日本語のデータセットを使った自然言語処理でshapを試してみた

自然言語処理の分類問題で解釈性のツールである shap を使ってみたのでまとめます。
結論から言うと DeepExplainer は shap_values の処理が早いが環境構築がむずかしい、 KernelExplainer は比較的環境構築がやりやすいが処理が遅かったです。
DeepExplainer は下記のバージョンを指定することで Colab 上で動いていますが、ローカル環境ですと tensorflow2.2以降しか pip でインストール出来ず詰まってしまいました。
| ライブラリ | バージョン |
|---|---|
| shap | 0.30.1 |
| tensorflow | 1.14.0 |
| tensorflow.keras | 2.2.4-tf |
Colab で実行する際、ライブラリのインストール後、ランタイムから 再起動をしてすべて実行 を選択しないといけない点も留意ください。
そうしないとデータセットの作成 のところでエラーで止まります。
参考にしたコードは下記の kaggle のもので使ってるデータセットは英語 (20_newsgroup) でしたが、日本語のコーパスであるライブドアニュースを使えるようにしました。

Word2Vec で日本語の学習済みモデルをダウンロードし、それを Embedding Matrix に変換して Keras で使用しています。
コードの詳細は本文中では割愛しますので、詳細は下記の Colab をご覧下さい。
(再現可能性について色々試したのですが、両者で学習結果や予測精度にずれがあるのが気がかりですが...)
DeepExplainer
- 特徴量ごとに SHAP Value を可視化
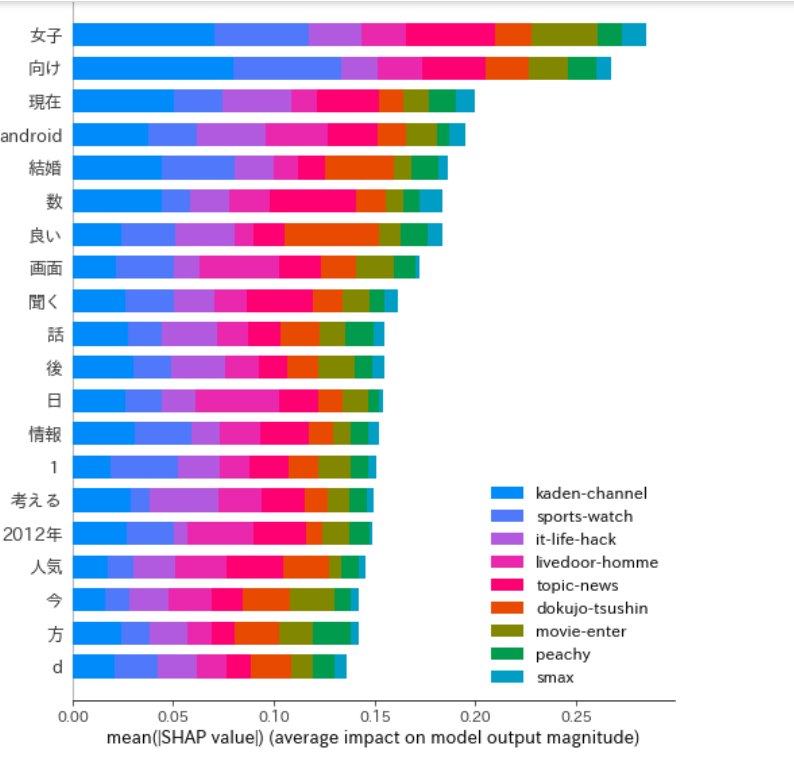
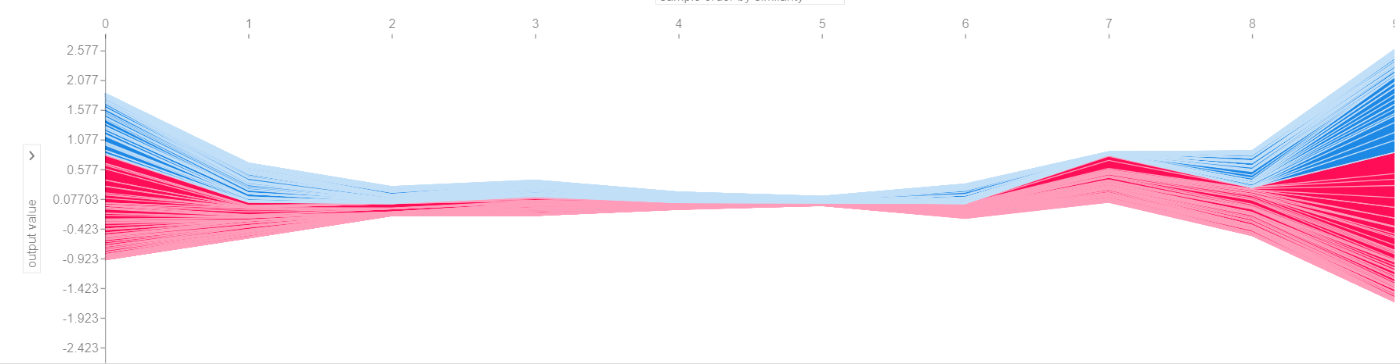
- 1つのサンプルを force_plot で可視化

- 複数のサンプルの Expected Value を出力
