この記事は Medley(メドレー) Advent Calendar 2025 の13日目です。
はじめまして、株式会社メドレーでエンジニアをしている德永です。
メドレーでは新規事業のプロダクト開発を担当しており、少し前に個人開発でもプロダクトをリリースし、この生成AI時代に実運用に乗っている0→1プロダクトの開発を複数経験することが出来ました。
0→1フェーズでは生成AIにより非常に高速な開発が進みますが、その一方で様々なボトルネックの顕在化が早くなることを強く実感しました。今回は、個人開発の中でドメインモデルを常に最新化するために取り組んだ内容をまとめました。
ドメインモデリングとテーブル設計のジレンマ
0→1フェーズでは、開発が進むにつれてドメインへの解像度が深まっていくことがほとんどです。また、0→1フェーズでなくとも法律など外部依存が変わったりすると、「このドメインのモデルはこうあるべきだった」と気づくことがよくあります。
しかし、一度本番稼働した RDB のテーブル構造の変更には通常大きな工数がかかるため、結果的にテーブル構造の都合に合わせてドメインモデルの方を妥協させる、という逆転現象が実務上何度も発生してきます。
事実と解釈を分離する
このジレンマを避けるためのアプローチとして、私は事実と解釈を分離するアプローチを採用しました。

「現在の状態」といった解釈済みの結果を保存するのではなく、「起きた事実」だけを追記していきます。どう解釈するか、どんなテーブル構造にするかは、仕様が固まってから、あるいは仕様が変わるたびに、過去のイベントから再構築できます。
事実を正として積み上げる手法が Event Sourcing、書き込み(事実)と読み込み(解釈)を構造的に分ける手法が CQRS (Command Query Responsibility Segregation) にあたります。
本記事では、これらを個人開発や 0→1 レベルでも手が出しやすい、 Cloudflare Workers + D1 + Queues という比較的軽量かつ低コストな構成で実現するパターンを紹介します。
なぜ今、Event Sourcing なのか
変更に対するアプローチの転換
従来の CRUD ベースの開発は、「現在の正解」を定義して保存するアプローチです。初期開発は非常に高速であるものの、後からドメインの概念が変わった場合、過去のデータも含めて新しい正解に移行させるための破壊的変更に伴うコストが発生します。

一方、Event Sourcing は「起きた事実」を追記していきます。ユーザーが作成された、名前が変更された、商品をカートに入れた、といった事実自体は、仕様が変わっても基本的には変わりません。
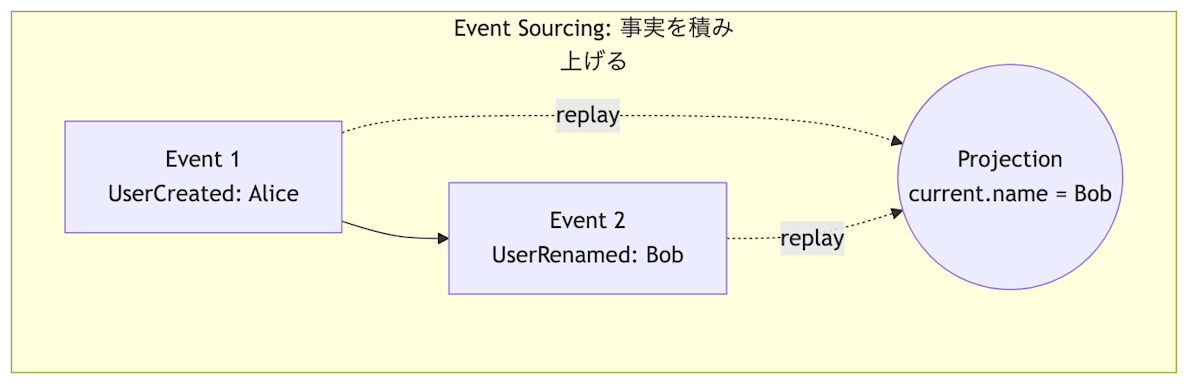
たとえばカートの集計ロジックを変えたいという要件が出ても、Read Model を捨てて、過去のイベントから再計算すれば済みます。これによって、データ移行のリスクを小さくでき、ドメインの変更をより高速に、かつ安全に行うことができます。
AI解析のためのコンテキスト資産化
また、Event Sourcing によって得られるベネフィットは変更容易性だけではありません。
