LiGNAMを使って因果推論を試してみた

Titanic のデータセットを使って LiGNAM で因果推論をやってみたのでまとめます。
ローカル、Windowsで環境構築する場合は、Graphivizのパスが通らなくて因果グラフの表示で苦労しました。
venvでの環境構築が良かったです。
Titanic のデータセットは下記のサイトを使用させていただいています。
Titanic の各カラムの意味は下記サイトをご参照ください。
以下では欠損値処理してカテゴリデータをOrdinalEncodingしたものを使っています。
基本的にはLiGNAMの公式チュートリアルを参照しています。
理論的な説明は下記サイトをご参照ください。
事前学習の設定
各特徴量の因果関係を設定することができます。
特に設定していなくても因果関係を算定、図示することは可能ですが、各特徴量の因果関係を把握している場合は確実に反映されるよう設定する方がよさそうです。
なお、LiGNAM はカラム名ではなくカラムのindex(何番目のカラムか)でしか指定できないようなので、下記の様に index とカラム名の辞書型データを作成し、カラム名を指定すればカラムの index を出力できるようにすると、少なくとも自分はカラムの指定が分かりやすくなりました。
df_list = df_en.drop("PassengerId", axis=1).columns.to_list()
df_dict = {}
for i, column in zip(range(len(df_list)), df_list):
df_dict[column] = i
print(df_dict)
出力:{'Survived': 0, 'Pclass': 1, 'Name': 2, 'Sex': 3, 'Age': 4, 'SibSp': 5, 'Parch': 6, 'Ticket': 7, 'Fare': 8, 'Embarked': 9}
下記引数にてそれぞれ次のような設定が可能です。
-
exogenous_variables 1次元listを渡す。設定した特徴量は必ず因果関係のスタート地点となり、他の特徴量の影響を受けないものとして設定されます。
-
sink_variables 1次元listを渡す。設定した特徴量は必ず因果関係の中継地点、又は終点となり、他の特徴量の影響を受けるとして設定されます。
-
paths 2次元リストを渡す。この特徴量とこの特徴量は必ず因果関係がある、という場合は設定するとよい。すなわち、[[特徴量A, 特徴量B], [特徴量A, 特徴量C]]のように設定すると、特徴量Aと特徴量B、特徴量Aと特徴量Cがそれぞれ因果関係がある、と認識される。
-
no_paths 2次元リストを渡す。この特徴量とこの特徴量は必ず因果関係がない、という場合は設定するとよい。設定し方は sink_variables と同じ。
prior_knowledge = make_prior_knowledge(
10, # 変数の数
# 外因性変数? 1D-list 一覧
exogenous_variables = [df_dict["Sex"], df_dict["Age"]],
# シンク変数? 1D-list 一覧
sink_variables = [df_dict["Survived"]],