Predicted vector is [0.05080769 0.04827464 0.3013961 0.07014181 0.14768766 0.04803588
0.0063931 0.0567992 0.2704639 ] = Class 2 = kaden-channel
Input features/words:
['姿' 'ある日' '同僚' '矢野' '先' '同級生' '矢野' '目撃' '告げる' '間' '矢野' '何' '起こる' '七美' '前'
'姿' '消す' '矢野' '竹内' '想い' '迷う' '七美' '決心' '今回' '公開' '予告映像' '前後' '篇' '主題歌'
'書き下ろす' '前篇' '主題歌' '祈り' '涙。' '主人公' '時間' '軌跡' '彼ら' '寄り添う' '仕上がり' '舞台' '東京'
'移す' '大人' '現在' '矢野' '七美' '誓う' '未来' '願う' '後篇' '主題歌' '楽曲' '仕上がる' '吉高' '自身'
'演じる' '七美' '人' '愛情' '強い' '見出す' '女の子' '表現' '迷う' '矢野' '幸せ' '想う' '続ける' '七美'
'強い' '想い' '彼女たち' '運命' '変える' '僕等がいた' '前篇' '土' '後篇' '4月21日' '土' '全国' '東宝'
'系' '2部' '作' '連続' 'ロードショー' '僕等がいた' '公式サイト' '僕等がいた' '特集' '関連' '記事' '吉高'
'w' '主演' '僕等がいた' '主題歌' '書き下ろす']
True class is 4 = movie-enter
Explainer expected value is [0.08577367 0.09992643 0.1944763 0.05046979 0.11091243 0.05538014
0.15659042 0.16944283 0.07702796], i.e. class 2 is the most common.