例えば EC サイトのカート機能があったとして、 CRUD でカートの status: abandoned だけが残っていても、そのユーザーがどういった経路で離脱したかは分かりません。
一方、Event Sourcing で次のようなイベント列が残っていれば、もう少し踏み込んだ分析ができます。
CartItemAdded(商品A, ¥5,000)
→ CouponPageViewed
→ CouponApplyFailed(期限切れ)
→ CartAbandoned
このイベント列から「価格がネックで離脱した可能性が高い」「有効なクーポンを提示すれば購入に繋がるかもしれない」といった仮説を立てることが出来ます。
また、同じ status: abandoned でも、次のようなイベント列だったとします。
CartItemAdded(商品A)
→ CartItemAdded(商品B)
→ CartItemRemoved(商品A)
→ CartItemAdded(商品A)
→ CartAbandoned
この場合は「商品選びで迷っている」「比較情報やレビューを提示した方がよい」といった別のアクションが導かれます。
イベントとして事実を残しておくことは、ユーザー行動への解像度が上がることに直結します。更に、将来の AI 活用に繋がる「生のユーザー行動」という非常に価値の高いコンテキストを資産として残すことにも繋がります。
分析用のログ基盤に残すだけではダメなのか?
分析目的だけなら RDB + ログ基盤(BigQuery、Redshift、Snowflake 等)へのログ送信で十分です。最大の違いは、そのデータが Single Source of Truth なのか、ただのコピーなのかです。
分析用ログはあくまで RDB の横で記録された副産物です。アプリがクラッシュしてログ送信だけ失敗したり、RDB とログの内容が食い違ったりした場合、そのデータを使って本番 DB を作り直すことはできません。
Event Sourcing では「イベントの保存 = データの確定」です。そこにある事実をシステムとしての唯一の情報源とみなせるので、仕様が変わったときに、過去のイベントを再生して Read Model を安全に作り直すことができます。また、当然こちらのほうがイベントの信頼性は高いため、ノイズの少ない高精度な分析を実現することが出来ます。
とはいえ、Event Sourcing や CQRS の導入には、ボイラープレートが多いというハードルがあります。
ただ、生成 AI が一般化した現在、そこは以前ほどのボトルネックではありません。面倒なボイラープレートの作成を AI に任せることで、エンジニアはイベントの設計やドメインモデリングに集中しやすくなります。
Cloudflare Workers + D1 + Queues の活用
生成 AI によって実装コストのハードルは下がり、Event Sourcing も選択肢に入りやすくなりました。一方で、インフラ構築の重さという別の壁が残っています。
Event Sourcing を本格導入しようとすると、Kafka や Aurora、Kubernetes といった運用コストの高い構成が標準になりがちです。将来の柔軟性のために、初動の速さを犠牲にして構築に何ヶ月もかけるのは、フェーズによっては割に合いません。