# 有向パスを持つ変数 2D-list 組み合わせ
paths = [[df_dict["Survived"], df_dict["Sex"]]],
# 有向パスのない変数 2D-list 組み合わせ
no_paths = [[df_dict["Survived"], df_dict["Embarked"]]],
)
因果推論の学習
# インスタンスを生成して、.fitするだけで簡単に実行できる
model = lingam.DirectLiNGAM(
random_state=42,
prior_knowledge = prior_knowledge
)
model.fit(df_en.drop("PassengerId", axis=1))
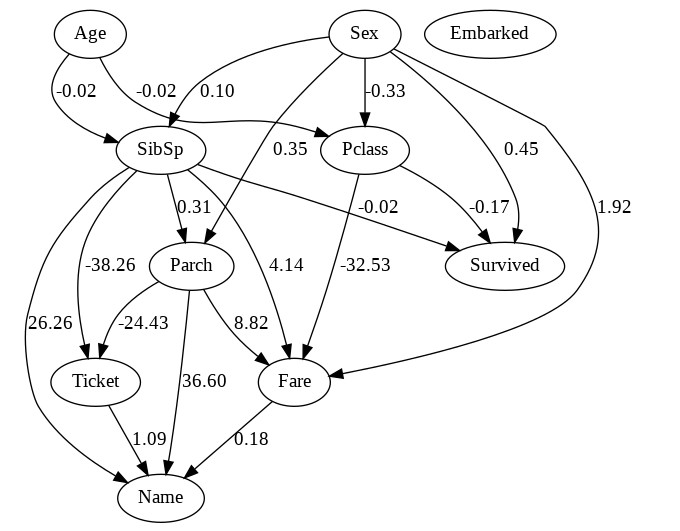
因果グラフの表示
因果グラフを表示させることができます。
これで特徴量の因果関係を可視化することができます。
先ほど事前知識を設定していた場合は、因果グラフに反映されます。
dot = make_dot(
# LiNGAMで推定された因果グラフを表す隣接行列。
# (i,j)成分の中身の値はx_iからx_jへの因果係数b_ijを表す
model.adjacency_matrix_,
labels=df_en.drop("PassengerId", axis=1).columns.to_list(),
)
# 画像を保存
dot.format = 'png'
dot.render('dag')
Image("dag.png")
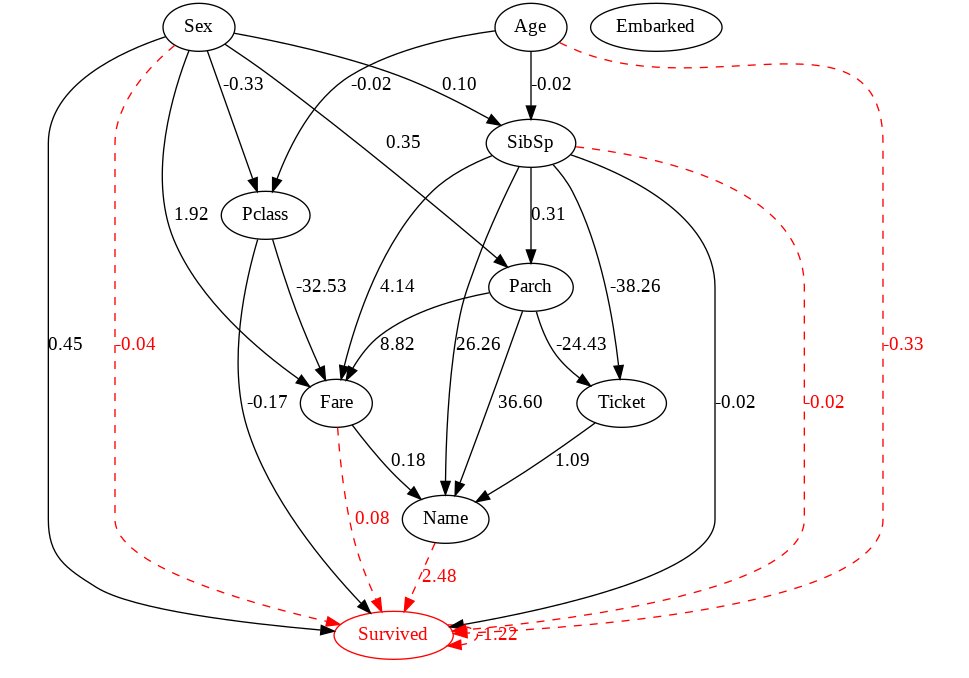
別途機械学習による学習・推論を行っている場合は、その結果を因果グラフに反映させることも可能です。
prediction_feature_indices に目的変数である Survived やそもそも使用しない特徴量 PassengerId 以外の特徴量を渡し、prediction_target_label に目的変数である Survived を渡せばいいです。
また、必須ではないですが ロジスティック回帰のような特徴量ごとの重みを出力出来る場合は、make_dot の引数、prediction_coefs に coef_ を渡すことで因果グラフに特徴量ごとの重みを表示させることが出来ます。
## ロジスティック回帰
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(random_state=42)
clf.fit(df_en.drop(["PassengerId", "Survived"], axis=1), df_en["Survived"])
features = [i for i in range(df_en.drop(["PassengerId", "Survived"], axis=1).shape[1])]
print("features: ", features)
dot = make_dot(
model.adjacency_matrix_,
labels=df_en.drop("PassengerId", axis=1).columns.to_list(),
prediction_feature_indices=features,
prediction_target_label='Survived',
prediction_coefs=clf.coef_[0]
