📖
トピックモデルを試してみた



こちらの記事を参考に、LDAによるトピックモデルで抽出したトピックのラベリング、可視化をやってみました。
データセットはライブドアニュースのものを使っています。
コードはこちら。
![]()
なお、トピックモデルの理論については下記の記事をご参照ください。
トピックモデルで抽出したトピックのラベリング
元のデータに対し、

こんな感じでラベルを付けてやります。

特段の前処理や特徴量エンジニアリングは行っていないため、微妙な感じになっていますが、ちゃんとトピックがラベリングされています。
かなり割愛していますので、詳細は参考サイトかコードをご参照ください。
トピック数を9とし、分かち書きして名詞、動詞、形容詞に絞りBoW形式にしたデータセットに対しLDAモデルの学習を行います。
dictionary = Dictionary(sentences)
corpus = [dictionary.doc2bow(text) for text in sentences]
lda = LdaModel(corpus, num_topics=9)
主に以下を使用します。
- lda[corpus[index]] ...コーパスの指定したindexに対するトピックのID、及び類似度を取得。
- dictionary.id2token[ID] ...トピックのIDに対応するトピックを取得。
- np.argpartition(-array, rank-1)[:rank] ...numpy の array型から指定した件数の上位のインデックスを抽出。
total_topic_contents_list = []
rank = 3
for i in tqdm.tqdm_notebook(range(len(corpus))):
# コーパスの各行ごとのトピックだけを格納するため初期化
topic_contents_list = []
# 各行のコーパスに対するトピックIDとその確率
toipc_ID_prob_list = np.array(lda[corpus[i]])
# スライスにより確率のみ抽出
np_toipc_prob = np.array(toipc_ID_prob_list)[:, 1]
