/12/2時点でkindle版は無料です。
Discussion