🕐
Pytorch-Forcastを使って複雑な時系列予測をしてみた

Pytorch-Forcasting のチュートリアルを参考に、複数のデータ(商品種類とか)を扱った時系列予測をやってみました。
コードはこちら
なお、データセットは Merlion内にある M4データセットを使用しています。
(ただし負荷軽減のため、一部だけ使用しています。)
学習データとテストデータの分割
便利なライブラリがありそうですが、詳しくないのでテストデータのサイズが約30%になるよう、日付をもとに学習データとテストデータに分割してやります。
threashold = datetime.datetime(1970, 1, 23, 0, 0, 0)
print("test size:", len(data[data["ds"]>=threashold]) / len(data["ds"]))
display(data[data["ds"]>=threashold].head())
display(data[data["ds"]>=threashold].tail())
train = data[data["ds"]<threashold]
test = data[data["ds"]>=threashold]
学習と交差検証
時系列データなので、交差検証は TimeSeriesSplit() を使用しています。
Seriesカラムの番号で種類が区別されていますが、ちゃんと種類ごとに指定の期間を TimeSeriesSplit() で抜けるようにしてやる必要があります。 、
今回使用したデータは、各種類ごとのデータのサイズが同じなので、時間で並び替えて TimeSeriesSplit() を使用しています。
最適な学習率を探索してくれてすごい。
### 交差検証
FOLD = 5
cross_rmse_nbeats = []
train_sort = train.sort_values(["ds", "series"])
tscv = TimeSeriesSplit(n_splits=FOLD, test_size=22*90)
for fold, (train_index, valid_index) in enumerate(tscv.split(train)):
# 学習用データセットの作成
training = TimeSeriesDataSet(
train_sort.iloc[train_index],
time_idx="time_idx",
target="value",
categorical_encoders={"series": NaNLabelEncoder().fit(data.series)},
group_ids=["series"],
# only unknown variable is "value" - and N-Beats can also not take any additional variables
time_varying_unknown_reals=["value"],
)
# 検証用データセットの作成
validation = TimeSeriesDataSet(
train_sort.iloc[valid_index],
time_idx="time_idx",
target="value",
categorical_encoders={"series": NaNLabelEncoder().fit(data.series)},
group_ids=["series"],
time_varying_unknown_reals=["value"],
)
# データローダーの作成
train_dataloader = training.to_dataloader(train=True, batch_size=batch_size, num_workers=2)
val_dataloader = validation.to_dataloader(train=False, batch_size=batch_size, num_workers=2)
# モデル作成
trainer = pl.Trainer(
gpus=gpu_nums,
gradient_clip_val=0.01,
deterministic=True
)
net = NBeats.from_dataset(
training,
learning_rate=LR,
weight_decay=1e-2,
widths=[32, 512],
backcast_loss_ratio=0.1
)
early_stop_callback = EarlyStopping(monitor="val_loss", min_delta=1e-4, patience=10, verbose=False, mode="min")
# ベースラインの学習
trainer = pl.Trainer(
max_epochs=EPOCH,
gpus=gpu_nums,
weights_summary="top",
gradient_clip_val=0.01,
callbacks=[early_stop_callback],
limit_train_batches=30,
deterministic=True
)
net = NBeats.from_dataset(
training,
learning_rate=LR,
log_interval=10,
log_val_interval=1,
weight_decay=1e-2,