そこで、私は Cloudflare Workers + D1 + Queues という構成を採用しました。

この構成にすると、重いミドルウェアを自前で管理せずに、サーバーレスなマネージドサービスだけで Event Sourcing 基盤を組めます。構築・運用の手間を抑えつつ、リクエスト数やストレージ量に応じた従量課金のため、Workers Paid Plan の月額 $5 から始められます。
Cloudflare コスト整理
続いて、具体的なコストを深ぼっていきます。この構成で主にコストが発生するのは
- Cloudflare Workers
- Cloudflare D1
- Cloudflare Queues
の 3 つとなります。
Cloudflare Workers
| プラン | 含まれるリクエスト / CPU | 超過時の従量課金 |
|---|---|---|
| Free | 100,000 リクエスト/日・1回あたり 10ms CPU | それ以上はその日の利用がブロック(課金ではなく制限) |
| Paid | 月額 $5 / アカウント → 1,000 万リクエスト/月 + 3,000 万 ms CPU/月 を含む |
リクエスト: $0.30 / 100万 CPU: $0.02 / 100万 ms |
Cloudflare D1
| プラン | 含まれる範囲 | 超過時の従量課金 |
|---|---|---|
| Free | 5,000,000 rows 読み取り / 日 100,000 rows 書き込み / 日 合計 5 GB まで |
超過するとクエリがエラーで拒否 |
| Paid | 月あたり最初の 250 億 rows 読み取り + 5,000 万 rows 書き込み + 5 GB ストレージまで含む |
読み取り: $0.001 / 100万 rows 書き込み: $1.00 / 100万 rows ストレージ: $0.75 / GB-month |
D1 は「行の読み書き」と「ストレージ量」に対して課金されます。行サイズには依存せず、何行スキャンしたかでカウントされます。また、クエリしていない時間の compute 料金は発生しないため、マルチテナントなどを目的として並列に複数 DB を立てても、使っていない分に追加料金はかかりません。
Cloudflare Queues
| プラン | 含まれる範囲 | 超過時の従量課金 |
|---|---|---|
| Paid | 1,000,000 operations / 月 | $0.40 / 100万 operations |
Queues は Workers Paid プランが必須ですが、料金は Workers の $5 に含まれています。コストはキューに対するオペレーション数(書き込み・読み取り・削除)で決まります。
通常 1 メッセージあたり 3 オペレーション(書き込み・読み取り・削除)です。また、64KB 超のメッセージは 64KB ごとに 1 オペレーションとしてカウントされます。
概算すると 1 メッセージ = 3 operations なので、約 33 万メッセージ/月 までは追加課金が発生しません。
ここから先は、Cloudflare Workers + D1 + Queues を使った Event Sourcing / CQRS なアプリケーションを運用する中で直面した課題と対応策を共有します。
