画像ファイルや文字列のBinary変換に苦労したのでメモとして残す

バイナリ変換について手こずったのでメモとして残します。
コードはこちら
文字列のバイナリ変換
変換前
text = "いろはにほへとちりぬるを"
バイナリ変換
text_bin = text.encode()
print(text_bin)
出力:
b'\xe3\x81\x84\xe3\x82\x8d\xe3\x81\xaf\xe3\x81\xab\xe3\x81\xbb\xe3\x81\xb8\xe3\x81\xa8\xe3\x81\xa1\xe3\x82\x8a\xe3\x81\xac\xe3\x82\x8b\xe3\x82\x92'
エンコードの確認
from chardet import detect
# encode の確認
print(detect(text_bin))
出力:
{'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
print(text_bin.decode("utf-8"))
出力:
'いろはにほへとちりぬるを'
画像のバイナリ変換
URLから直接画像を読み込む
url = "https://raw.githubusercontent.com/GitHub30/sketch2code-cli/master/samples/sample1.jpg"
response = requests.get(url)
img = Image.open(BytesIO(response.content))
plt.imshow(img)
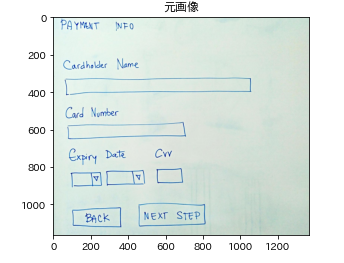
画像ファイルをnumpy の arrayに変換
バイナリデータからarrayに戻す際、型が必要になるので型を確認します
import numpy as np
# numpyのarray化
img_np = np.array(img)
# numpy の型確認
print(img_np.dtype)
出力:
uint8
# バイナリ変換
img_bin = img_np.tobytes()
print(img_bin[:50])
出力:
b'\xe2\xf6\xf4\xe1\xf5\xf3\xe1\xf5\xf3\xe0\xf4\xf2\xe0\xf4\xf2\xe1\xf5\xf3\xe1\xf5\xf3\xe2\xf6\xf4\xe4\xf8\xf6\xe4\xf8\xf6\xe4\xf8\xf6\xe3\xf7\xf5\xe3\xf7\xf5\xe2\xf6\xf4\xe2\xf6\xf4\xe2\xf6\xf4\xe3\xf7'
from chardet import detect
# エンコード確認
print(detect(img_bin))
{'encoding': 'Windows-1251', 'confidence': 0.33348597466870605, 'language': 'Bulgarian'}
np.frombuffer を使って バイナリデータをnumpy array に戻してやります。
この際、型を正しく指定しないと元のデータと違う数値になってしまうので注意です。
また、1次元の平坦な array になってしまうので、reshape で修正してやります。
# バイナリ -> numpy 変換
plt.imshow(np.frombuffer(img_bin, dtype = np.uint8).reshape(img_np.shape))
plt.title("バイナリ->numpy array")
plt.show()

以上になります、最後までお読みいただきありがとうございました。
参考サイト
Discussion