# 上位3件を抽出。ただし要素数が3未満の場合は要素数を上限とする
num_of_slices = min(rank, len( toipc_ID_prob_list))
# 上位3件の確率のインデックスを取得。ただし要素数が3未満の場合は要素数を上限とする
first_thirrd_list = np.argpartition(
-np_toipc_prob, num_of_slices -1
)[:num_of_slices]
# 上位3件のトピックを topic_contents_listに格納
for i in range(len(first_thirrd_list)):
topic_contents_list.append(
dictionary.id2token[int(toipc_ID_prob_list[:, 0][first_thirrd_list[i]])]
)
# 各行のコーパスを1つの要素として格納するリスト
total_topic_contents_list.append(topic_contents_list)
df["topic"] = total_topic_contents_list
df = df[["category", "topic", "article"]]
df.head()
先述のとおりトピックをラベリングすることができました。
可視化
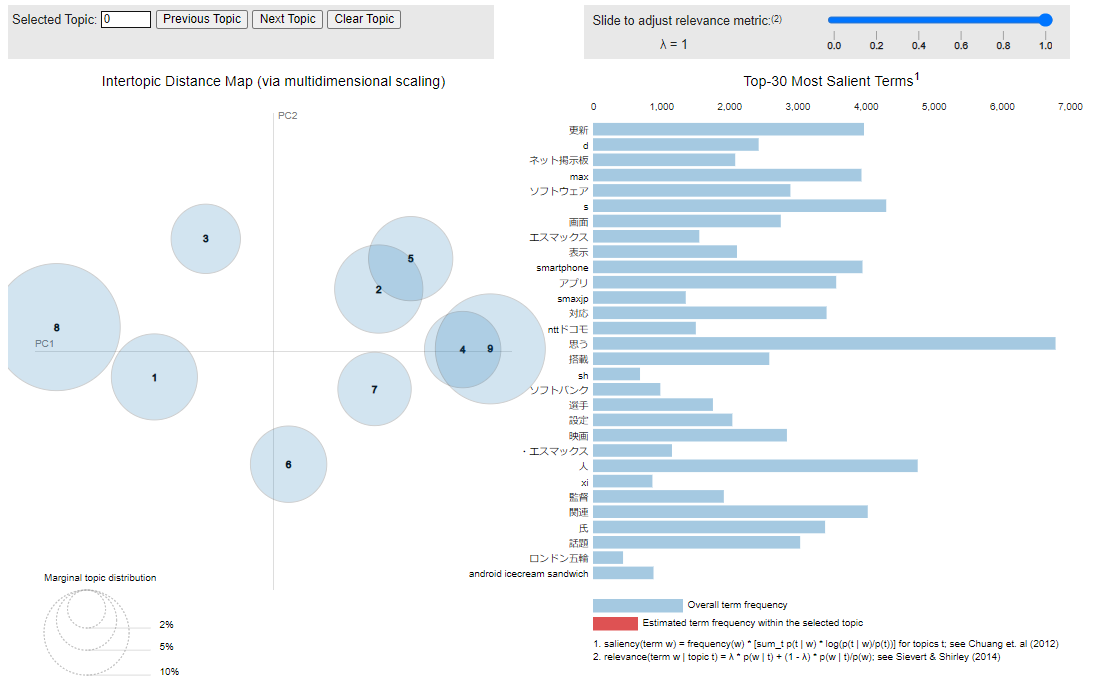
先述の参考サイトをコピペしただけですが、以下のように可視化も可能です。
作成した9つのトピック間の距離や、トピックごとの単語分布を確認することができます。
vis = pyLDAvis.gensim_models.prepare(
lda, corpus, dictionary, n_jobs = 1, sort_topics = False
)
pyLDAvis.display(vis)
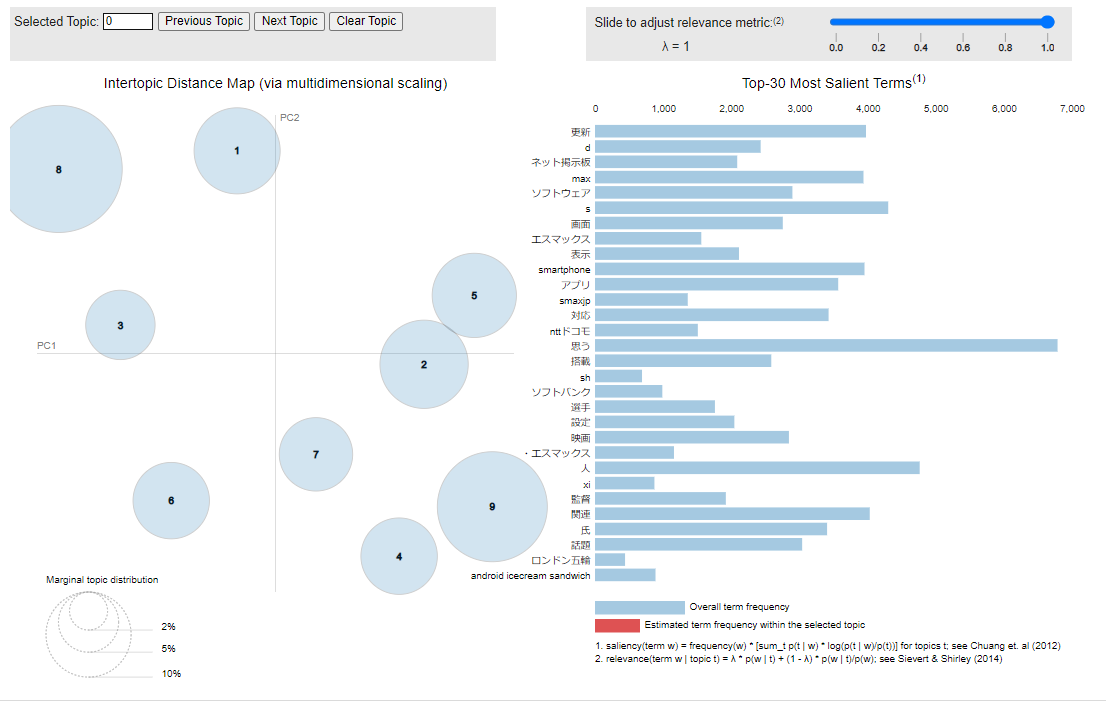
vis =pyLDAvis.gensim_models.prepare(
lda, corpus, dictionary, n_jobs = 1, mds='mmds', sort_topics = False
)
pyLDAvis.display(vis)
以上になります、最後までお読みいただきありがとうございました。
Discussion