課題1:分散トランザクションと整合性担保
D1 は 1 DB あたり 1 つの Durable Object 上でシリアライズされるため、書き込み順序は守られます。各 DB が 1 本のキューで直列処理される設計なので、同一 DB 内の書き込みは確実に順序付けられます。
一方で読み取りはグローバルレプリカから行われるため、書き込み直後の読み取りではレプリケーション遅延が起こり得ます。
運用では、Sessions API (db.withSession) を「書いた直後に読みたい箇所」にだけ使い、それ以外はレプリカ読み前提で UX を設計しています。
この順序一貫性は Cloudflare 公式ブログでも解説されています。
楽観的ロックと物理ガードの二段構え
さらに、論理チェックと物理制約を組み合わせた二段構えの楽観的ロックで競合を防いでいます。
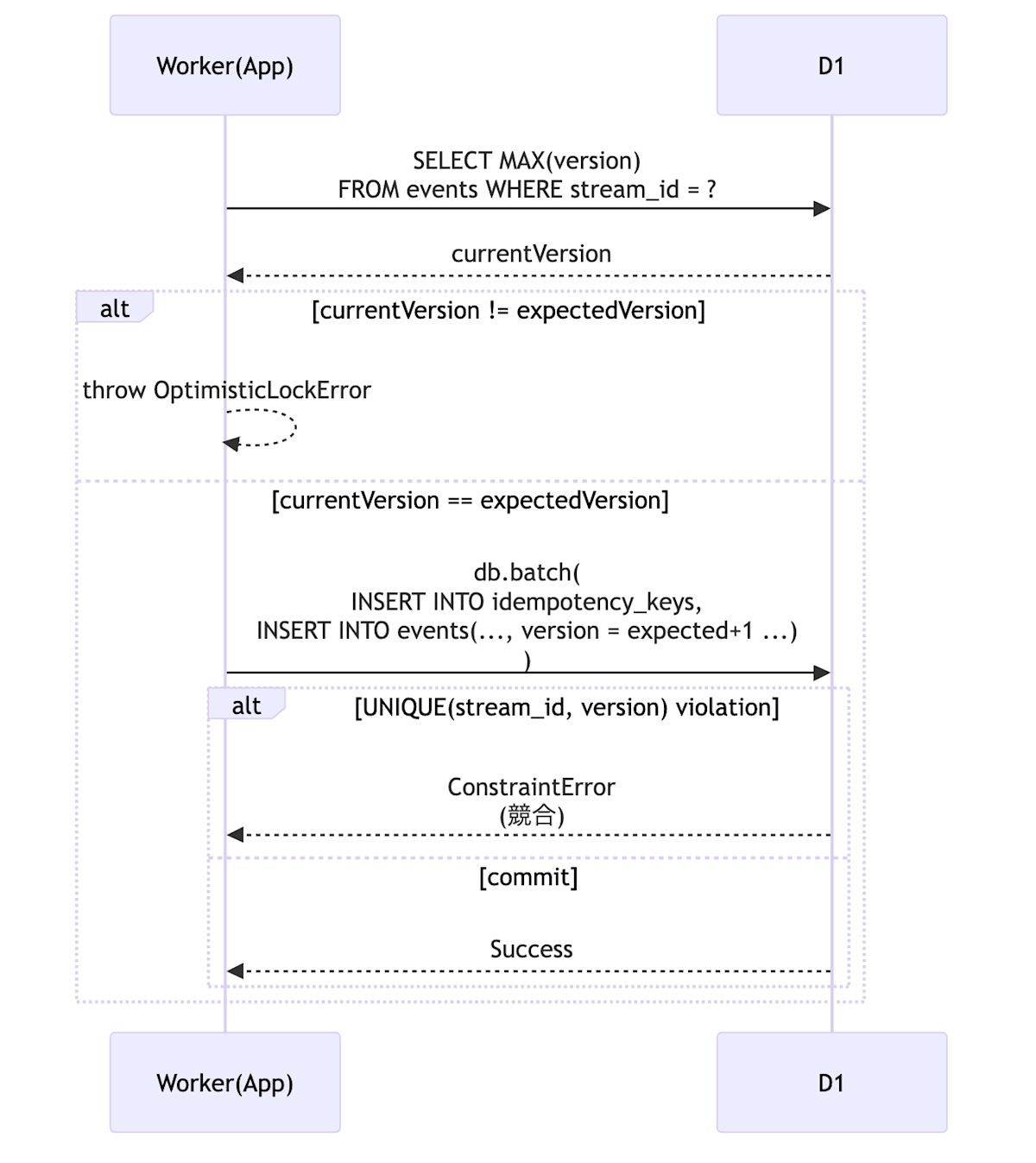
アプリケーションレベルでのバージョンチェックに加え、db.batch() を使って UNIQUE 制約付きテーブルへの書き込みをアトミックに行うことで、物理的な競合も抑えています。
// infrastructure/event-store.ts
// コードはイメージです。実運用に載せているコードから抜粋。
async appendEvents(streamId: string, events: DomainEvent[], expectedVersion: number) {
// 1. アプリケーション側でのバージョン確認
const current = await db.prepare("SELECT MAX(version) as v FROM events WHERE stream_id = ?")
.bind(streamId)
.first<{ v: number }>();
const currentVersion = current?.v ?? 0;
if (currentVersion !== expectedVersion) {
throw new OptimisticLockError({ streamId, expectedVersion, currentVersion });
}
const statements: D1PreparedStatement[] = [];
// 2. idempotency key の書き込み
const idemKey = events[0]?.metadata.idempotencyKey;
if (idemKey) {
statements.push(
db.prepare("INSERT INTO idempotency_keys (key, stream_id) VALUES (?, ?)")
.bind(idemKey, streamId)
);
}
// 3. イベント本体のINSERT
for (const event of events) {
statements.push(
db.prepare("INSERT INTO events (...) VALUES (...)").bind(...)