)
# 画像を保存
dot.format = 'png'
dot.render('dag')
Image("dag.png")
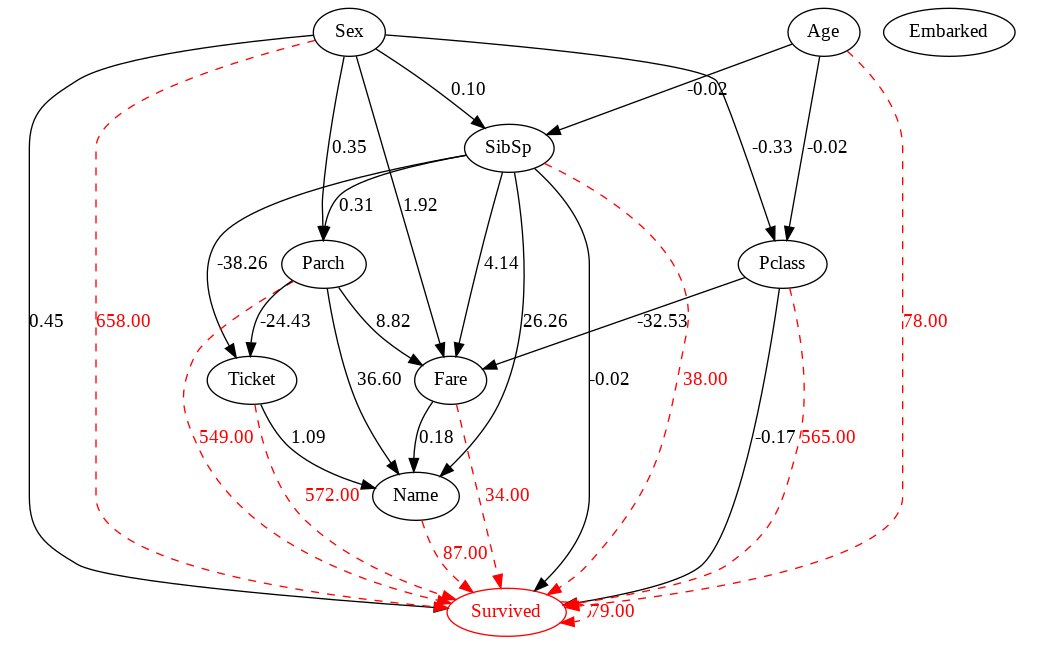
LightGBMのような特徴量の重要性を出力出来る場合は、make_dot の引数、prediction_coefs に feature_importance_ を設定することで因果グラフに特徴量の重要性を表示させることが出来ます。
## lightGBM
import lightgbm as lgb
clf = lgb.LGBMClassifier(random_state=42)
clf.fit(df_en.drop(["PassengerId", "Survived"], axis=1), df_en["Survived"])
dot = make_dot(
(略)
prediction_coefs=clf.feature_importances_
)
予測に最大の因果的影響を与えた特徴量の推定
特徴量の影響度も算定できるようです。
lce = lingam.CausalEffect(model)
effects = lce.estimate_effects_on_prediction(
df_en.drop(["PassengerId"], axis=1),
df.columns.to_list().index("Survived"), # 目的変数のindex
clf
)
df_effects = pd.DataFrame()
df_effects['feature'] = df_en.drop(["PassengerId"], axis=1).columns
df_effects['effect_plus'] = effects[:, 0]
df_effects['effect_minus'] = effects[:, 1]*-1
display(df_effects)
# 予測に最大の因果的影響を与えた特徴量
max_index = np.unravel_index(np.argmax(effects), effects.shape)
print(df_en.drop(["PassengerId"], axis=1).columns[max_index[0]])
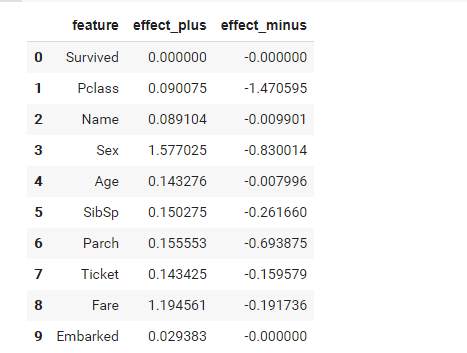
出力:Sex
estimate_total_effect メソッドと多次元配列の場合の argmax 処理 を使って指定した範囲の特徴量の影響度を算定することも可能なようです。
column_x = "SibSp"
column_y = "Pclass"
te = model.estimate_total_effect(
df_en.drop(["PassengerId"], axis=1),
df_dict[column_x], df_dict[column_y]
)
print(
f'{df_dict[column_x]}:{column_x}から{df_dict[column_y]}:\
{column_y}までの 影響度 合計: {te:.3f}'
)
出力:5:SibSpから1:Pclassまでの 影響度 合計: 0.000
以上になります、最後までお読みいただきありがとうございました。
Discussion