- 複数のサンプルを同時に force_plot で可視化
kernel_explainer
- 特徴量ごとに SHAP Value を可視化
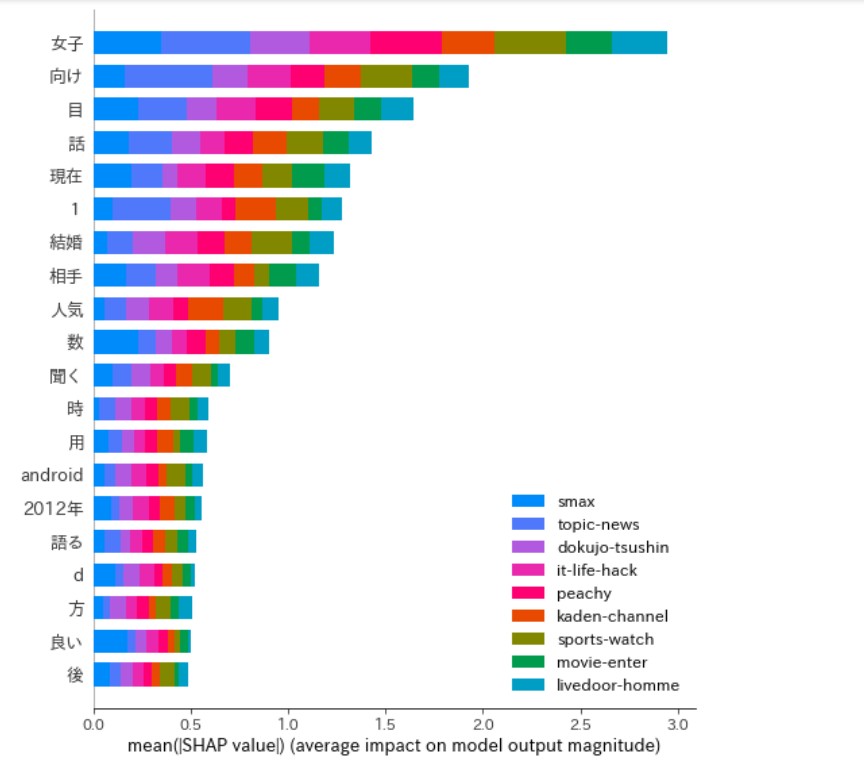
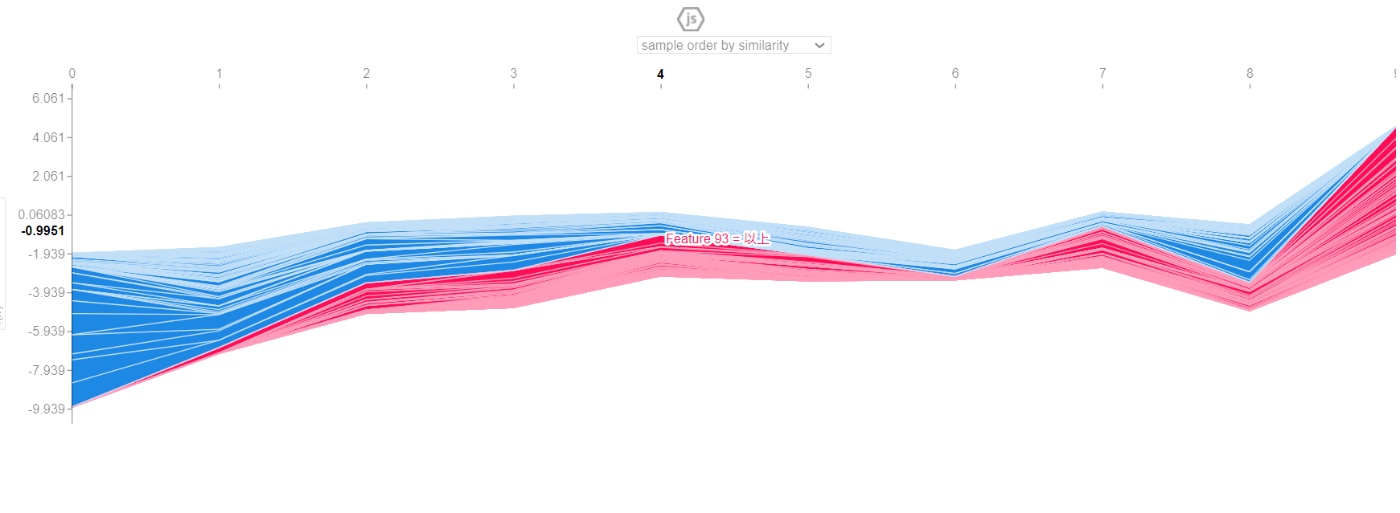
- 1つのサンプルを force_plot で可視化

- 複数のサンプルの Expected Value を出力
Predicted vector is [0.03255552 0.04091619 0.13853072 0.01792432 0.2013501 0.04182991
0.00526091 0.07994517 0.4416871 ] = Class 8 = topic-news
Input features/words:
['姿' 'ある日' '同僚' '矢野' '先' '同級生' '矢野' '目撃' '告げる' '間' '矢野' '何' '起こる' '七美' '前'
'姿' '消す' '矢野' '竹内' '想い' '迷う' '七美' '決心' '今回' '公開' '予告映像' '前後' '篇' '主題歌'
'書き下ろす' '前篇' '主題歌' '祈り' '涙。' '主人公' '時間' '軌跡' '彼ら' '寄り添う' '仕上がり' '舞台' '東京'
'移す' '大人' '現在' '矢野' '七美' '誓う' '未来' '願う' '後篇' '主題歌' '楽曲' '仕上がる' '吉高' '自身'
'演じる' '七美' '人' '愛情' '強い' '見出す' '女の子' '表現' '迷う' '矢野' '幸せ' '想う' '続ける' '七美'
'強い' '想い' '彼女たち' '運命' '変える' '僕等がいた' '前篇' '土' '後篇' '4月21日' '土' '全国' '東宝'
'系' '2部' '作' '連続' 'ロードショー' '僕等がいた' '公式サイト' '僕等がいた' '特集' '関連' '記事' '吉高'
'w' '主演' '僕等がいた' '主題歌' '書き下ろす']
True class is 4 = movie-enter
Explainer expected value is [-2.22118838 -2.34863188 -1.88403213 -3.36722057 -1.94303543 -1.93916927
-1.71997472 -1.52509183 -2.61690829], i.e. class 7 is the most common.
- 複数のサンプルを同時に force_plot で可視化
shap value の計算時間の比較
| DeepExplainer | KernelExplainer |
|---|---|
| 193.1秒 | 1時間14分 |
処理時間が全然違いますね・・・、DeepExplainerの環境構築が楽になるといいのですが。
Kernel shapの高速性と拡張性の向上を目指したライブラリ、shap pack というのも開発されているようなので、また試してみたいと思います、感謝。