);
}
// 4. 実行
try {
// events テーブル側に UNIQUE(stream_id, version) 制約を持たせておく
await db.batch(statements);
} catch (e) {
handleDbError(e);
}
}
課題2:スキーマの進化と型安全性
イベントデータは「事実」なので、一度保存したものは原則として消せません。ただし、開発が進めばイベントのスキーマを変えたくなることはあります。
バリデーションとバージョン変換
筆者の環境では Hono.js + TypeScript + Zod を使い、DB からデータを読み出す際の境界で検証と変換を行っています。

// Zod の transform で旧フォーマットを新フォーマットに変換
const V1Schema = z.object({ name: z.string() });
const V2Schema = z.object({ firstName: z.string(), lastName: z.string() });
// V1 のデータが来たら、V2 の形式に変換して返す
const EventSchema = z.union([
V2Schema,
V1Schema.transform((old) => ({
firstName: old.name,
lastName: ""
}))
]);
Zod などのライブラリでスキーマ変換を型安全に吸収することで、ドメインロジック側では常に最新のデータ型として扱うことが可能です。
課題3:プラットフォーム制約と対応策
D1 の動的生成の制限
筆者のプロダクトでは、テナントごとに DB を分割したい要件がありました。
D1 自体の作成は Cloudflare API の D1 Database create エンドポイント(Cloudflare API | D1 › Database › create)で動的に行えますが、Worker から参照する env.DB バインディングはデプロイ時に静的にしか定義できません。