widths=[32, 512],
backcast_loss_ratio=1.0,
)
# ベースラインの精度評価
actuals = torch.cat([y[0] for x, y in iter(val_dataloader)])
baseline_predictions = Baseline().predict(val_dataloader)
print(f"baseline absolute error :{SMAPE()(baseline_predictions, actuals)}")
# 最適な学習率の探索
res = trainer.tuner.lr_find(net, train_dataloader=train_dataloader, val_dataloaders=val_dataloader, min_lr=1e-5)
print(f"suggested learning rate: {res.suggestion()}")
fig = res.plot(show=True, suggest=True)
fig.show()
net.hparams.learning_rate = res.suggestion()
# 探索した学習率を踏まえた学習
trainer.fit(
net,
train_dataloader=train_dataloader,
val_dataloaders=val_dataloader,
)
best_model_path = trainer.checkpoint_callback.best_model_path
best_model = NBeats.load_from_checkpoint(best_model_path)
# 検証データを使った予測
test_torch = torch.cat([y[0] for x, y in iter(val_dataloader)])
pred_torch = best_model.predict(val_dataloader)
# 検証データを使った評価
score = np.sqrt(mean_squared_error(test_torch, pred_torch))
print(f"{fold} RMSE {score}")
cross_rmse_nbeats.append(score)
# 交差検証を踏まえた平均精度評価結果
print(f"CROSS_RMSE {np.mean(cross_rmse_nbeats)}")
テストデータを使った予測および精度評価
testing = TimeSeriesDataSet(
test,
time_idx="time_idx",
target="value",
categorical_encoders={"series": NaNLabelEncoder().fit(data.series)},
group_ids=["series"],
time_varying_unknown_reals=["value"],
)
test_dataloader = testing.to_dataloader(train=False, batch_size=batch_size, num_workers=2)
actuals = torch.cat([y[0] for x, y in iter(test_dataloader)])
predictions = best_model.predict(test_dataloader)
print("MAPE", torch.mean(np.abs((actuals - predictions) / actuals)) * 100)
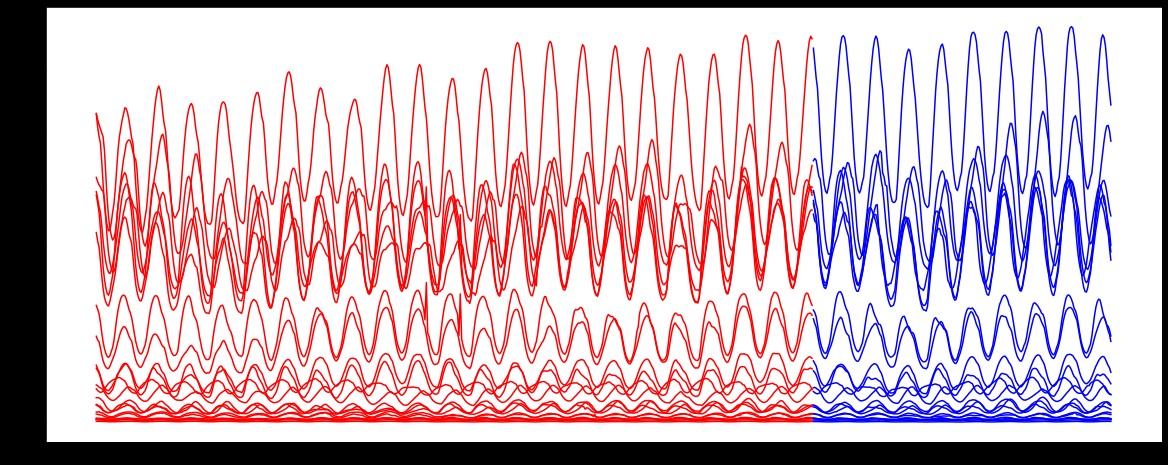
エポック数5回程度ですが、かなりの精度が出ました。
MAPE tensor(1.8761)
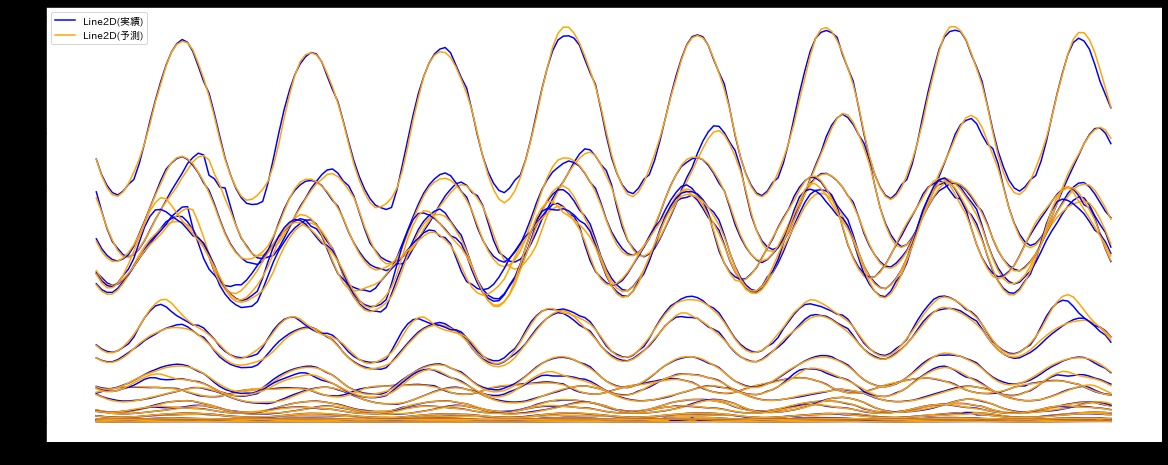
グラフで見ると、時系列の推移をなかなかうまくとらえられているようです。
result_df = pd.DataFrame([
series.reshape(-1).numpy(),
time_idx.reshape(-1).numpy(),
value.reshape(-1).numpy(),
]).T
result_df.columns = ["series" ,"time_idx", "actual"]
result_df[["series" ,"time_idx"]] = result_df[["series" ,"time_idx"]].astype(int)
result_df = pd.merge(result_df, test.drop("value", axis=1), on=["series", "time_idx"], how="left")
result_df = result_df[["ds", "actual", "series", "time_idx", "static"]]
result_df["pred"] = predictions.reshape(-1).numpy()
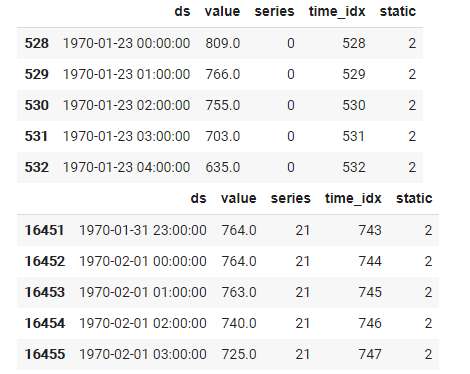
なお、元々のテストデータから各種類ごとに頭の30行ほどデータが抜けてしまうようです。
元々のテストデータ
データローダーから作成した実績値と予測データ
以上になります、最後までお読みいただきありがとうございました。
Discussion