以上になります、最後までお読みいただきありがとうございました。
その他参考サイト
-
協力ゲーム理論のシャープレイ値に基づき機械学習モデルの予測を解釈するKernel SHAPの理論と実装のまとめ
https://blog.tsurubee.tech/entry/2021/07/19/120541 -
ライブドアニュースのコーパスの取得
https://radiology-nlp.hatenablog.com/entry/2019/11/25/124219 -
Word2Vecの日本語学習済みモデルについて
https://qiita.com/Hironsan/items/8f7d35f0a36e0f99752c
https://github.com/Kyubyong/wordvectors -
Word2Vec の学習済みモデルから Embedding layer用の重み行列を作る
https://tksmml.hatenablog.com/entry/2019/09/01/112900 -
Google Drive から巨大ファイルをダウンロードするコマンド
https://www.mahirokazuko.com/entry/2019/04/27/134235 -
Mecab_tokenizer
https://analytics-note.xyz/machine-learning/gensim-lda/ -
Keras 使用時の再現性の確保
https://qiita.com/okotaku/items/8d682a11d8f2370684c9 -
Keras、Tensorflow のエラー周り
https://ameblo.jp/waka21/entry-12600778726.html
https://stackoverflow.com/questions/55982520/tensorflow-set-seed-error-when-running-autoencoder
https://stackoverflow.com/questions/65780082/attributeerror-module-tensorflow-has-no-attribute-get-default-graph-using-t
https://stackoverflow.com/questions/55142951/tensorflow-2-0-attributeerror-module-tensorflow-has-no-attribute-session
Discussion
Hi,
Thank you for your sharing. I learned a lot from this blog.
I also try to use
shapwith a xgboost model. To accelerate the speed, I used GPU:However, I always get this error message:
My environment is WLS2 Ubuntu20.04 with a NVIDIA GeForce 1080.