そのため、Worker から API を叩いて DB を作成し、GitHub Actions で wrangler.toml を更新して再デプロイする、というプール補充ワークフローを採用しています。
同様の実装を行っている例:
事前に空の DB プールを作成・デプロイしておき、サインアップ時にはそこから割り当て、裏で GitHub Actions が非同期にプールを補充します。
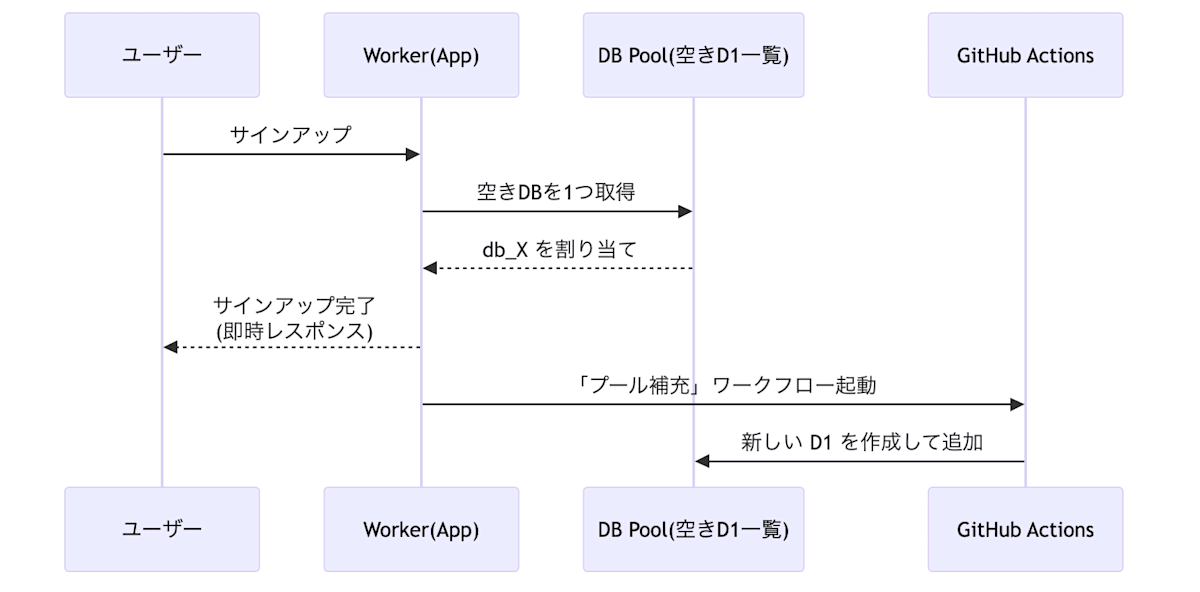
Cloudflare Queues の重複排除(冪等性設計)
Cloudflare Queues は At-Least-Once 配信のため、同じメッセージが再送される可能性があります。Consumer 側で冪等性を担保する必要があります。

processed_event_ids テーブルで処理済みの eventId を管理し、重複をスキップします。Read Model の更新と eventId の記録は db.batch() でアトミックに実行し、中途半端な状態を避けます。
スケーラビリティ:この構成の限界と次のステップ
Cloudflare Workers + D1 + Queues の構成は、実際に運用してみてもスモールスタートには有効なアプローチでした。ただ、プロダクトが成長した際にどこまで耐えられるか、どこで限界を迎えるかは把握しておく必要があります。
この構成でどこまで行けるかを各モジュールごとの制限は以下のようになっています。
また、 Read Replica による読み取りスケールは以下のドキュメントにまとまっています。
どこから「無理」になるか
| レベル | 条件 | 対応 |
|---|---|---|
| 対応可能 | ・月間 1,000万イベント以下 ・DB < 10GB ・テナント < 1,000 |
本記事の構成で運用可能 |
| リスクあり | ・書き込み 100+/sec ・Session API 多用 ・テナント 1,000〜10,000 |
チューニング・テナント分割で延命 |
| 構成変更が必要 | ・書き込み 1,000+/sec 継続 ・DB > 10GB ・強整合性が常時必要 |
外部 DB への移行を検討 |
一般的な Web サービスの初期フェーズであれば、本記事内のミニマム構成で十分運用できますし、インフラモジュールの差し替えも比較的容易です。
D1 の監視方法
限界に気づかないままサービスが止まるのは避けたいので、筆者の環境では D1 の監視機能を利用しています。
# クエリパフォーマンスの分析
npx wrangler d1 insights <database_name> --sort-by=time --limit=10
# 実行回数が多いクエリを特定
npx wrangler d1 insights <database_name> --sort-by=count --limit=10
GraphQL Analytics API を使えば、リージョン別のパフォーマンスや served_by_primary の割合なども取得できます。筆者の場合は Session API の利用箇所が増えつつあるため、その割合を定期的にチェックし、閾値を超えたらアラートが飛ぶようにしています。
スケールする構成への移行
プロダクトが成長してくると、Cloudflare のみでスケールさせるより、外部データベースに Event Store を逃がす方が現実的になるタイミングがあります。
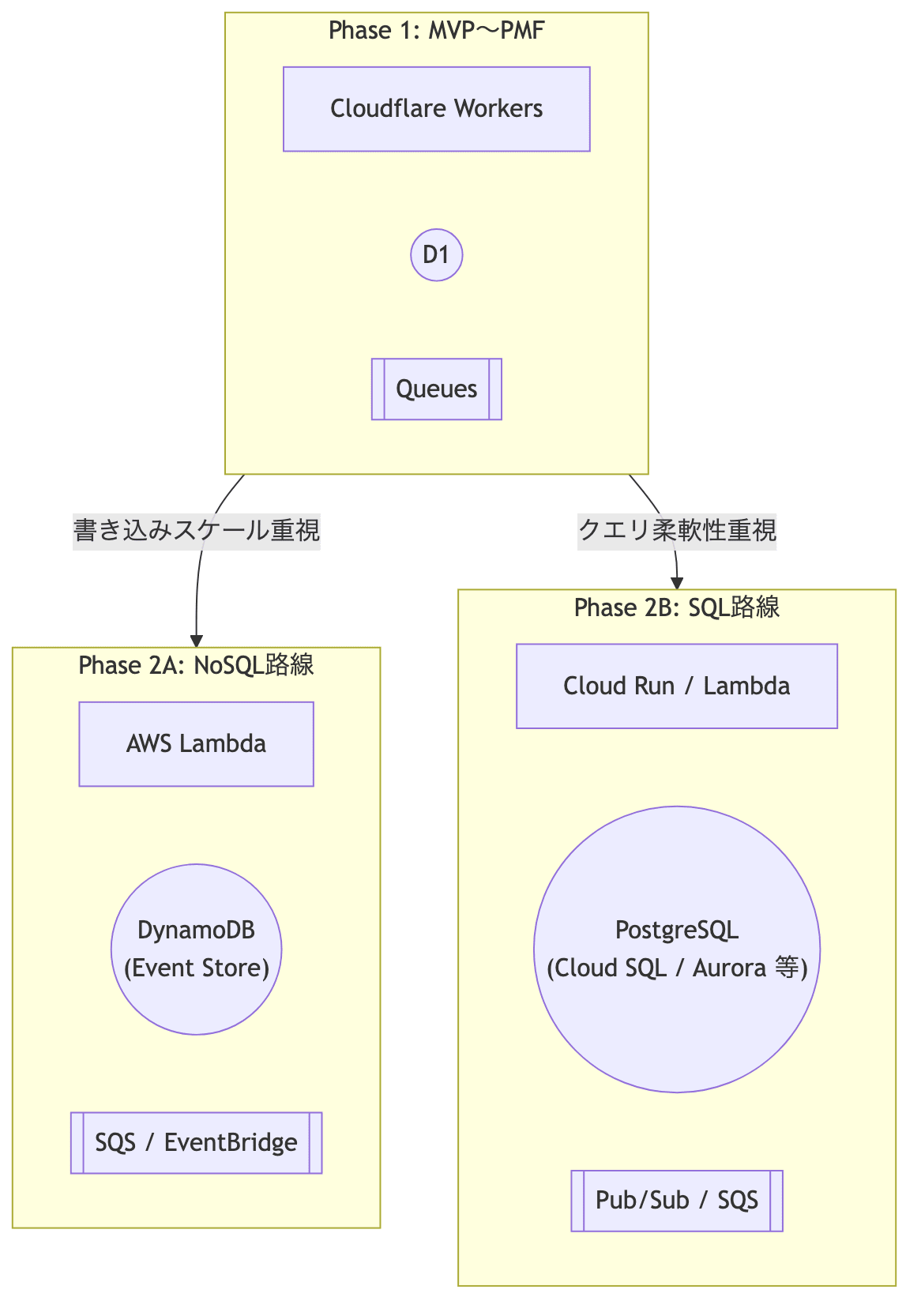
Event Sourcing の良いところは、イベントスキーマと Zod などによる変換ロジックがインフラにあまり依存しないことです。移行時もイベントストリームをそのまま新しいストアへコピーし、 Read Model を破棄して再投影することで移行できます。
Option A: DynamoDB(NoSQL 路線)
Event Sourcing と DynamoDB の組み合わせは、AWS 公式が Event-driven Architecture のリファレンスとして公開している構成です。
// DynamoDB でのイベントテーブル設計イメージ
Partition Key: aggregateId (e.g., "order-123")
Sort Key: version (e.g., 1, 2, 3...)
Attributes: eventType, payload, timestamp, metadata
パーティションキーを集約 ID にしてストリームを水平分割する戦略は、D1 の「1 DB = 1 Durable Object」という単一ライター構造を避けたいときの選択肢になります。
一方で、DynamoDB だけで複雑な集計や分析をこなすのは難しいため、
- Read Model 用に別ストア(Aurora / RDS / OpenSearch 等)を用意する
- 分析用途は Redshift / BigQuery などに流す
といった構成が現実的です。Event Store は事実ログに徹し、読み出しは用途に応じたストアに逃がすイメージです。
Option B: PostgreSQL + Cloud Run / Lambda(SQL 路線)
Event Store 自体も SQL で直接覗きたい、既存の運用ノウハウを活かしたい、といったケースでは PostgreSQL が有力です。
PostgreSQL を Event Store にした事例としては、例えば次のようなものがあります。
-- PostgreSQL でのイベントテーブル設計イメージ
CREATE TABLE events (
id UUID PRIMARY KEY,
aggregate_id UUID NOT NULL,
version INTEGER NOT NULL,
type TEXT NOT NULL,
payload JSONB NOT NULL,
occurred_at TIMESTAMPTZ NOT NULL,
UNIQUE (aggregate_id, version)
);
-
aggregate_id + versionで楽観ロック -
payloadは JSONB で保持しつつ進化させる - Projection は別テーブル(Read Model)として管理
といった構成は、D1 上の Event Store とほぼ同じです。そのため、アプリケーション側の Event Store インターフェースだけ差し替えることで、最初は D1 で始めて、後から PostgreSQL へ移行することも可能です。
マネージドサービスとしては Cloud SQL、Aurora / RDS などが候補に上がります。Compute 層は Cloud Run や Lambda などにすれば、 Workers で書いている Hono.js のコードをほぼそのまま載せ替えられます。
Cloudflare に残りつつ外部 DB を使う選択肢(Hyperdrive)
すぐに Cloudflare から完全に離れたくない場合、Workers はそのままにして、Event Store だけ外部 PostgreSQL に逃がす構成もあります。
Cloudflare の Hyperdrive を使うと、Workers から外部 DB に対して接続プーリングとキャッシュ付きでアクセスできます。
たとえば「Event Store は VPC 内の PostgreSQL / Aurora に配置し、アプリケーションロジックや API は Workers に残す」といった構成が取りやすくなります。
エンタープライズ向けの専用基盤
本記事では詳細は扱いませんが、エンタープライズ規模や厳格な監査要件、マルチストリーム集約が必要な場合は、最初から EventStoreDB や Kafka + ksqlDB のようなイベントストリーム専用基盤を選ぶ方が現実的です。
実践的な推奨事項
| フェーズ | 目安 | 推奨構成 |
|---|---|---|
| MVP〜PMF | 月間 100万イベント以下 / DB < 5GB | D1 + Queues(本記事の構成) |
| 成長期 | 月間 1,000万〜1億イベント | DynamoDB + Lambda(書き込みスケール重視) または PostgreSQL + Cloud Run(クエリ柔軟性重視) |
| エンタープライズ | 月間 10億イベント以上、厳格な要件 | EventStoreDB、Apache Kafka + ksqlDB など専用基盤 |
ポイントは、Event Sourcing のコア設計(イベントスキーマとバージョン管理)がインフラに依存しにくいことです。事実の設計さえしっかりしていれば、D1 から DynamoDB や PostgreSQL への移行も比較的やりやすく、大きな技術負債になりにくい構成にできます。
まとめ:不確実性を飼い慣らす
Event Sourcing は、かつては実装難易度も運用コストも高いアーキテクチャでした。ただ、Cloudflare Workers と D1 の登場により、個人開発レベルでも現実的な選択肢になっています。
このアーキテクチャを採用するコストは、将来の仕様変更コストを下げるための投資と考えられます。単純な技術負債は比較的返しやすい一方で、ドメイン領域の負債は返上が難しいことが多いです。
事実さえ残しておけば、AI が利用するコンテキストとして再解釈でき、長期的な価値を維持しやすくなります。この記事が、変化に強いプロダクトを設計したいエンジニアの方にとって、ひとつの参考になれば十分です。
おわりに
メドレーでは、本質的な課題に向き合うエンジニアを募集しています。
本記事で触れたような、不確実性への適応や、AI による実装コストの削減は、単なる技術検証ではなく、実運用に乗っているプロダクトの開発にも活用可能です。特に医療・ヘルスケアの領域は、法改正や制度変更、複雑な業務フローが絡み合う、仕様変更が常態化している世界です。
メドレーの開発チームでは、生成AIをコーディング補助ツールにとどめず、開発者の認知負荷を下げ、より本質的なドメインモデリングやユーザー価値の検討に時間を割くための道具として活用しています。
技術的な正解を固定せず、ビジネスの変化に応じてアーキテクチャを柔軟に進化させたい方。ボイラープレートは AI に任せて、人間は設計や意思決定に集中したい方。
そういった考え方に共感いただけるなら、ぜひ一度お話しできればと思います。筆者宛の DM もお待ちしています。
明日は @m_okazaki08 さんの記事です。

Discussion